






java 模板 word转pdf 可分页 带图片
之前写过一个简单的案例,但是在项目中完全不能满足客户的需求,所以重新用啦一种方式来写,采用了word转换pdf的方式,这种经过不断研究,满足了可分页,列表循环数据可带图片,可以说很完善了。
第一步:先来编写word自定义模板以及转换模板,转换模板可以直接是客户发过来的样式模板,自定义模板呢,就是带java中赋值的占位符字段。
下面举例几个:
单个:

列表:无边框

列表:有边框
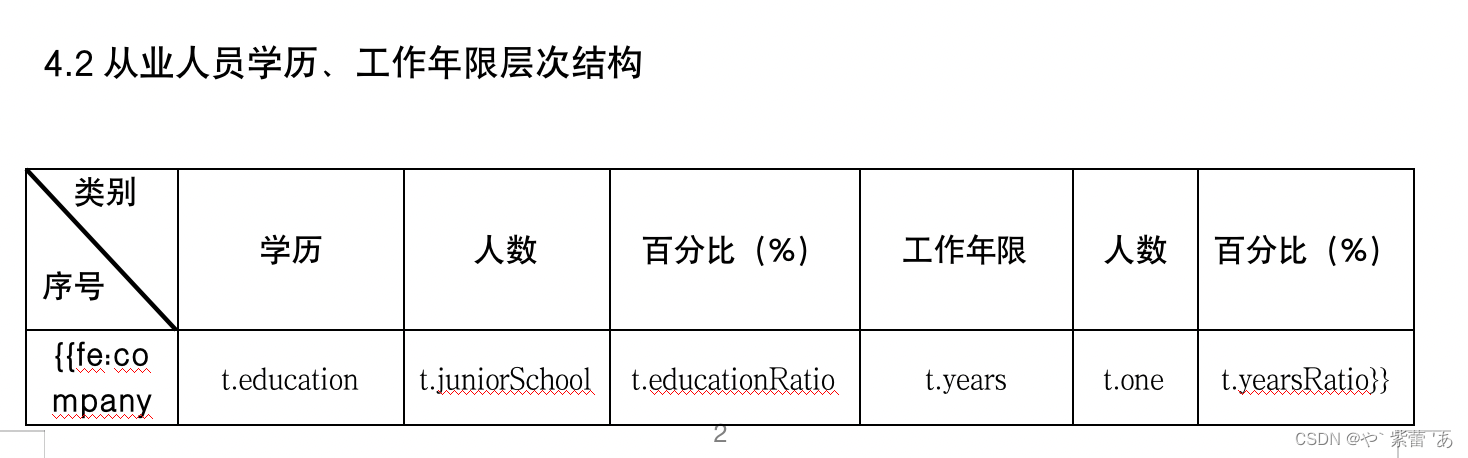
列表:带图片 单个图片 日期格式

@ApiOperation(value = "导出pdf报告")
@GetMapping("/exportPdf/{id}")
public void exportPdf(HttpServletResponse response, @PathVariable Integer id) {
mLegalCompanyService.exportPdf(response, id);
}
//两个模板 写模板docx 转换模板docx
@Value("${upload.dir}")
String ulr;//word模板路径
@Value("${imgUrl.url}")
String path;//图片路径
/**
* 根据 企业id生成 word
* word 转换PDF
*
* @param response
* @param id
*/
@Override
public void exportPdf(HttpServletResponse response, Integer id) {
//本地调试路径
//if (!System.getProperty("os.name").toLowerCase().contains("win")) {
// ulr = "/Users/xxx/Desktop/files/项目/转换dpf/";
//}
long old = System.currentTimeMillis();
LegalCompany legalCompany = this.getById(id);
if (ObjectUtils.isEmpty(legalCompany)) {
return;
}
HashMap<String, Object> map = new HashMap<>();
//头部标题
map.put("title", legalCompany.getCompanyName());
//报告时间
map.put("date1", "第一次检查");
// 评估依据
addBasis(map, legalCompany);
// 现场检查发现的问题
addRectifyList(map, legalCompany);
//日期
map.put("date", new Date());
//签名图片
if (StringUtils.isNotEmpty(legalCompany.getSignaturePicture())) {
ImageEntity image = new ImageEntity();
image.setHeight(842);
image.setWidth(595);
//这里我的路径需要拼接,只要图片路径能访问就可以。
image.setUrl(path + legalCompany.getSignaturePicture());
image.setType(ImageEntity.URL);
map.put("SignaturePicture", image);
}
try {
XWPFDocument doc = WordExportUtil.exportWord07(ulr + "/写模板.docx", map);
FileOutputStream fos = new FileOutputStream(ulr + "/转换模板.docx");
doc.write(fos);
fos.close();
// 开始转换pdf
InputStream inputStream = new FileInputStream(ulr + "/转换模板.docx");
OutputStream outputStream = response.getOutputStream();
response.setCharacterEncoding("utf-8");
response.setHeader("content-type", "application/octet-stream");
String fileName = URLEncoder.encode(legalCompany.getCompanyName() + "-" + TimeUtils.formatDate(inspectData, TimeUtils.DATE_FORMAT_DATEONLY) + "-" + "检查报告" + ".pdf", "UTF-8");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName);
response.setHeader("Access-Control-Expose-Headers", "Content-Disposition");
// 验证License 若不验证则转化出的pdf文档会有水印产生
if (!AsposeWordsUtils.getLicense()) {
return;
}
//要转换的word文件
Document doct = new Document(inputStream);
doct.save(outputStream, SaveFormat.PDF);
long now = System.currentTimeMillis();
//转化用时
log.info("共耗时:" + ((now - old) / 1000.0) + "秒");
outputStream.flush();
outputStream.close();
} catch (IOException e) {
log.info("IOException==>异常:{}==>{}", e);
} catch (Exception e) {
log.info("Exception==>异常:{}==>{}", e);
}
}
/**
* 评估依据
*
* @param map
* @param legalCompany
*/
private void addBasis(HashMap<String, Object> map, LegalCompany legalCompany) {
List<String> list = Lists.newArrayList();
//根据企业id查询检查完毕最后一条数据
LegalCheckTheRecord checkTheRecord = legalCheckTheRecordService.getByCompanyId(legalCompany.getCompanyId());
List<BasisInfo> basisInfoList = basisInfoService.findListByBasisId(checkTheRecord.getBasisId());
if (CollectionUtils.isNotEmpty(basisInfoList)) {
for (int i = 0; i < basisInfoList.size(); i++) {
list.add(basisInfoList.get(i).getBasisInfoName());
}
map.put("basis", list);
}
}
/**
* 设置 “现场检查发现的问题及整改情况”
*
* @param map
* @param legalCompany
*/
private void addRectifyList(HashMap<String, Object> map, LegalCompany legalCompany) {
List<HashMap<String, Object>> list = new ArrayList<>();
// 数据
List<LegalInspect> legalInspects = legalInspectService.selectList(legalCompany.getCompanyId);
if (CollectionUtils.isNotEmpty(legalInspects)) {
// 数据 for 循环
for (int i = 1; i <= legalInspects.size(); i++) {
LegalInspect legalInspect = legalInspects.get(i - 1);
HashMap<String, Object> mapData = new HashMap<>();
mapData.put("id", isNull(i));
mapData.put("problem", legalInspect.getProblem());
mapData.put("levelId", legalInspect.getLevelId().equals(1) ? "一般隐患" : "重大隐患");
//检查图片
if (StringUtils.isNotEmpty(legalInspect.getLivePhotos())) {
//这里我的路径需要拼接,只要图片路径能访问就可以。
ImageEntity image = new ImageEntity(path + legalInspect.getLivePhotos(), 100, 100);
mapData.put("livePhotos", image);
}
mapData.put("isRectify", legalInspect.getIsRectify().equals(1) ? "未整改" : "已整改");
//整改图片
if (StringUtils.isNotEmpty(legalInspect.getFinalPhotos())) {
ImageEntity image = new ImageEntity(path + legalInspect.getFinalPhotos(), 100, 100);
mapData.put("finalPhotos", image);
}
mapData.put("measure", legalInspect.getMeasure());
mapData.put("safetyPrincipal", legalCompany.getSafetyPrincipal());
if (null != periodMap && periodMap.containsKey(legalInspect.getDeadlineId())) {
mapData.put("deadlineNum", periodMap.get(legalInspect.getDeadlineId()).getDeadlineNum() + "天");
}
//检查次数
Long between = DateUtiles.between(legalInspect.getSubmitTime().getTime(), System.currentTimeMillis());
int num = 1;
if (between > legalCompany.getCycleDate()) {
num += between / legalCompany.getCycleDate();
}
mapData.put("num", "第" + num + "次检查");
list.add(mapData);
}
}
map.put("inspect", list);
}
// AsposeWordsUtils类
public class AsposeWordsUtils {
/**
* 判断是否有授权文件 如果没有则会认为是试用版,转换的文件会有水印
*/
public static boolean getLicense() {
boolean result = false;
try {
InputStream is = AsposeWordsUtils.class.getClassLoader().getResourceAsStream("license.xml");
License aposeLic = new License();
aposeLic.setLicense(is);
result = true;
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
}
pdf下载后:


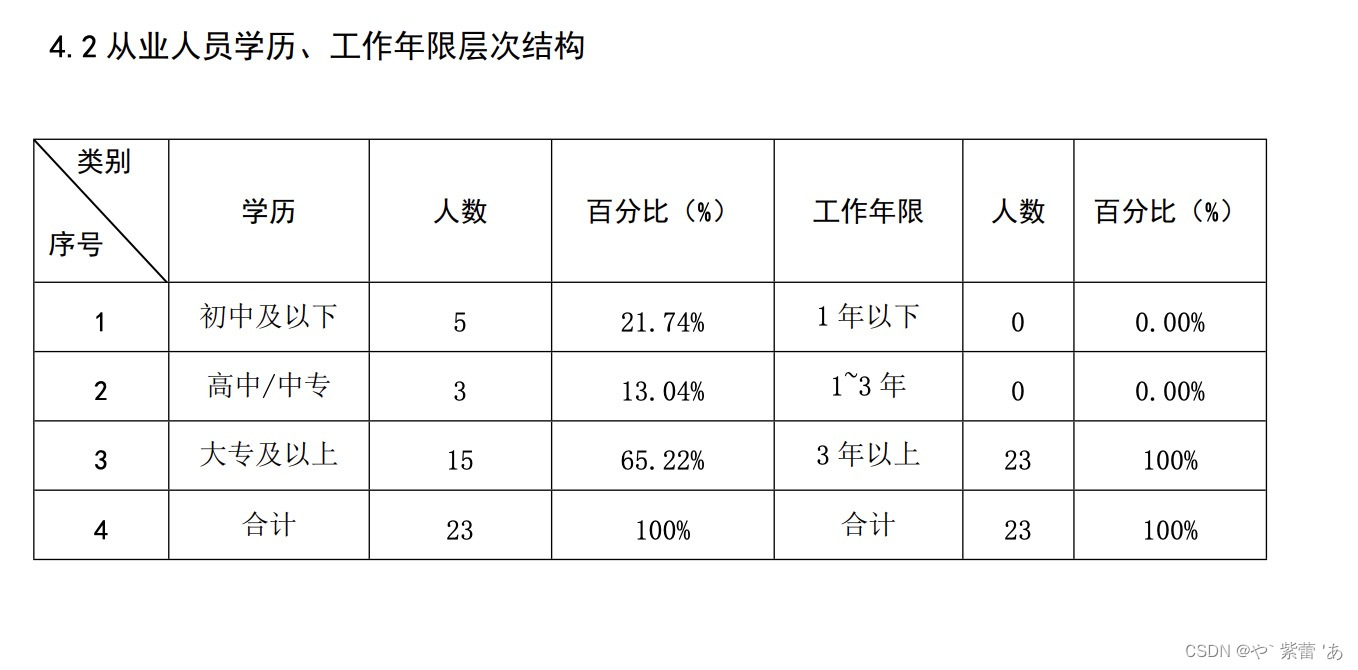
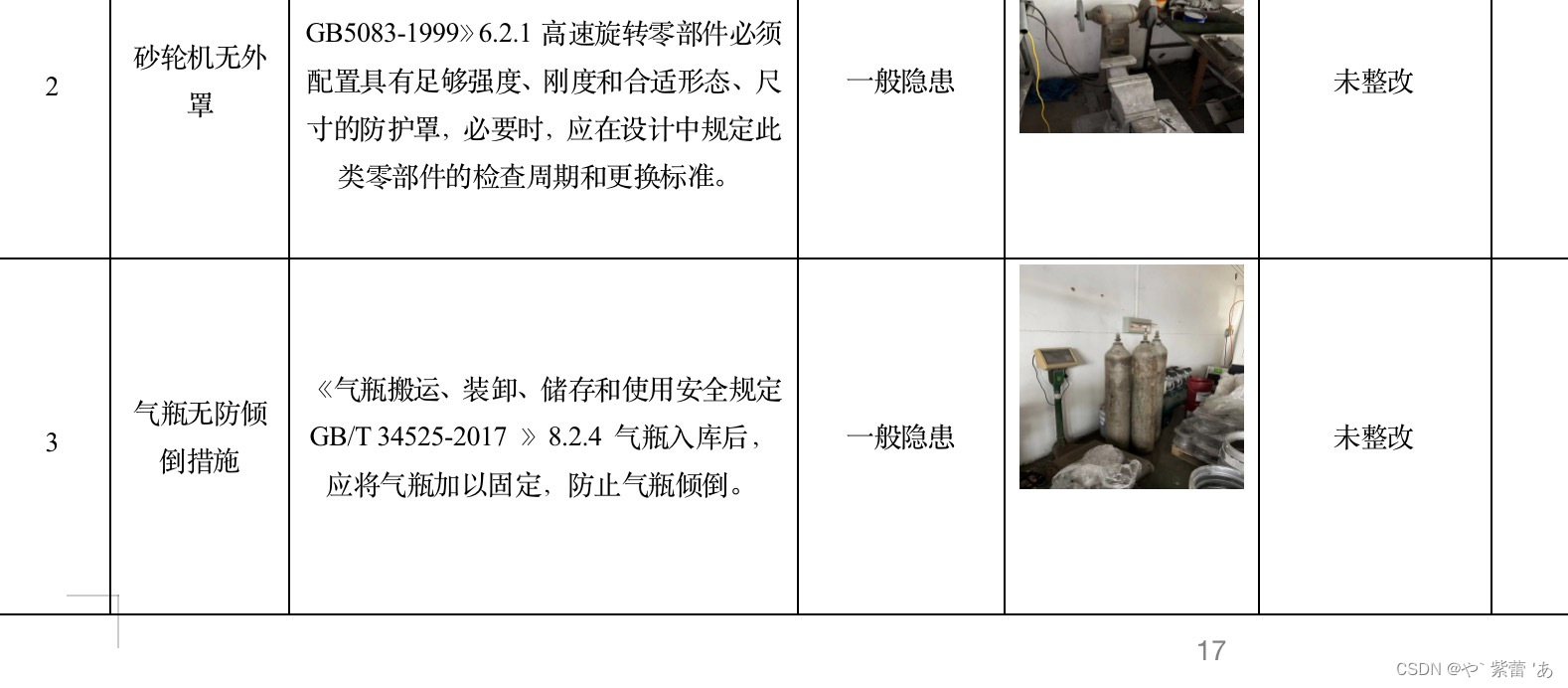

这个报告文件页码很长,我只截取了一小部分,代码很多,但是只截取了一些,可能没办法提供全,有些涉及企业机密,要是有哪不懂,可以评论留言,如果有需要可以提供其他的给你们参考。
这个是不限页面的,单图片 列表图片都可以下载下来。














 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









