









Hadoop-离线批处理技术

作者 | WenasWei
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。充分利用集群的威力进行高速运算和存储。
Hadoop的框架最核心的设计就是:HDFS1和MapReduce2。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Apache Hadoop软件库是一个框架,该框架允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。库本身不依赖于硬件来提供高可用性,而是被设计用来检测和处理应用程序层的故障,因此可以在计算机集群的顶部提供高可用性服务,每台计算机都容易出现故障。
Hadoop 是一个能够对大量数据进行分布式处理的软件框架, 支持C++,Java开发语言,其带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。
2.1 Hadoop的优点
- 1.高可靠性: Hadoop按位存储和处理数据的能力值得人们信赖, 假设计算元素和存储会失败,它维护的多个工作数据副本,确保能够针对失败的节点重新分布处理。
- 2.高扩展性: Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 3.高效性: Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快,且并行的方式工作,通过并行处理加快处理速度。
- 4.高容错性: Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 5.低成本:与一体机、商用数据仓库以及其他的数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
2.2 Hadoop的缺点
- 1、不能做到低延迟: 高数据吞吐量做了优化,牺牲了获取数据的延迟。
- 2、不适合大量的小文件存储。
- 3、文件修改效率低: 不支持任意修改文件和不支持多人同时进行写操作, HDFS 适合一次写入,多次读取的场景。
Hadoop 已经不只是一个大数据框架,它逐渐演化成为 Hadoop 生态系统。Hadoop 生态系统中涵盖
了各种各样的大数据处理技术,包括Hadoop、Storm、Spark、Hive、Zookeeper、Flume、Kafka等一系列技术和框架,已然成为大数据处理的事实标准。
Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储数据,对例如像 ETL3 这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop 的 MapReduce 功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
hadoop主要的功能就是用来处理大数据:
- 首先,大数据可以对顾客群体细分然后对每个群体量体裁衣般的采取独特的行动。
- 第二点,运用大数据模拟实境,发掘新的需求和提高投入的回报率。现在越来越多的产品中都装有传感器,汽车和智能手机的普及使得可收集数据呈现爆炸性增长。
- 第三点,提高大数据成果在各相关部门的分享程度,提高整个管理链条和产业链条的投入回报率。大数据能力强的部门可以通过云计算、互联网和内部搜索引擎把大数据成果和大数据能力比较薄弱的部门分享,帮助他们利用大数据创造商业价值。
- 第四点,进行商业模式产品和服务的创新。大数据技术使公司可以加强已有的产品和服务,创造新的产品和服务,甚至打造出全新的商业模式。
4.1 Hadoop的核心组件
Hadoop的核心组件分别是:
- MapReduce: 分布式计算框架
- HDFS:hadoop的数据存储工具
- YARN4:Hadoop 的资源管理器
- Common 工具: 封装的一些常用底层工具

(1) MapReduce-分布式计算框架
MapReduce 编程模型借鉴了 “分而治之” 的思想,将一个大而复杂的计算问题分解成多个小的计算问题,由多个map()函
数对这些分解后的小问题进行并行计算,输出中间计算结果,然后由 reduce() 函数对 map() 函数的输出结果进行进一步合并,得出最终的计算结果。
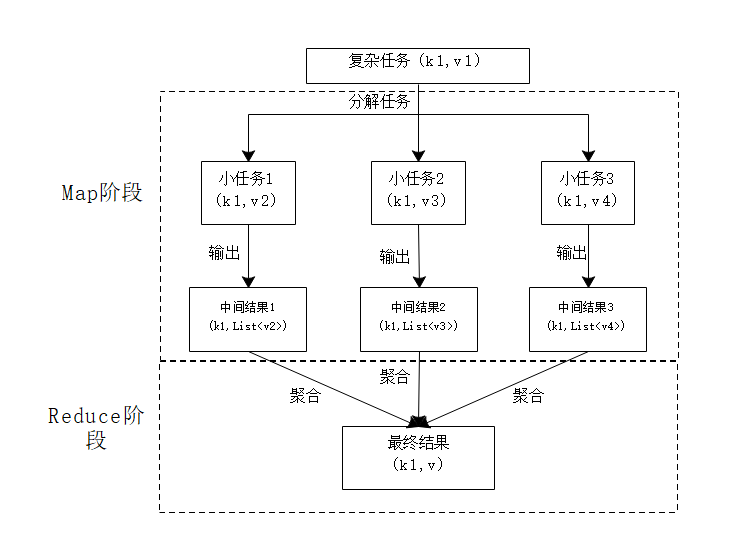
- 注: 一篇详细MapReduce介绍: 跳转链接
(2) HDFS-数据存储工具
Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。而且是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。
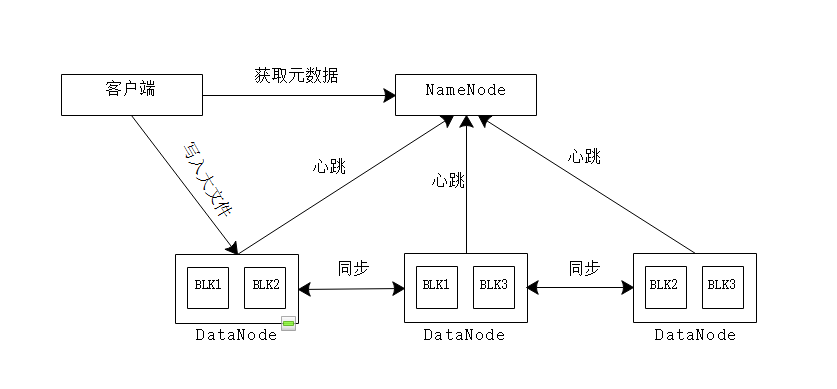
HDFS采用master/slave架构, 即主从模式。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
(3) YARN-资源管理器
YARN-资源调度框架是从Hadoop2.0版本开始引入的, 引入之前, MapReduce框架的核心 Job Tracker(作业跟踪者), JobTracker 需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作,还需要和数据元数据中心通讯,了解数据分布等等, 既当爹又当妈的意思,即既做资源管理又做任务调度/监控。Task Tracker资源划分过粗放,二大部分工作是可以高度一致的监控任务。
Job Tracker 存在的问题:
- 单点故障: 依旧是单点故障问题,如果JobTracker挂掉了会导致MapReduce作业无法执行
- 资源浪费: JobTracker完成了太多的任务,造成了过多的资源消耗,当map-reduce job非常多的时候,会造成很大的内存开销,潜在来说,也增加了JobTracker失效的风险,这也是业界普遍总结出老Hadoop的Map-Reduce只能支持4000节点主机的上限
- 局限性: 只支持简单的MapReduce编程模型, 要使用Hadoop进行编程的话只能使用基础的MapReduce,而无法使用诸如 Spark 这些计算模型。并且它也不支持流式计算和实时计算
YARN 框架中将 JobTracker 资源分配和作业控制分开,分为 Resource Manager(RM) 以及 Application Master(AM)。
资源调度管理器最核心是
- 管理集群资源,原则上可以包括任何硬件资源,当前 YARN 管理粒度是 CPU 和内存——解决物理资源透明化
- 基于资源情况和任务进行状态,调度任务队列——解决并发任务调度透明化
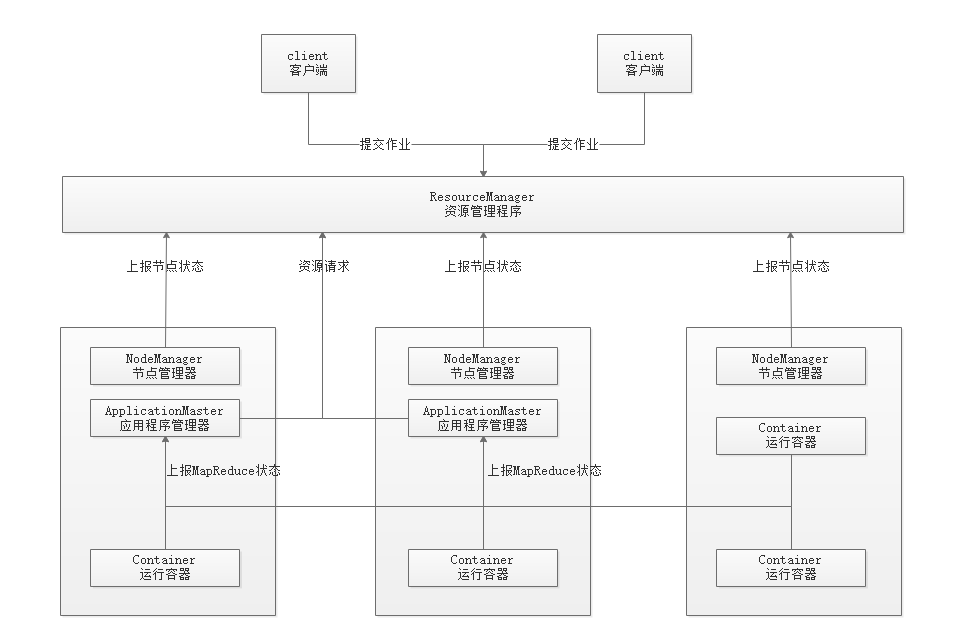
Yarn的主要组件如下:
-
Resource Manager:ResourceManager包含两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
-
定时调度器(Scheduler):定时调度器负责向应用程序分配资源,它不做监控以及应用程序的状态跟踪,并且它不保证会重启由于应用程序本身或硬件出错而执行失败的应用程序。
-
应用管理器(ApplicationManager):应用程序管理器负责接收新任务,协调并提供在ApplicationMaster容器失败时的重启功能。
-
-
Application Master:每个应用程序的ApplicationMaster负责从Scheduler申请资源,以及跟踪这些资源的使用情况以及任务进度的监控。
-
Node Manager:NodeManager是ResourceManager在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向ResourceManager/Scheduler提供这些资源使用报告。
-
Contain: 为资源申请和任务运行的容器, 会向 Application Master 上报 MapReduce 状态。
Yarn框架作为一个通用的资源调度和管理模块,同时支持多种其他的编程模型,比如最出名的Spark。
(4) Common-底层工具
Hadoop 的 Common 工作理解起来比较简单, 就是封装了一些常用的底层工具,供其他
Hadoop 模块使用。其主要包括配置工具 Configuration、 远程过程调用(Remote Procedure
Cal.RPC)、序列化工具和 Hadoop 的抽象文件系统工具 FileSystem 等,为其他 Hadoop 模块的运行提供基本服务,并为开 发Hadoop 程序提供了必要的 API。
4.2 Hadoop的物理架构
Hadoop 在物理架构上会采用 Master/Slave模式。NameNode 服务器存放集群的元数据信息,负责整个数据集群的管理。DataNode 分布在不同的物理机架上,保存具体的数据块并定期向 NameNode 发送存储的数据块信息,以心跳的方式告知 NameNode。客户端与 Hadoop 交互时,首先要向 NameNode 获取元数据信息,根据 NameNode 返回的元数据信息,到具体的 DataNode 服务器上获取数据或写入数据。
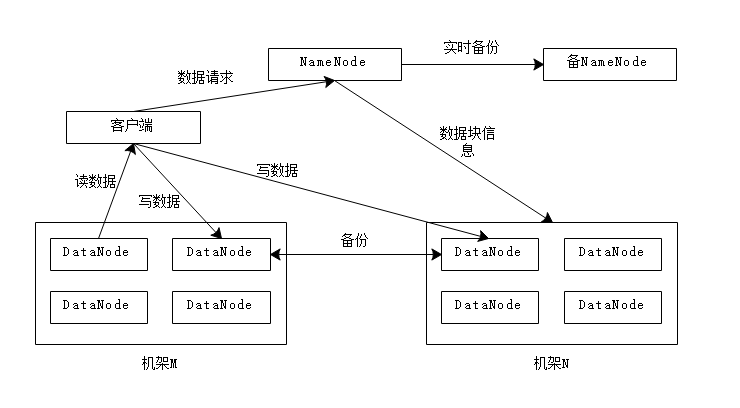
Hadoop 提供了默认的副本存放策略,每个 DataNode 默认保存了3个副本,其中2个副本会保存在同一个机架的不同节点,另一个副本会保存在不同机架的节点上。
参考文档:
- [1] apache.hadoop官网: http://hadoop.apache.org
- [2] GitHub地址: https://github.com/apache/hadoop
- [3] 冰河 . 海量数据处理与大数据技术实战 [M] . 第1版 . 北京: 北京大学出版社 , 2020-09
- [4] zzzzMing . Hadoop1.0 和 Hadoop 2.0 的区别 . 博客园 . https://www.cnblogs.com/listenfwind/p/10121817.html , 2018-12-25
- [5] WaveVector
. 分布式资源管理器YARN简介(一) . CSDN . https://blog.csdn.net/wendingzhulu/article/details/78826132 , 2017-12-17















 3838
3838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









