






1、@RestController @Controller相同点和不同点
@RestController和@Controller是Spring MVC中用于创建web控制器的两个核心注解,它们在定义控制器时有着不同的用途和行为。以下是它们的主要相似之处和区别:
相同点
- 组件扫描:两者都会被 Spring 的组件扫描机制识别,这意味着当你在类上使用这些注解时,Spring 会在启动时自动注册这些类作为 Spring 应用上下文中的 Bean。
- 请求映射:两者都可以配合
@RequestMapping或其派生的注解(如@GetMapping,@PostMapping等)来处理特定的HTTP请求。 - 依赖注入:都可以利用Spring的依赖注入特性,比如通过
@Autowired注入所需的依赖。
不同点
- 响应体处理:
@RestController是@Controller和@ResponseBody注解的组合。在@RestController中,每个方法都隐含地定义为返回一个响应体,这意味着它会自动进行消息转换。而在@Controller注解中,你需要指定@ResponseBody来表明方法的返回结果应该直接写入HTTP响应体中,而不是被解析为跳转路径。 - 用途:
@Controller通常用于传统的MVC控制器,其中方法返回的是视图名称(例如JSP页面的路径),而视图负责渲染模型数据。@RestController用于创建RESTful控制器,它返回的对象数据直接写入HTTP响应体,通常用于构建API。这意味着你通常不会从@RestController方法返回视图名称。
- 消息转换:由于
@RestController的方法默认加上了@ResponseBody,因此返回的对象会自动转换为JSON或XML等。在@Controller中,你需要指定@ResponseBody(或使用@RestControllerAdvice)来实现相同的效果。
源码级别的区别
@RestController的定义如下:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Controller
@ResponseBody
public @interface RestController {
@AliasFor(annotation = Controller.class)
String value() default "";
}
如你所见,@RestController内部标注了@Controller和@ResponseBody,这意味着它继承了这两个注解的特性。
而@Controller的定义如下:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Controller {
@AliasFor(annotation = Component.class)
String value() default "";
}
@Controller被标注为一个常规的组件,但没有指定返回值的处理方式,因此你需要使用@ResponseBody或返回一个视图名称。
总结
在Spring MVC中,你会根据应用的不同需求选择使用@Controller或@RestController。如果你正在构建一个HTML界面,可能会选择@Controller来返回视图。而如果你在构建一个服务于客户端如移动应用、前端框架(如React或Angular)的后端API,那么@RestController会是一个更好的选择,因为它默认返回JSON或XML响应。
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础
普通同步方法(实例方法),锁是当前实例对象 ,进入同步代码前要获得当前实例的锁
静态同步方法,锁是当前类的class对象 ,进入同步代码前要获得当前类对象的锁
同步方法块,锁是括号里面的对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
2、springboot starter机制
Spring Boot的Starter机制是其核心特性之一,旨在简化依赖管理和自动配置,以便快速启动和运行Spring应用程序。Starter依赖是预定义的依赖集合,这些集合帮助你在项目中包含所需的Spring及相关技术的库。
Starter的特点
- 依赖传递:每个Starter都是一个Maven项目,它包含了需要启动某个功能所需的依赖库。当你在项目中包含一个Starter时,这个Starter相关的依赖也会被传递性地添加到你的项目中。
- 自动配置:Spring Boot会利用Starter中包含的依赖来提供自动配置。这通常是通过
@Configuration类实现的,该类中定义了条件化的Bean声明,只有在特定条件满足时这些Bean才会被创建。 - 约定优于配置:使用Starter时,Spring Boot会提供一组默认配置,这些通常是基于约定的最佳实践。你可以通过在
application.properties或application.yml中设置属性来覆盖默认配置。
如何工作
当你在项目中添加了一个Starter依赖,并且启动你的Spring Boot应用程序时,以下是发生的事情:
- 依赖解析:Maven或Gradle会解析项目的依赖,并将Starter及其传递性依赖添加到类路径中。
- 启动引导:Spring Boot应用程序在启动时会创建一个
ApplicationContext,并且会查找类路径下的所有META-INF/spring.factories文件。 - 自动配置:
spring.factories文件中会列出一系列自动配置类,这些类使用@Configuration注释进行标注,并且通过@Conditional相关的注解进行条件化配置。 - 条件匹配:Spring Boot会根据环境(如类路径中的类、Bean的存在、属性值等)评估这些配置类的条件注解。
- Bean创建:如果条件匹配,相关的配置类会被实例化,并且将它们声明的Bean创建并注册到
ApplicationContext中。
Starter示例
Spring Boot提供了许多官方的Starters,例如:
- spring-boot-starter-web:用于构建Web应用程序,包括RESTful应用程序,使用Spring MVC。
- spring-boot-starter-data-jpa:包含Spring Data JPA和Hibernate等,用于数据库访问。
- spring-boot-starter-security:提供Spring Security支持,用于实现安全控制。
- spring-boot-starter-test:包含测试相关的库,如JUnit、Spring Test、AssertJ等。
创建自定义Starter
你也可以创建自己的Starter,步骤通常如下:
- 创建Maven项目:作为Starter的容器。
- 添加依赖:包含你希望Starter自动配置的库。
- 编写自动配置:使用
@Configuration类,并根据需要添加@Conditional注解。 - 定义
spring.factories:在META-INF/spring.factories文件中指定自动配置类。 - 打包和发布:将Starter打包成JAR文件,并将其发布到Maven仓库,以便其他人使用。
总结
Spring Boot的Starter提供了一个快速集成复杂技术栈的方式,通过预定义的依赖和自动配置,大幅简化了Spring应用程序的开发和配置过程。这些Starters遵循"约定优于配置"的原则,同时也提供了足够的灵活性来覆盖默认配置,以满足不同的业务需求。
SpringBootApplication
在Spring Boot应用程序中,@SpringBootApplication注解是一个方便的注解,它包含了@Configuration、@EnableAutoConfiguration和@ComponentScan注解的集合。这个注解提供了一种快速启动Spring应用程序的方法,它封装了多项功能,让我们一一来深入理解。
@Configuration
@Configuration注解表明该类使用Spring基于Java的配置。类中被@Bean标记的方法将被实例化为Spring容器中的Bean,并且配置依赖注入。
@EnableAutoConfiguration
@EnableAutoConfiguration告诉Spring Boot根据添加的jar依赖自动配置项目。例如,如果spring-boot-starter-web依赖是项目的一部分,那么Spring Boot会自动配置与Spring MVC相关的内容。这个注解是自动配置的关键,它让Spring Boot应用程序可以根据类路径下的类、Bean的定义以及各种属性设置来“猜测”你可能需要的配置。
@ComponentScan
@ComponentScan注解告诉Spring在包中查找其他组件、配置和服务,然后注册为Bean。默认情况下,它会扫描当前类所在的包和子包。
深入@EnableAutoConfiguration
@EnableAutoConfiguration的本质是根据类路径中的类和Spring Boot的各项配置来决策哪些配置是需要的。这个自动配置过程是通过spring.factories文件来实现的,它通常位于jar包的META-INF目录下。
Spring Boot会查找所有classpath中的META-INF/spring.factories文件,并读取其中org.springframework.boot.autoconfigure.EnableAutoConfiguration键下配置的值。这些值是自动配置类的全限定名,Spring Boot会创建这些类的实例,并执行相关的自动配置。
自动配置的条件化
Spring Boot的自动配置都是条件化的,即只有在特定条件满足时,相应的自动配置才会生效。这是通过@Conditional注解以及它的各种派生注解(如@ConditionalOnClass、@ConditionalOnMissingBean等)来实现的。这些注解可以结合使用,形成复杂的条件逻辑。
例如,DataSourceAutoConfiguration是在类路径上有DataSource类和EmbeddedDatabaseType类时才会自动配置。而如果用户定义了自己的DataSource Bean,则默认的数据源自动配置将不会应用。
覆盖自动配置
尽管Spring Boot的自动配置提供了很大的便利,但有时你可能需要覆盖某些自动配置。Spring Boot允许你通过多种方式进行自定义,包括:
- 在
application.properties或application.yml中通过设置属性来覆盖自动配置的默认值。 - 添加自己的
@Configuration类,声明自己的Bean,甚至可以使用@Primary注解来指定优先的Bean。 - 使用
@ComponentScan的excludeFilters属性或@EnableAutoConfiguration的exclude属性来排除特定的自动配置类。
@SpringBootApplication示例
在Spring Boot应用程序的入口类上通常可以看到@SpringBootApplication注解的使用,比如:
@SpringBootApplication
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
在这个例子中,@SpringBootApplication注解对于快速启动和自动配置应用程序至关重要。它整合了Spring的核心功能,通过一个单独的注解来启用,使Spring Boot成为一个非常易于使用和高度“开箱即用”的框架。
自动配置主要由@EnableAutoConfiguration实现,添加了@EnableAutoConfiguration注解,会导入AutoConfigurationImportSelector类,里面的selectImports方法通过SpringFactoriesLoader.loadFactoryNames()扫描所有含有META-INF/spring.factories的jar包,将对应key为@EnableAutoConfiguration注解全名对应的value类全部装配到IOC容器中。
3、死锁
死锁是计算机科学中多线程或多进程编程的一个概念,它发生在一组进程或线程中,每个成员都在等待另一个成员释放资源或完成操作,但是没有一个能够继续前进,因为它们都在相互等待。这导致所有进程或线程都无法继续执行它们的任务。
要发生死锁,通常需要满足以下四个条件,这被称为死锁的四个必要条件:
1. 互斥条件
资源不能被多个进程共享,只能由一个进程在任何时刻使用。每个资源要么已经分配给一个进程,要么就是可用的。
2. 持有并等待条件
进程至少持有一个资源,并且正在等待获取其他进程所持有的额外资源。
3. 不可剥夺条件
已经分配给一个进程的资源不能被强制从那个进程中剥夺;只有当进程自己释放资源时,资源才会变得可用。
4. 循环等待条件
有一组进程(P1, P2, …, Pn),P1在等待P2持有的资源,P2在等待P3持有的资源,依此类推,直到Pn在等待P1持有的资源,这样就形成了一个循环等待的环路。
死锁的例子
考虑一个简单的例子,其中有两个进程(P1和P2)和两个资源(R1和R2)。进程P1持有资源R1并请求资源R2,同时进程P2持有资源R2并请求资源R1。如果每个进程都不释放其当前持有的资源,那么这两个进程都将无法继续进行,因为它们要求的资源都被对方持有。
死锁处理
处理死锁的常见策略分为四类:
1. 死锁预防
预防死锁的策略旨在通过确保系统永远不会进入可能导致死锁的状态来避免死锁。这通常涉及破坏产生死锁的四个条件中的至少一个。
2. 死锁避免
与预防不同,避免策略允许这些条件存在,但是系统会尝试组织资源分配,使得系统永不进入不安全状态。银行家算法是解决死锁问题的一个著名的避免策略。
3. 死锁检测
在死锁检测策略中,系统允许死锁发生,并通过一些检测机制来检测是否已经发生了死锁。一旦检测到死锁,就可以采取一些措施解决。
4. 死锁恢复
一旦死锁被检测到,系统需要恢复到一个安全状态并重新开始执行。恢复策略可能包括终止一个或多个进程,或者剥夺一些资源。
死锁解决方案
解决死锁问题通常涉及以下措施:
- 终止进程:最直接的解决方法是直接终止一个或多个导致死锁的进程。
- 资源剥夺:强制从一个进程中取走资源并分配给其他进程。
- 进程回退:将一个或多个进程回退到足以打破循环等待的状态。
处理死锁的最佳方法取决于应用程序的具体需求和资源的性质。设计良好的系统会尽量避免死锁的发生,或者能够有效地检测并解决死锁问题。
4、事务
事务是数据库管理系统中的一个基本概念,它是一个独立的工作单位,由一系列操作组成,这些操作要么完全执行,要么完全不执行。在关系型数据库中,事务用来确保数据库的完整性和一致性。一个事务可以是一次简单的单一操作,如更新一个记录,也可以是多个操作的组合,如更新多个记录或执行多个不同的数据库操作。
事务的主要特性通常由ACID原则定义,该原则包括以下四个部分:
1. 原子性(Atomicity)
原子性确保事务中的所有操作要么全部完成,要么全部不完成。如果事务中的一个操作失败,整个事务将回滚到开始状态,所有已经执行的操作都将撤销。
2. 一致性(Consistency)
一致性确保事务从一个一致的状态转换到另一个一致的状态。在事务开始和完成时,数据库的完整性约束都必须保持一致。
3. 隔离性(Isolation)
隔离性保证事务的操作和其他并发事务的操作是隔离的。这意味着一个事务的中间状态不应该被其他事务所看到。
4. 持久性(Durability)
持久性确保一旦事务完成,它对数据库的改变是永久性的,即使系统发生故障也不会丢失。
事务的隔离级别
数据库事务的隔离级别定义了一个事务可能必须和其他并发事务隔离的程度。隔离级别通常有以下四种:
- 读未提交(Read Uncommitted): 在这个级别,一个事务可以读取另一个事务尚未提交的数据。这可能导致脏读(Dirty Read)。
- 读提交(Read Committed): 这个级别确保一个事务只可以读取另一个事务已经提交的数据。这可以避免脏读,但仍然可能出现不可重复读(Non-Repeatable Read)。
- 可重复读(Repeatable Read): 在这个级别,一个事务在整个过程中可以多次读取同一数据,并且保证结果一致,即使其他事务在这段时间内提交了更新。这可以避免脏读和不可重复读,但仍然可能出现幻读(Phantom Read)。
- 可串行化(Serializable): 这是最高的隔离级别,它完全隔离事务,使得事务只能一个接一个地执行,而不是并行执行。这可以避免脏读、不可重复读和幻读。
事务的管理
事务的管理通常涉及以下操作:
- 开始事务(BEGIN TRANSACTION): 声明事务的开始。
- 提交事务(COMMIT): 完成事务中的所有操作,并将其永久保存到数据库中。
- 回滚事务(ROLLBACK): 撤销事务中的所有操作,并放弃所有未保存的更改。
事务的实现
数据库通过各种技术来实现事务的管理和保证ACID特性,包括:
- 锁定机制:来确保当其他事务进行读/写操作时,数据的一致性可以得到维护。
- 日志记录:每一个被事务影响的数据项都会在日志中记录下来,在系统故障时可以用来恢复数据到一个一致的状态。
- 多版本并发控制(MVCC):一种避免在读取数据时进行锁定的方法,使得读写操作可以更加并行地执行。
数据库事务是一个复杂的主题,需要在保证数据完整性和系统性能之间找到平衡。正确理解和使用事务对于开发安全、稳定和高效的数据库应用程序至关重要。
事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
5、线程
在线程模型中,线程是轻量级的执行单元,它们在进程的上下文中并发执行。深入理解线程涉及探讨它们的行为、特性和实现方式。
线程的关键特性点
以下是线程的关键特性点,每一点都对理解线程的工作方式至关重要:
-
并发性: 线程允许多个任务几乎同时发生,促进了多核处理器上的并行处理和在单核处理器上的时间分片。
-
独立性: 每个线程都有其独立的程序计数器、堆栈和局部变量,但它们共享进程级别的资源,如内存和文件。
-
轻量级: 线程的创建和上下文切换通常比完整的进程轻量,因为它们共享更多的状态和资源。
-
通信: 线程间的通信(线程同步)可以通过共享内存和适当的同步机制来实现,这包括锁、等待/通知机制、信号量等。
-
线程池: 为避免频繁地创建和销毁线程带来的开销,线程池维护一组预先初始化的线程,这些线程可以被多个任务重用。
-
优先级: 大多数操作系统和线程库支持线程优先级,它影响线程获取CPU时间的顺序。高优先级的线程比低优先级的线程更有可能被选中执行。
-
守护线程: 一些线程可以被设置成守护线程,这种线程通常用于服务性的任务。当只剩下守护线程时,JVM会退出。
线程的状态
线程的状态描述了线程在任何给定时间的行为。在线程的生命周期中,线程可以处于以下状态:
-
新建(New): 线程被创建后,但还没有调用
start()方法。 -
就绪(Runnable): 线程已经调用了
start()方法,等待CPU分配时间片。 -
运行(Running): 线程获取了CPU时间片,正在执行。
-
阻塞(Blocked): 线程因为等待一个监视器锁(进入同步块)而被阻塞。
-
等待(Waiting): 线程等待另一个线程执行特定的(通常是状态变化)操作。
-
超时等待(Timed Waiting): 线程等待另一个线程执行操作到一定的时间。
-
终止(Terminated): 线程的运行结束。
线程的同步
在多线程程序中,同步对于保持数据一致性和避免竞态条件至关重要。同步可以通过以下方式来实现:
-
互斥锁(Mutex): 确保一次只有一个线程可以访问某个资源。
-
信号量(Semaphore): 限制可以同时访问资源或执行一段代码的线程数。
-
监视器(Monitor): 一种更高级的同步机制,通常与
wait()、notify()和notifyAll()方法一起使用。 -
并发集合: 线程安全的数据结构,如
java.util.concurrent中的集合。 -
原子变量: 利用特定的硬件指令来保证变量操作的原子性。
线程的问题
不当的线程管理可能导致以下问题:
-
竞态条件(Race Condition): 两个或多个线程同时访问共享资源,并尝试同时修改它。
-
死锁(Deadlock): 多个线程相互等待对方持有的锁,导致永久阻塞。
-
饥饿(Starvation): 一个或多个线程无法获取必要的资源,因而无法执行,通常是因为线程优先级不当。
-
活锁(Livelock): 线程不断重试一个操作,但总是失败,因为其他线程也在做相同的事情。
-
上下文切换(Context Switching): 线程切换可能引起的性能开销,特别是在高负载或大量线程时。
线程和并发编程是一个复杂的主题,它要求开发者对同步、资源共享和任务调度有深刻的理解。适当的线程使用策略可以使软件设计更加清晰,系统更加高效。
线程三大特性:原子性、可见性、有序性
原子性:即一个操作或多个操作要么全部执行并且执行过程中不被任何因素打断,要么就不执行
原子性其实就是保证数据一致,线程安全的一部分
可见性:当多个线程同时访问一个变量时,一个线程修改了这个变量的值,其它线程能立即看得到它修改的值,volatile关键字解决线程之间的可见性,强制线程每次读取该值的时候都去“主内存”中读取
有序性:执行的顺序按照代码的先后顺序执行
Lock是Java 5以后引入的新的API,和关键字synchronized相比主要相同点:Lock 能完成synchronized所实现的所有功能;主要不同点:Lock有比synchronized更精确的线程语义和更好的性能,而且不强制性的要求一定要获得锁。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且最好在finally 块中释放(这是释放外部资源的最好的地方)
6、FactoryBean和BeanFactory 有什么区别?
FactoryBean和BeanFactory是Spring框架中完全不同的概念,但它们都与Spring容器中bean的创建和管理有关。下面,我们将探讨它们的相同点和不同点。
相同点
实际上,FactoryBean和BeanFactory的相同点非常有限,主要是它们都与Spring容器中bean的创建有关联。它们都参与到了Spring容器管理对象实例的生命周期中。
不同点
不同点比较多,可以从各个方面深入地探讨:
1. 概念层面
- BeanFactory: 它是Spring的基础设施,是Spring IoC容器的核心接口,负责管理bean的生命周期,包括bean的创建、销毁、装配以及其他服务。
- FactoryBean: 它是一个可以生成或修饰对象实例的工厂模式实现,用于创建特殊的bean。
FactoryBean本身定义在Spring IoC容器中,但它产生的对象不一定必须由Spring IoC容器管理。
2. 用途和功能
- BeanFactory: 作为IoC容器,用于创建和管理容器中的所有bean。它主要用于加载和管理bean实例,以及延迟加载(懒加载)。
- FactoryBean: 设计用来创建复杂对象,当直接配置对象实例过于复杂时,通过实现
FactoryBean接口来简化配置。它是一个可以返回不同对象实例的bean。
3. 实现和扩展
- BeanFactory: 通过直接或间接实现
BeanFactory接口的方式来扩展,比如常见的ApplicationContext接口,它提供了更多高级特性如事件传播、AOP支持等。 - FactoryBean: 通过实现
FactoryBean接口,并重写getObject()方法来返回一个特定的对象实例。
4. 行为
- BeanFactory: 通常不会直接使用
BeanFactory,而是会使用它的实现,比如ApplicationContext,来获得和管理bean。 - FactoryBean: 当通过
BeanFactory获取到FactoryBean的实例时,你得到的对象是FactoryBean#getObject()方法返回的对象,而不是FactoryBean实例本身。
5. 访问方式
- BeanFactory: 你可以通过
getBean()方法直接从BeanFactory中获取bean。 - FactoryBean: 当从
BeanFactory请求FactoryBean产生的bean时,你需要使用bean的名称。如果需要访问FactoryBean实例本身,则需要在bean的名称前加上&。
例子
以下是一个FactoryBean的例子,展示如何使用它来创建复杂对象:
public class ComplexObjectFactoryBean implements FactoryBean<ComplexObject> {
@Override
public ComplexObject getObject() throws Exception {
// 实例化复杂对象,可能包括配置复杂的初始化逻辑
return new ComplexObject();
}
@Override
public Class<?> getObjectType() {
return ComplexObject.class;
}
@Override
public boolean isSingleton() {
return true;
}
}
在Spring的配置中注册这个FactoryBean:
<bean id="complexObject" class="example.ComplexObjectFactoryBean"/>
当请求complexObject时,实际上得到的将是ComplexObjectFactoryBean#getObject()方法返回的ComplexObject实例。如果你需要访问ComplexObjectFactoryBean本身,你应该请求&complexObject。
在比较FactoryBean和BeanFactory时,最重要的是理解BeanFactory是创建和管理bean的容器,而FactoryBean是用来创建复杂对象的模板或工厂类,它们在Spring框架中扮演着截然不同的角色。
7、JDK和CGLib的区别
在Java开发中,JDK动态代理和CGLib动态代理是实现AOP(面向切面编程)和代理模式的两种常见方式。它们都可以在运行时创建代理对象,但是底层实现和使用场景有所不同。
相同点
JDK动态代理和CGLib动态代理在用途上相似,都用于创建动态代理对象,允许开发者在不改变原有代码结构的情况下,增加或改变某些功能。这在AOP编程中尤为常见,比如在方法执行前后添加日志或事务处理。
不同点
JDK动态代理和CGLib动态代理之间有一些关键区别:
1. 实现机制
- JDK动态代理:使用反射包
java.lang.reflect中的Proxy类和InvocationHandler接口来创建代理对象。它只能对实现了接口的类创建代理。 - CGLib动态代理:通过继承目标类来创建子类的方式实现。它不需要目标类实现接口。
2. 性能
- JDK动态代理:由于JDK动态代理是基于接口的,它在调用过程中使用反射机制,会有一定的性能开销。
- CGLib动态代理:性能通常优于JDK动态代理(尤其是在方法调用频繁时),因为它使用
FastClass机制来直接调用方法,而不是通过反射。
3. 使用限制
- JDK动态代理:只能对接口或接口的实现类进行代理,不能对普通类进行代理。
- CGLib动态代理:可以代理没有实现接口的类,但是不能对
final类或final方法进行代理,因为它们不能被子类覆盖。
4. 使用场景
- JDK动态代理:适用于有接口定义的情况,如果你的类没有实现任何接口,则无法使用JDK代理。
- CGLib动态代理:适用于没有实现接口的类,或者对类的代理比接口的代理更有意义的场合。
5. 实现复杂度
- JDK动态代理:使用相对简单,只需要实现
InvocationHandler接口并重写invoke方法。 - CGLib动态代理:通过使用字节码处理库ASM,可以在运行时创建新的类。因此,它的使用通常比JDK动态代理更复杂。
6. 第三方库依赖
- JDK动态代理:作为Java标准库的一部分,不需要额外的依赖。
- CGLib动态代理:需要引入CGLib库以及其依赖的ASM字节码操作库。
示例
JDK动态代理
public interface MyInterface {
void doSomething();
}
public class MyInterfaceImpl implements MyInterface {
public void doSomething() {
System.out.println("Doing something...");
}
}
public class MyInvocationHandler implements InvocationHandler {
private Object target;
public MyInvocationHandler(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 在目标方法执行前后可以添加额外的操作
System.out.println("Before method");
Object result = method.invoke(target, args);
System.out.println("After method");
return result;
}
}
MyInterface proxy = (MyInterface) Proxy.newProxyInstance(
MyInterface.class.getClassLoader(),
new Class<?>[]{MyInterface.class},
new MyInvocationHandler(new MyInterfaceImpl())
);
proxy.doSomething();
CGLib动态代理
public class MyConcreteClass {
public void doSomething() {
System.out.println("Doing something...");
}
}
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(MyConcreteClass.class);
enhancer.setCallback(new MethodInterceptor() {
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
// 在目标方法执行前后可以添加额外的操作
System.out.println("Before method");
Object result = proxy.invokeSuper(obj, args);
System.out.println("After method");
return result;
}
});
MyConcreteClass proxy = (MyConcreteClass) enhancer.create();
proxy.doSomething();
总结来说,JDK动态代理和CGLib动态代理都是实现动态代理的有效手段,但是它们有不同的使用场景和限制。通常情况下,如果目标对象是一个实现了接口的类,可以优先考虑使用JDK动态代理,因为它是Java自带的,不需要额外的库。如果目标对象是一个没有实现接口的普通类,或者需要通过继承来增强行为,则可以使用CGLib动态代理。
Spring在选择用JDK还是CGLib的依据
当Bean实现接口时,Spring就会用JDK的动态代理
当Bean没有实现接口时,Spring使用CGLib来实现
可以强制使用CGLib(在Spring配置中加入<aop:aspectj-autoproxy proxy-target-class=“true”/>)
8、Java类的加载过程
在Java中,类的加载是通过类加载器(ClassLoader)完成的。Java虚拟机(JVM)在运行时会通过一个特定的类加载器实例来加载Java类。这一过程通常分为以下几个阶段:加载(Loading)、链接(Linking)、和初始化(Initialization)。
加载(Loading)
在加载阶段,类加载器负责从文件系统、网络或其他来源读取Java类的二进制数据,并将这些数据转为java.lang.Class类的实例。在这个过程中,类加载器会检查这个类是否已经被加载过,因为同一个类只能被加载一次。
加载时,类加载器主要执行以下步骤:
- 通过全类名来定位此类的二进制流。
- 将这个二进制流代表的类加载到JVM中。
- 将这个流转换成
java.lang.Class类的一个实例。
例如,当你调用Class.forName("com.example.MyClass")时,就会触发类加载。
链接(Linking)
链接阶段又分为验证(Verification)、准备(Preparation)和解析(Resolution)三个子步骤。
- 验证(Verification): 确保被加载的类符合JVM规范,没有安全问题。
- 准备(Preparation): JVM为类变量分配内存,并设置默认初始值。
- 解析(Resolution): JVM将所有的符号引用转换为直接引用。
初始化(Initialization)
在初始化阶段,JVM负责执行类的静态初始化块以及静态字段的初始化。这一步骤是执行构造器之前的最后一步,即执行<clinit>()方法的过程。
现在,我们来看一下JVM内部是如何使用类加载器来加载类的。
以ClassLoader.loadClass(String name)方法为例:
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先检查请求的类是否已被加载
Class<?> c = findLoadedClass(name);
if (c == null) {
try {
// 如果没有加载,则委托给父类加载器
if (parent != null) {
c = parent.loadClass(name, false);
} else {
// 如果没有父类加载器,则委托给启动类加载器(Bootstrap ClassLoader)
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// 如果类还没被加载,则调用本地的findClass方法来加载类
c = findClass(name);
}
}
if (resolve) {
// 链接类
resolveClass(c);
}
return c;
}
}
这个loadClass方法描述了类加载的入口点,具体的类加载动作发生在findClass方法中。
当类被加载后,它们会被缓存。如果之后再次需要加载,JVM会返回缓存中的类,而不是重新加载。
这只是一个高层次的概述,如果需要深入了解类加载器的实现,你可以直接查看OpenJDK的源代码。由于类加载器的实现可能根据不同的JVM实现(比如OpenJDK、Oracle JDK等)有所不同,具体细节可能会发生变化。
双亲委派
双亲委派模型(Parent Delegation Model)是Java 类加载器寻找类的一种机制。其核心思想是:当一个类加载器收到类加载请求时,它不会自己首先去尝试加载这个类,而是把这个请求委托给父类加载器去完成,每一层的加载器都是如此。只有当父类加载器反馈无法完成这个加载(它的搜索范围中没有找到所需的类)时,子类加载器才会尝试自己去加载。
这个模型的优点是防止内存中出现多份同样的字节码,并确保Java核心库的类型安全。双亲委派模型在java.lang.ClassLoader中实现。
下面是ClassLoader中与双亲委派模型相关的loadClass方法的简化版源码:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,检查该类是否已经被加载
Class<?> c = findLoadedClass(name);
if (c == null) {
try {
// 如果没有被加载,尝试从父类加载器中加载
if (parent != null) {
c = parent.loadClass(name, false);
} else {
// 如果父类加载器为空,则使用启动类加载器(Bootstrap ClassLoader)
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 如果父类加载器抛出ClassNotFoundException
// 表示父类加载器无法完成加载请求
}
if (c == null) {
// 如果父类加载器无法加载该类,则当前类加载器尝试加载
c = findClass(name);
}
}
if (resolve) {
// 链接已经被加载的类
resolveClass(c);
}
return c;
}
}
这段代码大致流程如下:
- 同步锁定(Synchronization): 防止多个线程同时加载同一个类。
- 检查类是否加载(Check Loaded): 检查请求加载的类是否已经被加载。
- 委托给父类加载器(Delegate to Parent): 如果类没有被加载,委托给父类加载器尝试加载。
- 使用启动类加载器(Use Bootstrap ClassLoader): 如果父类加载器是
null,意味着当前加载器是系统类加载器,它会尝试用启动类加载器来加载类。 - 当前类加载器加载(Load Class Itself): 如果父类加载器不能加载该类,则当前类加载器尝试自己去加载。
- 链接类(Resolve Class): 如果
resolve标志为true,则链接请求加载的类。
需要注意的是,findClass方法是ClassLoader中的一个抽象方法,由其子类具体实现。在findClass方法中,类加载器通常会根据给定的类名,将.class文件读入内存,转换成Class对象。如果findClass也无法完成类加载,它会抛出ClassNotFoundException。
在某些情形下,比如Java Agent,热部署等功能的实现中会绕开双亲委派模型,或者在OSGi环境中,每一个Bundle有自己的类加载器,这种情况下双亲委派模型会被设计得更加灵活。
总的来说,双亲委派模型是确保Java程序稳定运行的关键机制之一,它防止了核心库被随意篡改,同时也避免了类加载器之间的冲突。
9、如何解决hash冲突
有以下几种常见的解决hash冲突的方法:
链地址法(Chaining):将哈希表中每个桶中的元素使用链表等数据结构链接起来,当产生哈希冲突时,将新元素插入到链表的末尾。
这是最常用的解决哈希冲突的方法。
开放地址法(Open Addressing):当发生哈希冲突时,尝试在哈希表中找到另一个空闲的桶。
具体有以下几种实现方法:
线性探测:在哈希表中依次查找下一个空闲的桶。
二次探测:在哈希表中使用二次探测函数查找下一个空闲的桶。
双重哈希:使用另一个哈希函数计算下一个空闲的桶。
再哈希法(Rehashing):当发生哈希冲突时,使用另一个哈希函数计算出另一个哈希值,然后将元素插入到对应的桶中。
建立公共溢出区(Overflow Area):当发生哈希冲突时,将冲突的元素插入到一个公共溢出区中,需要时再通过遍历这个溢出区来查找元素。这种方法会增加查找的时间复杂度,不太常用。
在散列数据结构中,哈希冲突(Hash Collision)是指两个或更多的输入值在经过哈希函数处理后得到了相同的哈希值。由于哈希表的大小是有限的,而可能的输入值通常是无限的,哈希冲突是不可避免的。
为了解决哈希冲突,有几种常用的策略:
1. 分离链接(Separate Chaining)
分离链接是处理哈希冲突的一种直接方法。在这种策略中,每个哈希桶(bucket)本身是一个链表(或者是其他形式的动态数据结构,如树)。当一个新的条目与该位置上的现有条目发生冲突时,它会被添加到链表的末尾。
例如,假设我们有一个哈希表,有以下哈希函数和元素:
Hash Function: h(x) = x mod 10
Elements: 12, 22, 32
因为所有的元素都会映射到同一个值(2),所以哈希表中的索引2将指向一个链表,包含值12,22和32。
2. 开放寻址(Open Addressing)
在开放寻址策略中,所有的元素都存储在哈希表的数组里。当一个新的元素被插入且其哈希值对应的槽已经被占用时,哈希表尝试找一个空槽来存放这个新元素。这通过一系列的探测(probing)操作完成,比如线性探测(linear probing)、二次探测(quadratic probing)或双重哈希(double hashing)。
以线性探测为例,如果位置i被占用,算法会检查i+1,i+2,依此类推,直到找到一个空位置。
3. 双重哈希(Double Hashing)
双重哈希是开放寻址的一个变体,但是它使用了两个哈希函数。当第一个哈希函数h1产生冲突时,它会使用第二个哈希函数h2。新的位置将会是原始哈希值加上第二个哈希函数的倍数。
这个算法会产生一个探测序列,如果h2设计得当,这个序列可以访问哈希表中的每个槽,减少了聚集的可能性。
4. 再散列(Rehashing)
随着元素不断加入,哈希表的负载因子(即表中已有的元素数与位置总数的比例)会不断上升,从而增加冲突的概率。当负载因子超过某个阈值(如0.7)时,可以通过再散列来减少冲突,即创建一个更大的哈希表,并将所有现有元素重新映射到新表中。
5. 使用更好的哈希函数
选择一个良好的哈希函数至关重要,它可以最大程度地减少冲突的发生。一个好的哈希函数应该能够将输入数据均匀分布到所有哈希桶中。
实现示例
以Java中的HashMap为例,该结构内部使用了一种称作“数组+链表+红黑树”的结构:当链表的长度过长(默认超过8)时,链表将转换为红黑树,以提高搜索效率。以下是Java中HashMap解决哈希冲突的一个简化片段:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果表为空或者大小为0,进行扩容处理
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算索引i,并对其进行赋值
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 链表处理
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // 默认是8,链表转红黑树的阈值
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // 如果已经存在,替换旧值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
在这段代码中,HashMap使用链表处理冲突,当链表长度过大时,会将链表转换为红黑树以提高性能。此外,该实现也考虑了扩容逻辑,以适应不断增加的数据量。
处理哈希冲突的方法有很多,选择哪一种取决于具体的应用场景,包括数据的分布、频率、哈希表的大小、内存限制等因素。
10、抽象类和接口
抽象类(Abstract Class)和接口(Interface)都是Java面向对象编程中实现抽象的两个关键概念。它们有一些相似之处,也有许多不同之处。
相同点
- 不可以被实例化:既抽象类也接口都不能被实例化,它们通常用作其他类的基础。
- 包含抽象方法:抽象类和接口都可以包含抽象方法,即没有方法体的方法,具体的实现需要由子类或实现类完成。
- 被继承/实现的目的:它们都被用作基类,子类/实现类应提供相应的方法实现。
不同点
-
方法声明:
- 抽象类:可以包含具体方法(有方法体的方法)和抽象方法。
- 接口(在Java 8之前):只能包含抽象方法。从Java 8开始,接口也可以包含默认方法和静态方法。
-
成员变量:
- 抽象类:可以包含各种访问修饰符的字段,字段可以是非final的,也可以是非static的。
- 接口:只能包含静态和final变量(常量)。
-
构造函数:
- 抽象类:可以有构造函数。
- 接口:不能有构造函数。
-
继承和实现:
- 抽象类:一个类只能继承一个抽象类,因为Java不支持多重继承。
- 接口:一个类可以实现多个接口。
-
访问修饰符:
- 抽象类:方法和成员变量可以有任何访问修饰符。
- 接口:在Java 8之前,方法默认是public的,且不能有其他访问修饰符。从Java 9开始,接口可以包含私有方法。
-
多继承:
- 抽象类:不能实现多继承。
- 接口:支持多继承,即一个接口可以继承多个其他接口。
-
实现(Implementation):
- 抽象类:子类使用
extends关键字继承抽象类,并提供抽象方法的实现。 - 接口:类使用
implements关键字实现接口,必须提供接口中所有方法的实现,除非它是一个抽象类。
- 抽象类:子类使用
-
设计目的:
- 抽象类:用于捕获子类的通用特征,并提供一个部分实现的类层次结构。
- 接口:用于定义不同类之间的约定或协议,是实现多种功能的一种方式,不涉及实现。
-
版本兼容性:
- 抽象类:如果后续需要添加新的方法,可能会破坏已有的类体系结构。
- 接口:在Java 8之后,可以通过默认方法和静态方法添加新功能而不影响实现接口的类。
根据以上特点,你可以根据具体需求选择使用抽象类还是接口。如果你要定义一个基础的事物或者提供一个共同的实现,并且知道它将不需要与其他继承结构共存,那么抽象类可能是一个好选择。相反,如果你要定义一组可能由不同类以多种方式实现的行为,或者提供一个插件式的扩展机制,那么接口将是更好的选择。。
Feign原理
Feign是一个声明式的Web服务客户端,它的目标是简化HTTP API客户端的开发。其工作原理是,开发者定义一个接口并用注解修饰它的方法和参数来配置对应的HTTP请求,Feign在程序启动时会扫描并解析这些注解,生成代理类。当调用接口中的方法时,Feign通过这个代理类构建并发送HTTP请求到服务提供者,并将响应结果映射到接口方法的返回值上。
下面将Feign的内部工作原理,并结合源码进行讲解。
Feign的工作流程概述
- 定义服务接口:开发者编写一个接口,使用Feign的注解来声明服务提供者的REST API。
- 创建Feign.Builder:使用
Feign.Builder来创建Feign的客户端实例。 - 构建RequestTemplate:当程序启动时,Feign通过注解解析生成
RequestTemplate,它包含了构建请求所需的所有信息,例如URL、HTTP方法和查询参数等。 - 生成代理类:Feign使用JDK动态代理生成接口的代理实现类。
- 发送请求:当代理接口的方法被调用时,Feign根据
RequestTemplate生成HTTP请求,并通过Client接口的实现类(比如使用OkHttp、HttpClient等)发送请求。 - 处理响应:Feign接收到HTTP响应后,使用
Decoder将响应内容反序列化成接口方法的返回类型。
源码解析
下面是一个简化版的Feign工作原理的源码解析,显示了从接口定义到请求发送的主要步骤:
// Step 1: 定义服务接口
@FeignClient("stores")
public interface StoreClient {
@RequestMapping(method = RequestMethod.GET, value = "/stores")
List<Store> getStores();
}
// Step 2: 创建Feign客户端实例
StoreClient storeClient = Feign.builder()
.client(new OkHttpClient())
.encoder(new GsonEncoder())
.decoder(new GsonDecoder())
.target(StoreClient.class, "http://localhost:8000");
// Step 3 & 4: Feign的Builder会构建RequestTemplate并生成动态代理类
public class Feign {
public static Builder builder() {
return new Builder();
}
public static class Builder {
public <T> T target(Class<T> apiType, String url) {
// 省略了解析注解和创建RequestTemplate的复杂细节
// ...
// 创建动态代理
return (T) Proxy.newProxyInstance(apiType.getClassLoader(),
new Class<?>[] { apiType },
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
// 省略处理代码...
// 创建请求
Request request = buildRequestFromTemplate(template);
// 发送请求
Response response = client.execute(request, options);
// 解码响应
return decode(response);
}
});
}
}
}
在上述源码示例中,Feign.builder()部分用于创建Feign的客户端,并配置了它的编码器、解码器和HTTP客户端。Feign使用动态代理生成StoreClient的实现,在调用getStores方法时,Feign会根据注解信息生成HTTP请求,并通过配置好的客户端发送请求。
Feign内部使用了几个关键组件来实现其功能:
- Contract:负责解析接口上的注解,生成元数据。
- RequestTemplate:存储HTTP请求所需的所有信息,如服务地址、HTTP方法、请求头和请求体。
- Client:是一个接口,负责发送HTTP请求。Feign可以使用不同的实现,如默认的Java HTTP连接、Apache HttpClient或OkHttp。
- Encoder:用于将方法参数等数据编码到请求体中。
- Decoder:用于将HTTP响应体解码为Java对象。
- InvocationHandlerFactory:创建动态代理的处理器,这个处理器负责将方法调用转化为HTTP请求。
在实际的Feign实现中,代码会更加复杂,因为它需要处理多种注解、请求参数、请求头、错误处理等各种场景。
Ribbon
Ribbon是Netflix开源的一个客户端负载均衡器,它可以在客户端程序中根据某种策略将请求分发到多个不同的服务实例。Ribbon通常与Eureka等服务发现组件配合使用,可以动态地从服务注册中心获取服务实例列表。
Ribbon的关键组件
- IClientConfig:配置接口,存储客户端配置信息,如超时时间、重试次数等。
- ILoadBalancer:负载均衡器接口,主要实现类为
BaseLoadBalancer,它包含了服务实例列表和负载均衡算法。 - IPing:健康检查接口,用于确定服务实例是否可用。
- IRule:负载均衡规则接口,包含了不同的负载均衡算法,如轮询、随机、响应时间权重等。
负载均衡算法
Ribbon提供了多种负载均衡算法,以下是一些常见的算法:
- RoundRobinRule:轮询策略,按顺序循环选择服务实例。
- RandomRule:随机策略,随机选择服务实例。
- WeightedResponseTimeRule:根据响应时间计算所有服务的权重,响应时间越快的实例权重越大,选择权重高的实例。
- BestAvailableRule:选择一个最小的并发请求的服务实例。
Ribbon的工作流程
Ribbon的工作流程主要包含以下几个步骤:
- 在客户端配置Ribbon客户端,并指定负载均衡的策略。
- 客户端通过
LoadBalancerClient发起请求。 ILoadBalancer选择一个服务实例。- 使用
IRule决定使用哪个服务器。 - 发起实际的服务调用。
源码解析
以下是一个简化版的Ribbon工作原理的源码示例:
// 配置Ribbon客户端
IClientConfig ribbonClientConfig = DefaultClientConfigImpl.getClientConfigWithDefaultValues("clientName");
ILoadBalancer loadBalancer = LoadBalancerBuilder.newBuilder()
.withClientConfig(ribbonClientConfig)
.buildFixedServerListLoadBalancer(servers);
// 定义一个轮询策略
IRule roundRobinRule = new RoundRobinRule(loadBalancer);
// 使用负载均衡器选取一个服务实例
Server server = roundRobinRule.choose(null);
// 使用RestTemplate或者其他HTTP客户端发送请求
String url = "http://" + server.getHost() + ":" + server.getPort() + "/";
ResponseEntity<String> response = restTemplate.getForEntity(url, String.class);
在这段代码中,我们创建了一个配置对象IClientConfig,然后创建了一个负载均衡器ILoadBalancer,并且提供了一个服务实例列表。接着,我们定义了一个轮询策略IRule。在发送请求时,我们使用IRule的choose方法来选取一个服务实例,然后构建请求URL,并使用RestTemplate发送请求。
轮询算法示例
以轮询算法RoundRobinRule为例,下面简化的示例展示了它的工作原理:
public class RoundRobinRule extends AbstractLoadBalancerRule {
private AtomicInteger nextServerCyclicCounter;
public RoundRobinRule() {
nextServerCyclicCounter = new AtomicInteger(0);
}
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
}
Server server = null;
int count = 0;
while (server == null && count++ < 10) {
List<Server> reachableServers = lb.getReachableServers();
List<Server> allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
if ((upCount == 0) || (serverCount == 0)) {
return null;
}
int nextServerIndex = incrementAndGetModulo(serverCount);
server = allServers.get(nextServerIndex);
if (server == null) {
Thread.yield();
continue;
}
if (server.isAlive() && server.isReadyToServe()) {
return (server);
}
server = null;
}
if (count >= 10) {
return null;
}
return server;
}
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextServerCyclicCounter.get();
int next = (current + 1) % modulo;
if (nextServerCyclicCounter.compareAndSet(current, next))
return next;
}
}
}
在上面的RoundRobinRule实现中,choose方法会根据当前的索引选择一个服务实例并返回。incrementAndGetModulo方法确保索引是循环递增的,且能在多线程环境中安全地使用。
请注意,实际的Ribbon源码要复杂得多,它包含了更多的功能和异常处理逻辑。此外,随着Spring Cloud Netflix项目进入维护模式,Ribbon已经停止了更新,官方推荐使用其它替代方案,比如Spring Cloud的LoadBalancerClient或Spring Cloud LoadBalancer模块。
Nginx
Nginx是一个高性能的HTTP和反向代理服务器,同时也是一个IMAP/POP3/SMTP代理服务器。Nginx以其高性能、稳定性、简单的配置文件和低资源消耗而闻名。在许多用例中,Nginx用作负载均衡器,通过分发网络流量到多个服务器,以提高网站、应用程序的总体性能和可靠性。
Nginx的关键特性包括:
- 处理静态文件,索引文件以及自动索引;打开文件描述符缓存。
- 反向代理;通过HTTP、HTTPS、FastCGI、uwsgi、SCGI、memcached或GRPC等协议支持负载均衡。
- 负载均衡;使用不同策略分发流量(如轮询、最少连接、IP哈希等)。
- 容错和健康检查;检测后端服务器是否健康,自动剔除不健康节点。
- 缓存和压缩;减少数据传输量和响应延迟。
- 认证;基本的HTTP认证以及与外部认证服务器的集成。
- 重写和重定向;修改请求和应答。
Nginx内部工作原理
Nginx使用一个事件驱动的架构来高效地处理大量并发连接。其工作模式如下:
- 主进程(master process):读取和评估配置文件,维护一组工作进程(worker processes)。
- 工作进程(worker processes):处理实际的请求。Nginx的工作进程是多进程的,每个进程都是独立的,不需要线程间的锁定操作。
负载均衡策略
Nginx支持多种负载均衡策略,包括但不限于:
- 轮询(Round Robin):请求按时间顺序逐一分配到不同的后端服务器。
- 最少连接(Least Connections):优先分配给连接数最少的服务器。
- IP哈希(IP Hash):根据请求的IP地址来分配,可以在同一用户的会话中保持对同一后端服务器的访问。
Nginx源码概览
Nginx的源码是用C语言编写的,由于它的复杂性和灵活性,这里不会展示完整的源码。但是,我们可以简要查看与负载均衡相关的几个关键文件:
- ngx_http_upstream_round_robin.c:实现轮询负载均衡算法的源文件。
- ngx_http_upstream_least_conn.c:实现最少连接负载均衡算法的源文件。
- ngx_http_upstream_ip_hash.c:实现基于IP哈希的负载均衡算法的文件。
负载均衡算法示例
下面是一个简化的例子,展示了Nginx如何在配置文件中定义轮询负载均衡:
http {
upstream myapp1 {
server srv1.example.com;
server srv2.example.com;
server srv3.example.com;
}
server {
location / {
proxy_pass http://myapp1;
}
}
}
在上述配置中,有一个upstream块定义了名为myapp1的服务器组,将请求按轮询的方式分发到三个后端服务器上。每个server指令代表了一个后端服务器的地址。
注意
由于Nginx是一个开源项目,其源码是公开的,但解析和理解整个Nginx源码需要深厚的C语言功底,对网络编程和操作系统多进程/多线程模型有较好的理解,并且它的代码库非常庞大。通常,负载均衡的相关逻辑会涉及到复杂的数据结构和算法,以及对底层系统调用的优化,这些都是Nginx性能优良的原因之一。如果有兴趣深入了解Nginx的源码,推荐直接参考其官方代码库和相关文档。
Ribbon和Nginx
Ribbon和Nginx都可以用作系统中的负载均衡器,但它们的设计理念、运行环境和功能特性有显著差异。以下是Ribbon和Nginx的相同点和不同点的对比:
相同点
- 负载均衡功能:Ribbon和Nginx都提供了负载均衡功能,能够将客户端的请求分发到后端的多个服务器上。
- 多种负载均衡策略:它们都支持多种负载均衡策略,如轮询、最少连接数等。
- 服务消费者:在分布式系统中,Ribbon和Nginx都扮演服务消费者的角色,向服务提供者发起请求。
不同点
-
运行环境:
- Ribbon 是一个客户端负载均衡库,它在客户端运行,通常与Spring Cloud和Netflix OSS配合使用,适用于微服务架构。
- Nginx 是一个服务器端的反向代理服务器,通常作为独立的进程在服务器上运行,能够处理HTTP、HTTPS请求,也可以作为邮件代理服务器。
-
架构位置:
- Ribbon 是进程内的负载均衡器,它是以库的形式存在于每个服务消费者的应用程序中。
- Nginx 作为外部代理运行,独立于应用程序,通常部署在应用服务器的前端。
-
语言和集成:
- Ribbon 是用Java编写的,易于与Java应用程序集成,特别是在Spring Cloud生态系统中。
- Nginx 是用C编写的,配置通常通过编辑其文本配置文件完成,与应用程序语言无关。
-
功能性:
- Ribbon 只提供了HTTP客户端的负载均衡功能,需要与其他组件如Eureka搭配使用,进行服务发现。
- Nginx 是一个全功能的Web服务器,提供了静态内容的服务、反向代理、缓存、SSL终端、gzip压缩和Web应用防火墙等功能。
-
高可用性和伸缩性:
- Ribbon 的设计理念是在客户端实现智能路由,这就要求客户端能够动态感知后端服务的变化。
- Nginx 可以通过配置upstream模块实现高可用性和伸缩性,但更新配置通常需要重新加载配置文件。
-
动态性:
- Ribbon 可以实时地从服务注册中心获取服务列表,并且可以在运行时更改其负载均衡策略。
- Nginx 的配置相对静态,虽然也可以通过服务发现机制动态更新服务列表,但这常需要额外的模块支持和更复杂的配置。
总结来说,Ribbon是一个面向服务消费者的库,在客户端提供负载均衡;而Nginx是一个功能更为丰富的服务器端代理和Web服务器,不仅提供负载均衡,还提供了其他的网络层和应用层的服务。在微服务架构中,Ribbon通常用于客户端负载均衡,而Nginx更多用作入口网关,提供路由、认证、SSL终端等功能。
11、Ribbon、Feign和OpenFeign的区别
Ribbon、Feign和OpenFeign都是微服务架构中用于服务间调用的工具,它们各自有着不同的特点和用途。在Spring Cloud微服务架构中,这些工具通常被用于实现客户端负载均衡、服务声明和服务调用。
Ribbon
Ribbon 是一个客户端负载均衡器,它提供了一系列的配置项如连接超时、重试等,可以与服务发现组件如Eureka结合使用。Ribbon的主要作用是在客户端实现对于多个服务实例的负载均衡。当服务消费者调用服务提供者时,Ribbon可以根据特定的负载均衡算法(如轮询、随机等)从服务注册中心获取服务列表,然后选择一个服务实例进行调用。
Ribbon主要特点:
- 客户端负载均衡
- 支持多种负载均衡策略
- 可以和Eureka等服务发现工具联合使用
- 配置熔断机制,提高系统的弹性
- 直接与HTTP客户端整合,如Apache HttpClient和OkHttp
Feign
Feign 是一个声明式的Web服务客户端,让编写Web服务客户端变得更加简单。它的目标是通过简化HTTP API客户端的编程工作来减少开发者的负担。使用Feign时,开发者只需要创建一个接口并注解它,Feign会自动处理方法的实现。
Feign的主要特点:
- 声明式的服务调用客户端,易于使用
- 支持可插拔的注解特性,包括Feign注解和JAX-RS注解
- 支持可插拔的HTTP编码器和解码器
- 支持Hystrix和它的熔断器
- 使用反射方式根据注解和接口生成请求模板和实现
OpenFeign
OpenFeign是Spring Cloud在Feign的基础上支持的一个库,它使用Spring MVC的注解来实现Feign的HTTP请求,使得编写HTTP客户端更加方便。实质上,OpenFeign是Feign的进一步封装,它整合了Spring Cloud的特性,使得Feign的使用更加容易和规范化。
OpenFeign的主要特点:
- 集成了Ribbon,使用Ribbon作为客户端负载均衡工具
- 支持和Eureka等服务发现组件自动集成
- 通过提供一系列的Spring Cloud注解简化了HTTP客户端的开发
- 可以使用Spring MVC的注解来定义服务绑定
- 支持服务熔断的能力,通过整合Hystrix实现
Ribbon 与 Feign/OpenFeign的关系
- Ribbon通常作为底层的客户端负载均衡工具,可以单独使用,也可以被Feign或OpenFeign使用。
- Feign和OpenFeign通常用于定义HTTP客户端的接口,它们也会使用Ribbon来实现对服务提供者的调用。
- OpenFeign是对Feign的增强,提供了更紧密的Spring Cloud集成,主要是通过支持Spring MVC的注解来简化了Feign的使用。
总的来说,Ribbon、Feign和OpenFeign都是在微服务架构下进行服务间通信的工具,它们可以组合使用。Ribbon提供了客户端的负载均衡能力,而Feign提供了简洁的HTTP客户端声明,OpenFeign则在Feign的基础上提供了更好的Spring Cloud集成支持。
12、红黑树
红黑树(Red-Black Tree)是一种自平衡二叉查找树,它在插入和删除操作时通过特定的旋转和重新着色来保持树的平衡,从而保证了最坏情况下的时间复杂度为O(log n)。红黑树的每个节点都包含一个颜色属性,可以是红色或黑色,并且树必须满足以下性质:
- 每个节点要么是红的,要么是黑的。
- 根节点是黑的。
- 每个叶子节点(NIL节点,空节点)是黑的。
- 如果一个节点是红的,那么它的两个子节点都是黑的(红色节点不能相邻)。
- 对于每个节点,从该节点到其所有后代叶子节点的简单路径上,均包含相同数目的黑色节点。
这些性质确保了从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。因此,红黑树是相对接近平衡的二叉树。
源码实现
红黑树的源码实现通常包含节点的定义、旋转操作、插入操作、删除操作等。下面是一个简化的红黑树节点的定义和旋转操作的示例,这里以C语言为例:
struct rb_node {
int data;
struct rb_node *parent;
struct rb_node *left;
struct rb_node *right;
int color; // 1 -> Red, 0 -> Black
};
// 左旋转示例
void leftRotate(struct rb_node **root, struct rb_node *x) {
struct rb_node *y = x->right;
x->right = y->left;
if (y->left != NULL) {
y->left->parent = x;
}
y->parent = x->parent;
if (x->parent == NULL) {
*root = y;
} else if (x == x->parent->left) {
x->parent->left = y;
} else {
x->parent->right = y;
}
y->left = x;
x->parent = y;
}
// 右旋转示例
void rightRotate(struct rb_node **root, struct rb_node *y) {
struct rb_node *x = y->left;
y->left = x->right;
if (x->right != NULL) {
x->right->parent = y;
}
x->parent = y->parent;
if (y->parent == NULL) {
*root = x;
} else if (y == y->parent->right) {
y->parent->right = x;
} else {
y->parent->left = x;
}
x->right = y;
y->parent = x;
}
插入操作
插入操作包括两个主要步骤:标准的二叉查找树插入和红黑树修复。以下是插入操作后可能需要进行的一些修复操作的简化示例:
- 重新着色:如果一个父节点和一个叔叔节点都是红色的,则改变它们的颜色。
- 旋转:如果父节点是红色,但叔叔节点是黑色或不存在,可能需要进行旋转。
void insertFixUp(struct rb_node **root, struct rb_node *z) {
// 当前节点的父节点是红色
while (z != *root && z->parent->color == 1) {
if (z->parent == z->parent->parent->left) {
struct rb_node *y = z->parent->parent->right;
if (y->color == 1) {
// 叔叔节点是红色,只需进行重新着色
z->parent->color = 0;
y->color = 0;
z->parent->parent->color = 1;
z = z->parent->parent;
} else {
if (z == z->parent->right) {
// 当前节点是其父节点的右子节点,左旋
z = z->parent;
leftRotate(root, z);
}
// 进行右旋
z->parent->color = 0;
z->parent->parent->color = 1;
rightRotate(root, z->parent->parent);
}
} else {
// 对称操作...
}
}
(*root)->color = 0; // 根节点必须是黑色
}
以上代码是高度抽象的,实际的红黑树实现要考虑更多的边界条件。此外,删除操作比插入操作更复杂,因为它可能会破坏红黑树的更多性质,需要进行更多的修复工作。
在现代编程语言如Java或C++中,标准库通常提供了红黑树的实现,例如Java中的TreeMap和TreeSet,C++ STL中的map、multimap、set和multiset。
请注意,红黑树的完整实现需要处理许多特殊的情况,需要对算法和数据结构有深入了解。如果有兴趣深入学习红黑树的源码实现,可以查看相关开源项目或教科书中的示例代码。
13、Spring
Spring的核心特性是什么?Spring优点?
Spring的核心是控制反转(IoC)和面向切面(AOP)
Spring优点:
(1)方便解耦,简化开发 (高内聚低耦合)
Spring就是一个大工厂(容器),可以将所有对象创建和依赖关系维护,交给Spring管理
spring工厂是用于生成bean
(2)AOP编程的支持
Spring提供面向切面编程,可以方便的实现对程序进行权限拦截、运行监控等功能
(3) 声明式事务的支持
只需要通过配置就可以完成对事务的管理,而无需手动编程
(4) 方便程序的测试
Spring对Junit4支持,可以通过注解方便的测试Spring程序
(5)方便集成各种优秀框架
Spring不排斥各种优秀的开源框架,其内部提供了对各种优秀框架(如:Struts、Hibernate、MyBatis、Quartz等)的直接支持
(6) 降低JavaEE API的使用难度
Spring 对JavaEE开发中非常难用的一些API(JDBC、JavaMail、远程调用等),都提供了封装,使这些API应用难度大大降低
spring框架中需要引用哪些jar包,以及这些jar包的用途
4 + 1 : 4个核心(beans、core、context、expression) + 1个依赖(commons-loggins…jar)
理解AOP、IoC的基本原理
IOC: 控制反转(IoC)与依赖注入(DI)是同一个概念,
控制反转的思想:
传统的 java 开发模式中,当需要一个对象时,我们会自己使用 new 或者 getInstance 等直接或者间接调用构造方法创建一个对象。
而在 spring 开发模式中,spring 容器使用了工厂模式为我们创建了所需要的对象,不需要我们自己创建了,直接调用 spring 提供的对象就可以了
引入IOC的目的:
(1)脱开、降低类之间的耦合;
(2)倡导面向接口编程、实施依赖倒换原则;
(3)提高系统可插入、可测试、可修改等特性
AOP:面向切面编程(AOP)
面向切面编程思想:
在面向对象编程(oop)思想中,我们将事物纵向抽成一个个的对象。而在面向切面编程中,我们将一个个的对象某些类似的方面横向抽成一个切面,对这个切面进行一些如权限控制、事物管理,记录日志等公用操作处理的过程。
切面:简单说就是那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
AOP 底层:动态代理。
如果是接口采用 JDK 动态代理,如果是类采用CGLIB 方式实现动态代理。
AOP的一些场景应用;
Authentication 权限
Caching 缓存
Context passing 内容传递
Error handling 错误处理
Lazy loading 懒加载
Debugging 调试
logging, tracing, profiling and monitoring 记录跟踪 优化 校准
Performance optimization 性能优化
Persistence 持久化
Resource pooling 资源池
Synchronization 同步
Transactions 事务
spring注入的几种方式
(1)构造方法注入
(2)setter注入
(3)基于注解
Spring中自动装配的方式有哪些
no:不进行自动装配,手动设置Bean的依赖关系。
byName:根据Bean的名字进行自动装配。
byType:根据Bean的类型进行自动装配。
constructor:类似于byType,不过是应用于构造器的参数,如果正好有一个Bean与构造器的参数类型相同则可以自动装配,否则会导致错误。
autodetect:如果有默认的构造器,则通过constructor的方式进行自动装配,否则使用byType的方式进行自动装配。
(自动装配没有自定义装配方式那么精确,而且不能自动装配简单属性(基本类型、字符串等),在使用时应注意。)
@Resource 和 @Autowired 区别?分别用在什么场景?
(1)共同点:两者都可以写在字段和setter方法上。两者如果都写在字段上,那么就不需要再写setter方法。
(2)不同点:
@Autowired
@Autowired为Spring提供的注解,需要导入包org.springframework.beans.factory.annotation.Autowired;只按照byType注入。
@Autowired注解是按照类型(byType)装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它的required属性为false。如果我们想使用按照名称(byName)来装配,可以结合@Qualifier注解一起使用。
@Resource
@Resource默认按照ByName自动注入,由J2EE提供,需要导入包javax.annotation.Resource。
@Resource有两个重要的属性:name和type,而Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。所以,如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。
如果既不制定name也不制定type属性,这时将通过反射机制使用byName自动注入策略。
spring bean 生命周期
Spring框架是一个广泛使用的Java框架,它提供了对Java Bean生命周期的管理。理解Spring Bean的生命周期有助于更好地利用Spring框架进行开发。以下是Spring Bean生命周期的主要阶段:
1. 实例化(Instantiation)
Spring容器根据配置(XML文件、注解或Java配置类)创建Bean实例。这个过程通常是通过调用构造方法来完成的。
2. 属性赋值(Dependency Injection)
在Bean实例化之后,Spring容器会对Bean的属性进行赋值。这些属性可能是通过构造器注入或Setter方法注入。
3. 初始化(Initialization)
Bean的初始化过程包括以下几个步骤:
a. BeanNameAware 接口回调
如果Bean实现了BeanNameAware接口,Spring会调用setBeanName()方法,将配置文件中Bean的ID传递给它。
b. BeanFactoryAware 接口回调
如果Bean实现了BeanFactoryAware接口,Spring会调用setBeanFactory()方法,将BeanFactory传递给它。
c. ApplicationContextAware 接口回调
如果Bean实现了ApplicationContextAware接口,Spring会调用setApplicationContext()方法,将ApplicationContext传递给它。
d. BeanPostProcessor 前处理
Spring会调用所有注册的BeanPostProcessor的postProcessBeforeInitialization()方法,对Bean进行前处理。这个方法可以在Bean的初始化方法调用之前进行一些自定义操作。
e. InitializingBean 接口回调
如果Bean实现了InitializingBean接口,Spring会调用afterPropertiesSet()方法。这个方法在Bean的所有属性设置完成后被调用。
f. 自定义初始化方法
如果在配置文件中指定了Bean的自定义初始化方法(通过init-method属性),Spring会调用这个方法。
g. BeanPostProcessor 后处理
Spring会调用所有注册的BeanPostProcessor的postProcessAfterInitialization()方法,对Bean进行后处理。这个方法可以在Bean的初始化方法调用之后进行一些自定义操作。
4. 使用(Usage)
在Bean初始化完成之后,Spring容器将其交给应用程序使用。此时Bean已经完全准备好,可以进行各种业务操作。
5. 销毁(Destruction)
当Spring容器关闭时(例如,当应用程序上下文关闭时),它会对Bean进行销毁。销毁过程包括以下几个步骤:
a. DisposableBean 接口回调
如果Bean实现了DisposableBean接口,Spring会调用destroy()方法。这个方法用于在Bean销毁之前执行一些清理工作。
b. 自定义销毁方法
如果在配置文件中指定了Bean的自定义销毁方法(通过destroy-method属性),Spring会调用这个方法。这个方法用于在Bean销毁之前执行一些自定义清理工作。
总结
Spring Bean的生命周期可以总结为以下几个主要阶段:
- 实例化:创建Bean实例。
- 属性赋值:注入Bean的依赖属性。
- 初始化:
- 调用
BeanNameAware、BeanFactoryAware、ApplicationContextAware接口的相应方法。 - 调用
BeanPostProcessor的前处理方法。 - 调用
InitializingBean的afterPropertiesSet()方法。 - 调用自定义初始化方法。
- 调用
BeanPostProcessor的后处理方法。
- 调用
- 使用:Bean可以被应用程序使用。
- 销毁:
- 调用
DisposableBean的destroy()方法。 - 调用自定义销毁方法。
- 调用
通过理解和掌握这些生命周期阶段,开发人员可以更好地控制和管理Spring Bean的行为,从而编写出更加健壮和可维护的应用程序。
14、session何时被删除
在Web应用程序中,会话(Session)是用来存储用户会话所需数据的一种方式。它允许服务器在多个请求之间维护用户状态。Session的删除或失效主要有以下几种情况:
-
超时:大多数Web应用程序框架和服务器都有一种机制来设置会话的超时时间。如果用户在指定时间内没有进行新的请求,会话就会到期并自动删除。默认的超时时间因技术栈不同而异,例如,在Java的Servlet API中,默认的超时时间通常为30分钟。
-
手动删除:应用程序代码可以主动调用特定的方法来删除会话。例如,在Java中,可以通过
HttpSession.invalidate()方法来失效一个会话。 -
服务器重启:如果服务器或应用程序重启,未持久化的会话信息通常会丢失。但一些服务器和框架支持会话持久化,可以在重启后恢复会话。
-
浏览器关闭:在某些情况下,如果会话依赖于客户端的cookie来维护,那么关闭浏览器可能会删除这些cookie,从而终止会话。这取决于cookie的类型,如果是会话cookie(不设置过期时间),则浏览器关闭时通常会被删除。
-
会话存储清理:为了防止服务器上的会话存储变得过大,许多Web服务器都会定期清理旧的或不活跃的会话。
-
用户登出:在用户主动登出应用程序时,通常会程序性地结束用户的会话,来保护用户的安全。
-
容量限制:如果应用程序设置了会话存储的容量限制,一旦达到这个限制,一些旧的会话可能会被删除,以便为新会话腾出空间。
-
会话替换策略:在一些高负载的系统中,为了保证性能和资源使用,可能会实现某种会话替换策略,例如LRU(最近最少使用)算法,会自动删除最不活跃的会话。
实现
在不同的语言和框架中,会话的超时和删除的实现方式可能会有所不同。以下是一些常见的实现:
- Java Servlet API:可以在web.xml中或通过
HttpSessionAPI设置会话超时。 - ASP.NET:可以在Web.config文件或通过代码设置会话状态。
- PHP:可以在php.ini文件、通过
session_set_cookie_params()或在代码中设置会话超时。 - Node.js:在使用Express框架及其中间件如express-session时,可以配置会话的存储、超时和删除策略。
代码示例
以下是Java Servlet API中设置会话超时的代码示例:
HttpSession session = request.getSession();
session.setMaxInactiveInterval(30*60); // 设置会话超时时间为30分钟
会话超时是Web应用程序安全的重要方面之一,但设置超时值时需要在用户体验和安全性之间做出权衡。如果超时太短,用户可能会因为频繁的重新登录而感到不便;如果超时太长,又可能增加未授权访问的风险。
15、线程池
线程池的7个核心参数如下:
1、核心线程数(CorePoolSize):线程池中所拥有的线程数,即使线程处于空闲状态,也会一直存在,除非设置了allowCoreThreadTimeOut参数。
2、最大线程数(MaximumPoolSize):线程池中所允许的最大线程数,当任务数超过了核心线程数并且工作队列已满时,线程池就会创建新的线程来执行任务,直到最大线程数达到上限。
3、线程空闲时间(keepAliveTime):当线程池中的线程数量超过了核心线程数时,如果这些线程在指定的时间内没有执行任务,那么这些线程就会被回收,直到线程池中的线程数等于核心线程数。
4、时间单位(unit):用于指定线程空闲时间的时间单位,例如毫秒、秒、分钟等。
5、工作队列(workQueue):用于存放等待执行的任务的阻塞队列,当线程池中的线程已满时,新的任务会被存放到工作队列中等待执行。
6、线程工厂(threadFactory):用于创建新的线程,可以自定义线程的名称、优先级、是否为守护线程等属性。
7、饱和策略(handler):当线程池和工作队列都已满时,用于处理新的任务的策略,常见的策略有直接抛出异常、丢弃任务、丢弃队列中最早的任务、将任务分配给调用线程来执行等。
线程的生命周期
线程池饱和策略是指当线程池中所有线程都在工作且工作队列也已经满了时,新提交的任务该如何处理。常见的线程池饱和策略包括:
线程池的拒绝策略
1.ThreadPoolExecutor.AbortPolicy (使用最好使用默认的拒绝策略。)
线程池的默认拒绝策略为AbortPolicy,即丢弃任务并抛出RejectedExecutionException异常(即后面提交的请求不会放入队列也不会直接消费并抛出异常);
2.ThreadPoolExecutor.DiscardPolicy
丢弃任务,但是不抛出异常。如果线程队列已满,则后续提交的任务都会被丢弃,且是静默丢弃(也不会抛出任何异常,任务直接就丢弃了)。
3.ThreadPoolExecutor.DiscardOldestPolicy
丢弃队列最前面的任务,然后重新提交被拒绝的任务(丢弃掉了队列最前的任务,并不抛出异常,直接丢弃了)。
4.ThreadPoolExecutor.CallerRunsPolicy
由调用线程处理该任务(不会丢弃任务,最后所有的任务都执行了,并不会抛出异常)
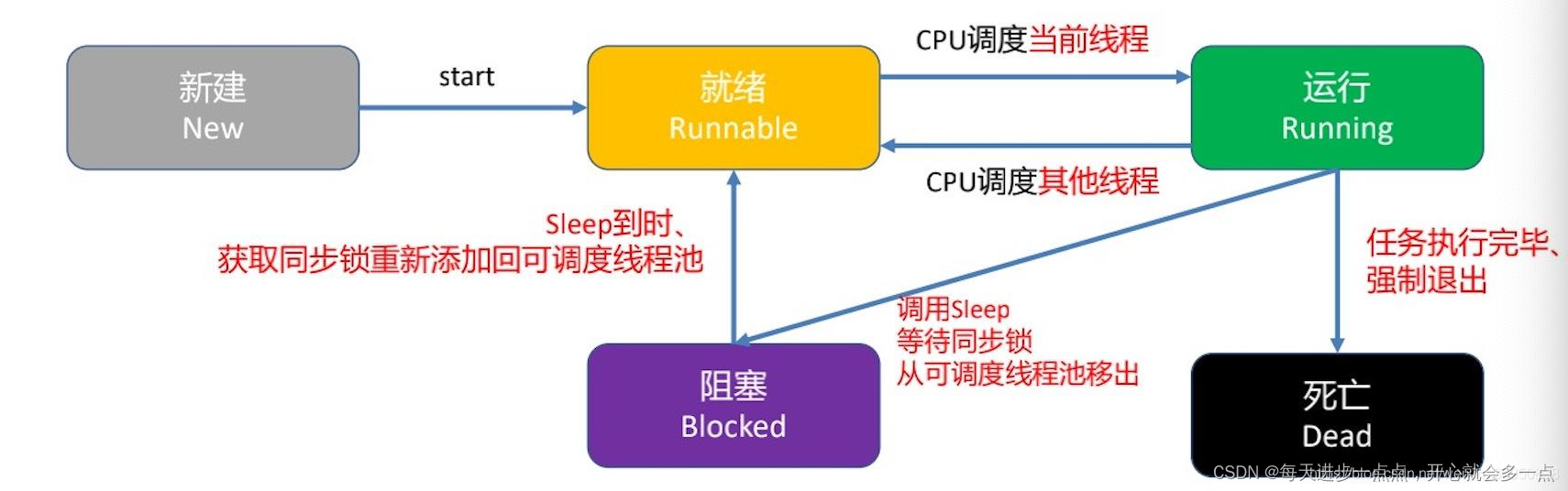
线程池工作原理:
16、JSP有9个内置对象
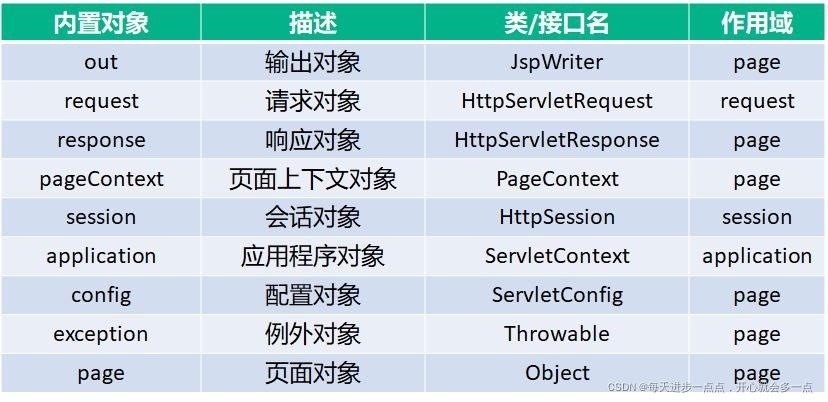
JSP有9个内置对象:
- request:封装客户端的请求,其中包含来自GET或POST请求的参数;
- response:封装服务器对客户端的响应;
- pageContext:通过该对象可以获取其他对象;
- session:封装用户会话的对象;
- application:封装服务器运行环境的对象;
- out:输出服务器响应的输出流对象;
- config:Web应用的配置对象;
- page:JSP页面本身(相当于Java程序中的this);
- exception:封装页面抛出异常的对象。
四大域对象: page<request<session<application
JSP中的四种作用域分别是:
page作用域:在当前JSP页面中有效,即只能在当前JSP页面的任何地方访问。可以使用pageContext对象来访问page作用域中的变量。
request作用域:在同一个HTTP请求中有效,即在同一个请求中的所有JSP页面和Servlet之间共享。可以使用request对象来访问request作用域中的变量。
session作用域:在同一个HTTP会话中有效,即在同一个浏览器会话期间的所有请求之间共享。可以使用session对象来访问session作用域中的变量。
application作用域:在整个Web应用程序中有效,即在所有JSP页面和Servlet之间共享。可以使用application对象来访问application作用域中的变量。
Lock 是 synchronized 的扩展版,Lock 提供了无条件的、可轮询的(tryLock 方法)、定时的(tryLock 带参方法)、可中断的(lockInterruptibly)、可多条件队列的(newCondition 方法)锁操作。另外 Lock 的实现类基本都支持非公平锁(默认)和公平锁,synchronized 只支持非公平锁
17、修饰代码块时,执行的顺序
修饰代码块时,执行的顺序
(加载的顺序)如下:
父类静态变量
父类静态代码块
子类静态变量
子类静态代码块
父类普通变量
父类普通代码块
父类构造函数
子类普通变量
子类普通代码块
子类构造函数
总结一下就是,静态的先被加载(在这个基础上,父类优先于子类,在父类优先于子类的基础上,变量优先于代码块优先于构造函数(有的话))
18、Mysql
什么是慢查询?
所有执行时间超过 long_query_time 秒的所有查询或不适用于索引的查询。
long_query_time默认时间是10秒,即超过10秒的查询都认为是慢查询。
当创建(a,b,c)复合索引时,想要索引生效的话,只能使用 a和ab、ac和abc三种组合!
回表
“回表”这个术语通常与数据库查询优化相关,特别是在关系数据库中。它指的是在使用索引进行查询后,还需要再访问一次表数据以获取所需的完整记录。这种情况在使用非聚簇索引(非聚集索引)时比较常见。
回表的工作原理
在关系数据库中,索引是为了加速查询而创建的辅助数据结构。索引中存储了表中部分列的数据和这些数据所在记录的指针。然而,索引通常并不包含表的所有列,因此,当查询需要访问的列不在索引中时,即使利用索引可以快速定位到一些记录,数据库系统仍然需要“回表”访问实际的表数据以获取完整的记录。
示例
假设有一个包含以下列的表 users:
idnameemailage
现在,为了加速根据 name 字段进行查询,我们在 name 字段上创建了一个非聚簇索引。非聚簇索引中包含 name 字段及其对应的 id (或其他指向实际记录的指针)。
如果我们执行以下查询:
SELECT name, email FROM users WHERE name = 'Alice';
数据库系统会执行以下步骤:
- 使用索引查找:首先利用
name字段上的索引快速找到name = 'Alice'的记录。这一步可以高效地定位到满足条件的记录。 - 回表获取数据:由于索引中只包含
name和id,而查询还需要email字段的数据,数据库系统需要通过索引中的id,再访问一次实际的表数据以获取email列的值。
聚簇索引与回表的关系
如果在 id 上创建了聚簇索引,因为聚簇索引将数据按索引顺序存储在表中,所以表数据和索引数据在物理上是相同的。这意味着当查询包含索引字段时,不需要回表,因为所有所需的数据都已经在聚簇索引中。
例如,假设在 id 上有一个聚簇索引,执行以下查询:
SELECT id, name FROM users WHERE id = 1;
由于 id 是聚簇索引,数据库系统可以直接在聚簇索引中找到 id = 1 对应的 name,不需要再次访问表数据。
避免回表的策略
-
覆盖索引:如果索引中包含查询所需的所有列,回表操作可以避免。这样的索引被称为覆盖索引。例如,如果查询需要
name和email,可以在name, email上创建一个复合索引。 -
适当的索引设计:根据查询的频次和类型设计索引,以减少不必要的回表操作。例如,可以结合查询需求,在常用的查询字段上创建复合索引。
-
选择合适的索引类型:在某些情况下,使用聚簇索引可能会比非聚簇索引更有效,特别是当查询经常需要访问整个记录时。
总结
回表是数据库查询优化中的一个重要概念,主要发生在使用非聚簇索引时,当查询需要访问的列不在索引中时,数据库系统需要回表获取完整的记录。通过合理设计索引和使用覆盖索引,可以减少回表操作,提高查询效率。理解回表的工作原理和优化策略,有助于更好地进行数据库性能调优。
回表就是先通过数据库索引扫描出数据所在的行,再通过行主键id取出索引中未提供的数据,即基于非主键索引的查询需要多扫描一棵索引树.
回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
跳表
跳表(Skip List)是一种基于链表的数据结构,旨在提供一种在链表上的快速查找、插入和删除操作。跳表通过增加多级索引来实现这一目标,使得查找效率接近于平衡二叉树。它是由William Pugh在1990年发明的。
跳表的结构
跳表的基本思想是在原始的链表基础上,增加多级“跳跃”节点,形成多层索引,使得可以跳过一些节点进行快速查找。这些层次由多个“塔”组成,每个塔由不同高度的节点构成。
跳表的特性
- 层级结构:跳表由多层链表组成,每一层都包含一个有序的元素子集。最低层(第0层)包含所有元素,顶层包含最少的元素。
- 概率性:每个元素在跳表中的层级是随机确定的,通常使用一种概率性算法(如抛硬币)决定每个元素在多少层中出现。
- 平衡性:跳表的层数和元素数目以对数关系增长,保持了整体的平衡性。
跳表的操作
1. 查找(Search)
要查找某个元素,从顶层开始,根据节点中的值进行比较,沿着水平指针前进。如果在该层无法前进(即下一个节点值大于目标值),则下降到下一层继续查找,直到找到目标元素或确认元素不存在。
2. 插入(Insert)
插入操作也从顶层开始。首先找到插入位置,然后使用概率性算法确定新节点的层数,并将新节点插入到相应层的链表中。插入完成后,需要更新相关节点的前向和后向指针。
3. 删除(Delete)
删除操作类似于查找操作。首先找到要删除的节点,然后在所有包含该节点的层中将其删除,最后更新相关节点的前向和后向指针。
跳表的时间复杂度
由于跳表的多级索引结构,查找、插入和删除操作的期望时间复杂度为 (O(\log n)),其中 (n) 是元素的总数。这使得跳表在处理动态数据时表现出色。
跳表的优点
- 简单性:相比于平衡树等复杂数据结构,跳表的实现较为简单。
- 动态性能:跳表能够高效地处理动态插入和删除操作。
- 随机性:跳表的层级结构使用随机算法,平均性能稳定,不依赖于数据的初始排列。
跳表的示意图
下图展示了一个跳表的示意图。每一层都是一个链表,顶层包含的元素最少,底层包含所有元素。
Level 3: [1]----------------------->[10]
Level 2: [1]-------->[6]----------->[10]
Level 1: [1]->[3]->[6]------>[10]->[15]
Level 0: [1]->[3]->[6]->[7]->[9]->[10]->[15]->[17]->[20]
在这个示意图中,查找元素7的过程如下:
- 从顶层开始,比较
7和10,7小于10,下降到下一层。 - 在第二层,比较
7和6,7大于6,向右移动到6的位置。 - 继续比较
7和10,7小于10,下降到下一层。 - 在第一层,比较
7和6,7大于6,向右移动到6的位置。 - 继续比较
7和10,7小于10,下降到下一层。 - 在第零层,比较
7和6,7大于6,向右移动到6的位置。 - 继续比较
7和7,找到元素7。
总结
跳表是一种高效的数据结构,通过多级索引实现快速查找、插入和删除操作。相较于平衡树等复杂结构,跳表的实现简单且性能稳定,非常适合动态数据的处理。理解跳表的工作原理和实现方法,可以帮助开发者更好地选择和应用合适的数据结构来优化程序性能。
N+1
“N+1” 查询问题是一种常见的数据库性能问题,特别是在使用ORM(对象关系映射)框架时。它的具体表现是:在执行一个查询时,导致额外的N次单独查询,从而导致非常低效的数据库访问模式。
N+1 查询问题
假设你有两个相关联的表,例如:
users表:包含用户信息。orders表:包含用户的订单信息,每个订单都有一个外键user_id指向users表。
场景描述
假设你希望查询所有用户及其对应的订单。如果使用不当的查询模式,会导致"N+1"查询问题。例如:
-
初始查询(1查询):首先你执行一个查询,从
users表中获取所有用户:SELECT * FROM users; -
后续查询(N查询):对于每个用户,你再执行一个查询,从
orders表中获取这个用户的所有订单:SELECT * FROM orders WHERE user_id = ?;这里的
?是每个用户的id,所以如果有 N 个用户,你将会执行 N 次这种查询。
这样,总共执行了 1 + N 个查询,极大地增加了数据库的负载和查询时间。
示例
假设有 3 个用户,你的查询模式如下:
-- 初始查询,获取所有用户
SELECT * FROM users;
-- 对于每个用户,再执行一次查询,获取其订单
SELECT * FROM orders WHERE user_id = 1;
SELECT * FROM orders WHERE user_id = 2;
SELECT * FROM orders WHERE user_id = 3;
这里总共执行了 1 + 3 = 4 次查询。
解决方案
解决N+1查询问题的典型方法是使用连接查询(JOIN)或批量查询。
1. 使用连接查询(JOIN)
通过使用SQL的JOIN操作,可以在一次查询中获取所有需要的数据:
SELECT users.*, orders.*
FROM users
LEFT JOIN orders ON users.id = orders.user_id;
这样,只需要一次查询,就可以获取所有用户和他们的订单。
2. 使用批量查询
在某些ORM框架中,可以使用批量查询或预加载(eager loading)来解决N+1查询问题。例如,在Hibernate中,可以使用fetch join或配置fetch策略为EAGER。
-
Hibernate 示例:
// 使用HQL的fetch join String hql = "SELECT u FROM User u LEFT JOIN FETCH u.orders"; List<User> users = session.createQuery(hql, User.class).getResultList(); -
JPA 示例:
@Entity public class User { @OneToMany(fetch = FetchType.EAGER) private Set<Order> orders; // other fields and methods }
3. 使用批量加载
一些ORM框架提供了批量加载的功能,可以在一次查询中获取所有相关的数据。例如,Django ORM提供了select_related和prefetch_related方法来解决N+1查询问题。
-
Django 示例:
# 使用select_related users = User.objects.select_related('orders').all() # 使用prefetch_related users = User.objects.prefetch_related('orders').all()
总结
N+1 查询问题是数据库性能优化中的一个重要问题,特别是在使用ORM框架时。理解并识别这种问题,可以帮助开发者通过使用连接查询或批量查询等方法来优化数据库访问,从而显著提高应用的性能。通过合理设计查询和使用ORM提供的批量加载功能,可以有效地避免N+1查询问题。
聚集索引和非聚集索引的根本区别是表记录的排列顺序与索引的排列顺序是否一致
聚集索引
聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序。
非聚集索引
非聚集索引制定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致,两种索引都采用B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。
mysql引擎
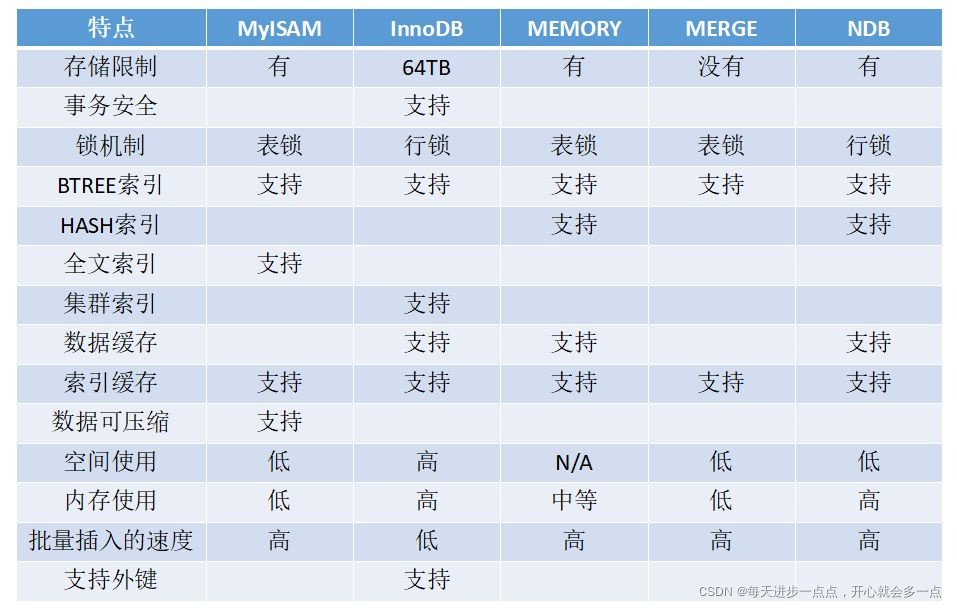
MySQL
Innodb引擎,Innodb引擎提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。
它的设计的目标就是处理大数据容量的数据库系统。它本身实际上是基于Mysql后台的完整的系统。
Mysql运行的时候,Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是,该引擎是不支持全文搜索的。
同时,启动也比较的慢,它是不会保存表的行数的。当进行Select count(*) from table指令的时候,需要进行扫描全表。
所以当需要使用数据库的事务时,该引擎就是首选。由于锁的粒度小,写操作是不会锁定全表的。所以在并发度较高的场景下使用会提升效率的。
MyIASM引擎,它是MySql的默认引擎,但不提供事务的支持,也不支持行级锁和外键。
因此当执行Insert插入和Update更新语句时,即执行写操作的时候需要锁定这个表。所以会导致效率会降低。
不过和Innodb不同的是,MyIASM引擎是保存了表的行数,于是当进行Select count(*) from table语句时,可以直接的读取已经保存的值而不需要进行扫描全表。
所以,如果表的读操作远远多于写操作时,并且不需要事务的支持的。可以将MyIASM作为数据库引擎的首先。
c.大容量的数据集时趋向于选择Innodb。因为它支持事务处理和故障的恢复。Innodb可以利用数据日志来进行数据的恢复。主键的查询在Innodb也是比较快的。
d.大批量的插入语句时(这里是INSERT语句)在MyIASM引擎中执行的比较的快,但是UPDATE语句在Innodb下执行的会比较的快,尤其是在并发量大的时候。
oracle
oracle中不存在引擎的概念,数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
MyIASM引擎,它是MySql的默认引擎,但不提供事务的支持,也不支持行级锁和外键。
Innodb引擎,Innodb引擎提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。
MySQL默认是自动提交
Oracle默认不自动提交,需要用户手动提交,需要在写commit;指令或者点击commit按钮
mysql的默认隔离可重复读,Oracle的默认隔离读已提交 互联网项目一般将隔离级别设为读已提交
CAS 实现:
Java 中java.util.concurrent.atomic包下面的原子变量使用了乐观锁的一种 CAS 实现方式。
版本号控制: 一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。
当数据被修改时,version 值会+1。当线程A要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值与当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
Oracle数据库可以以字节或者字符来存储字符串的,一般来说默认是存储字节
UTF-8:一个汉字 = 3个字节,英文一个字母占用一个字节
GBK: 一个汉字 = 2个字节,英文一个字母占用一个字节
总结:oracle 中varchar2(10) 既10个字节3个汉字
mysql 中varchar(10) 既10个字符10个汉字
锁
Synchronized,它就是一个:非公平,悲观,独享,互斥,可重入的重量级锁
ReentrantLock,它是一个:默认非公平但可实现公平的,悲观,独享,互斥,可重入,重量级锁。
ReentrantReadWriteLocK,它是一个,默认非公平但可实现公平的,悲观,写独享,读共享,读写,可重入,重量级锁。
http和https区别 ssl证书加密
19、RabbitMQ
RabbitMQ消息堆积怎么处理?
答:
增加消费者的处理能力(例如优化代码),或减少发布频率
单纯升级硬件不是办法,只能起到一时的作用
考虑使用队列最大长度限制,RabbitMQ 3.1支持
给消息设置年龄,超时就丢弃
默认情况下,rabbitmq消费者为单线程串行消费,设置并发消费两个关键属性concurrentConsumers和prefetchCount,concurrentConsumers设置的是对每个listener在初始化的时候设置的并发消费者的个数,prefetchCount是每次一次性从broker里面取的待消费的消息的个数
建立新的queue,消费者同时订阅新旧queue
生产者端缓存数据,在mq被消费完后再发送到mq
打破发送循环条件,设置合适的qos值,当qos值被用光,而新的ack没有被mq接收时,就可以跳出发送循环,去接收新的消息;
消费者主动block接收进程,消费者感受到接收消息过快时主动block,利用block和unblock方法调节接收速率,当接收线程被block时,跳出发送循环。
新建一个topic,partition是原来的10倍;然后写一个临时的分发数据的consumer程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的10倍数量的queue;
接着临时征用10倍的机器来部署consumer,每一批consumer消费一个临时queue的数据;等快速消费完积压数据之后,得恢复原先部署架构,重新用原先的consumer机器来消费消息;
RabbitMQ的消息丢失解决方案?
答:
消息持久化:Exchange 设置持久化:durable:true;Queue 设置持久化;Message持久化发送。
ACK确认机制:消息发送确认;消息接收确认。
常见6种负载均衡算法:轮询,随机,源地址哈希,加权轮询,加权随机,最小连接数。
nginx5种负载均衡算法:轮询,weight,ip_hash,fair(响应时间),url_hash
dubbo负载均衡算法:随机,轮询,最少活跃调用数,一致性Hash
竞态条件:指设备或系统出现不恰当的执行时序,而得到不正确的结果。
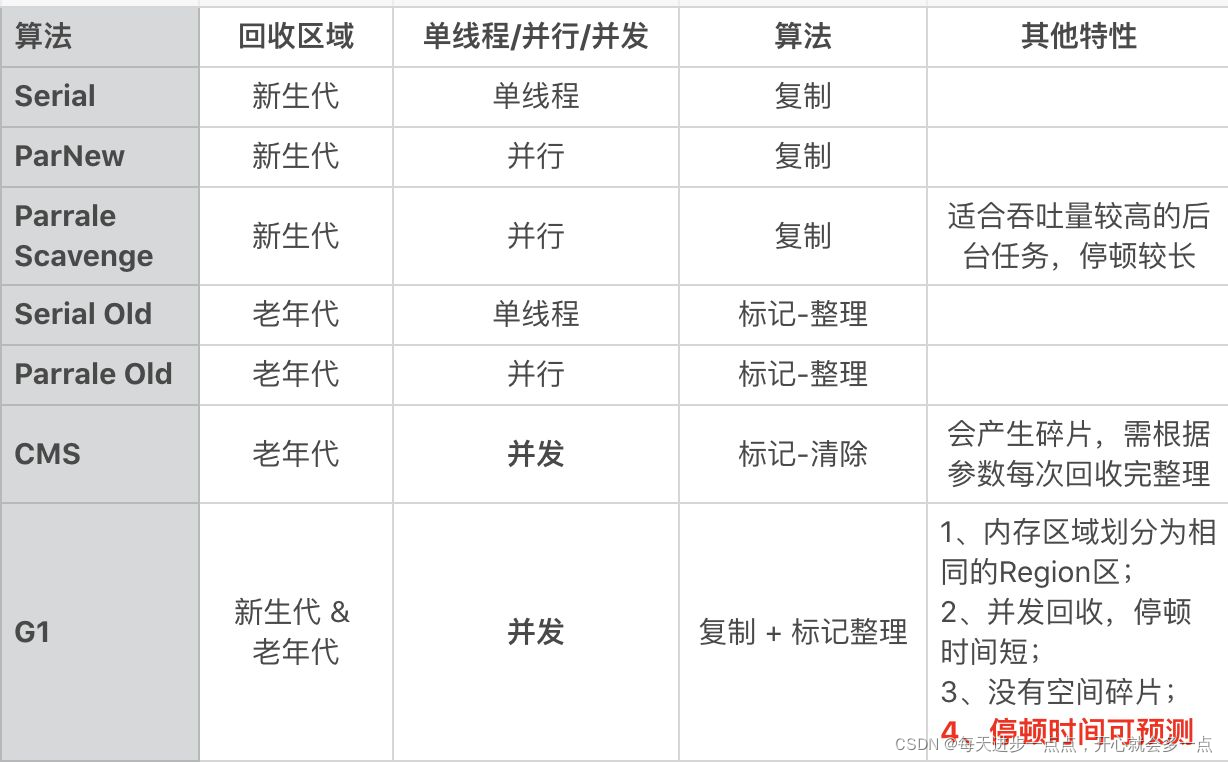
G1垃圾收集参数 -XX:MaxGCPauseMillis=N,(默认200毫秒,与throughput收集器有所不同)
吞吐量跟MaxGCPauseMillis之间做一个平衡。如果MaxGCPauseMillis设置的过小,那么GC就会频繁,吞吐量就会下降。如果MaxGCPauseMillis设置的过大,应用程序暂停时间就会变长。G1的默认暂停时间是200毫秒,我们可以从这里入手,调整合适的时间。
TDD:测试驱动开发(Test-Driven Development)
BDD:行为驱动开发(Behavior Driven Development)
ATDD:验收测试驱动开发(Acceptance Test Driven Development)
DDD:领域驱动开发(Domain Drive Design)
20、粘包、拆包
粘包、拆包发生原因
1、要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生拆包。
2、待发送数据大于MSS(最大报文长度),TCP在传输前将进行拆包。
3、要发送的数据小于TCP发送缓冲区的大小,TCP将多次写入缓冲区的数据一次发送出去,将会发生粘包。
4、接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包。
粘包、拆包解决办法
解决问题的关键在于如何给每个数据包添加边界信息,常用的方法有如下几个:
1、发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度,这样接收端在接收到数据后,通过读取包首部的长度字段,便知道每一个数据包的实际长度了。
2、发送端将每个数据包封装为固定长度(不够的可以通过补0填充),这样接收端每次从接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。
3、可以在数据包之间设置边界,如添加特殊符号,这样,接收端通过这个边界就可以将不同的数据包拆分开。
21、什么是XSS攻击?什么是SQL注入攻击?什么是CSRF攻击?
- XSS(Cross Site Script,跨站脚本攻击)是向网页中注入恶意脚本在用户浏览网页时在用户浏览器中执行恶意脚本的攻击方式。
跨站脚本攻击分有两种形式:
反射型攻击(诱使用户点击一个嵌入恶意脚本的链接以达到攻击的目标,目前有很多攻击者利用论坛、微博发布含有恶意脚本的URL就属于这种方式)
持久型攻击(将恶意脚本提交到被攻击网站的数据库中,用户浏览网页时,恶意脚本从数据库中被加载到页面执行,QQ邮箱的早期版本就曾经被利用作为持久型跨站脚本攻击的平台)。
XSS虽然不是什么新鲜玩意,但是攻击的手法却不断翻新,防范XSS主要有两方面:消毒(对危险字符进行转义)和HttpOnly(防范XSS攻击者窃取Cookie数据)。
- SQL注入攻击是注入攻击最常见的形式(此外还有OS注入攻击(Struts 2的高危漏洞就是通过OGNL实施OS注入攻击导致的)),当服务器使用请求参数构造SQL语句时,恶意的SQL被嵌入到SQL中交给数据库执行。
SQL注入攻击需要攻击者对数据库结构有所了解才能进行,攻击者想要获得表结构有多种方式:
(1)如果使用开源系统搭建网站,数据库结构也是公开的(目前有很多现成的系统可以直接搭建论坛,电商网站,虽然方便快捷但是风险是必须要认真评估的);
(2)错误回显(如果将服务器的错误信息直接显示在页面上,攻击者可以通过非法参数引发页面错误从而通过错误信息了解数据库结构,Web应用应当设置友好的错误页,一方面符合最小惊讶原则,一方面屏蔽掉可能给系统带来危险的错误回显信息);
(3)盲注。防范SQL注入攻击也可以采用消毒的方式,通过正则表达式对请求参数进行验证,此外,参数绑定也是很好的手段,这样恶意的SQL会被当做SQL的参数而不是命令被执行,JDBC中的PreparedStatement就是支持参数绑定的语句对象,从性能和安全性上都明显优于Statement。
- CSRF攻击(Cross Site Request Forgery,跨站请求伪造)是攻击者通过跨站请求,以合法的用户身份进行非法操作(如转账或发帖等)。
CSRF的原理是利用浏览器的Cookie或服务器的Session,盗取用户身份.
防范CSRF的主要手段是识别请求者的身份,主要有以下几种方式:
(1)在表单中添加令牌(token);
(2)验证码;
(3)检查请求头中的Referer(前面提到防图片盗链接也是用的这种方式)。
令牌和验证都具有一次消费性的特征,因此在原理上一致的,但是验证码是一种糟糕的用户体验,不是必要的情况下不要轻易使用验证码,目前很多网站的做法是如果在短时间内多次提交一个表单未获得成功后才要求提供验证码,这样会获得较好的用户体验。
22、反射中,Class.forName和classloader的区别
在Java反射机制中,Class.forName()和类加载器(ClassLoader)都可以用来加载类,但它们之间存在一些关键的区别。下面两者的差异,并提供相关的源码上下文。
Class.forName()
Class.forName()是一个静态方法,当你知道一个类的全路径名时,你可以使用这个方法来动态加载这个类。Class.forName()不仅将类加载到JVM中,而且还会对类进行初始化,即执行静态代码块。
Class<?> clazz = Class.forName("com.example.MyClass");
这行代码做了两件事情:
- 加载类:将
com.example.MyClass类加载到JVM中。 - 初始化类:执行
com.example.MyClass类的静态初始化器,即运行静态代码块和静态字段初始化。
Class.forName()有一个重载版本,允许你指定是否初始化类:
Class<?> clazz = Class.forName("com.example.MyClass", false, this.getClass().getClassLoader());
在这个重载方法中,第二个参数是一个布尔值,表示是否要初始化类。第三个参数是使用的ClassLoader。
ClassLoader
ClassLoader是Java中的一个抽象类,它负责动态加载类和资源。不同的类加载器有不同的加载策略。例如,系统类加载器会加载classpath上的类,网络类加载器可以加载网络上的类等。
使用ClassLoader加载类通常是这样的:
ClassLoader classLoader = this.getClass().getClassLoader();
Class<?> clazz = classLoader.loadClass("com.example.MyClass");
loadClass()方法做的事情:
- 加载类:将
com.example.MyClass类加载到JVM中。 - 不初始化类:与
Class.forName()不同,使用ClassLoader加载类时,默认不会初始化类。也就是说,静态代码块不会执行。
源码层面的区别
在JDK的源码中,我们可以看到Class.forName()最终也是通过ClassLoader来实现类的加载的,但在加载完毕后会立即初始化类:
// Class.java 的部分源码
public static Class<?> forName(String className) throws ClassNotFoundException {
Class<?> caller = Reflection.getCallerClass();
return forName0(className, true, ClassLoader.getClassLoader(caller), caller);
}
// 这是一个本地方法,涉及到JVM内部的实现
private static native Class<?> forName0(String name, boolean initialize,
ClassLoader loader,
Class<?> caller) throws ClassNotFoundException;
而ClassLoader的loadClass()方法则通常不负责类的初始化:
// ClassLoader.java 的部分源码
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
在上面的代码中,resolve参数表示是否要链接类,这是类加载过程中的一个步骤,但即使是链接,也不会导致类的初始化;初始化是发生在链接之后的另一个阶段。
总结
Class.forName()会加载并初始化类,它更常用于加载JDBC驱动程序和需要立即执行静态代码块的场景。ClassLoader.loadClass()只会加载类而不会初始化,这在很多需要动态加载但不需要立即执行静态代码块的场景中非常有用。
选择使用哪一个通常取决于你是否需要初始化类。如果你需要触发静态初始化,那么使用Class.forName();如果你只是想加载类而不初始化它们,那么使用ClassLoader的loadClass()方法更为合适。
23、微服务
微服务的优点:
代码的独立。各自团队负责各自微服务的代码维护,互相不会影响,也不容易造成代码冲突。
也包括code review、还有功能测试。下载代码也不需要下载全部的代码。
如果共用代码,有的功能没有开发好,有的小功能已经开发好了,已经开发好的功能没法单独上线。除非采用很多分支,拆分上线。
微服务系统间的独立。系统之间相对独立,非核心系统的发版或者异常,不会影响整个系统核心业务的运行。更加敏捷。
数据的独立。各自服务负责各自的数据,特别是机密数据不需要开放给无关的人员。
业务的切分,降低了单个服务的复杂性,负责某一服务的开发人员,只需要了解自己相关的业务。快速上手,focus在各自的业务上。
人的独立。团队管理更方便。比如招一个人负责商品的服务,则该小伙伴不需要了解支付、优惠券、库存相关的业务场景,只需要清楚商品相关的业务规则就可以了
产出于Spring大家族,Spring在企业级开发框架中无人能敌,来头很大,可以保证后续的更新、完善
组件丰富,功能齐全。Spring Cloud 为微服务架构提供了非常完整的支持。例如、配置管理、服务发现、断路器、微服务网关等;
Spring Cloud 社区活跃度很高,教程很丰富,遇到问题很容易找到解决方案
服务拆分粒度更细,耦合度比较低,有利于资源重复利用,有利于提高开发效率
可以更精准的制定优化服务方案,提高系统的可维护性
减轻团队的成本,可以并行开发,不用关注其他人怎么开发,先关注自己的开发
微服务可以是跨平台的,可以用任何一种语言开发
适于互联网时代,产品迭代周期更短
Eureka:各个服务启动时,Eureka Client都会将服务注册到Eureka Server,并且Eureka Client还可以反过来从Eureka Server拉取注册表,从而知道其他服务在哪里
Ribbon:服务间发起请求的时候,基于Ribbon做负载均衡,从一个服务的多台机器中选择一台
Feign:基于Feign的动态代理机制,根据注解和选择的机器,拼接请求URL地址,发起请求
Hystrix:发起请求是通过Hystrix的线程池来走的,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题
Zuul:如果前端、移动端要调用后端系统,统一从Zuul网关进入,由Zuul网关转发请求给对应的服务
微服务通常使用以下组件来实现实时更新配置:
配置中心:微服务架构中的配置中心可以集中管理所有微服务的配置。例如,Spring Cloud Config、Consul、ZooKeeper等。
消息总线:使用消息总线来通知微服务应用程序配置已更改。例如,Spring Cloud Bus、Kafka等。
服务注册中心:微服务可以在服务注册中心中注册并发现其他微服务。例如,Eureka、Consul、ZooKeeper等。
通过使用这些组件,微服务可以在不需要重启服务的情况下更新配置。当配置更改时,配置中心将通知服务应用程序,并通过消息总线将更改传播到所有微服务。这使得微服务架构更加灵活和可扩展。
23、redis
maxmemory-policy 六种方式
volatile-lru:只对设置了过期时间的key进行LRU(默认值)
allkeys-lru : 删除lru算法的key
volatile-random:随机删除即将过期key
allkeys-random:随机删除
volatile-ttl : 删除即将过期的
noeviction : 永不过期,返回错误
I/O 多路复用模型是利用select、poll、epoll可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中唤醒,
于是程序就会轮询一遍所有的流(epoll是只轮询那些真正发出了事件的流),依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,
“复用”指的是复用同一个线程。
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),
且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
缓存穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
1、接口校验。在正常业务流程中可能会存在少量访问不存在 key 的情况,但是一般不会出现大量的情况,所以这种场景最大的可能性是遭受了非法攻击。可以在最外层先做一层校验:用户鉴权、数据合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对非正整数直接过滤等等。
2、缓存空值。当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时间,该时间需要根据产品业务特性来设置。
3、布隆过滤器。使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
设置热点数据永远不过期。
加互斥锁
缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,
缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
设置热点数据永远不过期。
FIFO ,first in first out ,最先进入缓存的数据在缓存空间不够情况下(超出最大元素限制时)会被首先清理出去
LFU , Less Frequently Used ,一直以来最少被使用的元素会被被清理掉。这就要求缓存的元素有一个hit 属性,在缓存空间不够得情况下,hit 值最小的将会被清出缓存。
LRU ,Least Recently Used ,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,
24、什么是双亲委派机制
双亲委派机制(Parent Delegation Model)是Java类加载器(ClassLoader)的一个基本行为,它是Java为了保证Java应用的稳定运行和安全所采用的一种机制。这个机制是在Sun公司的工程师们在JDK 1.2时期引入的。下面介绍双亲委派机制的工作原理和目的。
工作原理:
当一个ClassLoader需要加载一个类时,它不会先尝试自己去加载这个类,而是把这个请求委派给父类加载器去执行。如果父类加载器无法完成这个加载(它不认识这个类),子类加载器才会尝试自己去加载。
通常情况下,Java使用的类加载器有:
- 引导类加载器(Bootstrap ClassLoader):它是最顶层的类加载器,负责加载JVM基础核心类库(如
rt.jar),无法直接被Java代码访问。 - 扩展类加载器(Extension ClassLoader):它负责加载JVM扩展目录中的类库。
- 系统类加载器(System ClassLoader):它根据Java应用的classpath来加载Java类。
双亲委派模型的具体流程:
- 当
System ClassLoader需要加载一个类时,它不会自己直接去加载,而是委托给其父类加载器(Extension ClassLoader)去尝试加载。 Extension ClassLoader接到请求后,也不会自己直接去加载,而是委托给Bootstrap ClassLoader去尝试加载。- 如果
Bootstrap ClassLoader可以完成这个类的加载,就返回给Extension ClassLoader,然后再返回给System ClassLoader。这个时候,整个加载请求就完成了。 - 如果
Bootstrap ClassLoader无法加载这个类(比如它不是核心类库中的类),请求就会返回给Extension ClassLoader。Extension ClassLoader会尝试去加载这个类,如果它也失败了,请求最终会返回给System ClassLoader。 System ClassLoader最后会尝试自己去classpath上加载这个类。如果还是失败,就会抛出ClassNotFoundException异常。
目的:
双亲委派模型的设计有以下目的:
- 避免类的重复加载:由于在委派链上的类加载器都是单例的,因此一个类一旦被加载,就可以被所有的子加载器所共享。
- 保护程序安全:防止核心API被随意篡改。例如,通过自定义String类来进行替换,如果没有双亲委派机制,那么自定义的String类可能会代替核心库中的String,这可能会造成严重的安全问题。
- 保护程序稳定运行:通过保证使用的都是同一个版本的类(通过同一个类加载器加载)来避免类的冲突。
代码实现:
在JDK源码中,ClassLoader类中的loadClass方法就实现了双亲委派模型:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 首先,检查请求的类是否已经被加载过
Class<?> c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
// 如果存在父类加载器,则委托父类加载器加载
c = parent.loadClass(name, false);
} else {
// 如果没有父类加载器,则使用引导类加载器进行加载
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 如果父类加载器和引导类加载器都不能完成加载,那么异常被捕获
}
if (c == null) {
// 如果所有的上级加载器都不能完成加载,当前加载器尝试自己加载这个类
c = findClass(name);
}
}
if (resolve) {
// 链接请求的类
resolveClass(c);
}
return c;
}
}
双亲委派模型的破坏:
尽管双亲委派模型对于Java类加载机制十分重要,但在某些场景下需要打破这一模型。比如,OSGi环境中的类加载器行为、Java的SPI(Service Provider Interface)机制、热部署功能等,这些场景下就需要设计特殊的类加载器来满足特殊需求。
以上就是双亲委派机制的介绍。它是Java类加载架构的一个关键特性,对于理解Java的类加载器行为和避免常见的类加载问题非常重要。
只有当链表中的元素个数大于8(此时 node有9个),并且数组的长度大于等于64时才会将链表转为红黑树。
25、定时框架
什么是XXL-JOB?
XXL-JOB是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。
现已开放源代码并接入多家公司线上产品线,开箱即用。
Java主流三大定时器技术选型
选型时原则:少服务器 后期维护方便 增加任务省事而且快捷 不涉及启停服务
1、Quartz
优点:支持集群部署
缺点:没有自带的管理界面;调度逻辑和执行任务耦合在一起;维护需要重启服务
总结:针对目前项目情况,利弊相同
2、xxl-job
优点:支持集群部署;提供运维界面维护成本小;自带错误预警;相对elastic-job来说不需要额外的组件(zookeeper);支持调度策略;支持分片;文档齐全
缺点:相对Quartz来说需要多部署调度中心
总结:针对目前项目情况,利大于弊
3、elastic-job
优点:支持集群部署;维护成本小
缺点:elastic-job需要zookeeper,zookeeper集群高可用至少需要三台服务器
总结:针对目前项目情况,弊大于利
小结:综合选型原则及三个定时任务框架的优缺点和目前项目的状况,建议选用xxl-job。
XXL-JOB的一些特性:
1、执行失败可以查看日志
2、支持邮件报警
3、路由策略支持轮询等策略,可以减轻执行服务器的压力
4、轮询时间等参数修改后立即生效
5、执行器有问题或新增,快速识别
6、调度中心高可用,调度中心可以集群部署(集群部署的机器时钟必须同步),如果调度中心没有做负载在执行器的配置中需要配多个地址,如果调度中心配置负载则执行器配置负载地址即可
7、执行器高可用(执行器可以集群部署)
26、线程安全的定义?
线程安全的定义?
线程安全是多线程编程中的一个概念,它描述了一段代码、一系列操作或者整个程序在多线程环境中执行时的安全性。如果一段代码是线程安全的,它可以同时被多个线程安全地调用,而不会产生不一致的结果或者破坏数据结构。
线程安全的定义:
线程安全通常涉及以下几个方面:
-
原子性(Atomicity):一个操作或者多个操作要么全部执行,要么全不执行,不会停留在中间状态。在编程中,原子操作通常通过锁或者原子变量实现。
-
可见性(Visibility):一个线程对共享变量的修改,可以被其他线程立即看到。Java中可以通过
volatile关键字、synchronized关键字或者java.util.concurrent包下的工具来保证可见性。 -
有序性(Ordering):程序中的指令执行顺序可能会被编译器或者处理器优化打乱,但是从并发的角度看,这些指令的执行顺序应该是有逻辑的和可预期的。在Java中,
volatile关键字和happens-before原则是保证指令有序性的常用机制。
当一段代码是线程安全的,它会正确地处理多线程间的原子性、可见性和有序性,从而保证并发执行时的正确性。
线程安全的实现:
在Java中,实现线程安全的常见方法有:
- 使用synchronized关键字:它提供了一种锁机制,能够保证同一时刻只有一个线程执行某个方法或者代码块。
public class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
- 使用ReentrantLock:
java.util.concurrent.locks.Lock接口及其实现提供了比synchronized更灵活的锁定机制。
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Counter {
private final Lock lock = new ReentrantLock();
private int count = 0;
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public int getCount() {
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}
}
- 使用volatile关键字:这可以保证共享变量的可见性,当一个线程修改了这个变量的值,新值对于其他线程来说是立即可见的。
public class Flag {
private volatile boolean flag = false;
public void setFlag(boolean flag) {
this.flag = flag;
}
public boolean isFlagSet() {
return flag;
}
}
-
使用并发集合:
java.util.concurrent包提供了一系列的线程安全集合类,如ConcurrentHashMap、CopyOnWriteArrayList等。 -
使用原子变量:
java.util.concurrent.atomic包提供了一系列原子变量,如AtomicInteger、AtomicLong等,这些类利用CAS(Compare-and-Swap)操作提供了无锁的线程安全编程方法。
import java.util.concurrent.atomic.AtomicInteger;
public class Counter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.incrementAndGet();
}
public int getCount() {
return count.get();
}
}
- 不可变对象:创建不可变的对象,这些对象一旦创建,其状态就不可改变。因此,它们自然是线程安全的。
public final class ImmutableValue {
private final int value;
public ImmutableValue(int value) {
this.value = value;
}
public int getValue() {
return value;
}
}
线程安全的重要性:
在多线程应用程序中,线程安全是至关重要的,因为数据竞争和并发修改可能导致不一致的状态,从而导致应用程序的失败。通过确保代码是线程安全的,可以避免这些问题,保证程序的稳定性和可靠性。
综上所述,线程安全需要考虑多个方面,而且在Java中有多种方法可以实现线程安全。选择哪种方法取决于具体情况,考虑到性能、简便性以及其他因素。
27、jvm调优的20个参数及作用
1、-Xms:设置JVM初始堆大小,如-Xms512m表示初始堆大小为512MB。
2、-Xmx:设置JVM最大堆大小,如-Xmx1024m表示最大堆大小为1GB。
通常情况下我们会把Xms和Xmx参数设成一样的值,可以减少内存抖动频率,内存抖动会额外消耗cpu时间,设成一样的值可以在最小化不必要的内存分配和减少垃圾回收频率之间平衡,从而提高应用程序的性能和稳定性。
3、-Xmn:设置年轻代大小,如-Xmn256m表示年轻代大小为256MB。
4、-XX:PermSize:设置永久代初始大小,如-XX:PermSize=256m表示永久代初始大小为256MB。
5、-XX:MaxPermSize:设置永久代最大大小,如-XX:MaxPermSize=512m表示永久代最大大小为512MB。
6、-XX:NewSize:设置新生代初始大小,如-XX:NewSize=128m表示新生代初始大小为128MB。
7、-XX:MaxNewSize:设置新生代最大大小,如-XX:MaxNewSize=256m表示新生代最大大小为256MB。
8、-XX:SurvivorRatio:设置年轻代中Eden区和Survivor区的比例,如-XX:SurvivorRatio=8表示Eden区和Survivor区的比例为8:1。
9、-XX:MaxTenuringThreshold:设置对象晋升老年代的最大阈值,如-XX:MaxTenuringThreshold=10表示对象存活次数达到10次时,将晋升到老年代。
10、-XX:NewRatio:设置年轻代和老年代的比例,如-XX:NewRatio=2表示年轻代和老年代的比例为1:2。
11、-XX:ParallelGCThreads:设置并行垃圾收集器的线程数,如-XX:ParallelGCThreads=8表示并行垃圾收集器的线程数为8个。
12、-XX:+UseConcMarkSweepGC:开启CMS垃圾收集器。
13、-XX:+UseParallelGC:开启并行垃圾收集器。
14、-XX:+UseSerialGC:开启串行垃圾收集器。
15、-XX:+UseG1GC:开启G1垃圾收集器。
16、-XX:+HeapDumpOnOutOfMemoryError:发生内存溢出时生成Heap Dump文件。
17、-XX:HeapDumpPath:设置Heap Dump文件生成路径。
18、-XX:+PrintGCDetails:输出GC详细信息。
19、-XX:+PrintGCDateStamps:输出GC的时间戳。
20、-XX:+PrintCommandLineFlags:输出JVM启动时的参数信息。
28、 发生内存溢出的10种场景?
内存溢出(OutOfMemoryError,简称OOM)是指程序在申请内存时,没有足够的内存空间供其使用,发生的错误。在Java中,内存溢出通常是指堆内存(Heap Space)不足,但也有可能是其他部分内存空间不足。以下是常见的一些内存溢出场景及其可能的原因:
-
Java堆内存溢出:
List<Object> list = new ArrayList<>(); while (true) { list.add(new Object()); // 不断创建对象,并保持引用,导致GC无法回收,最终堆内存不足 } -
永久代或元空间溢出:
// 在Java 8之前,永久代会因为加载了大量的类或者大量的反射操作而溢出 // 在Java 8中,永久代已经被元空间(Metaspace)所取代 List<Class<?>> classes = new ArrayList<>(); while (true) { Class<?> clazz = ClassLoader.getSystemClassLoader().loadClass("SomeClass"); classes.add(clazz); } -
栈内存溢出:
public void recursiveMethod() { recursiveMethod(); // 递归调用,没有退出条件,会造成栈内存溢出 } -
本地方法栈溢出:
// 本地方法栈溢出一般发生在调用本地方法时,无限递归或者大量线程调用本地方法可能导致 // 本地方法栈溢出的代码示例不容易提供,因为它涉及到JNI(Java Native Interface)调用 -
直接内存溢出:
// 使用NIO进行大量直接内存分配,可能导致直接内存溢出 ByteBuffer buffer = ByteBuffer.allocateDirect(1024 * 1024 * 1024); // 分配1GB直接内存 -
内存泄漏:
// 长生命周期的对象持有短生命周期对象的引用,导致短生命周期对象无法被GC回收 public class MemoryLeak { private List<Object> leakList = new ArrayList<>(); public void addObject(Object obj) { leakList.add(obj); // 对象实际上已经不再需要,却仍然被保存在列表中 } } -
过多线程:
// 创建过多的线程,每个线程都会占用一定的栈内存,可能导致内存溢出 while (true) { new Thread(new Runnable() { public void run() { try { Thread.sleep(10000000); } catch (InterruptedException e) { Thread.currentThread().interrupt(); } } }).start(); } -
数据库连接耗尽:
// 如果数据库连接不释放,会导致连接对象无法回收 while (true) { Connection conn = dataSource.getConnection(); // 忘记调用 conn.close(); } -
大量动态生成类:
// 动态生成大量的类,可以通过CGLIB或Javassist等库实现 while (true) { Enhancer enhancer = new Enhancer(); enhancer.setSuperclass(MyClass.class); enhancer.setUseCache(false); enhancer.setCallback(new MethodInterceptor() { public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable { return proxy.invokeSuper(obj, args); } }); MyClass myClass = (MyClass) enhancer.create(); } -
大量静态内容:
// 静态内容(如静态集合类)的生命周期与应用程序一样长,如果不断向里面添加内容,会导致内存不足 public class StaticContentHolder { private static List<Object> staticList = new ArrayList<>(); public void addToList(Object obj) { staticList.add(obj); } }
以上代码示例都是造成内存溢出的潜在原因。在实际开发中,内存溢出问题的解决通常需要对代码进行的分析,并使用像Java虚拟机工具接口(JVMTI)、Java Mission Control、VisualVM、MAT(Memory Analyzer Tool)等工具来分析内存使用情况,从而找出内存泄漏或者溢出的根本原因。
29、 泛型
泛型是Java语言提供的一个编译时特性,它允许程序员编写能够适用于多种数据类型的代码。泛型的主要好处是提供了类型安全性和避免了类型转换的麻烦。
泛型的基本概念:
- 类型参数化:能够将类型作为参数传递给类和方法。
- 类型擦除:Java的泛型是在编译期实现的,编译器将类型信息擦除,并添加类型转换代码。
- 通配符:使用?表示未知类型。通配符可以有上界(
? extends T)和下界(? super T)。
泛型类:
一个典型的泛型类的定义如下:
public class Box<T> {
private T t; // T stands for "Type"
public void set(T t) {
this.t = t;
}
public T get() {
return t;
}
}
在上面的例子中,T是一个类型变量,它将在创建Box类的实例时被实际的类型替换。
使用泛型类:
Box<Integer> integerBox = new Box<>();
Box<String> stringBox = new Box<>();
integerBox.set(10); // 自动装箱
stringBox.set("Hello World");
Integer intValue = integerBox.get(); // 不需要类型转换
String stringValue = stringBox.get(); // 不需要类型转换
泛型方法:
泛型也可以应用于方法。一个泛型方法可能被定义在一个非泛型类中。
public class Utility {
public static <T> void printArray(T[] array) {
for (T element : array) {
System.out.print(element + " ");
}
System.out.println();
}
}
使用泛型方法:
Integer[] intArray = {1, 2, 3};
String[] stringArray = {"Hello", "World"};
Utility.<Integer>printArray(intArray); // 指定类型
Utility.printArray(stringArray); // 类型推断
泛型的边界:
泛型可以限定类型变量的上界(extends)或下界(super)。
public class Stats<T extends Number> {
private T[] nums;
public Stats(T[] nums) {
this.nums = nums;
}
public double average() {
double sum = 0.0;
for (T num : nums) {
sum += num.doubleValue();
}
return sum / nums.length;
}
}
在上面的例子中,类型参数T必须是Number或其子类。这允许在方法average中安全地调用doubleValue。
泛型通配符:
使用通配符?可以让你编写能够适应不同类型的泛型代码。
public static void printList(List<?> list) {
for (Object elem : list) {
System.out.print(elem + " ");
}
System.out.println();
}
printList方法可以接收任何类型的List作为参数,无论这个List的元素类型是什么。
泛型的局限性:
- 类型擦除:运行时类型查询只能使用原始类型。泛型类型参数在运行时不可用,因为它们会被擦除。
- 静态上下文中的类型参数:不能在静态变量或方法中引用类型参数。
- 原始类型:使用泛型时,不能使用基本数据类型(int, long, double等),必须使用它们的包装类(Integer, Long, Double等)。
- 创建泛型数组:由于类型擦除,无法创建特定泛型类型的数组,
T[] array = new T[10];会引起编译错误。
泛型和反射:
由于擦除,泛型类型信息在运行时不可获取,这限制了反射的使用。然而,可以通过其他手段在运行时获取到泛型的类型信息,例如通过子类化一个参数化类型。
总结:
泛型是Java编程中的一个强大工具,它提供了编译时类型安全性并且阻止了类型转换的错误。了解泛型如何工作以及如何有效地使用它们是一个Java开发者必需的技能。在使用泛型时,需要考虑类型擦除以及它对你的代码可能产生的影响。
PECS原则
PECS原则是指“Producer Extends, Consumer Super”,这是由Joshua Bloch在他的著作《Effective Java》中提出的一种泛型设计指导原则。PECS原则用来指导泛型通配符的使用,以便获得最佳的灵活性和类型安全。
-
Producer Extends:如果你需要一个提供(生产)元素给你的集合,那么你应该使用带有
extends通配符的泛型。它意味着这个集合可以安全地读取其中的元素,因为这些元素都是这个通配符指定的类型的子类型。 -
Consumer Super:如果你需要一个消费(接收)元素的集合,那么你应该使用带有
super通配符的泛型。它允许你安全地向集合中写入元素,因为这些元素都是这个通配符指定的类型的父类型。
为什么使用PECS原则?
在泛型中,集合的类型参数指定了集合可以持有的元素的类型。但是,泛型是不可变的,这意味着List<String>并不是List<Object>的子类型。这给集合的赋值和参数传递带来了限制。为了提供更多的灵活性,Java提供了泛型通配符。
使用? extends T可以为泛型类型创建一个上界,表示这个通配符可以是T或T的任何子类。同样,? super T创建了一个下界,表示这个通配符可以是T或T的任何父类。
示例:
假设我们有一个类Fruit,以及两个子类Apple和Orange。
class Fruit {}
class Apple extends Fruit {}
class Orange extends Fruit {}
class Box<T> {
private T t;
public Box(T t) { this.t = t; }
public T get() { return t; }
public void set(T t) { this.t = t; }
}
现在,让我们看看PECS原则如何应用于这些类:
Producer Extends:
如果我们有一个方法需要读取(生产)水果,我们将使用extends:
public static void printFruits(List<? extends Fruit> fruits) {
for (Fruit fruit : fruits) {
System.out.println(fruit.getClass().getSimpleName());
}
// fruits.add(new Apple()); // 错误!不能添加元素
}
这里的List<? extends Fruit>可以接受List<Fruit>、List<Apple>或List<Orange>作为参数。我们可以从中读取数据,因为我们知道列表中的每个元素至少是Fruit类的对象。
Consumer Super:
如果我们需要写入(消费)水果,我们将使用super:
public static void addApple(List<? super Apple> fruits) {
fruits.add(new Apple()); // 正确!我们可以添加一个苹果或它的子类
// Fruit fruit = fruits.get(0); // 错误!不能确切知道返回类型
}
这里的List<? super Apple>可以接受List<Fruit>或List<Apple>作为参数。我们可以向其添加Apple或其子类的实例。
PECS原则的好处:
- 最大化灵活性:通过将限制放在恰当的位置,你可以编写更灵活的代码。
- 提高类型安全:使用PECS原则,编译器可以帮助你避免在运行时出现
ClassCastException。 - 易于理解:代码的使用者可以通过方法签名更容易地理解代码。比如
printFruits方法显然不会修改传入的列表,而addApple方法则可能会这样做。
总结:
PECS原则是处理生产者和消费者的泛型集合时提供指导的有效工具。它通过边界通配符的正确使用,使得你的API更加灵活和类型安全。在编写泛型代码时,总是考虑是使用extends还是super,以确保你的代码既具有好的兼容性,也易于维护。
为什么不用object替换泛型
使用Object替换泛型确实是在Java中泛型出现之前所做的做法。然而,泛型引入后,它们提供了许多有点,这些优势使得泛型比使用Object更加强大和灵活。这些优势包括:
类型安全
泛型提供了编译时的类型检查。如果你使用泛型,当你尝试将错误类型的对象放入集合时,编译器会提醒你。使用Object,这些错误会在运行时发生,可能会导致ClassCastException。
List<String> strings = new ArrayList<>();
strings.add("text"); // OK
strings.add(1); // 编译错误,类型安全
List objects = new ArrayList<>();
objects.add("text"); // OK
objects.add(1); // OK,但是失去了类型安全
避免强制类型转换
泛型避免了在取出元素时进行强制类型转换,因为编译器能够通过泛型知道集合中的元素类型。
List<String> strings = new ArrayList<>();
strings.add("text");
String s = strings.get(0); // 没有强制类型转换
List objects = new ArrayList<>();
objects.add("text");
String s = (String) objects.get(0); // 需要强制类型转换
使用Object,每次从集合中取出元素时,你都需要进行类型转换,这不仅增加了代码的复杂性,还增加了运行时出错的风险。
API清晰性
泛型使得API更加清晰,因为它直接在代码中指定了操作的数据类型。
// 没有泛型
public void processItems(List items) {
// ...
}
// 有泛型
public void processItems(List<Item> items) {
// ...
}
在第二个例子中,通过查看方法的签名,你可以立即知道这个方法期望接受什么类型的元素。
重用性
泛型代码可以很容易地重用,因为它们可以与多种数据类型一起工作。
public class Box<T> {
private T t;
public void set(T t) { this.t = t; }
public T get() { return t; }
}
上面的Box类可以用于存储任何类型的对象,而不是只能存储Object类型的对象。
促进更好的设计
泛型鼓励编程人员更深入地考虑类型,从而写出更通用且可重用的代码。它还可以帮助避免某些设计中的不良做法,例如过度使用instanceof检查和强制类型转换。
代码优化
编译器在编译带泛型的代码时会进行类型擦除,将泛型类型参数替换为它们的边界或Object。这意味着泛型不会对运行时的性能产生影响。泛型的引入基本上是一种无成本的抽象。
总结
尽管使用Object可以实现类似的功能,但泛型提供了更好的类型检查、更清晰的API、减少了强制类型转换的需要,以及更灵活的代码重用性。此外,它们使得代码更加安全、可读、易于维护,并且没有引入任何运行时开销。因此,泛型是一种比使用Object更好的选择。
30、 静态代理和动态代理
静态代理和动态代理的区别
1、静态代理通常只代理一个类,动态代理是代理一个接口下的多个实现类。
2、静态代理事先知道要代理的是什么,而动态代理不知道要代理什么东西,只有在运行时才知道。
3、动态代理是实现JDK里的InvocationHandler接口的invoke方法,但注意的是代理的是接口,也就是你的业务类必须要实现接口,通过Proxy里的newProxyInstance得到代理对象。
4、还有一种动态代理CGLIB,代理的是类,不需要业务类继承接口,通过派生的子类来实现代理。通过在运行时,动态修改字节码达到修改类的目的。
静态代理
某个对象提供一个代理,代理角色固定,以控制对这个对象的访问。 代理类和委托类有共同的父类或父接口,这样在任何使用委托类对象的地方都可以用代理对象替代。代理类负责请求的预处理、过滤、将请求分派给委托类处理、以及委托类执行完请求后的后续处理。
静态代理的特点
1、目标角色固定
2、在应用程序执行前就得到目标角色
3、代理对象会增强目标对象的行为
4、有可能存在多个代理 引起"类爆炸"(缺点)
动态代理
相比于静态代理,动态代理在创建代理对象上更加的灵活,动态代理类的字节码在程序运行时,由Java反射机制动态产生。它会根据需要,通过反射机制在程序运行期,动态的为目标对象创建代理对象,无需程序员手动编写它的源代码。
动态代理的特点
1、目标对象不固定
2、在应用程序执行时动态创建目标对象
3、代理对象会增强目标对象的行为
31、 Java有哪些引用类型?
Java有四种引用类型,包括强引用、软引用、弱引用和虚引用。
1、强引用:最普通的引用,只要强引用还存在,垃圾回收器就永远不会回收被引用的对象。
2、软引用:用来描述一些可能还有用但并非必需的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常前,将会把这些对象列进回收范围之中进行第二次回收。如果这次回收还没有把对象回收掉,那么在系统堆内存发生严重溢出时,才会把这些对象列入回收范围。
3、弱引用:也是用来描述非必需对象的,它和软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期——仅在当前内存足够的情况下,垃圾回收器才不会回收它。当内存空间不足时,垃圾回收器可以回收这些对象。
4、虚引用:是最弱的一种引用关系。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来取得一个对象实例。唯一的用处就是能在这个对象被收集器回收时收到一个系统通知。
32、@Contended作用和优缺点?
@Contended是Java 8中引入的一个注解,用于减少多线程环境下的“伪共享”现象,以提高程序的性能。
它的作用是使被标注的对象独占缓存行,不会和任何变量或者对象共享缓存行。这样做可以避免处理器缓存行大小不同带来的影响,做到Java语言的初衷:平台无关性。
@Contended的优点是可以提高程序的性能,通过减少“伪共享”现象,使得程序在多线程环境下的执行效率更高。
然而,@Contended也存在一些缺点。
首先,它默认只在JDK内部起作用,如果需要在程序代码中使用@Contended注解,需要开启JVM参数-XX:-RestrictContended才能生效。
其次,被@Contended标注的对象会独占缓存行,这可能会增加内存占用和处理器缓存争用,从而对系统性能产生负面影响。
因此,在使用@Contended注解时,需要根据实际情况权衡利弊,以选择最适合的应用场景。
33、ThreadLocal
ThreadLocal 是 Java 中一个用于实现线程局部存储的类。它允许你创建的变量只能被同一个线程访问。因此,即使多个线程都使用相同的 ThreadLocal 对象创建了副本,它们也不会相互干扰。这在进行并发编程时是非常有用的,尤其是在使用无状态的对象时,例如日期格式化。
ThreadLocal 的工作原理
每个线程都有一个自己的 ThreadLocalMap(一个简化的 Map 类型的数据结构),它以弱引用的方式存储了线程局部变量的副本。ThreadLocal 对象作为键,线程局部变量的副本作为值。
当线程终止并且没有其他对这个线程对象的引用时,由于是弱引用,ThreadLocal 键会被垃圾收集器回收。
ThreadLocal 类的核心部分
以下是 ThreadLocal 类的核心方法:
set(T value):将当前线程的局部变量副本设置为指定的值。get():返回当前线程的局部变量副本。remove():移除当前线程的局部变量副本。initialValue():返回该线程局部变量的初始值,默认是null。
ThreadLocal 源码的核心部分
在 Java 源码中,ThreadLocal 的实现大概可以分为以下几个部分。这里只呈现部分关键代码和概念:
ThreadLocal 类
public class ThreadLocal<T> {
// ... 其他成员 ...
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
// ... 其他方法 ...
}
ThreadLocal.ThreadLocalMap 类
ThreadLocal.ThreadLocalMap 是 ThreadLocal 的一个内部类,它的实现类似于一个简化版的 Map,专门为每个线程存储其局部变量副本。
static class ThreadLocalMap {
// ... 其他成员 ...
private static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
private Entry[] table;
private Entry getEntry(ThreadLocal<?> key) {
// ... 实现查找 ...
}
private void set(ThreadLocal<?> key, Object value) {
// ... 实现赋值 ...
}
// ... 其他方法 ...
}
源码概要
ThreadLocal实例基本上是一个键。真正的值存储在Thread对象自己的ThreadLocalMap中。ThreadLocalMap使用ThreadLocal的弱引用作为键。对于每个键-值关系,键是ThreadLocal的弱引用,值是对应的线程局部对象。initialValue()默认实现返回null,但可以重写以返回线程首次访问变量时的初始值。get()方法会从当前线程的ThreadLocalMap中获取与ThreadLocal实例关联的值。set(T value)会将值与当前线程的ThreadLocal实例关联。remove()会删除当前线程的ThreadLocalMap中与ThreadLocal实例关联的值。
ThreadLocal 使用注意事项
- 内存泄漏:由于
ThreadLocalMap的生命周期与线程一样长,所以如果线程是线程池中的线程,而且不被销毁,那么存在内存泄漏的风险。 - 性能问题:过多的使用
ThreadLocal可能会导致性能问题,因为每个线程都需要维护自己的ThreadLocalMap。
使用 ThreadLocal 时,您应该始终记住在不再需要存储在 ThreadLocal 中的数据时调用 remove() 方法,特别是在使用线程池的情况下,以避免任何潜在的内存泄漏。
ThreadLocal 在一些特定的场景下非常有用,例如,在需要保持线程安全的情况下,为每个线程保持数据库连接或用户会话信息。然而,正确地管理 ThreadLocal 变得很重要,因为不当使用可能导致内存泄漏。
34、竞态条件
竞态条件(Race Condition)是指系统的输出依赖于不受控制的事件序列或时序的情况。在并发编程中,当多个进程或线程访问共享数据并且试图同时修改它时,就可能发生竞态条件。如果事件的发生顺序不正确,程序就可能导致不可预测的结果或破坏数据的完整性。
理解竞态条件
竞态条件通常发生在以下情况中:
- 共享数据:多个线程或进程共享同一块数据资源。
- 多个线程修改数据:至少有一个线程修改数据资源,而其他线程可能读取或写入同一个资源。
- 交替执行:线程的执行顺序由操作系统的调度算法决定,这通常是不确定的。
举例说明竞态条件
假设有两个线程,它们都要更新同一个银行账户余额。如果两个线程同时检查余额,然后基于当前值计算新的余额,并尝试将这个更新的值写会到账户中,就可能出现问题。
如果两个线程几乎同时读取到账户余额为$100,然后它们各自都要在余额上增加$50,理论上最后的余额应该是$200。但是,由于竞态条件,如果它们没有适当的协调机制,可能都读取到$100,各自计算出新的金额$150,并将其写回,最后结果只有$150存入账户,$50就这样丢失了。
竞态条件的类型
- 检查后操作(Check-Then-Act):先检查条件,然后基于条件执行操作。如果在检查与操作之间状态改变了,那么操作可能是基于过时的信息。
- 读取-修改-写入(Read-Modify-Write):当一个线程读取一个值,修改它,然后写回时,如果另一个线程在同一时间做同样的事情,就可能会发生竞态条件。
如何避免竞态条件
解决竞态条件的关键在于同步,确保在给定时间内只有一个线程可以访问和修改共享资源。以下是一些常见的同步技术:
- 互斥锁(Mutex):使用互斥锁可以确保同一时间只有一个线程能进入临界区。
- 信号量(Semaphores):信号量可以控制对共享资源的访问,通过使用计数器来允许多少个线程可以同时访问资源。
- 监视器(Monitors):在Java中,
synchronized关键字可以用来创建监视器,用于控制对对象的并发访问。 - 原子操作:使用能够保证原子性的数据结构或操作(如
AtomicInteger类)。 - 顺序一致性:内存模型可以保证顺序一致性,确保程序执行的顺序和预期的一致。
- 事务内存(Transactional Memory):一些系统提供了事务内存支持,它可以让一组操作或者是全部成功,或者是全部不发生,以此来避免竞态条件。
竞态条件的检测和工具
在开发过程中,竞态条件可能不容易被发现,因为它们的发生通常依赖于特定的时序条件。有一些工具和技术可以帮助检测竞态条件:
- 静态分析工具:能够在代码编写时检查潜在的同步问题。
- 动态分析工具:如 Valgrind、Helgrind 等,可以在程序运行时检查竞态条件。
总的来说,竞态条件是并发编程中常见的问题,它们对程序的正确性构成了严重威胁。通过合理的设计和使用同步机制,可以避免竞态条件的发生。开发人员需要对这些概念有深入的理解,并在实际编程中注意相关问题。
35、当前读和快照读的区别
在数据库系统以及数据一致性领域,特别是在事务数据库中,“当前读”(Current Read)和"快照读"(Snapshot Read)是两种常见的数据读取策略。它们各自有不同的用途和特点,针对不同的场景选择合适的读取策略对于保证数据的一致性和事务的隔离性非常关键。
当前读(Current Read)
当前读是指读取最新版本的数据,也就是说,当一个事务尝试读取一行数据时,它将会得到该数据最近一次被提交的值。如果该数据项正在由另一个未提交的事务持有锁,则当前读操作通常会被阻塞,直至该锁被释放。
- 锁定行为:为了保证读取的数据是最新的,当前读操作通常会对所涉及的数据行加锁。在SQL标准中,这对应了锁定读命令,如
SELECT ... FOR UPDATE。 - 一致性和隔离性:当前读可以防止不一致性和脏读(即读取到其他未提交事务的数据),并且在许多隔离级别下都是必须的,如可重复读(Repeatable Read)和串行化(Serializable)。
- 性能影响:由于加锁的需要,当前读可能会导致较高的锁争用,从而影响并发性能。
快照读(Snapshot Read)
快照读是指读取数据的某一历史版本,这个版本反映了事务开始时或特定时间点的数据状态。这意味着,即使数据在事务执行期间被其他事务修改,事务还是能看到一致的“快照”。
- 无锁操作:快照读通常不需要对数据进行加锁,因为它们访问的是数据的旧版本。
- 一致性视图:快照读能够提供一个事务一致性视图,从而不会看到其他并发事务所做的修改,这有助于减少锁争用并提高并发性能。
- 多版本并发控制(MVCC):许多支持快照读的数据库管理系统使用MVCC来实现,能够在不锁定资源的情况下,提供一致性的读取。
区别和应用场景
- 事务隔离级别:当前读通常用于较高的隔离级别(如可重复读和串行化),而快照读则用于较低隔离级别(如读已提交)。
- 数据可见性:当前读保证了读取到的数据是最新的,而快照读可能读取到旧版本的数据。
- 锁争用和性能:快照读由于其无锁操作特点,通常具有更好的并发性能,但在一些情况下可能会牺牲一致性。
- 应用场景:如果应用程序需要处理最新数据并且可以容忍锁等待,则应该使用当前读。如果应用程序可以处理稍微陈旧的数据,并且优先考虑系统的吞吐量和响应时间,则应该使用快照读。
- 实现方式:当前读的实现通常简单,因为它只需要传统的锁机制。而快照读则依赖于数据库管理系统的复杂实现,如MVCC,这需要额外的存储空间来保存数据的多个版本。
结论
选择当前读还是快照读取决于应用的具体需求、事务的隔离级别要求以及对性能的影响。数据库管理员和开发人员需要根据不同的工作负载和一致性要求来选择最适合的读取策略。在现代数据库中,快照读的MVCC模型由于其高并发性能和较好的读取一致性保证,常常是默认的选择。
36、事务失效的场景
事务失效可能不仅仅是因为配置错误或不正确的使用注解,它可能涉及到更深层次的问题,如事务管理器的配置、事务的传播性、隔离级别、数据库支持等。下面探究一些场景:
1. 通过this调用事务方法
如果在同一个类的一个非事务方法中通过this关键字调用一个事务方法,此时调用不会通过Spring创建的代理对象,导致事务配置不被应用。为解决这个问题,可以将被调用的方法放置到另一个Spring管理的Bean中。
2. 事务注解用于非public方法
由于Spring AOP代理机制的限制,只有public方法执行时,Spring才能将事务逻辑织入代码中。对于其他访问权限的方法,你必须确保事务逻辑在调用这些方法的外围public方法中得到处理。
3. 不正确的事务传播行为
Spring事务的传播行为决定当前事务方法是应该运行在现有事务上下文中还是创建一个新的事务。如果选择了错误的传播行为,可能导致事务不按预期工作。比如使用Propagation.REQUIRES_NEW时,内部事务可能会被独立地提交或回滚,而不管外部事务的状态。
4. 数据库不支持事务
有些数据库引擎不支持事务(例如,旧版本的MySQL的MyISAM引擎),或者数据库连接设置为自动提交模式,这会导致Spring事务管理机制失效。
5. 异常管理不当
Spring默认仅在方法抛出运行时异常时回滚事务。如果你的方法抛出受检异常,但没有在@Transactional注解中声明这些异常,事务将不会回滚。
6. 异常被吞没
如果在事务方法中捕捉到了异常,并且这个异常没有被抛出或者被错误地处理,Spring事务管理器就无法捕获到异常,导致事务不回滚。
7. 指定了错误的事务管理器
如果配置了多个事务管理器,但在使用@Transactional注解时没有指定正确的事务管理器,可能会发生事务失效。
8. 配置错误的数据源
事务管理依赖于正确配置的数据源。如果数据源没有实现Spring的DataSource接口,或者没有正确配置为支持事务,则事务管理会失效。
9. 自调用问题
在同一个Bean内部,一个方法直接调用另一个方法,即使被调用的方法被@Transactional标注,这种自调用也不会启动Spring代理,从而不会启动事务。
10. 不正确的超时设置
在@Transactional注解中指定的超时值太小,可能会导致在数据库操作完成之前事务被回滚。超时设置需要根据数据库操作的实际执行时间来合理设定。
11. 在测试中的事务失效
在测试中,如果没有使用@Transactional注解或者没有正确配置Spring测试上下文,事务可能不会按预期执行。确保测试类使用了@RunWith(SpringRunner.class)和@SpringBootTest注解,并且测试方法或测试类使用了@Transactional。
12. 多线程环境下的事务同步问题
在多线程环境下处理事务时,需要确保正确的事务上下文被传播到执行事务操作的每个线程中。默认情况下,事务上下文是线程绑定的,不会自动传播到新创建的线程中。
处理这些问题的策略通常涉及到重构代码以确保正确使用Spring的代理机制、正确配置事务管理器和数据源、合理处理异常以及对多线程情况进行特殊处理。此外,开发者也应该充分了解Spring事务管理的工作原理,包括事务的传播性、隔离级别、回滚规则等,以及它们如何与底层数据库系统交互。
37、深克隆和浅克隆
在Java中,克隆对象通常通过实现Cloneable接口并重写clone()方法来实现。克隆可以分为浅克隆和深克隆,它们在复制对象时的行为和结果有显著的区别。
浅克隆 (Shallow Clone)
浅克隆是指创建一个新对象,但对象中的属性值仅仅是原对象属性的引用。这意味着浅克隆对象和原对象共享相同的引用类型属性。如果引用类型属性中的数据发生变化,浅克隆对象和原对象都会受到影响。
浅克隆的实现通常是通过调用Object类的clone()方法来完成的。clone()方法会创建一个新对象,并将原对象中的基本数据类型属性和引用类型属性的引用复制到新对象中。
示例代码:
class Address implements Cloneable {
String city;
public Address(String city) {
this.city = city;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
class Person implements Cloneable {
String name;
Address address;
public Person(String name, Address address) {
this.name = name;
this.address = address;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class ShallowCloneTest {
public static void main(String[] args) throws CloneNotSupportedException {
Address address = new Address("New York");
Person person1 = new Person("John", address);
Person person2 = (Person) person1.clone();
System.out.println(person1.address.city); // New York
System.out.println(person2.address.city); // New York
person2.address.city = "Los Angeles";
System.out.println(person1.address.city); // Los Angeles
System.out.println(person2.address.city); // Los Angeles
}
}
在上面的例子中,person1和person2共享相同的Address对象,当我们修改person2的地址时,person1的地址也会改变。
深克隆 (Deep Clone)
深克隆是指创建一个新对象,同时递归地克隆所有引用类型的属性,使得新对象和原对象完全独立,互不影响。深克隆可以确保新对象和原对象在内存中占据不同的位置,即使它们包含相同的引用类型属性,修改一个对象的引用类型属性不会影响另一个对象。
深克隆的实现可以通过手动递归克隆每一个引用类型属性来完成,也可以使用序列化和反序列化来实现。
示例代码:
class Address implements Cloneable {
String city;
public Address(String city) {
this.city = city;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
class Person implements Cloneable {
String name;
Address address;
public Person(String name, Address address) {
this.name = name;
this.address = address;
}
@Override
protected Object clone() throws CloneNotSupportedException {
Person cloned = (Person) super.clone();
cloned.address = (Address) address.clone();
return cloned;
}
}
public class DeepCloneTest {
public static void main(String[] args) throws CloneNotSupportedException {
Address address = new Address("New York");
Person person1 = new Person("John", address);
Person person2 = (Person) person1.clone();
System.out.println(person1.address.city); // New York
System.out.println(person2.address.city); // New York
person2.address.city = "Los Angeles";
System.out.println(person1.address.city); // New York
System.out.println(person2.address.city); // Los Angeles
}
}
在这个例子中,我们在Person类的clone()方法中,除了调用super.clone(),还手动克隆了Address对象,因此person1和person2会有独立的Address对象,修改person2的地址不会影响person1的地址。
浅克隆: 被Clone的对象的所有变量都含有原来对象相同的值,而引用变量还是原来对用的引用【拷贝对象时仅仅拷贝对象本身(包括对象中的基本变量),而不拷贝对象包含的引用指向的对象。】
深克隆: 被克隆对象的所有变量都含有原来的对象相同的值,引用变量也重新复制了一份【不仅拷贝对象本身,而且拷贝对象包含的引用指向的所有对象】
总结
- 浅克隆 (Shallow Clone):复制对象时,只复制对象本身,不复制其引用类型属性所指向的对象。结果是克隆对象和原对象共享相同的引用类型属性。
- 深克隆 (Deep Clone):复制对象时,同时递归地复制所有引用类型属性所指向的对象。结果是克隆对象和原对象完全独立,互不影响。
选择浅克隆还是深克隆,主要取决于具体的需求和场景。如果需要完整独立的副本,应选择深克隆;如果只需要复制对象本身而不需要修改引用类型属性,可以选择浅克隆。
38、递归查文件
要遍历一个文件夹及其子文件夹中的所有文件,可以使用Java中的java.nio.file包。Files和Paths类提供了方便的方式来访问和遍历文件系统。下面是一个示例代码,展示了如何使用递归方法遍历并打印一个文件夹中的所有文件:
使用 java.nio.file 包
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
public class FileWalker {
public static void main(String[] args) {
Path startPath = Paths.get("your_directory_path_here"); // 请替换为实际的目录路径
try {
Files.walkFileTree(startPath, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println(file.toString());
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException {
System.err.println("Failed to access file: " + file.toString() + " (" + exc.getMessage() + ")");
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
if (exc == null) {
return FileVisitResult.CONTINUE;
} else {
throw exc;
}
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
}
这个代码使用 Files.walkFileTree 方法来遍历文件树。其中,SimpleFileVisitor 提供了访问文件和目录的方法,你可以根据需要覆盖这些方法来实现自定义行为。
使用 java.io.File 包
如果你更喜欢使用传统的 java.io.File 方法,可以使用递归的方法遍历文件夹:
import java.io.File;
public class FileLister {
public static void main(String[] args) {
File directory = new File("your_directory_path_here"); // 请替换为实际的目录路径
listFiles(directory);
}
public static void listFiles(File dir) {
if (dir.isDirectory()) {
File[] files = dir.listFiles();
if (files != null) {
for (File file : files) {
if (file.isDirectory()) {
listFiles(file); // 递归调用
} else {
System.out.println(file.getAbsolutePath());
}
}
}
} else {
System.out.println(dir.getAbsolutePath());
}
}
}
这个代码使用递归方法遍历目录和子目录,并打印所有文件的路径。
总结
- 使用
java.nio.file包中的Files.walkFileTree方法,可以更高效和更灵活地遍历文件系统,适用于复杂的文件访问需求。 - 使用传统的
java.io.File方法,可以通过递归简单地遍历文件夹及其子文件夹,适用于简单的文件遍历需求。
请根据具体需求和环境选择合适的方法,并记得替换示例代码中的目录路径为你实际需要遍历的路径。
39、反射
反射(Reflection)是Java语言的一项强大功能,它允许程序在运行时检查或修改自身的结构和行为。这包括检查类、接口、字段、方法以及构造函数等成员的详细信息。反射主要通过Java的java.lang.reflect包来实现。
反射的主要作用
- 动态加载类:反射可以在运行时动态加载类,而不是在编译时确定。这使得程序可以根据需求动态加载和使用类。
- 访问和修改私有成员:反射允许程序访问和修改类的私有字段和方法,这对于某些需要深度修改类行为的操作非常有用。
- 动态调用方法:反射可以在运行时调用类的任意方法,包括私有方法,这增强了程序的灵活性。
- 创建对象实例:反射可以在不知道类名的情况下创建类的实例。
- 框架和库:许多Java框架(如Spring、Hibernate等)和库都使用反射来在运行时动态处理对象和依赖关系。
- 工具和开发环境:反射被广泛应用于开发工具和环境中,例如调试器和IDE,它们需要在运行时获得类详细信息。
反射的使用示例
以下是一些反射常见的使用场景及示例代码:
1. 动态加载类
public class ReflectionExample {
public static void main(String[] args) {
try {
// 加载类
Class<?> clazz = Class.forName("com.example.MyClass");
System.out.println("Class Loaded: " + clazz.getName());
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
2. 获取类信息
public class ReflectionExample {
public static void main(String[] args) {
Class<String> stringClass = String.class;
// 获取类名
System.out.println("Class Name: " + stringClass.getName());
// 获取方法
Method[] methods = stringClass.getDeclaredMethods();
for (Method method : methods) {
System.out.println("Method: " + method.getName());
}
// 获取字段
Field[] fields = stringClass.getDeclaredFields();
for (Field field : fields) {
System.out.println("Field: " + field.getName());
}
}
}
3. 动态调用方法
import java.lang.reflect.Method;
public class ReflectionExample {
public static void main(String[] args) {
try {
Class<?> clazz = Class.forName("java.util.ArrayList");
Object instance = clazz.getDeclaredConstructor().newInstance();
// 获取 add 方法
Method addMethod = clazz.getMethod("add", Object.class);
addMethod.invoke(instance, "Hello Reflection");
// 获取 size 方法
Method sizeMethod = clazz.getMethod("size");
int size = (int) sizeMethod.invoke(instance);
System.out.println("Size: " + size);
} catch (Exception e) {
e.printStackTrace();
}
}
}
4. 访问和修改私有字段
import java.lang.reflect.Field;
class Person {
private String name;
public Person(String name) {
this.name = name;
}
}
public class ReflectionExample {
public static void main(String[] args) {
try {
Person person = new Person("John");
// 获取私有字段
Field fieldName = person.getClass().getDeclaredField("name");
fieldName.setAccessible(true);
// 获取字段值
String name = (String) fieldName.get(person);
System.out.println("Name before: " + name);
// 修改字段值
fieldName.set(person, "Doe");
name = (String) fieldName.get(person);
System.out.println("Name after: " + name);
} catch (Exception e) {
e.printStackTrace();
}
}
}
反射的注意事项
- 性能问题:反射涉及的操作通常比直接调用方法要慢,因为它们涉及动态类型检查和安全检查。
- 安全问题:反射可以绕过访问控制机制,访问和修改私有字段和方法,可能会引起安全问题。
- 代码可维护性:反射使代码变得更加复杂和难以维护,因为它打破了编译时的类型检查。
总结
反射是一种强大的工具,允许程序在运行时检查和修改自身的结构和行为。尽管它提供了很大的灵活性,但也带来了性能和安全方面的挑战。因此,在使用反射时,需要权衡其带来的好处和潜在的开销。
40、网络应用的模式及其特点
典型的网络应用模式:B/S、C/S和P2P。
1. B/S (Browser/Server) 模式
特点:
- 客户端使用浏览器:用户无需安装专用软件,通过浏览器即可访问应用,这简化了客户端的部署和管理。
- 跨平台兼容性:由于浏览器是跨平台的,B/S模式可以在不同操作系统上运行。
- 集中管理:服务器端统一管理应用,便于升级和维护。
- 访问便捷:用户只需通过网址访问,无需配置客户端应用。
应用场景:
- Web应用:如电子邮件、社交媒体、在线办公(Google Docs)、在线购物等。
- 企业信息系统:如ERP、CRM等。
2. C/S (Client/Server) 模式
特点:
- 定制客户端:客户端一般是专门开发的软件,能够提供更丰富的用户体验和功能。
- 高效通信:客户端和服务器之间的通信可以通过专门设计的协议,效率较高。
- 复杂性:客户端需要安装和配置,带来了版本管理和更新的挑战。
- 强大的处理能力:可以在客户端进行大量的数据处理和计算,减轻服务器的负担。
应用场景:
- 桌面应用:如各类办公软件、设计软件、数据分析工具等。
- 游戏:如网络游戏客户端。
- 企业内部应用:如定制的生产管理系统、财务系统等。
3. P2P (Peer-to-Peer) 模式
特点:
- 对等网络:网络中的每台计算机(节点)都可以同时作为客户端和服务器,互相提供资源和服务。
- 分布式资源共享:资源(如文件、计算能力、存储空间等)分布在多个节点上,没有单一的集中服务器。
- 弹性和可扩展性:节点可以随时加入或离开网络,系统具备良好的扩展性和容错性。
- 安全和版本控制挑战:由于缺乏集中管理,安全和版本控制是主要的挑战。
应用场景:
- 文件共享:如BitTorrent、eMule等P2P文件共享系统。
- 分布式计算:如SETI@home、Folding@home等分布式计算项目。
- 即时通讯:如早期的Skype(部分功能使用P2P技术)。
- 区块链:如比特币、以太坊等分布式账本技术。
混合模式
许多现代应用混合使用了以上三种模式,以充分利用各自的优势。例如:
- 网络视频应用:可以使用B/S模式提供用户界面和播放功能,使用C/S模式进行视频流的高效传输,同时使用P2P模式来分发和共享视频文件,从而减轻服务器负载。
- 在线游戏:客户端负责图形渲染和用户交互(C/S模式),游戏更新和社交功能通过浏览器进行(B/S模式),而玩家之间的资源共享或通信可以采用P2P模式。
电子商务模式区分
电子商务模式(B2B、B2C、C2C、C2B、O2O等)主要描述的是商业交易的参与者和关系,而不是技术实现方式。因此,不要将其与网络应用模式混淆。
因为有很多人被问到这个问题的时候马上想到的是B2B(如阿里巴巴)、B2C(如当当、亚马逊、京东)、C2C(如淘宝、拍拍)、C2B(如威客)、O2O(如美团、饿了么)。
总结
B/S、C/S和P2P三种典型的网络应用模式各有特点和适用场景。了解这些模式的基本概念和应用场景有助于在设计和开发网络应用时做出更合理的架构选择。同时,现代应用常常结合多种模式,以发挥各自的优势,满足复杂的需求。
41、7大法则和23种设计模式
在软件开发领域,设计模式和开发法则是提升软件质量和开发效率的重要工具。下面介绍7大设计法则和23种经典设计模式。
7大设计法则
-
单一职责原则(Single Responsibility Principle, SRP)
- 定义:一个类应该只有一个引起它变化的原因。
- 目的:降低类的复杂度,提高其可维护性和可读性。
-
开放封闭原则(Open/Closed Principle, OCP)
- 定义:软件实体(类、模块、函数等)应该对扩展开放,对修改封闭。
- 目的:通过扩展功能而不是修改现有代码来实现新的需求,从而提高系统的稳定性和可扩展性。
-
里氏替换原则(Liskov Substitution Principle, LSP)
- 定义:子类对象可以替换父类对象而不影响系统的正确性。
- 目的:确保继承关系的合理性,保证子类在替代父类时能正确执行。
-
依赖倒置原则(Dependency Inversion Principle, DIP)
- 定义:高层模块不应该依赖低层模块,二者都应该依赖于抽象;抽象不应该依赖于细节,细节应该依赖于抽象。
- 目的:减少模块间的耦合,提高系统的可维护性和可扩展性。
-
接口隔离原则(Interface Segregation Principle, ISP)
- 定义:客户端不应该被强迫依赖它不使用的方法;一个类对另一个类的依赖应该建立在最小接口上。
- 目的:通过多个专门的接口,而不是单一的总接口,让接口实现类只需关心自己需要的方法。
-
合成复用原则(Composite Reuse Principle, CRP)
- 定义:尽量使用对象组合,而不是继承来达到代码复用的目的。
- 目的:通过组合现有对象的功能来复用代码,而不是通过继承来增加系统的灵活性和可维护性。
-
迪米特法则(Law of Demeter, LoD,又称最少知识原则)
- 定义:一个对象应该对其他对象有最少的了解。
- 目的:通过减少对象之间的依赖关系,降低系统的模块间耦合度,提高系统的可维护性。
23种设计模式
设计模式通常分为三大类:创建型模式、结构型模式和行为型模式。以下是这23种设计模式的介绍。
创建型模式(Creational Patterns)
-
单例模式(Singleton Pattern)
- 目的:确保一个类只有一个实例,并提供一个全局访问点。
- 示例:线程池、缓存、日志对象。
-
工厂方法模式(Factory Method Pattern)
- 目的:定义一个创建对象的接口,但让子类决定实例化哪个类。
- 示例:Java中的
Calendar.getInstance()方法。
-
抽象工厂模式(Abstract Factory Pattern)
- 目的:提供一个创建一系列相关或相互依赖对象的接口,而无需指定其具体类。
- 示例:GUI工具库中的窗口、按钮、文本框等控件家族。
-
建造者模式(Builder Pattern)
- 目的:将一个复杂对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表示。
- 示例:各种复杂对象的构建,如构建不同风格的房屋。
-
原型模式(Prototype Pattern)
- 目的:使用原型实例指定创建对象的种类,并通过复制这些原型创建新的对象。
- 示例:对象的克隆,特别是在需要大量相似对象的场景中。
结构型模式(Structural Patterns)
-
适配器模式(Adapter Pattern)
- 目的:将一个类的接口转换成客户希望的另一个接口,使原本接口不兼容的类可以一起工作。
- 示例:Java的
java.util.Arrays#asList方法。
-
桥接模式(Bridge Pattern)
- 目的:将抽象部分与它的实现部分分离,使它们都可以独立变化。
- 示例:图形绘制系统中的形状和颜色的分离。
-
组合模式(Composite Pattern)
- 目的:将对象组合成树形结构以表示“部分-整体”的层次结构,使得客户端对单个对象和组合对象的使用具有一致性。
- 示例:文件系统中的文件和文件夹。
-
装饰器模式(Decorator Pattern)
- 目的:动态地给一个对象添加一些额外的职责,就扩展功能而言,装饰器模式比生成子类更灵活。
- 示例:Java的
java.io.BufferedReader类。
-
外观模式(Facade Pattern)
- 目的:为子系统中的一组接口提供一个一致的界面,使得子系统更容易使用。
- 示例:Java的
javax.faces.context.FacesContext类。
- 享元模式(Flyweight Pattern)
- 目的:运用共享技术有效地支持大量细粒度对象的复用。
- 示例:Java的字符串常量池。
- 代理模式(Proxy Pattern)
- 目的:为其他对象提供一种代理,以控制对这个对象的访问。
- 示例:Java的RMI(远程方法调用)。
行为型模式(Behavioral Patterns)
- 责任链模式(Chain of Responsibility Pattern)
- 目的:为请求创建一个接收者对象的链,使多个对象都有机会处理这个请求。
- 示例:Java的
javax.servlet.Filter接口。
- 命令模式(Command Pattern)
- 目的:将一个请求封装成一个对象,从而使你可以用不同的请求对客户进行参数化。
- 示例:Java的
java.lang.Runnable接口。
- 解释器模式(Interpreter Pattern)
- 目的:给定一个语言,定义它的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。
- 示例:SQL解析器。
- 迭代器模式(Iterator Pattern)
- 目的:提供一种方法顺序访问一个聚合对象中的各个元素,而不暴露其内部表示。
- 示例:Java的
java.util.Iterator接口。
- 中介者模式(Mediator Pattern)
- 目的:用一个中介对象封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散。
- 示例:Java的
java.awt.Container类。
- 备忘录模式(Memento Pattern)
- 目的:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便以后可以将对象恢复到原先保存的状态。
- 示例:Java的
java.util.Date类。
- 观察者模式(Observer Pattern)
- 目的:定义对象间的一种一对多的依赖关系,以便当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知并自动更新。
- 示例:Java的
java.util.Observer接口和java.util.Observable类。
- 状态模式(State Pattern)
- 目的:允许一个对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类。
- 示例:Java的线程状态转换。
- 策略模式(Strategy Pattern)
- 目的:定义一系列算法,把每一个算法封装起来,并且使它们可以互换。
- 示例:Java的
java.util.Comparator接口。
- 模板方法模式(Template Method Pattern)
- 目的:定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,使得子类可以不改变算法的结构即可重定义该算法的某些特定步骤。
- 示例:Java的
javax.servlet.http.HttpServlet类。
- 访问者模式(Visitor Pattern)
- 目的:表示一个作用于某对象结构中的各元素的操作,它使你可以在不改变各元素类的前提下定义作用于这些元素的新操作。
- 示例:Java的
java.nio.file.FileVisitor接口。
总结
7大设计法则和23种设计模式是软件开发中的重要工具,有助于提高软件的可维护性、可扩展性和复用性。设计模式提供了有效的解决方案,而设计法则则提供了指导原则,两者结合使用可以帮助开发者设计出高质量的软件系统。
42、分布式ID
在分布式系统中,确保唯一ID的生成是一个重要而且复杂的问题。分布式ID系统需要解决以下几个关键问题:
- 唯一性:ID必须是全局唯一的。
- 高可用性:ID生成系统必须能够在高并发条件下保持可用。
- 有序性:在某些场景中,还需要ID是有序的。
- 效率:ID生成过程需要高效,能够快速生成ID。
以下是几种常见的分布式ID生成策略:
1. 数据库自增ID
利用数据库的自增ID特性生成唯一ID。具体方法是每次插入记录时,数据库会自动生成一个唯一的自增ID。
- 优点:实现简单,ID有序。
- 缺点:单点故障、性能瓶颈,高并发情况下可能会出现锁争用。
CREATE TABLE ids (
id BIGINT AUTO_INCREMENT PRIMARY KEY
);
2. UUID (Universally Unique Identifier)
UUID 是一种标准的128位全局唯一标识符。
- 优点:生成简单,几乎不可能重复。
- 缺点:长度较长,不适合用于索引,有些场景下可能会显得过于冗长。
在许多编程语言中都可以轻松生成UUID,例如在Python中:
import uuid
unique_id = uuid.uuid4()
3. Snowflake 算法
Snowflake 算法是由Twitter开发的一种分布式ID生成算法。生成的ID是64位整数,结构如下:
- 1位符号位:始终为0。
- 41位时间戳:表示当前时间,与一个固定的时间起点之间的时间差。
- 10位机器ID:表示生成ID的机器或节点。
- 12位序列号:在同一毫秒内生成的ID的序号。
| 1 bit | 41 bits timestamp | 10 bits machine ID | 12 bits sequence number |
这种结构确保了ID的全局唯一性和趋势递增性。
- 优点:高性能、高并发下生成ID,时间有序性。
- 缺点:依赖系统时间,如果时间回拨可能会出现重复ID。
示例实现(Python)
class SnowflakeIDGenerator:
def __init__(self, machine_id, epoch=1546300800000):
self.machine_id = machine_id
self.epoch = epoch
self.sequence = 0
self.last_timestamp = -1
def _current_timestamp(self):
return int(time.time() * 1000)
def _next_timestamp(self):
while True:
timestamp = self._current_timestamp()
if timestamp > self.last_timestamp:
return timestamp
def get_id(self):
timestamp = self._current_timestamp()
if timestamp < self.last_timestamp:
raise Exception("Clock moved backwards. Refusing to generate id")
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & 0xFFF
if self.sequence == 0:
timestamp = self._next_timestamp()
else:
self.sequence = 0
self.last_timestamp = timestamp
id = ((timestamp - self.epoch) << 22) | (self.machine_id << 12) | self.sequence
return id
4. 基于Redis的ID生成
Redis可以通过其原子操作来生成唯一ID。例如,可以使用INCR命令:
-- Redis命令
INCR key
- 优点:简单、高效,利用Redis的高性能和原子性保证唯一性。
- 缺点:单点故障问题,需要Redis高可用配置来解决。
5. 基于Zookeeper的ID生成
Zookeeper可以利用其顺序节点(sequential node)特性来生成唯一ID。每次创建顺序节点时,Zookeeper会自动为节点名添加一个递增的序号。
- 优点:ID有序,Zookeeper提供的高可用性和可靠性。
- 缺点:Zookeeper本身的复杂性和性能瓶颈。
总结
在选择分布式ID生成策略时,需要根据具体应用场景的需求来权衡不同方法的优缺点。如果需要简单实现和不关心ID的长度,可以选择UUID。如果需要高并发和有序性,Snowflake算法是一个较好的选择。如果依赖现有的数据库或缓存系统,利用它们的自增特性也是一种简单有效的方式。综合考虑系统的高可用性、性能和复杂度,选择最适合的解决方案。
43、Java中常见集合
以下是Java中常见集合类及其底层数据结构和特点的汇总表:
| 集合类型 | 底层数据结构 | 特点 |
|---|---|---|
ArrayList | 动态数组 | 1. 随机访问速度快(O(1)) 2. 插入和删除速度较慢(O(n)) 3. 支持动态扩展 |
LinkedList | 双向链表 | 1. 插入和删除速度快(O(1)) 2. 访问速度慢(O(n)) 3. 支持双向遍历 |
HashMap | 数组 + 链表/红黑树(冲突解决) | 1. 访问、插入和删除速度快(O(1),最坏O(n)) 2. 无序 |
TreeMap | 红黑树 | 1. 有序 2. 插入、删除和访问速度较快(O(log n)) |
HashSet | 基于HashMap | 1. 无重复元素 2. 无序 3. 插入和删除速度快(O(1),最坏O(n)) |
TreeSet | 基于红黑树 | 1. 无重复元素 2. 有序 3. 插入和删除速度较快(O(log n)) |
LinkedHashMap | 哈希表 + 双向链表 | 1. 访问、插入和删除速度快(O(1),最坏O(n)) 2. 有序(按插入顺序或访问顺序) |
LinkedHashSet | 基于LinkedHashMap | 1. 无重复元素 2. 有序(按插入顺序) 3. 插入和删除速度较快(O(1),最坏O(n)) |
PriorityQueue | 二叉堆(最小堆/最大堆) | 1. 支持快速获取最小值或最大值(O(1)) 2. 插入和删除速度较快(O(log n)) |
ArrayDeque | 动态数组 | 1. 双端队列 2. 插入和删除速度快(O(1)) 3. 不支持随机访问 |
Vector | 动态数组 | 1. 线程安全 2. 随机访问速度快(O(1)) 3. 插入和删除速度较慢(O(n)) 4. 支持动态扩展 |
Stack | 动态数组(继承Vector) | 1. 后进先出(LIFO) 2. 插入和删除速度快(O(1)) 3. 线程安全 |
总结
ArrayList和LinkedList适用于不同的应用场景,前者适合随机访问,后者适合频繁的插入和删除。HashMap和TreeMap提供了不同的键值对存储方式,前者无序且速度快,后者有序但速度稍慢。HashSet和TreeSet适用于不同需要保持唯一性的集合,前者无序,后者有序。LinkedHashMap和LinkedHashSet在原有哈希表基础上增加了顺序性,适合需要顺序访问的场景。PriorityQueue适用于需要经常获取最小值或最大值的场景。ArrayDeque是性能良好的双端队列实现。Vector和Stack提供了线程安全的动态数组实现,但一般不推荐在新代码中使用。
44、布隆过滤器
布隆过滤器(Bloom Filter)是一种空间效率非常高的概率数据结构,用于检查一个元素是否可能在一个集合中。它的核心特点是能够高效地处理大量数据,但会有一定的误判率,即可能会错误地判断一个不在集合中的元素为在集合中。布隆过滤器不支持删除操作。
工作原理
布隆过滤器的基本构成包括一个位数组(bit array)和一组哈希函数(hash functions)。其操作主要分为两个部分:元素插入和元素查询。
1. 元素插入
- 首先,将要插入的元素通过一组哈希函数进行哈希运算,得到一组哈希值。
- 然后,将这些哈希值对应的位数组位置设为1。
2. 元素查询
- 对查询元素同样进行哈希运算,得到一组哈希值。
- 检查这些哈希值对应的位数组位置是否都为1。如果都为1,说明该元素可能在集合中;否则,说明该元素一定不在集合中。
优点
- 空间效率高:相比于传统集合(如哈希表),布隆过滤器使用的空间要少得多。
- 查询速度快:查询操作的时间复杂度是常数时间。
缺点
- 误判率:布隆过滤器会有一定的误判率,即可能会判断一个实际不在集合中的元素为在集合中。
- 不支持删除:布隆过滤器不支持删除操作,因为删除可能会影响其他元素的判断。
实现示例
以下是一个简单的布隆过滤器的Java实现:
import java.util.BitSet;
import java.util.Random;
public class BloomFilter {
private static final int DEFAULT_SIZE = 2 << 24;
private static final int[] seeds = new int[] {3, 5, 7, 11, 13, 31, 37, 61};
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length];
public BloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
public static void main(String[] args) {
BloomFilter filter = new BloomFilter();
filter.add("hello");
filter.add("world");
System.out.println(filter.contains("hello")); // true
System.out.println(filter.contains("world")); // true
System.out.println(filter.contains("bloom")); // false
}
}
应用场景
- 网页爬虫中的URL去重:布隆过滤器可以用来判断一个URL是否已经被访问过,从而避免重复抓取。
- 垃圾邮件过滤:在电子邮件系统中,布隆过滤器可以用来快速判断一封邮件是否为垃圾邮件。
- 分布式系统中的缓存:布隆过滤器可以用来判断一个缓存是否含有某个元素,从而减少不必要的数据库查询。
布隆过滤器在很多需要快速判断元素是否存在的大规模数据处理场景中都有广泛应用,是一种非常高效的算法工具。
45、二阶段提交和三阶段提交
二阶段提交(2PC, Two-Phase Commit)和三阶段提交(3PC, Three-Phase Commit)是分布式系统中常见的分布式事务协议,用于确保分布式环境下的所有参与节点能够一致地提交或回滚事务。它们用于解决在分布式系统中事务一致性的问题。
二阶段提交(2PC)
二阶段提交协议分为两个阶段:准备阶段(Prepare Phase)和提交阶段(Commit Phase)。
准备阶段(Prepare Phase)
- **协调者(Coordinator)**向所有参与者(Participants)发送准备请求(Prepare Request),询问是否可以提交事务。
- 参与者执行本地事务操作,但不提交,记录操作日志,并向协调者返回表明自己是否准备好提交的响应(Prepare Response)。
提交阶段(Commit Phase)
- 协调者根据所有参与者的响应决定事务的最终结果。
- 如果所有参与者都同意提交,协调者向所有参与者发送提交请求(Commit Request)。
- 如果有任何参与者不同意提交,协调者向所有参与者发送回滚请求(Rollback Request)。
- 参与者接收到协调者的最终请求后,执行对应的提交或回滚操作,并向协调者返回结果。
优点:
- 实现简单,能有效保证事务的原子性。
缺点:
- 孤军现象:如果协调者在第二阶段之前崩溃,参与者会一直处于准备阶段,无法提交或回滚。
- 同步阻塞:参与者在准备阶段会被阻塞,直到收到协调者的最终指令。
三阶段提交(3PC)
三阶段提交协议在二阶段提交的基础上增加了一个准备提交阶段(Precommit Phase),以减少协调者宕机带来的影响。
阶段一:准备阶段(CanCommit Phase)
- 协调者向所有参与者发送准备请求(CanCommit Request),询问是否可以提交事务。
- 参与者执行本地检查,并向协调者返回表明自己是否可以提交的响应(CanCommit Response)。
阶段二:准备提交阶段(Precommit Phase)
- 协调者根据所有参与者的响应决定是否可以进入准备提交阶段。
- 如果所有参与者都返回同意,协调者向所有参与者发送准备提交请求(PreCommit Request)。
- 如果有任何参与者返回不同意,协调者向所有参与者发送中止请求(Abort Request)。
- 参与者接收到准备提交请求后,执行本地预提交操作,记录操作日志,并返回确认(ACK)。
阶段三:提交阶段(DoCommit Phase)
- 协调者根据所有参与者的确认决定事务的最终结果。
- 如果所有参与者都返回确认,协调者向所有参与者发送提交请求(DoCommit Request)。
- 如果有任何参与者未返回确认,协调者向所有参与者发送中止请求(Abort Request)。
- 参与者接收到最终请求后,执行对应的提交或回滚操作,并向协调者返回结果。
优点:
- 减少了协调者宕机时的孤军现象,因为在准备提交阶段,参与者知道自己可以提交,并且已经记录了日志。
- 更具容错性,协调者和参与者都能在不同阶段采取适当的补救措施。
缺点:
- 比二阶段提交更复杂,需要更多的通信次数,会带来额外的网络开销。
对比与应用
- 复杂性:三阶段提交比二阶段提交更复杂,需要更多的步骤和通信。
- 可靠性:三阶段提交在协调者崩溃后具有更好的容错性和恢复能力。
- 性能:二阶段提交协议的性能优于三阶段提交,因为其通信步骤较少。
在实际应用中,选用哪种提交协议需要权衡系统的性能和可靠性需求。如果系统对性能要求较高且能够容忍一定的风险,二阶段提交可能更合适。如果系统对数据一致性要求极高且无法容忍任何风险,三阶段提交则是更好的选择。
实际应用
在实际分布式系统中,由于三阶段提交的复杂性和性能开销较大,通常会结合使用其他机制(如补偿事务、幂等操作、重试机制等)来实现分布式事务的一致性。此外,现代分布式数据库和微服务架构中,常常使用分布式共识算法(如Paxos、Raft)或基于日志的分布式事务(如Sagas模式)来替代2PC和3PC。
46、jwt
JSON Web Token(JWT)是一种用于在各方之间作为JSON对象安全地传输信息的开放标准。JWT通常用于身份验证、授权和信息交换。它具有以下几个优点:
- 紧凑和自包含:JWT是URL安全的,可以在URL、POST参数或HTTP头中发送。它包含了所需的信息,因此不需要在服务器上存储会话信息。
- 可验证:使用数字签名(如HMAC或RSA),接收方可以验证JWT的真实性和完整性。
JWT 的结构
JWT由三部分组成:Header(头部)、Payload(负载)和Signature(签名)。它们用点(.)分隔。
例如:xxxxx.yyyyy.zzzzz
1. Header(头部)
Header通常包含两个部分:类型(即JWT)和使用的签名算法(如HMAC SHA256或RSA)。
{
"alg": "HS256",
"typ": "JWT"
}
2. Payload(负载)
Payload包含声明(claims),声明是关于实体(通常是用户)和其他数据的声明。有三种类型的声明:
- Registered claims:预定义的声明,如
iss(发行者)、exp(到期时间)、sub(主题)和aud(接收方),这些是推荐使用的但不是强制的。 - Public claims:用户定义的声明,可以通过IANA JSON Web Token Registry标准化,或避免冲突使用一组私有命名空间。
- Private claims:私有声明是为了在同意的双方之间共享信息。
例如:
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
3. Signature(签名)
为了创建签名,需要将编码后的Header、编码后的Payload和一个密钥组合起来,并使用Header中指定的签名算法进行签名。
例如,如果使用HMAC SHA256算法,签名过程如下:
HMACSHA256(
base64UrlEncode(header) + "." + base64UrlEncode(payload),
secret)
签名用于验证消息的发送者,并确保消息在途中未被更改。
JWT 的使用
JWT的常见使用场景包括:
-
认证(Authentication):
- 用户登录时,服务器生成一个JWT并返回给客户端。
- 客户端每次请求时将JWT发送到服务器(通常放在Authorization头部)。
- 服务器验证JWT并根据其中的信息处理请求。
-
授权(Authorization):
- JWT可以存储用户的权限信息,服务器可以根据JWT中的权限信息来决定是否允许用户执行某个操作。
-
信息交换:
- 因为JWT是自包含的,它可以用于安全地在各方之间传递信息,并且接收方可以验证信息的真实性。
示例代码
以下是使用Java中的io.jsonwebtoken库生成和解析JWT的示例代码:
生成JWT
import io.jsonwebtoken.Jwts;
import io.jsonwebtoken.SignatureAlgorithm;
import java.util.Date;
public class JWTExample {
private static final String SECRET_KEY = "mySecretKey";
public static void main(String[] args) {
String jwt = Jwts.builder()
.setSubject("1234567890")
.setIssuedAt(new Date())
.setExpiration(new Date(System.currentTimeMillis() + 3600000)) // 1 hour
.claim("name", "John Doe")
.claim("admin", true)
.signWith(SignatureAlgorithm.HS256, SECRET_KEY)
.compact();
System.out.println("Generated JWT: " + jwt);
}
}
解析JWT
import io.jsonwebtoken.Claims;
import io.jsonwebtoken.Jwts;
public class JWTExample {
private static final String SECRET_KEY = "mySecretKey";
public static void main(String[] args) {
String jwt = "xxxxx.yyyyy.zzzzz"; // 替换为实际的JWT
Claims claims = Jwts.parser()
.setSigningKey(SECRET_KEY)
.parseClaimsJws(jwt)
.getBody();
System.out.println("Subject: " + claims.getSubject());
System.out.println("Name: " + claims.get("name"));
System.out.println("Admin: " + claims.get("admin"));
}
}
安全注意事项
- 选择合适的签名算法:确保使用安全的签名算法来保护JWT,如HS256或RS256。
- 保护密钥:签名密钥应当严格保密,不能泄露。
- 验证所有声明:在使用JWT时,务必验证所有重要的声明,如到期时间(exp)、发行者(iss)和接收方(aud)。
- 使用HTTPS:确保通过HTTPS传输JWT以保护传输中的数据。
JWT在分布式身份验证和授权中非常有用,但同时也需要注意安全实践,避免潜在的安全风险。
47、nginx如何配置请求路径
Nginx 是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。配置 Nginx 时,你可以通过编写配置文件来控制请求路径的处理方式。以下是一些基本的配置示例,说明如何配置请求路径。
基本配置文件结构
Nginx 的主要配置文件通常位于 /etc/nginx/nginx.conf 或 /usr/local/nginx/conf/nginx.conf。配置文件的基本结构如下:
http {
server {
listen 80;
server_name example.com;
location / {
root /var/www/html;
index index.html index.htm;
}
location /api/ {
proxy_pass http://backend_server;
}
location /static/ {
alias /var/www/static/;
}
}
}
配置示例
1. 基本路径配置
通过 location 指令配置不同的路径处理,例如将根路径 / 定向到某个目录:
server {
listen 80;
server_name example.com;
location / {
root /var/www/html;
index index.html index.htm;
}
}
上述配置将所有到根路径 / 的请求映射到 /var/www/html 目录,并默认查找 index.html 或 index.htm 文件。
2. 反向代理配置
将某个路径下的请求转发到后台服务器(反向代理):
server {
listen 80;
server_name example.com;
location /api/ {
proxy_pass http://backend_server;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
上述配置将所有 /api/ 开头的请求转发到 http://backend_server。
3. 路径别名配置
将某个路径别名映射到不同的目录:
server {
listen 80;
server_name example.com;
location /static/ {
alias /var/www/static/;
}
}
上述配置将 /static/ 路径映射到 /var/www/static/ 目录。例如,请求 /static/css/style.css 将被映射到 /var/www/static/css/style.css。
4. 使用正则表达式匹配路径
通过正则表达式匹配路径并处理请求:
server {
listen 80;
server_name example.com;
location ~ ^/images/.*\.(jpg|jpeg|png|gif)$ {
root /var/www/html;
}
}
上述配置将匹配 /images/ 目录下的所有图片文件(扩展名为 .jpg, .jpeg, .png, .gif),并将请求映射到 /var/www/html/images 目录。
5. URL 重写
使用 rewrite 指令进行 URL 重写:
server {
listen 80;
server_name example.com;
location / {
rewrite ^/old-path/(.*)$ /new-path/$1 permanent;
}
}
上述配置将所有 /old-path/ 路径的请求永久重定向到 /new-path/。
高级配置
1. 负载均衡
将请求负载均衡到多个后端服务器:
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
上述配置将请求负载均衡到 backend1.example.com 和 backend2.example.com。
2. 使用 try_files
用于处理静态文件并在文件不存在时转发请求:
server {
listen 80;
server_name example.com;
location / {
root /var/www/html;
try_files $uri $uri/ /index.html;
}
}
上述配置将尝试查找请求的文件或目录,如果都不存在,则返回 index.html 文件。
结论
Nginx 提供了灵活且强大的配置选项,可以根据不同的请求路径执行各种操作,包括静态文件服务、反向代理、路径别名、URL 重写等。通过理解和使用这些配置指令,可以构建高效、稳定的 Web 服务。
48、gateway作用以及如何配置路由
网关(Gateway)在网络和应用架构中起着非常重要的作用,主要用于接受客户端请求并将其转发到适当的服务或后端。网关可以提供负载均衡、安全、路由、监控和限流等功能,使得后端服务可以更加专注于业务逻辑而无需处理这些通用问题。
网关的主要作用
- 请求路由:根据请求路径、头信息、参数等,将请求转发到适当的后端服务。
- 负载均衡:将请求分发到多个后端实例以实现负载均衡。
- 安全管理:处理认证、授权和数据加密,保护后端服务的安全。
- 协议转换:将不同协议之间的请求进行转换,如从HTTP到WebSocket。
- 流量控制:限流、熔断、重试等,保护后端服务免受过载。
- 监控与日志:收集请求和响应的日志,监控服务的健康状态。
配置网关进行路由
不同的网关有不同的配置方法。这里我们以两个常见的网关:Nginx 和 Spring Cloud Gateway 为例,介绍如何配置路由。
使用 Nginx 配置路由
Nginx 可以作为反向代理和HTTP网关来使用,通过配置不同的 server 和 location 块来实现请求路由。
示例配置:
http {
upstream backend1 {
server backend1.example.com;
}
upstream backend2 {
server backend2.example.com;
}
server {
listen 80;
server_name gateway.example.com;
# 根路径的请求转发到backend1
location / {
proxy_pass http://backend1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
# /api路径的请求转发到backend2
location /api/ {
proxy_pass http://backend2;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
上述配置中,Nginx 将根路径 / 的请求转发到 backend1,将 /api/ 路径的请求转发到 backend2。
使用 Spring Cloud Gateway 配置路由
Spring Cloud Gateway 是一个基于 Spring Framework 和 Spring Boot 的网关解决方案,具有动态路由、断路器、限流、重试等特性。
示例配置:
首先,需要添加 Spring Cloud Gateway 依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
然后,在配置文件 application.yml 中配置路由:
spring:
cloud:
gateway:
routes:
- id: backend1_route
uri: http://backend1.example.com
predicates:
- Path=/api/backend1/**
- id: backend2_route
uri: http://backend2.example.com
predicates:
- Path=/api/backend2/**
上述配置中,Spring Cloud Gateway 将 /api/backend1/** 路径的请求转发到 http://backend1.example.com,将 /api/backend2/** 路径的请求转发到 http://backend2.example.com。
自定义过滤器:
Spring Cloud Gateway 还支持通过 Java 代码自定义过滤器:
import org.springframework.cloud.gateway.route.RouteLocator;
import org.springframework.cloud.gateway.route.builder.RouteLocatorBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class GatewayConfig {
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route("backend1_route", r -> r.path("/api/backend1/**")
.uri("http://backend1.example.com"))
.route("backend2_route", r -> r.path("/api/backend2/**")
.uri("http://backend2.example.com"))
.build();
}
}
总结
网关在分布式系统和微服务架构中起着至关重要的作用,能够帮助我们实现请求路由、负载均衡、安全管理等功能。无论是通过 Nginx 还是 Spring Cloud Gateway 配置路由,都可以通过灵活的配置和扩展来满足不同的需求。选择合适的网关方案,取决于具体的应用场景、性能要求以及团队的技术栈。
49、jvm怎么检查死锁
在 JVM 中检查死锁主要有以下几种方法:
- 使用 Java 自带的工具:如
jstack。 - 使用第三方监控工具:如 VisualVM、JConsole。
- 在代码中手动检测:使用线程管理工具类,如
ThreadMXBean。
使用 Java 自带的工具
jstack
jstack 是 JDK 提供的一个工具,用于生成 Java 虚拟机中某个进程的线程快照(线程 dump),它能够帮助你分析和诊断死锁等问题。以下是使用 jstack 检查死锁的步骤:
-
找到 JVM 进程 ID:
你可以使用jps命令来列出当前所有的 Java 进程及其 PID。jps -
生成线程 dump:
使用jstack命令生成线程 dump。jstack <pid> > thread_dump.txt其中
<pid>是你的 Java 应用的进程 ID,thread_dump.txt是输出的线程 dump 文件。 -
分析线程 dump 文件:
打开thread_dump.txt文件,查找Found one Java-level deadlock关键字,如果存在,则表示发现了死锁,并且会列出涉及死锁的线程。
使用第三方监控工具
VisualVM
VisualVM 是一个功能强大的工具,集成了多个 JDK 自带的监控和分析工具,可以用来监控 Java 应用的性能、内存、CPU 使用情况以及检测死锁。
-
启动 VisualVM:
在命令行中运行jvisualvm启动 VisualVM 工具。jvisualvm -
连接到目标应用:
在 VisualVM 中,你会看到一个本地应用列表,双击你想要监控的 Java 应用。 -
检测死锁:
切换到Threads选项卡,点击Detect Deadlock按钮,如果存在死锁,VisualVM 会给出相应的提示。
JConsole
JConsole 是另一个 JDK 自带的监控工具,主要用于监控 JVM 的性能情况。
-
启动 JConsole:
在命令行中运行jconsole启动 JConsole 工具。jconsole -
连接到目标应用:
在 JConsole 中选择你要监控的 Java 应用,然后点击Connect。 -
检测死锁:
切换到Threads选项卡,JConsole 会自动检测死锁,如果存在死锁,会有对应的提示信息。
在代码中手动检测
你可以在代码中使用 ThreadMXBean 来检测死锁。ThreadMXBean 是 Java 管理扩展 (JMX) 中的一个接口,它提供了对线程系统的监控方法。
import java.lang.management.ManagementFactory;
import java.lang.management.ThreadInfo;
import java.lang.management.ThreadMXBean;
public class DeadlockDetector {
public static void main(String[] args) {
ThreadMXBean bean = ManagementFactory.getThreadMXBean();
// 检查死锁
long[] threadIds = bean.findDeadlockedThreads();
if (threadIds != null) {
ThreadInfo[] infos = bean.getThreadInfo(threadIds);
System.out.println("Detected deadlock threads:");
for (ThreadInfo info : infos) {
System.out.println(info.getThreadName());
}
} else {
System.out.println("No deadlock found.");
}
}
}
总结
检测死锁的方法有多种,具体选择哪种方法取决于你的具体需求和环境。对于日常的监控和诊断,使用 jstack、VisualVM 或 JConsole 这样的工具是比较方便和直观的。而在一些特定的场景下,可能需要在代码中手动检查死锁,通过 ThreadMXBean 来进行实时检测和处理。通过这些方法,可以有效地发现和解决死锁问题,提高应用的可靠性和稳定性。
50、jps
jps 是 JDK 自带的一个工具,用于列出当前所有运行的 Java 虚拟机进程及其进程 ID。它非常有用,当你需要了解系统中正在运行哪些 Java 应用程序时,特别是在需要进行故障排查和性能分析时。
使用 jps 命令
基本用法
jps
该命令会输出当前用户权限下所有运行的 Java 进程的进程 ID 以及对应的 Java 类名或 JAR 文件名。
常用选项
-
-l:输出进程的主类全名或 JAR 文件的完整路径。jps -l -
-v:输出每个 Java 进程的启动参数。jps -v -
-m:输出传递给主类的参数。jps -m -
-q:仅输出进程 ID,不输出类名或 JAR 文件名。jps -q
综合示例
jps -lv
该命令会输出每个 Java 进程的进程 ID、主类全名或 JAR 文件的完整路径、以及启动参数。
实际输出示例
假设你在系统上运行了几个 Java 应用程序,执行 jps -lv 命令后的输出可能如下所示:
1234 org.example.MyApplication -Dconfig.file=/path/to/config
5678 jar:file:/path/to/another-app.jar!/BOOT-INF/classes!/ com.example.AnotherApp
9102 sun.tools.jps.Jps -Dapplication.home=/path/to/jdk -Xms8m
在这个示例中:
1234是进程 ID,org.example.MyApplication是主类名,-Dconfig.file=/path/to/config是传递给主类的参数。5678是进程 ID,表示运行了一个 JAR 文件another-app.jar,对应的主类是com.example.AnotherApp。9102是jps本身的进程 ID。
jps 的应用场景
-
查找 Java 进程:当你需要对运行中的 Java 程序进行调试或性能分析时,
jps能帮助你快速找到目标进程的 ID。 -
结合其他工具:在找到目标进程的 ID 后,可以结合
jstack、jmap、jstat等其他 JDK 工具进行进一步的分析和诊断。例如使用jstack查看线程 dump,以分析线程的状态和排查死锁问题。
其他注意事项
- 权限问题:
jps命令列出的进程是当前用户权限下所有的 Java 进程。如果需要查看其他用户的 Java 进程,可能需要相应的权限。 - 环境变量:确保你的
JAVA_HOME环境变量正确设置,并且jps命令在系统的PATH中。
通过 jps,你可以方便地查看系统上正在运行的 Java 应用进程,为进一步的调试和分析打下基础。
51、jstack
jstack 是 JDK 提供的一个命令行工具,用于生成 Java 虚拟机中某个进程的线程快照(也称为线程 dump)。线程 dump 显示了每个线程的调用栈,可以帮助你分析和诊断线程相关的问题,如死锁、线程阻塞、性能瓶颈等。
使用 jstack 命令
基本用法
jstack <pid>
其中 <pid> 是你想要生成线程 dump 的 Java 进程的进程 ID。
常用选项
-
-l:显示额外的锁信息。jstack -l <pid> -
-m:显示本地方法调用栈(C/C++代码)。jstack -m <pid> -
-F:当通常的jstack命令无法响应时,强制生成线程 dump。jstack -F <pid> -
-h:显示帮助信息。jstack -h
输出重定向到文件
你可以将命令输出重定向到文件中,以便后续分析:
jstack <pid> > thread_dump.txt
实际输出示例
以下是一个典型的 jstack 输出示例:
2023-01-01 12:00:00
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.291-b10 mixed mode):
"main" #1 prio=5 os_prio=0 tid=0x00007f9d0c00b800 nid=0x1c03 waiting on condition [0x00007f9d1c7e3000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x000000076b8f8ff8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
"Reference Handler" #2 daemon prio=10 os_prio=0 tid=0x00007f9d0c014000 nid=0x1c04 in Object.wait() [0x00007f9d1c8e4000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x000000076b8f8b70> (a java.lang.ref.Reference$Lock)
at java.lang.Object.wait(Object.java:502)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:157)
"Finalizer" #3 daemon prio=8 os_prio=0 tid=0x00007f9d0c018000 nid=0x1c05 in Object.wait() [0x00007f9d1c9e5000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x000000076b8f91e8> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)
...
"VM Thread" os_prio=0 tid=0x00007f9d0c021000 nid=0x1c07 runnable
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007f9d0c004800 nid=0x1c01 runnable
...
输出
- 线程名称:例如
"main",即线程的名字。 - 线程 ID:例如
#1,即线程的 ID。 - 优先级:例如
prio=5,即线程的优先级。 - 本地线程 ID:例如
nid=0x1c03,即操作系统分配的线程 ID。 - 线程状态:例如
java.lang.Thread.State: WAITING (parking),即线程的当前状态。 - 调用栈:显示该线程的调用栈信息。
检查死锁
在 jstack 生成的线程 dump 中,如果存在死锁,会有类似如下的提示:
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x000000076b8f8ff8 (object 0x000000076b8f8ff8, a java.util.concurrent.locks.ReentrantLock$FairSync),
which is held by "Thread-2"
"Thread-2":
waiting to lock monitor 0x000000076b8f8b70 (object 0x000000076b8f8b70, a java.util.concurrent.locks.ReentrantLock$FairSync),
which is held by "Thread-1"
总结
jstack 是一个非常有用的命令行工具,可以帮助你生成并分析 Java 应用程序的线程 dump。从线程 dump 中可以看出每个线程的调用栈、状态及相关的锁信息,对于调试死锁、线程阻塞和性能问题非常有帮助。通过结合 jstack 与其他 JDK 工具,可以更好地了解和优化 Java 应用的性能和稳定性。
52、jmap
jmap 是 JDK 提供的一个工具,用于生成关于 Java 进程内存使用情况信息。它可以帮助你分析 Java 应用程序的内存分配状况、堆的使用情况以及生成堆转储(heap dump)等。
使用 jmap 命令
基本用法
jmap <option> <pid>
其中 <option> 是你想要进行的操作选项,<pid> 是目标 Java 进程的进程 ID。
常用选项
-
-heap:显示堆的概要信息,包括使用的 GC 算法、堆配置以及各个区域的内存使用情况。jmap -heap <pid> -
-histo[:live]:显示堆中的对象直方图。如果附加:live,则只显示活跃对象(即未被垃圾收集的对象)。jmap -histo <pid> jmap -histo:live <pid> -
-dump:format=b,file=<filename>:生成堆转储文件,格式为二进制。jmap -dump:format=b,file=heap_dump.hprof <pid> -
-finalizerinfo:显示等待终结的对象信息。jmap -finalizerinfo <pid> -
-F:当通常的jmap命令无法响应时,强制生成堆转储或直方图。jmap -dump:format=b,file=heap_dump.hprof -F <pid>
输出重定向到文件
你可以将命令输出重定向到文件中,以便后续分析:
jmap -heap <pid> > heap_info.txt
实际输出示例
以下是一些常用 jmap 命令的输出示例:
jmap -heap <pid>
Attaching to process ID <pid>, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.291-b10
using parallel threads in the new generation.
using thread-local object allocation.
Parallel GC with 2 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 257949696 (246.0MB)
OldSize = 54525952 (52.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 1793064960 (1710.0MB)
used = 123456789 (117.65234375MB)
free = 1669604608 (1592.34765625MB)
6.887739968365553% used
Eden Space:
capacity = 1572864 (1.5MB)
used = 0 (0.0MB)
free = 1572864 (1.5MB)
0.0% used
From Space:
capacity = 257949696 (246.0MB)
used = 123456789 (117.65234375MB)
free = 134492907 (128.34765625MB)
48.25590761316872% used
To Space:
capacity = 257949696 (246.0MB)
used = 0 (0.0MB)
free = 257949696 (246.0MB)
0.0% used
concurrent mark-sweep generation:
capacity = 2044723200 (1950.0MB)
used = 123456789 (117.65234375MB)
free = 1911266411 (1832.34765625MB)
6.887739968365553% used
4653 interned Strings occupying 495221 bytes.
jmap -histo <pid>
num #instances #bytes class name
----------------------------------------------
1: 10000 16000000 [I
2: 50000 8000000 [C
3: 20000 3200000 java.util.HashMap$Node
4: 50000 3000000 java.lang.String
5: 1000 2800000 <some other class>
...
Total 200000 40000000
应用场景
-
内存使用分析:通过
jmap -heap可以查看堆的使用情况,帮助你了解应用程序的内存分配和使用模式。 -
对象分布分析:通过
jmap -histo可以查看堆中对象的分布情况,识别内存泄漏或内存使用异常的类。 -
生成堆转储:通过
jmap -dump生成堆转储文件,可以用其他分析工具(如 Eclipse MAT、VisualVM)进一步分析内存问题。 -
终结器分析:通过
jmap -finalizerinfo可以查看等待终结的对象信息,帮助你了解对象的生命周期管理问题。
其他注意事项
- 权限问题:
jmap命令需要对目标进程有足够的权限。如果是其他用户的进程,可能需要超级用户权限。 - 性能影响:生成堆转储或对象直方图可能会对应用程序的性能产生一定影响,建议在非高峰期或测试环境中执行。
- 环境变量:确保你的
JAVA_HOME环境变量正确设置,并且jmap命令在系统的PATH中。
通过使用 jmap,你可以深入了解 Java 应用程序的内存使用情况,为优化内存性能和解决内存问题提供有力的支持。
53、VisualVM
VisualVM 是一个功能强大的工具,用于监视、故障排除和分析 Java 应用程序的性能。它集成了多个 JDK 工具(如 jstack、jmap、jinfo、jstat 等)的功能,提供了一个图形化的用户界面,使得监控和分析 Java 应用程序更加直观和方便。
安装和启动 VisualVM
-
下载与安装:
你可以从 VisualVM 的官方网站 下载 VisualVM。下载完成后,解压并按照说明进行安装。 -
启动:
安装完成后,运行 VisualVM 可执行文件启动工具。通常,你可以在安装目录下找到名为visualvm的可执行文件。
主要功能
1. 监控 JVM 性能
VisualVM 提供了对 JVM 实时监控的功能,包括 CPU 使用率、内存使用情况、垃圾回收活动等。
- 概览(Overview):显示选定应用程序的基本信息,包括 JVM 参数、系统属性、线程和堆内存使用情况。
- 监视(Monitor):提供 CPU、内存、线程和类加载的实时图表。
- 线程(Threads):显示应用程序中的所有线程及其状态,支持查看线程 dump(堆栈跟踪)。
2. 分析堆内存使用
VisualVM 可以生成并分析堆转储文件,帮助你找出内存泄漏和高内存消耗的对象。
- 堆转储(Heap Dump):生成并分析堆转储文件。可以查看对象分布、查找垃圾对象等。
- 内存分析(Sampler):通过内存采样分析对象的分布情况,识别热点对象。
3. CPU 性能分析
VisualVM 提供了 CPU 分析功能,帮助你识别性能瓶颈和高 CPU 消耗的方法。
- CPU 分析(Profiler):通过 CPU 采样分析应用程序的性能,展示各个方法的执行次数和消耗时间。
4. 插件扩展
VisualVM 支持通过插件扩展功能,你可以根据需要安装额外的插件来增强 VisualVM 的功能。
- 插件中心:在 VisualVM 的 “工具” 菜单中,可以找到 “插件” 选项,进入插件中心安装和管理插件。
使用示例
以下是如何使用 VisualVM 监控和分析 Java 应用程序的几个示例:
监控 JVM
-
启动 VisualVM:
打开 VisualVM。 -
连接 Java 应用程序:
在 VisualVM 左侧的 “应用程序” 树中,找到你要监控的 Java 应用程序。双击该应用程序以打开监控视图。 -
查看监控数据:
切换到 “监视” 标签,可以看到 CPU、内存、线程和类加载的实时图表。
分析堆内存
-
生成堆转储:
在 “应用程序” 树中右键点击目标应用程序,选择 “堆转储” 生成堆转储文件。 -
分析堆转储:
堆转储生成后,VisualVM 会自动打开该文件。你可以查看对象分布、垃圾对象和内存泄漏信息。
CPU 分析
-
启动 CPU 分析:
在 “应用程序” 树中右键点击目标应用程序,选择 “分析” -> “CPU 分析”。 -
查看分析结果:
一段时间后,停止 CPU 分析,你可以查看各个方法的执行次数、消耗时间和调用图。
注意事项
- 性能影响:在生产环境中进行堆转储或 CPU 分析时,可能会对应用程序的性能产生一定影响,建议在非高峰期或测试环境中进行。
- 权限问题:确保你对目标 Java 进程有足够的权限,以便进行监控和分析。
- JDK 版本:VisualVM 通常与 JDK 捆绑在一起,确保你的 JDK 版本与 VisualVM 兼容。
通过 VisualVM,你可以直观地了解 Java 应用程序的运行状况和性能瓶颈,从而更好地进行性能优化和故障排除。
54、JConsole
JConsole 是一个基于 Java Management Extensions (JMX) 的图形化监控工具,用于实时监控和管理 Java 应用程序的性能和资源使用情况。它是 JDK 自带的一个实用工具,可以帮助开发者和运维人员监视 JVM 的各种参数,如内存使用、线程活动、类加载和垃圾回收等。
如何启动 JConsole
-
通过命令行启动:
打开你的命令行终端,输入以下命令:jconsole这将启动 JConsole 应用程序。
-
通过 JDK 安装目录启动:
在 JDK 安装目录的bin目录下,找到jconsole可执行文件,双击启动它。
连接到 Java 应用程序
本地连接
当 JConsole 启动后,它会自动列出当前用户拥有权限的所有本地 Java 进程。你可以从列表中选择一个 Java 应用程序进行监控。
-
选择进程:
在 “新连接” 对话框中选择你要监控的 Java 进程。 -
点击连接:
选择进程后,点击 “连接” 按钮。
远程连接
你还可以通过 JMX 远程连接到运行在其他机器上的 Java 应用程序。
-
配置远程应用程序:
远程 Java 应用程序需要启动时启用 JMX 远程连接。可以通过以下 JVM 参数来启用:-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=<port> -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -
输入远程连接字符串:
在 “新连接” 对话框中选择 “远程进程”,并输入远程连接字符串,格式为hostname:port。 -
点击连接:
输入连接信息后,点击 “连接” 按钮。
主要功能
概览(Overview)
- 概览标签 提供了 JVM 的基本信息,包括 CPU 使用率、内存使用情况、线程数和类加载数。
- 内存使用情况:查看堆内存和非堆内存的使用情况。
- 线程活动:显示当前活动线程的数量和总线程数。
- 类加载:显示当前加载的类数量和自 JVM 启动以来加载的类总数。
内存(Memory)
- 堆内存使用:实时查看堆内存的使用情况,并可以手动触发垃圾回收。
- 非堆内存使用:监控非堆内存(如 Metaspace、Code Cache 等)的使用情况。
线程(Threads)
- 线程状态:显示所有线程的当前状态(如运行、等待、阻塞等)。
- 线程栈:查看每个线程的堆栈跟踪,帮助诊断线程问题。
类加载(Classes)
- 类加载信息:显示当前加载的类数量、已卸载的类数量和总共加载的类数量。
- 类加载趋势:查看类加载和卸载的趋势图。
VM 测试(VM Summary)
- JVM 概览:显示 JVM 的版本信息、启动时间和输入参数等。
MBeans
- 管理 MBeans:你可以通过 JConsole 访问和管理应用程序公开的 JMX MBeans,进行更细粒度的监控和管理。
使用示例
监控内存使用情况
- 启动 JConsole 并连接到目标应用程序。
- 切换到 “内存” 标签,查看堆内存和非堆内存的实时使用情况。
- 手动触发垃圾回收:点击 “Perform GC” 按钮,手动触发一次垃圾回收,观察内存使用的变化。
分析线程活动
- 启动 JConsole 并连接到目标应用程序。
- 切换到 “线程” 标签,查看所有线程的状态。
- 查看线程堆栈跟踪:点击某个线程,查看其堆栈跟踪,分析线程的执行路径和状态。
管理和监控 MBeans
- 启动 JConsole 并连接到目标应用程序。
- 切换到 “MBeans” 标签,展开树状结构,查看应用程序公开的所有 MBeans。
- 管理 MBeans 属性和操作:选择某个 MBean,可以查看和修改其属性,调用其操作方法。
注意事项
- 权限问题:确保你对目标 Java 进程有足够的权限,以便进行监控和管理。如果是远程连接,确保网络和防火墙配置允许 JMX 连接。
- 性能影响:在生产环境中使用 JConsole 进行深度监控(如频繁触发垃圾回收或查看线程栈)时,可能对应用程序性能产生一定影响,建议在非高峰期或测试环境中执行。
- 安全性:配置远程 JMX 连接时,建议启用身份验证和 SSL 加密,确保连接的安全性。
通过 JConsole,你可以实时监控和管理 Java 应用程序的各种性能指标,帮助你更好地了解和优化应用程序的运行状况。
55、Spring Security
Spring Security 是一个强大且高度可定制的安全框架,主要用于在基于 Spring 的 Java 应用程序中实现身份验证和授权。它提供了全面的安全功能,能够保护 Web 应用程序、微服务和企业应用程序。
主要功能
- 身份验证(Authentication):支持多种身份验证方式,如表单登录、HTTP 基本认证、OAuth2、LDAP 等。
- 授权(Authorization):基于角色和权限的访问控制机制,支持方法级别和URL级别的安全控制。
- 防止 CSRF 攻击:内置 CSRF 保护机制。
- 会话管理:支持会话固定攻击防护、并发会话控制等。
- 集成:与 Spring Framework 的各个模块紧密集成,如 Spring Boot、Spring MVC 等。
安装和配置
依赖配置
如果你在使用 Spring Boot,可以在 pom.xml 中添加 Spring Security 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
基本配置
创建一个安全配置类,并继承 WebSecurityConfigurerAdapter 类:
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/public/**").permitAll() // 允许所有人访问 /public/ 下的资源
.anyRequest().authenticated() // 其他请求需要身份验证
.and()
.formLogin()
.loginPage("/login") // 自定义登录页面
.permitAll()
.and()
.logout()
.permitAll();
}
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth
.inMemoryAuthentication()
.withUser("user").password("{noop}password").roles("USER")
.and()
.withUser("admin").password("{noop}admin").roles("ADMIN");
}
}
功能
身份验证
Spring Security 提供了多种身份验证方式,你可以根据需求选择合适的方式。
表单登录
http
.formLogin()
.loginPage("/login")
.permitAll();
HTTP 基本认证
http
.httpBasic();
LDAP 身份验证
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth
.ldapAuthentication()
.userDnPatterns("uid={0},ou=people")
.groupSearchBase("ou=groups")
.contextSource()
.url("ldap://localhost:8389/dc=springframework,dc=org")
.and()
.passwordCompare()
.passwordEncoder(new LdapShaPasswordEncoder())
.passwordAttribute("userPassword");
}
授权
Spring Security 提供了基于 URL 和方法级别的授权控制。
URL 级别控制
http
.authorizeRequests()
.antMatchers("/admin/**").hasRole("ADMIN")
.antMatchers("/user/**").hasRole("USER")
.anyRequest().authenticated();
方法级别控制
使用注解在方法级别进行控制:
import org.springframework.security.access.prepost.PreAuthorize;
import org.springframework.stereotype.Service;
@Service
public class MyService {
@PreAuthorize("hasRole('ROLE_ADMIN')")
public void adminMethod() {
// Admin specific logic
}
@PreAuthorize("hasRole('ROLE_USER')")
public void userMethod() {
// User specific logic
}
}
在配置类中启用方法安全:
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.method.configuration.EnableGlobalMethodSecurity;
@Configuration
@EnableGlobalMethodSecurity(prePostEnabled = true)
public class MethodSecurityConfig {
// Additional configuration if needed
}
CSRF 保护
CSRF(跨站请求伪造)攻击是一种常见的 Web 攻击,Spring Security 默认启用了 CSRF 保护。
在某些情况下(例如使用 API 的时候),你可能需要禁用 CSRF 保护:
http
.csrf().disable();
会话管理
Spring Security 还提供了会话管理功能,可以防止会话固定攻击和控制并发会话。
防止会话固定攻击
http
.sessionManagement()
.sessionFixation().migrateSession();
并发会话控制
http
.sessionManagement()
.maximumSessions(1)
.maxSessionsPreventsLogin(true);
总结
Spring Security 是一个功能强大且高度可定制的安全框架,能够满足各种 Java 应用程序的安全需求。通过合理的配置和使用,可以有效地保护应用程序免受各种安全威胁。如果你在开发基于 Spring 的 Java 应用程序,Spring Security 是一个不可或缺的安全解决方案。


















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











