







什么是计算机集群?
计算机集群是一组相互连接的计算机(服务器),它们协同工作以完成共同的任务。集群中的每个计算机节点都可以独立运行,但它们通过网络连接在一起,以实现更高的可靠性、性能和可扩展性。

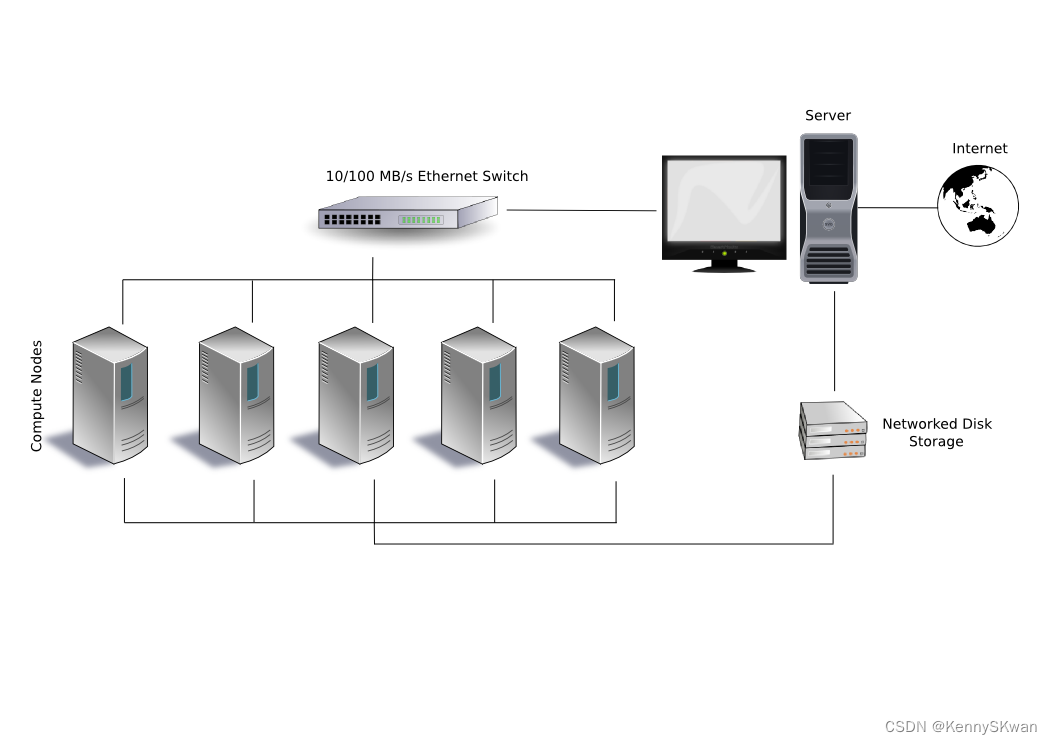
典型的贝奥武夫配置
**
为什么要分布式数据存储?
**
总的想法是,当您开始收集、存储和分析大量数据时,如果您的数据不适合机器的 RAM(随机存取存储器- 计算机的一部分),则将其存储在一台机器上会导致效率非常低下。可快速访问但不稳定的存储)。
您也不希望将所有数据存储在一个地方,因为如果那台计算机出现故障,您将丢失所有数据。使用计算机的规则之一是它们总是会崩溃。此外,一台服务器中存储的数据越多,读取它以查找相关信息所需的时间就越长。
**
这里要引入一下Hadoop 的起源
**
Hadoop的诞生源自于谷歌对存储大量数据并快速访问所有数据的商业需求。谷歌的系统启发了Hadoop分布式文件系统(HDFS),这一系统的核心概念是将数据存储在服务器集群上。与传统的大型服务器相比,Hadoop采用了分布式架构,利用许多普通计算机的硬盘驱动器进行数据存储和处理。这使得Hadoop系统能够无限可扩展,并且无需巨额投资购买昂贵的硬件设备。

数据是冗余存储的(这意味着相同的信息被写入多台不同的服务器上,通常是 3 台),这样系统就不会因为一台服务器宕机而受到削弱。数据通过处理系统Hadoop MapReduce进行处理,该处理系统在集群资源管理器Hadoop YARN上运行。MapReduce 可以获取分布式数据,将其转换(Map),并将其聚合(Reduce)为其他有用的数据。
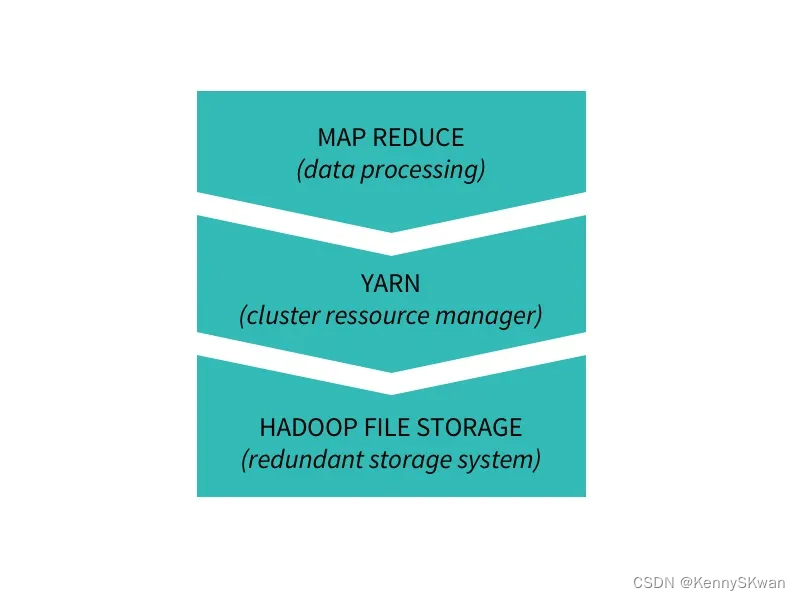
计算机集群在大数据体系中的作用
1. 分布式存储:
分布式存储是指将数据分散存储在集群中的多个节点上,而不是集中存储在单个存储设备上。这种存储方式带来了以下优势:
- 高可靠性和可用性: 数据的复制和分布存储在多个节点上,即使某个节点发生故障,数据仍然可通过其他节点访问,提高了系统的可靠性和可用性。
- 高性能: 分布式存储允许数据在多个节点上并行读取和写入,从而提高了数据访问速度和处理性能。
- 扩展性: 可以根据需要向集群中添加更多的存储节点,以增加存储容量,而无需对现有系统进行大规模更改。
- 灵活性: 分布式存储系统通常支持多种数据访问模式和数据存储格式,能够满足不同应用场景的需求。
常见的分布式存储系统包括Hadoop的HDFS、Apache Cassandra、Amazon S3等。
2.并行计算:
并行计算是指将任务分解为多个子任务,并在集群中的多个节点上同时执行这些子任务,以加速计算过程。并行计算带来了以下优势:
- 高性能: 通过同时利用集群中的多个计算节点,可以大大加快数据处理和计算速度。
- 资源利用率高: 并行计算充分利用了集群中的所有计算资源,提高了资源的利用效率。
- 灵活性: 并行计算框架通常提供丰富的API和工具,使得开发人员可以轻松地编写并行计算任务,并根据需要动态调整任务分配和执行策略。
常见的并行计算框架包括Apache Hadoop的MapReduce、Apache Spark等。
3. 容错性:
容错性是指系统在面对节点故障或其他异常情况时能够继续正常工作的能力。计算机集群的容错性主要体现在以下方面:
- 节点故障处理: 当集群中的某个节点发生故障时,系统能够自动检测并将任务重新分配给其他可用节点,以保证任务的顺利执行。
- 数据冗余: 分布式存储系统通常会对数据进行多次复制存储在不同的节点上,以保证数据的可靠性和容错性。
- 检测与恢复: 集群管理系统通常会定期检测集群中的节点状态,并采取相应的措施来修复故障节点或数据损坏。
4. 水平扩展性:
水平扩展性是指系统能够通过增加节点数量来扩展其计算和存储能力,而无需对现有系统进行大规模更改。水平扩展性带来了以下优势:
-
弹性扩展: 可以根据需要动态地向集群中添加新的节点,以满足不断增长的数据处理需求。
-
成本效益: 水平扩展通常比垂直扩展更具成本效益,因为可以使用廉价的标准硬件来构建集群。
-
无需停机: 在进行水平扩展时,通常无需停机或只需短暂停机,从而保证了系统的持续可用性。
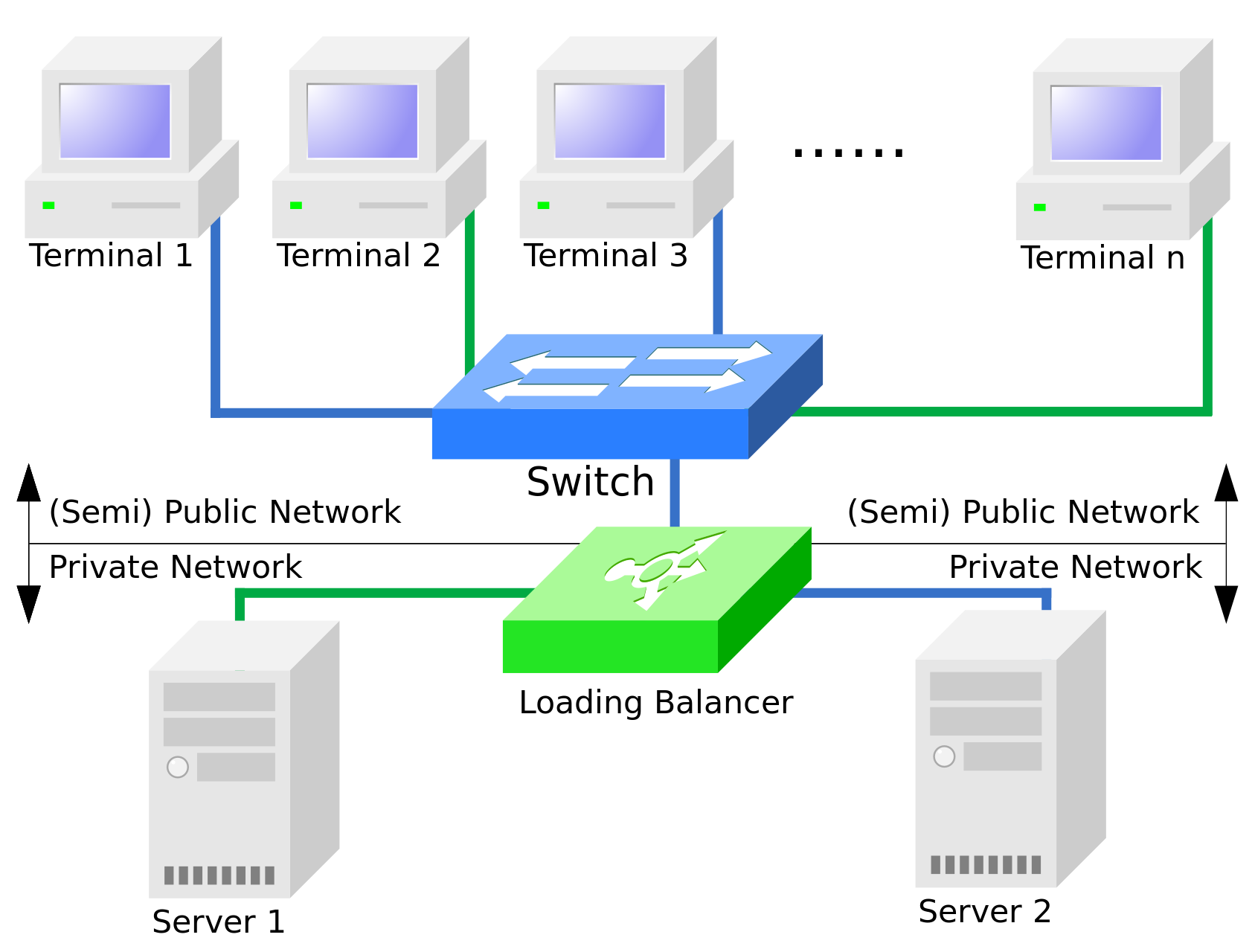
一个负载均衡集群,有两台服务器和N个用户站
**
计算机集群的工作原理
**
1. Master-Slave架构:
在计算机集群中,通常采用Master-Slave架构来管理和协调集群中的工作。在这种架构下,有一个主节点(Master),负责协调和管理整个集群,以及多个从节点(Slave),负责执行实际的计算任务。
Master节点:
- 负责任务调度和资源分配:Master节点负责接收来自用户或应用程序的任务请求,并将任务分配给集群中的从节点执行。它根据集群中各个节点的负载情况和任务的优先级来动态调整任务分配策略,以实现最佳的性能和资源利用率。
- 管理集群状态:Master节点负责监控集群中各个节点的状态,包括节点的健康状况、资源使用情况等,以及任务的执行情况。它可以及时检测到节点故障或任务执行异常,并采取相应的措施进行处理。
Slave节点:
- 执行任务:Slave节点接收Master节点分配的任务,并执行实际的计算和处理工作。它们负责读取数据、执行计算任务、生成结果,并将结果返回给Master节点。
- 向Master节点汇报状态:Slave节点定期向Master节点汇报自身的状态,包括负载情况、可用资源等信息,以帮助Master节点进行任务调度和资源管理。
2. 分布式文件系统:
分布式文件系统是指将文件分散存储在集群中的多个节点上,并提供统一的文件访问接口。它具有以下特点:
-
数据分布和复制:
分布式文件系统将文件划分为多个块,并将这些块分布存储在集群中的多个节点上。为了提高数据的可靠性和容错性,通常会对数据进行多次复制存储在不同的节点上。 -
透明性和一致性:
用户可以通过统一的文件访问接口(如文件路径)来访问分布式文件系统中的文件,而无需关心文件的具体存储位置。分布式文件系统会自动处理数据的复制、一致性和容错性等问题,使用户感受不到底层的复杂性。 -
高性能和可扩展性: 分布式文件系统通常具有高性能和可扩展性,能够支持大规模数据的高速存储和访问,并且可以根据需要动态扩展存储容量和吞吐量。
常见的分布式文件系统包括Hadoop的HDFS、Google的GFS、Amazon的S3等。
3. 任务调度:
任务调度是指Master节点根据任务的优先级和集群资源的情况,动态地将任务分配给集群中的各个节点执行。它包括以下几个方面:
- 任务调度策略:
Master节点根据任务的优先级和节点的负载情况,选择合适的节点执行任务。通常会采用一些调度算法来实现任务调度,如最短作业优先、公平调度等。 - 资源管理:
Master节点负责监控集群中的资源使用情况,包括CPU、内存、磁盘等资源的利用率和可用性。它根据节点的资源情况来决定是否接受新的任务,并将任务分配给空闲的节点执行。 - 任务执行监控:
Master节点负责监控任务的执行情况,包括任务的启动、执行进度、完成情况等。它可以及时检测到任务执行异常或节点故障,并采取相应的措施进行处理。
4. 数据通信:
数据通信是集群中各个节点之间进行数据交换和通信的过程。它包括以下几个方面:
-
节点间通信:
各个节点之间通过网络进行通信,包括数据传输、消息通知等。高性能的网络通常是集群系统的关键组成部分,它能够支持大量数据的高速传输和低延迟通信。 -
数据传输协议:
集群中的节点通常使用一些常见的数据传输协议来进行通信,如TCP/IP协议栈。此外,还可以针对特定的应用场景和数据类型开发定制的通信协议,以提高数据传输的效率和可靠性。 -
数据安全和加密: 数据通信过程中需要考虑数据的安全性和隐私保护。可以采用加密算法对数据进行加密,以防止数据被非法获取和篡改。

















 78
78











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











