






JAVA 实现多线程下载大文件
开发中遇到一个问题,下载大文件到本地,导致等待时间过长,然后就寻找一个可以多线程下载的办法,受下载软件启发,想到多线程下载,
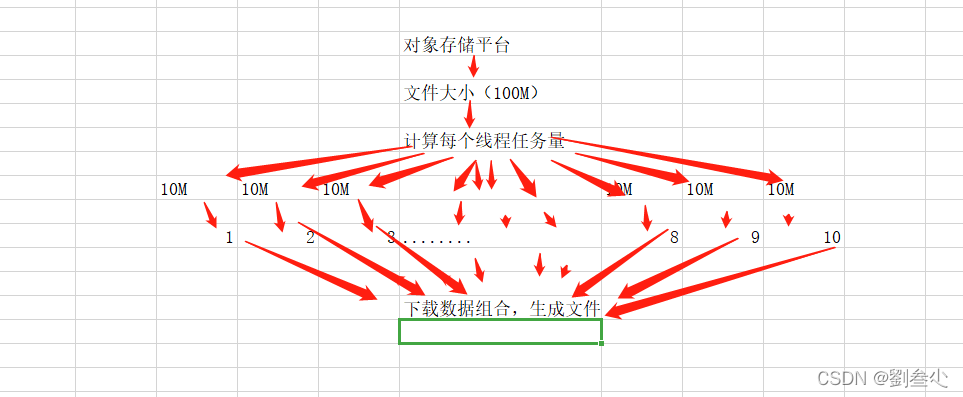
原理,首先查到这个文件的大小,然后根据线程数量去分配每个线程下载多大的片段,然后将每个线程的组合到一起,就是最终的下载文件。如图
然后就是代码时间, 必不可少的控制层
@Override
@ApiOperation(value = "多线程获取大文件", httpMethod = "POST")
@BodyValidate
public Result getBigFile(@RequestBody CommonFileRequest commonFileRequest, HttpServletResponse response) {
return commonFileService.getBigFile(commonFileRequest,response);
}
然后是业务层
/**
* .
* @Description: 作用: 多线程获取大文件
* @Author: LXT
* @Date: 2021/12/27 9:18
* @param request 入参
* @return Result
*/
public Result getBigFile(CommonFileRequest request, HttpServletResponse response) {
logger.info("多线程获取大文件," + JSON.toJSONString(request));
long start = System.currentTimeMillis();
//超大 6G
//String path = "???";
// 1.3G
//String path = "???";
//正常大小
String path = "???";
try {
ServletOutputStream out = null;
String s = BigFileDownload.BigFileTestUtil(accessKey, secretKey, endpoint, bucketName, path);
File file = new File(s);
InputStream fis = new BufferedInputStream(new FileInputStream(file));
response.reset();
// 设置response的Header
response.addHeader("Content-Length", "" + file.length());
response.setContentType("application/octet-stream;charset=UTF-8");
response.setHeader("Content-disposition", "attachment;filename=" + UUID.randomUUID().toString().replace("-", "") + ".zip");
out = response.getOutputStream();
//读取文件流
int len = 0;
byte[] buffer = new byte[1024 * 10];
while ((len = fis.read(buffer)) != -1){
out.write(buffer,0,len);
}
out.flush();
} catch (Exception ex) {
ex.printStackTrace();
}
logger.info("获取大文件耗时 {}", BusinessStringUtils.formatTime(System.currentTimeMillis() - start));
return null;
}
解析 首先 记录一下请求的日志 然后是拿到对应的存储位置
然后去平台获取文件 BigFileDownload.BigFileTestUtil 这个方法
返回的缓存在服务器 或者本地的一个位置 然后将其返回给移动端
后边这些就不说了 都是正常的反流代码 这里着重说明 多线程分片下载
/**
* .
*
* @ClassName: BigFileDownload
* @Description:
* @Author: LXT
* @Date: 2021/12/27 13:01
*/
public class BigFileDownload {
//创建一个计数器锁。初始值为线程数量,每执行结束一个线程后计数器减去1 ,当计数器为0的时候await等待的线程会被唤醒继续执行。
public static CountDownLatch latch = new CountDownLatch(100);
public static String BigFileTestUtil(String accessKey, String secretKey, String endpoint, String bucketName, String downloadFilePath) {
RandomAccessFile file = null;
String filename = "D:\\222ddddd2.zip";
File fileDownService = new File(filename);
if (!fileDownService.exists()) {
try {
fileDownService.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("文件已创建");
} else {
System.out.println("文件已存在");
}
try {
AWSCredentials credentials = new BasicAWSCredentials(accessKey, secretKey);
ClientConfiguration clientConfig = new ClientConfiguration();
clientConfig.setProtocol(Protocol.HTTP);
AmazonS3 s3Client = new AmazonS3Client(credentials, clientConfig);
s3Client.setEndpoint(endpoint);
//获取对象大小
AmazonS3 instance = AmazonS3Builder.getInstance(endpoint, accessKey, secretKey);
S3Object object = instance.getObject(bucketName, downloadFilePath);
S3ObjectInputStream in3 = object.getObjectContent();
ObjectMetadata metadata = object.getObjectMetadata();
long filesize = metadata.getInstanceLength();
System.out.println("文件大小:" + filesize);
ExecutorService service = Executors.newFixedThreadPool(100);
long length = filesize;
long packageLength = length / 100;
long leftLength = length % 100;
long pos = 0;
long end = packageLength;
file = new RandomAccessFile(filename, "rw");
//计算每个线程请求文件的开始和结束位置
for (int i = 0; i < 100; i++) {
if (leftLength > 0) {
packageLength++;
leftLength--;
}
System.out.println("pos: " + pos + " endpos: " + packageLength);
service.execute(new BigFileDownloadRunnable(pos, packageLength, file, endpoint, accessKey, secretKey, bucketName, downloadFilePath));
pos = packageLength;
packageLength = packageLength + end;
}
//等待其他线程结束后继续向下执行
try {
latch.await();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//关闭线程池
service.shutdown();
} catch (AmazonServiceException | FileNotFoundException e) {
// 服务端错误
e.printStackTrace();
} finally {
if (file != null) {
try {
file.close();
} catch (Exception e) {
}
}
}
return filename;
}
}
其实也比较好理解 首先创建一个线程 用来分片下载
然后是主代码
方法入参 分别是 对象平台的一些参数 只有随后一个是存储平台地址 其他平台可自行更改
然后就是做一个本地缓存用的假文件
接着到 异常里
先做存储平台的链接,然后获取要下载文件的大小
获取大小后 更具线程数量 自行计算启动多少个线程来下载 我这里直接给的100 然后使用for进行线程的启动 启动后进入线程等待 全执行完之后 可正常生成文件,
然后就是线程使用的分片下载工具类
/**
* .
*
* @ClassName: BigFileDownloadRunnable
* @Description:
* @Author: LXT
* @Date: 2021/12/27 13:19
*/
class BigFileDownloadRunnable implements Runnable {
private String endpoint;
private String accessKey;
private String secretKey;
private String bucketName;
private long from;
private long end;
private RandomAccessFile file;
private String downloadFilePath;
public BigFileDownloadRunnable(long from, long end, RandomAccessFile file,
String endpoint, String accessKey, String secretKey, String bucketName,String downloadFilePath) {
this.from = from;
this.end = end;
this.file = file;
this.endpoint = endpoint;
this.accessKey = accessKey;
this.secretKey = secretKey;
this.bucketName = bucketName;
this.downloadFilePath = downloadFilePath;
}
public void run() {
String filename = downloadFilePath;
S3Object objectPortion = null;
InputStream input = null;
BufferedInputStream buffer = null;
try {
AWSCredentials credentials = new BasicAWSCredentials(accessKey, secretKey);
ClientConfiguration clientConfig = new ClientConfiguration();
clientConfig.setProtocol(Protocol.HTTP);
clientConfig.setConnectionTimeout(90000000);
clientConfig.setMaxConnections(1000);
AmazonS3 s3Client = new AmazonS3Client(credentials, clientConfig);
s3Client.setEndpoint(endpoint);
//获取对象指定范围的流写入文件
GetObjectRequest rangeObjectRequest = new GetObjectRequest(bucketName, filename).withRange(from, end);
objectPortion = s3Client.getObject(rangeObjectRequest);
input = objectPortion.getObjectContent();
buffer = new BufferedInputStream(input);
byte[] buf = new byte[1024];
int len;
long start = this.from;
long stop = this.end;
for (; ; ) {
if ((len = buffer.read(buf)) == -1) {
break;
}
synchronized (file) {
file.seek(from);
file.write(buf, 0, len);
}
from += len;
}
System.out.println("文件片段 " + start + "~" + stop + "下载完成");
new BigFileDownload().latch.countDown();//线程结束计数器减1
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (buffer != null) {
try {
buffer.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (input != null) {
try {
input.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (objectPortion != null) {
try {
objectPortion.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
因为线程分段 也需要去请球平台 所以就将平台的数据一并传输过来
然后线程内run 大概意思 就是 我拿到了平台链接 然后又有文件的存错位置 还有我需要下载的片段位置,然后就是正常下载过程
由于大文件比较大 链接时间设置的相对较长一点,
一小点的进步都是对开发者的激励,记录一下,分享给大家。有用记得点♥















 7730
7730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









