







 本文介绍了层次分析法在确定评价指标权重后,如何使用Topsis法(逼近理想解排序法)进行决策,通过引入理想解和负理想解,计算方案的贴近度来选择最优选项。给出了一个实际应用案例和Python代码示例,展示了如何对研究生院评价进行量化分析。
本文介绍了层次分析法在确定评价指标权重后,如何使用Topsis法(逼近理想解排序法)进行决策,通过引入理想解和负理想解,计算方案的贴近度来选择最优选项。给出了一个实际应用案例和Python代码示例,展示了如何对研究生院评价进行量化分析。
引入
生活中的评价问题
层次分析法通过确定各指标的权重,来进行打分,但决策层不能太多,且判断矩阵的构造相对主观。
依然从一个例子入手,现在仍然是从A,B,C三物中选择最佳的一个,其评价指标如下表。
| 物品 | 因素1(越大越优) | 因素2(越小越优) |
| A | 9 | 10 |
| B | 8 | 7 |
| C | 6 | 3 |
我们考虑一下最理想的组合情况(9,3)以及最不理想的组合情况(6,10)
然后把总共5个点在图上画出来:(左上角是最劣,右下角是最优)
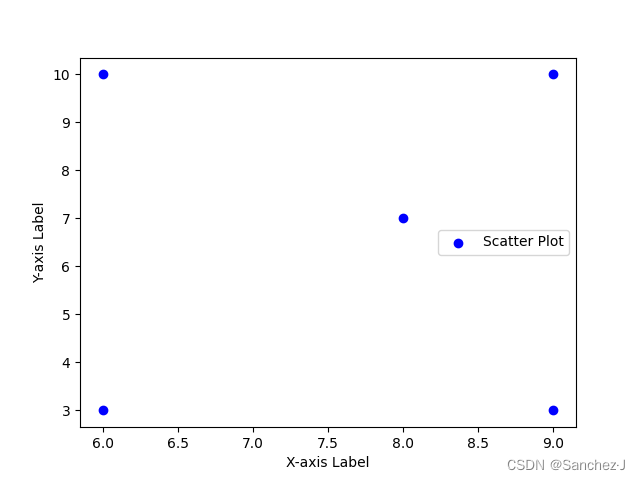
那么我们现在实际上可以通过距离来衡量优劣,也就是距离最优点最近或者距离最劣点最远的点就是我们要选择的点。
Topsis法
可翻译为逼近理想解排序法,或称优劣解距离法。
引入了理想解和负理想解,我们的方案就是选出最接近理想解、最原理负理想解的来确定最优选择。
对于结果,用贴近度来评价
基本步骤
- 将原始矩阵正向化:就是要把所有指标类型统一化为极大型指标(即越大越好的指标)
- 正向矩阵标准化:目的在于去除量纲的影响,保证各指标在同一数量级。标准化之后,还需给不同指标加上权重,这里就可以用上层次分析法。
- 计算得分并归一化:
,
是得分,
和
是评价对象与最大值、最小值的距离。
Python代码
import numpy as np
import pandas as pd
# TOPSIS方法函数
def Topsis(A1):
W0 = [0.2, 0.3, 0.4, 0.1]
# 权重矩阵
W = np.ones([A1.shape[1], A1.shape[1]], float)
# 创建了一个形状为 (A1 的列数, A1 的列数) 的全 1 矩阵,该矩阵将用于构建加权矩阵。
for i in range(len(W)):
for j in range(len(W)):
if i == j:
W[i, j] = W0[j]
# 如果当前元素的行索引和列索引相等,将加权矩阵中的该位置元素设为对应的权重值。
else:
W[i, j] = 0
Z = np.ones([A1.shape[0], A1.shape[1]], float)
# 创建了一个形状为 (A1 的行数, A1 的列数) 的全 1 矩阵,该矩阵将用于存储加权后的矩阵。
Z = np.dot(A1, W) # 加权矩阵
# 通过矩阵乘法,将输入矩阵 A1 与加权矩阵 W 相乘,得到加权后的矩阵 Z。每一行代表一个样本,每一列代表一个指标,元素值表示加权后的指标值。
# 计算正、负理想解
Zmax = np.ones([1, A1.shape[1]], float)
Zmin = np.ones([1, A1.shape[1]], float)
for j in range(A1.shape[1]):
if j == 3:
Zmax[0, j] = min(Z[:, j])
Zmin[0, j] = max(Z[:, j])
else:
Zmax[0, j] = max(Z[:, j])
Zmin[0, j] = min(Z[:, j])
# 计算各个方案的相对贴近度C
C = []
for i in range(A1.shape[0]):
Smax = np.sqrt(np.sum(np.square(Z[i, :] - Zmax[0, :])))
Smin = np.sqrt(np.sum(np.square(Z[i, :] - Zmin[0, :])))
C.append(Smin / (Smax + Smin))
C = pd.DataFrame(C, index=['院校' + i for i in list('12345')])
return C
# 标准化处理
def standard(A):
# 效益型指标
A1 = np.ones([A.shape[0], A.shape[1]], float)
for i in range(A.shape[1]):
if i == 0 or i == 2:
if max(A[:, i]) == min(A[:, i]):
A1[:, i] = 1
else:
for j in range(A.shape[0]):
A1[j, i] = (A[j, i] - min(A[:, i])) / (max(A[:, i]) - min(A[:, i]))
# 成本型指标
elif i == 3:
if max(A[:, i]) == min(A[:, i]):
A1[:, i] = 1
else:
for j in range(A.shape[0]):
A1[j, i] = (max(A[:, i]) - A[j, i]) / (max(A[:, i]) - min(A[:, i]))
# 区间型指标
else:
a, b, lb, ub = 5, 6, 2, 12
for j in range(A.shape[0]):
if lb <= A[j, i] < a:
A1[j, i] = (A[j, i] - lb) / (a - lb)
elif a <= A[j, i] < b:
A1[j, i] = 1
elif b <= A[j, i] <= ub:
A1[j, i] = (ub - A[j, i]) / (ub - b)
else: # A[i,:]< lb or A[i,:]>ub
A1[j, i] = 0
return A1
# 读取初始矩阵并计算
def data(file_path):
data = pd.read_csv(file_path).values
# print(data)
A = data[:, 2:]
# print(A)
A = np.array(A)
# m,n=A.shape[0],A.shape[1]
# m表示行数,n表示列数
return A
# 权重
A = data('data.csv')
# print(A)
A1 = standard(A)
# print(A1)
C = Topsis(A1)
print(C)
附:生成所用数据文件的代码
import pandas as pd
import numpy as np
df = pd.DataFrame({
'研究生院': [1, 2, 3, 4, 5],
'人均专著/(本/人)': [0.1, 0.2, 0.4, 0.9, 1.2],
'生师比': [5, 6, 7, 10, 2],
'科研经费/(万/年)': [5000, 6000, 7000, 10000, 400],
'人均专著/%': [4.7, 5.6, 6.7, 2.3, 1.8],
})
df.to_csv('data.csv')















 5387
5387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









