




 本文详细解释了MapReduce在分布式计算中的作用,包括Map、Shuffle和Reduce三个阶段的工作原理,以及为何磁盘和HDFS在处理成本中的重要性。同时提出了通过内存计算、资源扩展和数据优化来降低成本的策略。
本文详细解释了MapReduce在分布式计算中的作用,包括Map、Shuffle和Reduce三个阶段的工作原理,以及为何磁盘和HDFS在处理成本中的重要性。同时提出了通过内存计算、资源扩展和数据优化来降低成本的策略。
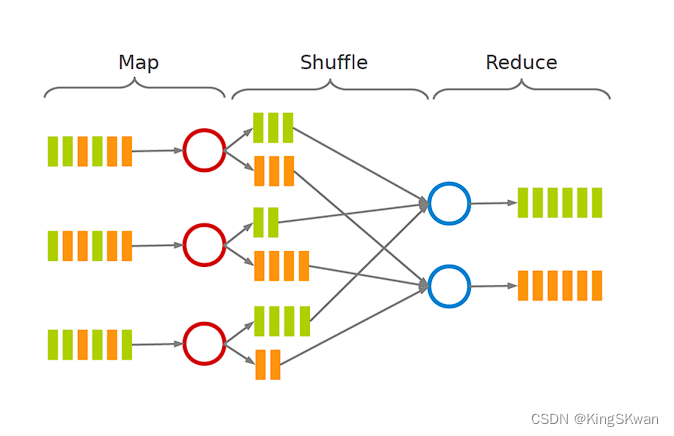
当谈到分布式计算和大数据处理时,MapReduce是一个经典的范例。它是一种编程模型和处理框架,用于在大规模数据集上并行运行计算任务。MapReduce包含三个主要阶段:Map、Shuffle 和 Reduce。
**
Map 阶段
**
Map 阶段是 MapReduce 的第一步,它负责将输入数据集分解成一系列键值对,并将这些键值对传递给各个 Mapper 函数进行处理。在 Map 阶段,用户自定义的 Map 函数会被并行应用于输入数据集中的每个元素。Map 函数的输出结果是一系列中间键值对,通常称为中间数据。
Map 阶段的工作原理可以概括为以下几个步骤:
数据分片: 输入数据集被划分成若干个大小合适的数据块,每个数据块被一个 Mapper 处理。
映射函数应用: 每个 Mapper 对数据块中的每个元素应用用户定义的映射函数。映射函数将每个输入元素转换为零个或多个中间键值对。
中间键值对生成: 映射函数的输出结果形成一系列中间键值对,其中键用于标识数据,值用于保存与键相关联的信息。
中间结果分发: 中间键值对被分发到后续的 Shuffle 阶段,以便根据键进行分组并传递给相应的 Reducer。
**
Shuffle 阶段
**
Shuffle 阶段是 MapReduce 中的一个关键步骤,它负责将 Map 阶段产生的中间键值对按键进行排序和分组,并将具有相同键的键值对传递给相同的 Reducer。Shuffle 阶段的主要任务是在不同的节点之间传输数据并进行合并操作,以便在 Reduce 阶段中能够高效地处理数据。
Shuffle 阶段的工作原理包括以下几个步骤:
分区: 根据中间键值对的键,对数据进行分区,将具有相同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











