






PG数据库基础
1. PostGreSQL与MySOL区别
1.1 数据库以及PostGresQL介绍
数据库定义
数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
PostGreSQL
一个功能强大的开源对象关系型数据库系统,它使用和扩展了SQL语言,并结合了许多安全存储和扩展最复杂数据工作负载的功能。
MySQL与PostGresQL异同点
**共同特点:**开源免费、SQL语法、事务处理、全文检索
区别:
- SQL语法格式区别
- 关键符号区别
- 自增区别
- 函数区别
MySQL比较PostGresQL优势
- InnoDB基于回滚实现MVCC机制,效率更高
- 索引组织表,适用于基于主键匹配査询,删改操作
- 优化器简单,适用于简单查询操作
- 简单查询速度更快,适用于业务逻辑相对简单场景
PostGresQL与MySQL对比

如果应用需要复杂的数据模型、强大的功能集和保障数据安全,PostgreSQL可能是更好的选择。
2. PostGreSQL架构设计
2.1 服务架构
database
每个PG服务可以包含多个独立的database。
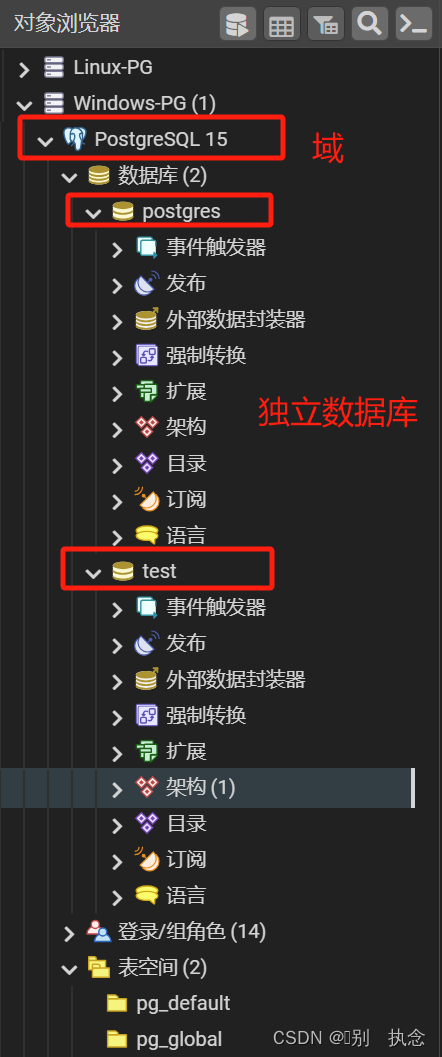
schema
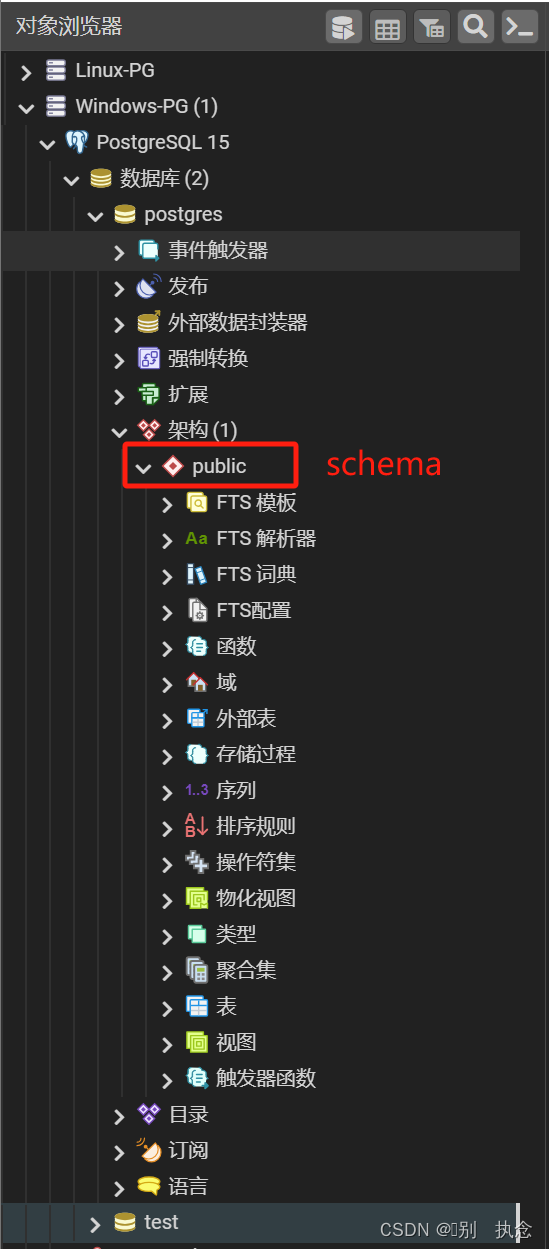
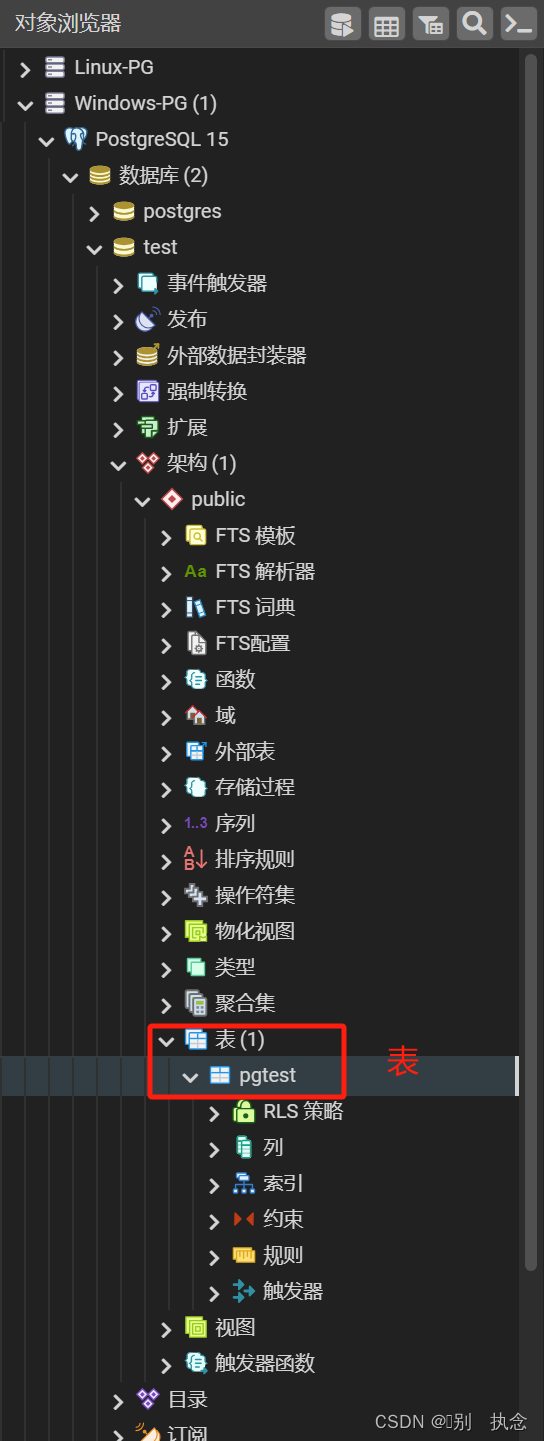
Table
2.2 PostgreSQL 整体架构
2.2.1进程架构
PostgreSQL是一个多进程架构的客户端/服务器模式的关系型数据库管理系统。PG数据库中的一系列进程组合进来就是PostgreSQL服务端。这些进程可以细分为以下几大类:
- postgres server进程 -是PG数据库中所有进程的父进程。
- backend进程 - 每个客户端对于一个backend进程,处于这个客户端中的所有请求。
- background进程 - 包含多个后台进程,比如做脏块刷盘的BACKGROUND WRITER进程,做垃圾清理的AUTOVACUUM进程,做检查点的CHECKPOINTER进程等。
- replication相关进程 - 处理流复制的进程。
PG数据库中有一个主的postgres server进程,针对每个客户端有一个backend postgres进程,另外有一系列的background后台进程(针对不同的功能模块)。所以这些进程都对应一个共享内存shared memory。
Postgres Server Process
postgres server process是所有PG进程的父进程,在以前的版本中称为postmaster。
当使用pg_ctl start启动数据库时,这个进程就被启动了, 然后它会启动一个共享内存shared memory,启动多个background后台进程,启动复制相关进程,如有需要也启动background worker progress,然后等待客户端的连接。
当接收到一个客户端连接时,它就会启动一个backend progress,专门服务于这个客户端。
postgres server process通常有一个对应的监听端口,默认是5432。如果一台机器上安装多个postgres实例有多个postgres server process,那么就需要修改对应的端口地址比如5433、5434等。
Backend Process
backend process也称为postgres进程,是由postgres server process启动的用于服务于对应的客户端,通过TCP协议和客户端进行通信。
由于这个进程只能服务于一个特定的database,所以需要在连接PG数据库的时候指定一个默认连接的database。
PG允许多个客户端同时连接数据库,由max_connections参数控制最大并发连接数,默认是100。
如果有很多客户端频繁的对数据库进行短连接与释放连接,那么可能会造成连接耗时比较长,因为PG目前没有连接池的功能。针对于这种场景,一般通过像pgbouncer或pgpool-II这种插件来优化。
Background Process
background process后台进程有多个,每个进程负责一个模块或是一类任务
- background writer:负责将共享内存中的脏页刷到持久化存储,在PG9.1或更早版本中也负责checkpoint的工作
- checkpointer:在PG9.2及之后版本中,引入用来单独处理checkpoint任务
- autovacuum launcher:向postgres server进程请求启动autovacuum worker进程,用来进行定期的aotuvacuum任务
- WAL writer:负责将共享内存中的WAL周期性的刷到持久化存储
- statistics collector:负责收集统计信息,如pg_stat activity和pg_stat_database
- logging collector:负责把错误消息写到日志文件
- archiver:负责归档日志
2.2.2 内存架构
PG中的内存主要分为两类:
- 本地内存区:用于每个backend process内部使用,每个客户端连接对应一个本地内存区。
- 共享内存区:所有PG进程共享使用。
本地内存区
本地内存区有多个,每个对应一个backend progres进程,用于处于这个连接内部的一些工作,包括:
- work_mem:进行ORDER BYIDISTINCT语句相关的排序工作,以及像merge关联或hash关联之类的关联工作
- maintenance_work_mem:一些维护之类的工作,比如vacuum、reindex之类
- temp_buffers:存储临时表相关的工作
共享内存区
共享内存区在数据库启动时创建,也可以划分为多个子区域,包括:
- shared buffer pool:从持久化存储中把表及索引数据加载到这个区域直接操作数据
- WAL buffer:为了保证数据不丢失,PG支持WAL机制,WAL数据(XLOG)就是事务相关的日志,WALbufer是WAL日志落盘前的缓冲区
- commit log:commit log(CLOG)保存所有事务的状态,如in_progress、committed、aborted
3. PostGreSQL数据类型和函数
3.1数据类型
数值类型

自增类型

布尔类型

二进制类型

位串类型

字符串类型

日期时间类型

枚举类型
枚举类型是包含一系列有序的静态值集合的一个数据类型,使用前需要先声明
枚举类型使用CREATE TYPE来创建,如下所示:
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
枚举创建后,就可以将其作为PostgresSQL预定义的类型使用
CREATE TABLE person (
name text,
current_mood mood
);
INSERT INTO person VALUES ('Moe', 'happy');
几何类型

网络地址类型

XML类型
xml类型可用于存储XML数据,插入数据时会对输入的数据进行检查,使不符合XML标准的数据不能存放到数据库中,同时还提供了函数对其类型进行安全性检查,可以使用函数xmlparse将字符串转换为xml数据,如下所示:
XMLPARSE ( {DOCUMENT | CONTENT} value)
JSON类型

JSON类型与PostgreSQL数据库类型映射

3.2 函数
查询服务器当前时间及日期
select now(); 取当前日期及时间
select current_time;
select current_date;
select extract(YEAR from now()); 取当前日期的年
select extract(month from now()); //取当前月
select extract(day from now()); //取当前日
字符串操作
select 'aaaaa'||'bbbbbb' as f1; //字符串相加
select char_length('abcdefgh'); //字符串长度
select position('fgh' in 'abcdefgh'); //查找子串
select substring ( 'abcdefgh' from 5 for 3); //取一段字符串
select lower( 'abCDefgh')||upper('abCDefgh')
日期转字符串
select to_char(now(), 'yyyy-mm-dd hh:mi:ss');
数学函数
abs(-23.7)=23.7 --绝对值:
cbrt(8)=2 --立方根:
ceil(-38.8)=-38 ,ceiling(-38.8)=-38 --不小于参数的最小整数:
degree(1)=57.2957795 --把弧度转化为角度:
exp(1)=2.7182818 --自然指数:
floor(-42.8)=-43,floor(42.8)=42 --不大于参数的最大值:
ln(2.71828)=0.9999993273472820 --自然对数:
log(1000)=3 --以10为底的对数:
log(2.0,32.0)=5 --以b为底数的对数:log(b,x),
mod(7,3)=1 --y/x的余数:mod(y,x),
pi()=3.14159265358979 --pi常量:
power(2.0,3.0)=8 --a的b次幂:
radians(45.0)=0.785398163397448 --角度转换为弧度:
random() --随机一个小数。0.0~1.0之间的随机数:
round(36.5)=37 --四舍五入到最接近的整数:
round(36.5252,2)=36.53 --四舍五入到n位小数:
setseed(0.54823)=117314959 --为随后的random()调用设置种子(0~1之间) :
sign(-8.4)=-1 --参数的符号:(-1,0,1),
sqrt(2)=1.4142136623731 --平方根:
trunc(42.8)=42 --截断,向零靠近:
trunc(42.4382,2)=42.43 --截断为n位小数:
acos(1)=0 --反余玄
acos(-1)=3.14159265358979
asin(0)=0 --反正玄
asin(1)*2=3.14159265358979 --反余玄
atan(1)=0.788398163397448 --反正切
atan2(1,1)=0.788398163397448 --x/y的反正切。
cos(pi())=-1 ,cos(0)=1 --余玄
cot(0)=Infinity --余切
sin(0)=0,sin(pi()/2)=1 --正玄
tan(pi()/4)=1 --正切
character varing(n)
varchar(n) pg变长,最大1G,oracle中varchar2(n) 最多4000,mysql varchar(n) 最多64K。
character(n),char(n) 定长,最大1G。
text :变长,无长度限制,与mysql中的longtext 类似。
4. PostGreSQL数据索引
创建索引
CREATE INDEX index_name ON table_name;
索引类型
(1)单列索引
单列索引是一个只基于表的一个列上创建的索引,基本语法如下:
CREATE INDEX index_name
ON table_name (column_name);
(2)组合索引
组合索引是基于表的多列上创建的索引,基本语法如下:
CREATE INDEX index_name
ON table_name (column1_name, column2_name);
(3)唯一索引
CREATE UNIQUE INDEX index_name
on table_name (column_name);
(4)局部索引
CREATE INDEX index_name
on table_name (conditional_expression);
(5)隐式索引
隐式索引 是在创建对象时,由数据库服务器自动创建的索引。索引自动创建为主键约束和唯一约束。
删除索引
DROP INDEX index_name;
- 索引不应该使用在较小的表上。
- 索引不应该使用在有频繁的大批量的更新或插入操作的表上。
- 索引不应该使用在含有大量的 NULL 值的列上。
- 索引不应该使用在频繁操作的列上。
5. PostGreSQL调优
数据库优化的思路常用的是下面两种:
- 第一种思路:“The fastest way to do something is don’t do it”,意思是说,“ 做得最快的方法就是不做”。从这个思路上来说,把一些无用的步骤或作用不大的步骤去掉就是一种优化。
- 第二种思路:做同样一件事情,要想更快有多种方法,最简单的方法就是换硬件。让数据库跑在更快的硬件上。但换硬件一般都是最后的选择,除此之外,最有效的方法是优化算法,如让SQL走到更优的执行计划上。
在数据库优化中,主要有以下优化指标。
- 响应时间:衡量数据库系统与用户交互时多久能够发出响应。
- 吞吐量:衡量在单位时间内可以完成的数据库任务。
6. 数据库架构演变
单体架构

主从架构

共享存储负载均衡

分布式架构

云原生分布式架构

7. PostGreSQL集群模式原理

数据复制方式
- Shared DiskFailover:共享磁盘。只有一份磁盘数据避免了数据复制的开消,但当共享磁盘失效时主备服务器都宕机,备服务器不应该操作磁盘
- File System (BlockDevice)Replication:文件系统复制。主库上的文件系统改变时能正确的同步到备服务器上,要求备库上的文件系统定入的顺序与主库一致,DRDB是常用的工具。
- Write-Ahead LogShipping:预写日志。备库通过读取预写日志同步数据。当主库宕机时,备库几乎拥有主备的全部数据,并且可以快速切换到主库。同步可以是异步或者同步的,但是必须对所有主库的所有数据库同步。可以使用日志发送(file-based log Shipping)或者流streaming)来实现同步。
- LogicalReplication:逻辑复制。逻辑复制允许数据库服务器将数据修改流发送到另一个服务器。PostGreSQL逻辑复制从WAL构造一个逻辑数据修改流。逻辑复制允许复制来自各个表的数据更改。
- Trigger-BasedMaster-StandbyReplication:基于触发器的主备复制。主库实时的捕获修改的数据并异步发送到备库。复制的是表。
- Statement-BasecReplication Middleware:基于语句的复制中间件。程序拦截每个SQL查询并将其发送到复制服务器。读写查询必须发送到所有服务器,以便每个服务器都能收到任何更改。但是只读查询只能发送到一台服务器,从而允许在它们之间分配读工作负载。random()、CURRENT TIMESTAMP和sequence会有问题要特殊处理。
- Asynchronous Multimaster Replication:异步多主复制
- SynchronousMultimaster Replication:同步多主复制。多主复制每个库都可以接受读写请求,在每个事务提交之前,修改过的数据发送到其它服务器。大量的写活动可能会导致过度的锁定和提交延迟,从而导致较差的性能。同步多主复制最适合大多数读工作负载。多主复制数据在一台上修改后复制到其它库,因此不存在random()的问题。
共享磁盘集群模式

基于WAL的物理数据复制

基于SQL的逻辑复制

基于citus的完全分布式集群


主从集群构建参考CSDN文章《postgres 数据库搭建集群 (主备模式)》















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









