







批量数据处理
对于系统之间数据交互,会涉及到一种情况,即A系统的数据要同时发给B、C、D等几个系统。这个时候A一般会提供接口或数据文件供外系统取数。在信创改造的时候,这两个情况对应的方案也区别较大。
接口
这种在信创改造的时候相对来说改动较小,只需要换成信创环境跑下代码就可以了,遇见报错就改报错。可能涉及的点是Oracle的merge into 要修改成MySQL的语法。
要在 MySQL 中实现类似的功能,你可以使用多个 INSERT … ON DUPLICATE KEY UPDATE 语句,或者结合使用 INSERT IGNORE、REPLACE INTO 以及 UPDATE 语句。
以下是一个Oracle MERGE INTO 示例及其可能的MySQL实现:
Oracle MERGE INTO 示例
MERGE INTO target_table t
USING source_table s
ON (t.id = s.id)
WHEN MATCHED THEN
UPDATE SET t.column1 = s.column1, t.column2 = s.column2
WHEN NOT MATCHED THEN
INSERT (id, column1, column2)
VALUES (s.id, s.column1, s.column2);
MySQL 实现
在MySQL中,你可以使用 INSERT … ON DUPLICATE KEY UPDATE 来实现上述功能,但这要求 target_table 有一个唯一索引或主键。
假设 target_table 有唯一索引或主键 id
-- 插入新记录或更新现有记录
INSERT INTO target_table (id, column1, column2)
VALUES (?, ?, ?)
ON DUPLICATE KEY UPDATE
column1 = VALUES(column1),
column2 = VALUES(column2);
在这个语句中,? 是占位符,实际使用时需要替换为具体的值,或者通过参数绑定来传递值。
对于我个人来说,MySQL的INSERT … ON DUPLICATE KEY UPDATE 的语法的局限较大,需要MySQL表的主键就是Oracle语法的ON的条件才行。
我用的较多的是下面的形式,update和insert的组合,而且这种是通用的。但是效率是没有merge into的形式高的。所以这个要根据项目的实际情况来进行综合的考虑。
-- 尝试更新现有记录
UPDATE target_table t
JOIN source_table s ON t.id = s.id
SET t.column1 = s.column1, t.column2 = s.column2;
-- 插入那些在源表中但不在目标表中的新记录
INSERT INTO target_table (id, column1, column2)
SELECT s.id, s.column1, s.column2
FROM source_table s
LEFT JOIN target_table t ON s.id = t.id
WHERE t.id IS NULL;
数据文件
对于Oracle来说,可以通过splldr来处理数据文件。这里面简单记一下sqlldr的使用。sqlldr分为四个部分即控制文件(control file)、数据文件(data file)、日志文件(log file)和错误文件(bad file)。
splldr要做的事情是,当我需要将一个数据文本A1的内容转化成Oracle表A2中的数据的时候,我就会用到这个功能。
这里对四个文件做简单的解释。
首先会用truncate来将表数据进行清理。
控制文件(.ctl)是根据表A2的字段来生成的,里面的重点是指定了每个要处理的列和列的类型。以及数据文件中,每一行数据的分割符,行中每一列数据的分隔符。后面需要用这些分隔符来将数据文件分割成一行行的数据,再对应到数据库表的列。
数据文件(.txt)就是外系统发来的数据文件。
日志文件(.log)就是记录了每一个文件的导入情况,成功、失败的数量,失败的原因等。日志文件是每导入一次数据文件都会生成的。一旦导入有问题可以找到错误文件对应的日志文件。
错误文件(.bad)是导入的数据有问题才会生成错误文件。不是没一次都会生成的。
userid指定了数据库的用户名和密码,control指定了控制文件的路径,data指定了数据文件的路径,log、bad分别指定了日志文件、错误文件路径2。
sqlldr userid=用户名/密码@oracle control=ctl/test.ctl data=data/test.txt log=log/test.log bad=bad/test.bad
同样的功能在MySQL中也有类似的实现。
MySQL中对应的语法是LOAD DATA。
一个注意项,需要修改MySQL的驱动配置,才能实现这个功能。以下是一个dbeaver的工具的实例。对应代码是url后面拼接&allowLoadLocalInfile=true
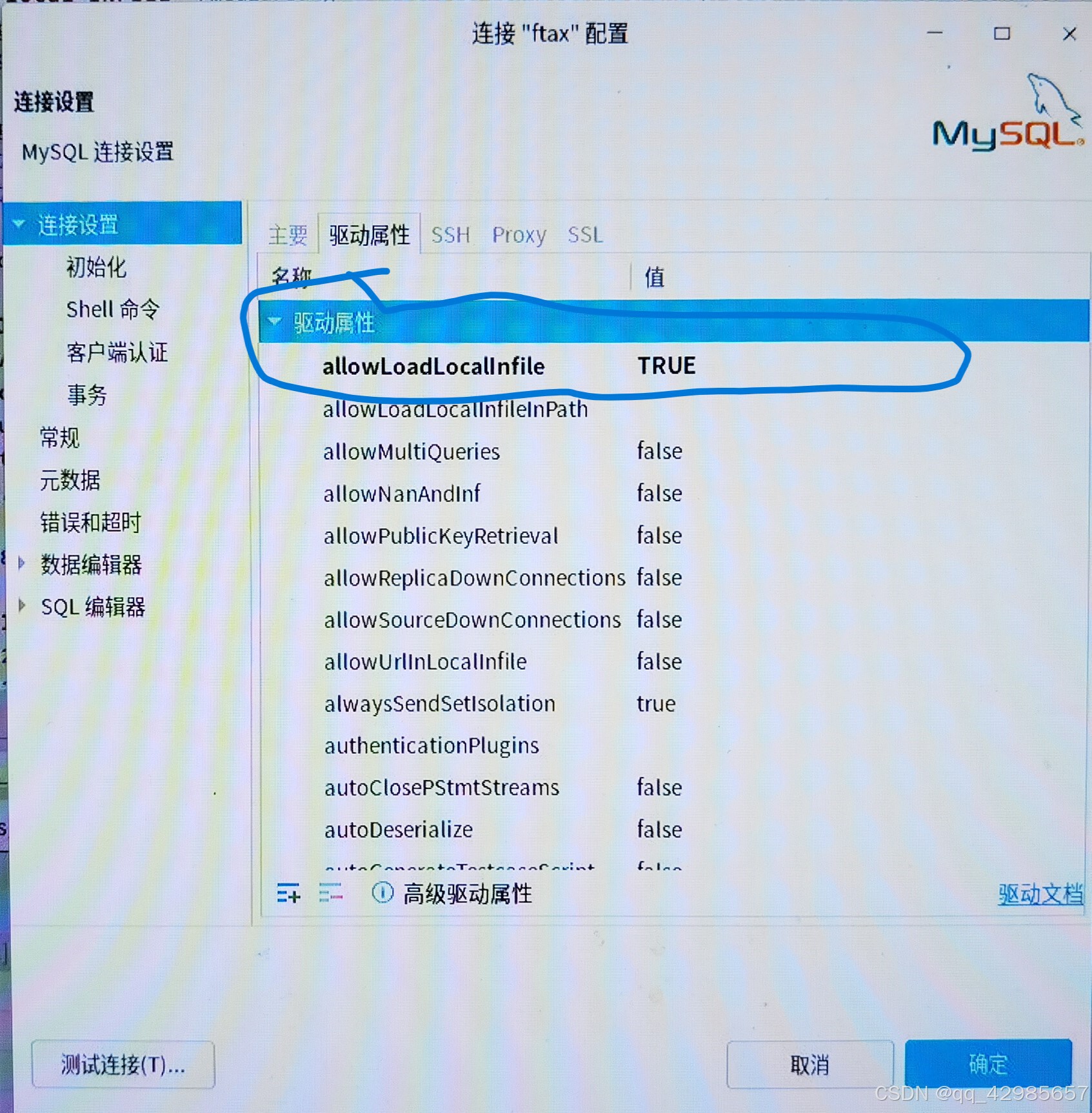
LOAD DATA [LOCAL] INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE table_name
[FIELDS TERMINATED BY 'string']
[OPTIONALLY ENCLOSED BY 'char']
[LINES TERMINATED BY 'string']
[IGNORE number LINES]
[(column_list)]
[SET column_name = expr, ...]
LOCAL:如果指定,文件将被解释为客户端主机上的文件。如果没有指定 LOCAL,文件必须位于服务器主机上,并且 MySQL 服务器必须有权限读取它。(重点)
REPLACE 或 IGNORE:可选的关键字,用于处理重复键错误。REPLACE 会删除现有行并插入新行,而 IGNORE 会跳过导致错误的行。
FIELDS TERMINATED BY:指定字段之间的分隔符。(重点)
OPTIONALLY ENCLOSED BY:指定字段值可能被包围的字符(如引号)。
LINES TERMINATED BY:指定行之间的分隔符。(重点)
IGNORE number LINES:跳过文件开头的指定数量的行。
(column_list):可选地指定要加载的列。如果省略,将加载所有列。
SET column_name = expr:允许在加载数据时计算列值。
写一个简单的示例是
LOAD DATA LOCAL INFILE 'home/tomcat/test.txt'
INTO TABLE test
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
(id, name, age, department);
用法其实不复杂。重点是问题的排查。在信创环境中数据文件中有1000行数据,但是LOAD DATA加载成功的可能只有500条。但是在程序运行的时候是很难输出错误信息的,如果发现表中的数据比数据文件中的数据少,可以尝试在dbeaver的SQL编辑器中执行相应的LOAD DATA语句,看输出窗体中的内容。
目前遇到的问题有:Oracle和MySQL的表结构不一样,导致数据不一致。重点排查是主键是设置是不是一样。遇到过由于主键设置的字段不一致,导致MySQL的表中少了很多数据。这种情况在代码中跑的时候没有报错的信息。这种是将语句放到dbeaver中执行从输出窗口输出的信息中排查出来的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











