









单调栈
单调栈代码模板 找下一个更大(不是大于等于)元素
vector<int> nextGreaterElement(vector<int>& nums) {
int n = nums.size();
vector<int> res(n, -1);
stack<int> s;
// 从后向前构建单调栈
for (int i = n - 1; i >= 0; i--) {
while (!s.empty() && nums[i] >= s.top()) {
// 来大哥了,小个子失去存在意义
s.pop();
}
// s不为空则说明找到了下一个大元素
res[i] = s.empty() ? -1 : s.top();
s.push(nums[i]);
}
return res;
}
注:这里的nums[i] >= s.top()表示来的元素如果大于等于栈顶元素,栈顶元素就失去意义了,就算相等也弹出,意思是必须找到严格大于当前元素。
- 改为
nums[i] > s.top()即找下一个大于等于当前元素。 - 改为
nums[i] <= s.top()即找下一个严格小于当前元素。 - 改为
nums[i] < s.top()即找下一个小于等于当前元素。
739. 每日温度 Medium 单调栈 2023/2/8
给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
示例:
输入: temperatures = [73,74,75,71,69,72,76,73]
输出: [1,1,4,2,1,1,0,0]
看到 下一个较大/小元素,一定为单调栈。
需要注意的是本题存入下标较为方便,且计算的是天数差。
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& temperatures) {
int n = temperatures.size();
vector<int> ans(n, 0);
stack<int> s;
// 从后向前构建单调栈
for (int i = n - 1; i >= 0; i--) {
while (!s.empty() && temperatures[i] >= temperatures[s.top()]) {
// 来大哥了,小个子失去存在意义
s.pop();
}
// s不为空则说明找到了下一个大元素
ans[i] = s.empty() ? 0 : (s.top() - i);
s.push(i);
}
return ans;
}
};
496. 下一个更大元素 I Easy 单调栈 2023/2/8
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。
对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。
返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素 。
示例:
输入:nums1 = [4,1,2], nums2 = [1,3,4,2].
输出:[-1,3,-1]
本题也是单调栈的经典例题,由于nums1是nums2的子集,且不存在重复元素,可以使用单调栈遍历一遍nums2得到每个元素的下个最大元素,并存在哈希表中,最后遍历一遍nums1取出哈希表的值。
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
stack<int> s; // 单调栈
unordered_map<int, int> m; // 哈希表用于快速查找
for (int i = nums2.size() - 1; i >= 0; i--) {
while (!s.empty() && nums2[i] >= s.top()) {
s.pop();
}
m[nums2[i]] = s.empty() ? -1 : s.top();
s.push(nums2[i]);
}
vector<int> res(nums1.size(), -1);
// 遍历nums1
for (int i = 0; i < nums1.size(); i++) {
res[i] = m[nums1[i]]; // 查找对应的下一个更大元素
}
return res;
}
};
503. 下一个更大元素 II Medium 单调栈 2023/2/9
给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是 nums[0] ),返回 nums 中每个元素的 下一个更大元素 。
数字 x 的 下一个更大的元素 是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1 。
示例:
输入: nums = [1,2,1]
输出: [2,-1,2]
解释: 第一个 1 的下一个更大的数是 2;
数字 2 找不到下一个更大的数;
第二个 1 的下一个最大的数需要循环搜索,结果也是 2。
本题与上一题相比,唯一的区别在于数组变为了循环数组,对于循环数组,常用的做法是数组扩展到两倍再进行操作,但会有O(n)的空间复杂度。
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
// 扩展数组到两倍
nums.insert(nums.end(), nums.begin(), nums.end());
vector<int> res(nums.size(), -1);
stack<int> s;
// 单调栈模板
for (int i = nums.size() - 1; i >= 0; i--) {
while (!s.empty() && s.top() <= nums[i]) {
s.pop();
}
res[i] = s.empty() ? -1 : s.top();
s.push(nums[i]);
}
// 删除后半段
res.erase(res.begin() + nums.size() / 2, res.end());
return res;
}
};
也可使用求模符号模拟构造双倍数组,i%n 从n-1到0 再从n-1到0,降低空间复杂度。
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
int n = nums.size();
vector<int> res(n, -1);
stack<int> s;
// 假装这个数组长度翻倍 i%n 从n-1到0 再从n-1到0
for (int i = 2 * n - 1; i >= 0; i--) {
while (!s.empty() && s.top() <= nums[i % n]) {
s.pop();
}
res[i % n] = s.empty() ? -1 : s.top();
s.push(nums[i % n]);
}
return res;
}
};
42. 接雨水 Hard 类单调栈 2023/2/9
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例:
输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
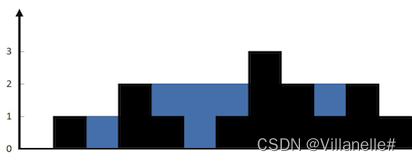
单调栈适用于解 下一个最大元素,本题可以利用单调栈的思想,构建递增单调栈(存下标),从后向前遍历,若
- 栈里有值,且当前元素大于等于栈顶元素 则 栈顶元素出栈,作为低洼区域,并记录好下标,再次判定栈里有没有值
- 若没值,则无事发生
- 若有值,计算w和h填平该低洼区域
- 栈里没值或当前元素小于栈顶元素 则 无事发生
最后无论什么情况当前元素都要入栈,始终保持栈的单调递增性
class Solution {
public:
int trap(vector<int>& height) {
stack<int> s;
int rain = 0;
// 递增单调栈
for (int i = height.size() - 1; i >= 0; i--) {
while (!s.empty() && height[s.top()] <= height[i]) {
int lowIndex = s.top(); // 得到低洼区下标
s.pop();
// 栈里还有值,说明低洼区是一个水塘,填平
if (!s.empty()) {
int h = min(height[i], height[s.top()]) - height[lowIndex]; // 高
int w = s.top() - i - 1; // 宽
rain += h * w;
}
}
s.push(i);
}
return rain;
}
};
316. 去除重复字母 Hard 类单调栈 2023/2/9
给你一个字符串 s ,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证 返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
示例:
输入:s = “cbacdcbc”
输出:“acdb”
字典序的含义是从头开始比较两个字符串每个字符的ASCII码,如aac和aba,aac的字典序显然更小。
单调栈的终极难题——看出这题是个单调栈问题!
使用instack数组判断字母是否用过,避免字母重复出现。使用count数组判断字母是否用完,如果用完不得不用。使用单调栈维护字典序。
class Solution {
public:
string removeDuplicateLetters(string s) {
stack<char> stk;
bool instack[256] = {false};
int count[256] = {0};
for (char c: s) count[c]++;
for (char c: s) {
// 每遍历一个字符,对应计数-1
count[c]--;
// 该字符已经出现过了
if (instack[c]) continue;
// 违反字典序
while (!stk.empty() && stk.top() > c) {
// 不存在栈顶元素了,停止pop
if (count[stk.top()] == 0) break;
instack[stk.top()] = false;
stk.pop();
}
stk.push(c);
instack[c] = true;
}
string res;
while (!stk.empty()) {
res += stk.top();
stk.pop();
}
// 翻转
reverse(res.begin(), res.end());
return res;
}
};
剑指 Offer II 039.直方图最大矩形面积 Hard 单调栈 2023/3/3
给定非负整数数组 heights ,数组中的数字用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例:
输入:heights = [2,1,5,6,2,3]
输出:10
解释:最大的矩形为图中红色区域,面积为 10
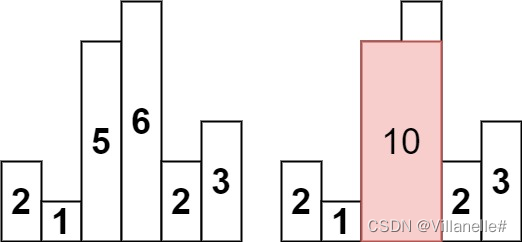
使用双指针和滑动窗口显然不行。可以对于每个下标,找到下一个更小元素的下标和上一个更小元素的下标,并进行相减再乘上当前元素的高,即为以当前元素为高的最大矩形面积。如何找到下一个更小元素?单调栈!
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
int len = heights.size();
stack<int> s_next, s_prev;
vector<int> v_next(len, -1), v_prev(len, -1);
// 下一个更小元素的下标
for (int i = len - 1; i >= 0; i--) {
while (!s_next.empty() && heights[s_next.top()] >= heights[i])
s_next.pop();
v_next[i] = s_next.empty() ? len : s_next.top(); // 如果没找到,说明当前元素最矮,为最右边的柱子的右边一个
s_next.push(i);
}
// 上一个更小元素的下标
for (int i = 0; i < len; i++) {
while (!s_prev.empty() && heights[s_prev.top()] >= heights[i])
s_prev.pop();
v_prev[i] = s_prev.empty() ? -1 : s_prev.top(); // 如果没找到,说明当前元素最矮,为最左边的柱子的左边一个
s_prev.push(i);
}
int res = 0;
// 面积等于 (下一个更小元素的下标 - 上一个更小元素的下标 - 1) * 当前柱子高度
for (int i = 0; i < len; i++) {
int area = (v_next[i] - v_prev[i] - 1) * heights[i];
res = max(res, area);
}
return res;
}
};
剑指 Offer II 040.矩阵中最大的矩形 Hard 单调栈 2023/3/3
给定一个由 0 和 1 组成的矩阵 matrix ,找出只包含 1 的最大矩形,并返回其面积。
注意:此题 matrix 输入格式为一维 01 字符串数组。
示例:
输入:matrix = [“10100”,“10111”,“11111”,“10010”]
输出:6
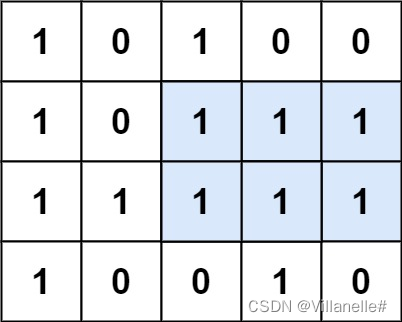
本题看似与上题毫无关联,其实可以看作上题的升级版!
将每一行视作一排柱子,如果下一行对应的列为1则叠加,为0则清空。找柱子面积直接使用上题单调栈即可。
1
,
0
,
0
,
1
,
0
1,0,0,1,0
1,0,0,1,0
2
,
1
,
1
,
2
,
1
2,1,1,2,1
2,1,1,2,1
3
,
0
,
2
,
3
,
2
3,0,2,3,2
3,0,2,3,2
4
,
0
,
3
,
0
,
0
4,0,3,0,0
4,0,3,0,0
class Solution {
public:
int maximalRectangle(vector<string>& matrix) {
if (matrix.empty()) return 0;
int rows = matrix.size();
int cols = matrix[0].size();
vector<int> cur_rows(cols, 0);
int res = 0;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (matrix[i][j] == '0')
cur_rows[j] = 0;
else cur_rows[j] += 1;
}
res = max(largestRectangleArea(cur_rows), res);
}
return res;
}
int largestRectangleArea(vector<int>& heights) {...}
};
单调队列
单调队列(递减)代码模板 始终维护当前队列最大值
包括放数、取最大值、删数方法
class MonotonicQueue {
public:
deque<int> data;
void push(int n) {
// 把队尾小于n的元素都删掉,保证队列单调递减
while (!data.empty() && data.back() < n) {
data.pop_back();
}
data.push_back(n);
}
int max() {
// 返回队首元素,即最大值
return data.front();
}
void pop(int n) {
// 如果队首元素等于n,就删掉
if (!data.empty() && data.front() == n) {
data.pop_front();
}
}
};
239. 滑动窗口最大值 Hard 单调队列 2023/2/9
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
示例:
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
按照单调队列逻辑,每次把元素放进去再删掉旧元素。
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MonotonicQueue window;
// 先把前k个元素放进去
for (int i = 0; i < k; i++) {
window.push(nums[i]);
}
vector<int> res = {window.max()};
for (int i = k; i < nums.size(); i++) {
// 把新元素放进去
window.push(nums[i]);
// 删掉旧元素,保证窗口大小为k
window.pop(nums[i - k]);
// 把当前窗口的最大值放进结果数组
res.push_back(window.max());
}
return res;
}
};
面试题59 - II. 队列的最大值 Medium 单调队列 2023/2/10
请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数max_value、push_back 和 pop_front 的均摊时间复杂度都是O(1)。
若队列为空,pop_front 和 max_value 需要返回 -1
示例:
输入:
[“MaxQueue”,“push_back”,“push_back”,“max_value”,“pop_front”,“max_value”]
[[],[1],[2],[],[],[]]
输出: [null,null,null,2,1,2]
本题与代码模板相比,唯一的区别在于pop时还需要输出队列首的元素,因此需要额外使用一个队列q维护。
- 在push时q也跟着push。
- 在pop时pop队列q首元素,如果恰好等于双端数组d首元素,则pop掉。
class MaxQueue {
queue<int> q; // 用于pop
deque<int> d;
public:
MaxQueue() {}
int max_value() {
return d.empty() ? -1 : d.front();
}
void push_back(int value) {
// d前面的小元素都没用了
while (!d.empty() && d.back() < value) {
d.pop_back();
}
d.push_back(value);
q.push(value);
}
int pop_front() {
if (q.empty())
return -1;
int ans = q.front();
if (ans == d.front()) {
d.pop_front();
}
q.pop();
return ans;
}
};
变长数组+哈希表 实现 O ( 1 ) O(1) O(1) 随机存取
剑指 Offer II 030.插入、删除和随机访问都是 O(1) 的容器 Medium 变长数组 哈希表 随机数 2023/2/26
设计一个支持在平均 时间复杂度 O(1) 下,执行以下操作的数据结构:
insert(val):当元素 val 不存在时返回 true ,并向集合中插入该项,否则返回 false 。
remove(val):当元素 val 存在时返回 true ,并从集合中移除该项,否则返回 false 。
getRandom:随机返回现有集合中的一项。每个元素应该有 相同的概率 被返回。
变长数组可以在 O ( 1 ) O(1) O(1) 的时间内完成随机访问元素操作,但是由于无法在 O ( 1 ) O(1) O(1) 的时间内判断元素是否存在,因此不能在 O ( 1 ) O(1) O(1) 的时间内完成插入和删除操作。哈希表可以在 O ( 1 ) O(1) O(1) 的时间内完成插入和删除操作,但是由于无法根据下标定位到特定元素,因此不能在 O ( 1 ) O(1) O(1) 的时间内完成随机访问元素操作。为了满足插入、删除和随机访问元素操作的时间复杂度都是 O ( 1 ) O(1) O(1) ,需要将变长数组和哈希表结合,变长数组中存储元素,哈希表中存储每个元素在变长数组中的下标。
class RandomizedSet {
public:
RandomizedSet() {
// 设置随机数种子
srand((unsigned)time(NULL));
}
bool insert(int val) {
if (indices.count(val)) return false;
int index = nums.size();
nums.emplace_back(val);
indices[val] = index;
return true;
}
bool remove(int val) {
if (!indices.count(val)) return false;
int index = indices[val];
int last = nums.back();
// 用最后一个元素替换对应数组元素
nums[index] = last;
indices[last] = index;
nums.pop_back();
indices.erase(val);
return true;
}
int getRandom() {
int randomIndex = rand() % nums.size();
return nums[randomIndex];
}
private:
vector<int> nums; // 变长数组
unordered_map<int, int> indices; // 哈希表(键:元素值,值:对应变长数组的元素下标)
};
另一种方法,使用了*next方法,可以根据下标定位到特定元素(投机取巧?)直接使用一个unordered_set即可。
class RandomizedSet {
public:
unordered_set<int> s;
RandomizedSet() {
srand((unsigned)time(NULL));
}
bool insert(int val) {
if (s.find(val) != s.end()) return false;
s.insert(val); return true;
}
bool remove(int val) {
if (s.find(val) == s.end()) return false;
s.erase(val); return true;
}
int getRandom() {
int randomIndex = rand() % s.size();
return *next(s.begin(), randomIndex);
}
};
优先队列(大/小 堆)
优先队列priority_queue也是STL中的一种容器适配器,其底层实现是堆,以二叉树为基础。
采用堆这样的数据结构,可以保证第一个元素总是整个优先队列中**最大的(或最小的)**元素。默认使用vector作为底层存储数据的容器。
优先队列用法
参数理解
模板参数列表template <class T, class Container = vector<T>, class Compare = less<typename Container::value_type> >
class T优先队列中存储元素的类型,如存储整形元素为int,存储对组为pair<int, int>。class Container = vector<T>优先队列底层使用的数据结构,默认采用vector,里面的T要与第一个参数一致。class Compare优先队列元素的比较方式类,默认为less,即大堆。
优先队列元素的比较方式决定了是大堆还是小堆,例如大堆每个结点的值都不大于其父节点,堆顶元素最大。
编译器中的比较类std::less<> std::greater<>只能比较内置类型,自定义类的比较方式必须用户自己给出,通常使用仿函数实现。
std::less<> std::greater<>的内部实现:
template <class T>
struct less : binary_function <T,T,bool> {
bool operator() (const T& x, const T& y) const {return x<y;}
};
template <class T>
struct greater : binary_function <T,T,bool> {
bool operator() (const T& x, const T& y) const {return x>y;}
};
为什么less是大堆?
C++的优先队列是优先级高的在队首,定义优先级大小的方式是传入一个算子的参数比较a, b两个东西,返回true则a的优先级<b的优先级。默认是less算子也就是返回a<b,也就是小的优先级也小,而greater算子返回a>b,小的优先级高。
如果是默认的less算子,值大的优先级高,值大的排到了队头,优先队列大的先出队。
常用方法
T top()返回队首,即优先级大的empty()同常用容器size()同常用容器push(T t)元素入队pop()元素出队
存储自定义数据类型的写法
如剑指 Offer II 060中要求构造的小堆,存储的数据类型为pair<int, int>型,且需按照其second构建小堆,仿照less构建:
两个const一个都不能少!
class MyGreater {
public:
bool operator()(const pair<int, int>& p1, const pair<int, int>& p2) const {
return p1.second > p2.second;
}
};
...
priority_queue<pair<int, int>, vector<pair<int, int>>, MyGreater> q;
解题时,往往使用小堆和大堆都可以,且一种比另一种的写法更为方便,但有时另一种的时间复杂度会略低一些。
剑指 Offer II 060.出现频率最高的 k 个数字 Medium 优先队列 2023/3/12
给定一个整数数组 nums 和一个整数 k ,请返回其中出现频率前 k 高的元素。可以按 任意顺序 返回答案。
示例:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
统计元素出现频次使用unordered_map,统计完后遍历时插入优先队列,但是这里应该使用小堆还是大堆呢?
- 如使用大堆,即先将map中元素全部插入优先队列,再pop出前k个元素即可,其时间复杂度为 O ( l o g n ) O(logn) O(logn)。
- 如使用小堆,即先把k个元素入队,对于接下来的元素,比较队首元素和该元素,若遍历的元素较大,则队首元素出队,该元素入队,否则无事发生,时间复杂度为
O
(
l
o
g
k
)
O(logk)
O(logk)。最后把队列中的元素逐一放进
vector中。
这里使用小堆。
// 小堆仿函数
class MyGreater {
public:
bool operator()(const pair<int, int>& p1, const pair<int, int>& p2) const {
return p1.second > p2.second;
}
};
class Solution {
public:
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int> mp;
priority_queue<pair<int, int>, vector<pair<int, int>>, MyGreater> q;
vector<int> res;
for (int num: nums) mp[num]++;
for (auto it: mp) {
if (q.size() < k) q.push(it);
else if (MyGreater()(it, q.top())) {
q.pop();
q.push(it);
}
}
for (int i = 0; i < k; i++) {
res.push_back(q.top().first);
q.pop();
}
return res;
}
};
剑指 Offer II 061.和最小的 k 个数对 Medium 优先队列 2023/3/12
给定两个以升序排列的整数数组 nums1 和 nums2 , 以及一个整数 k 。
定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2 。
请找到和最小的 k 个数对 (u1,v1), (u2,v2) … (uk,vk) 。
示例:
输入: nums1 = [1,7,11], nums2 = [2,4,6], k = 3
输出: [1,2],[1,4],[1,6]
解释: 返回序列中的前 3 对数:
[1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6]
本题显然使用两层for循环遍历,并将其二元vector入队,使用小根堆还是大跟对与上题的思路类似,使用小堆的写法较为简洁,但时间复杂度较高,这里使用大根堆。
// 大堆仿函数
class MyLess {
public:
bool operator()(const vector<int>& v1, const vector<int>& v2) const {
return v1[0] + v1[1] < v2[0] + v2[1];
}
};
class Solution {
public:
vector<vector<int>> kSmallestPairs(vector<int>& nums1, vector<int>& nums2, int k) {
priority_queue<vector<int>, vector<vector<int>>, MyLess> q;
vector<vector<int>> res;
for (int num1: nums1)
for (int num2: nums2) {
if (q.size() < k) q.push({num1, num2});
else if (MyLess()({num1, num2}, q.top())) {
q.pop();
q.push({num1, num2});
}
}
while (k > 0 && !q.empty()) {
res.push_back(q.top());
q.pop();
k--;
}
return res;
}
};
前缀树
前缀树代码模板 查找单词前缀
这里参考了文章,实现了常用的插入单词、查找结点、查找单词、查找最短和最长前缀等方法。
// 前缀树叶子结点
class TrieNode {
public:
bool isWord; // 是否是单词
TrieNode* children[26]; // 索引表示对应字母
TrieNode() {
isWord = false;
for (int i = 0; i < 26; i++) {
children[i] = nullptr;
}
}
};
// 前缀树
class TrieMap {
public:
TrieNode* root; // 根结点
TrieMap() {
root = new TrieNode();
}
// 插入单词
void insert(string word) {
TrieNode* node = root;
for (char c : word) {
if (node->children[c - 'a'] == nullptr) {
node->children[c - 'a'] = new TrieNode();
}
node = node->children[c - 'a'];
}
node->isWord = true;
}
// 根据单词查找结点,如果不存在返回nullptr
TrieNode* getNode(string word) {
TrieNode* node = root;
for (char c : word) {
if (node->children[c - 'a'] == nullptr) {
return nullptr;
}
node = node->children[c - 'a'];
}
return node;
}
// 查找单词是否存在
bool get(string word) {
return getNode(word) != nullptr && getNode(word)->isWord;
}
// 查找是否存在以prefix为前缀的单词
bool hasKeyWithPrefix(string prefix) {
return getNode(prefix) != nullptr;
}
// 查找单词的最短前缀,该前缀必须是一个单词
string shortestPrefixOf(string word) {
TrieNode* node = root;
string prefix = "";
for (char c : word) {
if (node->children[c - 'a'] == nullptr) {
return "";
}
prefix += c;
node = node->children[c - 'a'];
if (node->isWord) {
return prefix;
}
}
return "";
}
// 查找单词的最长前缀,该前缀不需要是一个完整的单词
string longestPrefixOf(string word) {
TrieNode* node = root;
string prefix = "";
for (char c : word) {
if (node->children[c - 'a'] == nullptr) {
return prefix;
}
prefix += c;
node = node->children[c - 'a'];
}
return prefix;
}
};
剑指 Offer II 063.替换单词 Medium 前缀树 2023/3/23
在英语中,有一个叫做 词根(root) 的概念,它可以跟着其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典和一个句子,需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
示例:
输入:dictionary = [“cat”,“bat”,“rat”], sentence = “the cattle was rattled by the battery”
输出:“the cat was rat by the bat”
套用上述模板,调用shortestPrefixOf方法即可快速找出最短前缀。
string replaceWords(vector<string>& dictionary, string sentence) {
TrieMap tm;
for (string word: dictionary) tm.insert(word);
string str;
string res;
sentence += ' ';
for (char c: sentence) {
if (c == ' ') {
string prefix = tm.shortestPrefixOf(str);
if (prefix != "") res += prefix;
else res += str;
res += ' ';
str.clear();
}
else str += c;
}
res.erase(res.size() - 1);
return res;
}
















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









