






在深度学习中,特别是在 Transformer 模型中,由于模型结构本身不具备顺序信息(不像 RNN 是按时间顺序处理的),所以需要 位置编码(Positional Encoding) 来告诉模型输入序列中各个元素的先后顺序。
位置编码分为两种主流方式:绝对位置编码(Absolute Positional Encoding) 和 相对位置编码(Relative Positional Encoding)。
一、为什么需要位置编码?
Transformer 中的核心是 自注意力机制(Self-Attention),它一次性接收整个序列,并对所有位置同时计算注意力。
但是这样会带来一个问题:位置顺序的信息丢失了。比如,“我爱你” 和 “你爱我” 会得到一样的表示,这显然不行。
为了补偿这个缺失,我们给每个位置加入一个“位置信息”——这就是 位置编码,现有的位置编码包括绝对位置编码和相对位置编码。
二、绝对位置编码(Absolute Positional Encoding)
1. 概念
绝对位置编码是指:为输入序列中每一个位置生成一个唯一的向量,然后将这个向量加到原始词向量上,让模型知道“这个词在第几位”。
2. 常用实现:正弦和余弦函数(Sinusoidal)
这是 Transformer 原始论文《Attention is All You Need》中提出的方法。其核心思想是:
使用一组不同频率的正弦和余弦函数,编码每个位置的不同维度:
P E ( p o s , 2 i ) = sin ( p o s 10000 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d m o d e l ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) \\ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)PE(pos,2i+1)=cos(100002i/dmodelpos)
其中:
- p o s pos pos:当前词的位置(从 0 开始)
- i i i:当前维度的编号(从 0 到 d_model-1)
- d m o d e l d_{model} dmodel:词向量的维度(比如 512)
3. 直观解释
每个位置都会生成一个长度为 d_model 的向量。
不同位置的向量彼此不同,且相近位置的编码向量也“相似”。
这样模型可以“感知”到词语在句子中的顺序。
4. 特点
- 优点:不依赖训练,可以泛化到比训练长度更长的句子。
- 缺点:绝对位置编码实现简单,存在以下缺点:
- 尽管能包含一定的相对位置信息,但是这种信息仅仅保存在位置编码内部,在计算自注意力时,这种位置信息就被破坏了。
- 一个token的位置编码是什么由其在句子中的绝对位置决定,但是真正重要的往往不是绝对位置,而是它与其他token之间的关系。
- 对输入的长度敏感,一旦输入变化则需要重新调整。
三、相对位置编码(Relative Positional Encoding)
1. 概念
- 对于绝对位置编码有如下的问题:
- 泛化性差:它为每个固定位置分配一个独立向量,模型可能在训练时过拟合到这些特定的“位置模板”,导致对未见长度的序列泛化能力差。
- 表示僵化:不能很好地表示“相对位置信息”,也就是“这个词距离我几个词远”。
而对于相对位置编码不再关注“每个词的位置是多少”,而是关注:“当前词与其他词之间的相对距离”。
也就是说,模型关心的是:词 A 距离词 B 是 +2 还是 -1,而不是它们在句子中的绝对位置。
2. 举个例子
假设我们有句子:“我 爱 自然语言 处理”。
- 在绝对编码中,“自然” 是位置 2,“语言” 是位置 3。
- 在相对编码中,模型会更关注:“‘自然’ 与 ‘语言’ 相邻”,相对位置是 -1。
3. 方法
(1)ALiBi:Attention with Linear Biases
✅ 核心思想:
直接在注意力打分中加入与相对距离相关的线性惩罚项,而不是显式地构造位置向量参与注意力计算。
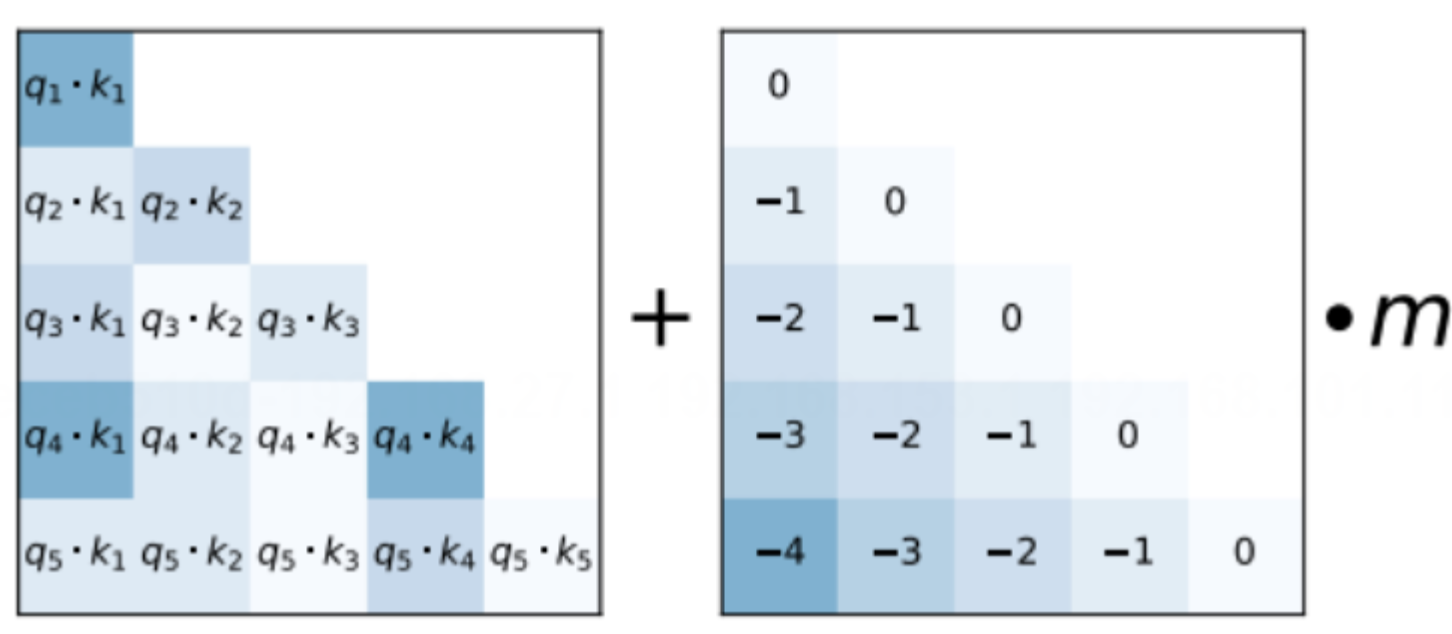
✅ 公式结构:
假设 A i , j A_{i,j} Ai,j 是第 i i i 个位置对第 j j j 个位置的注意力打分:
A i , j = Q i K j T d + b ∣ i − j ∣ A_{i,j} = \frac{Q_i K_j^T}{\sqrt{d}} + b_{|i - j|} Ai,j=dQiKjT+b∣i−j∣
其中, b ∣ i − j ∣ = − m ⋅ ∣ i − j ∣ b_{|i-j|} = -m \cdot |i-j| b∣i−j∣=−m⋅∣i−j∣,表示一个线性惩罚项(常为负值),鼓励模型关注更近的词语。
✅ 优点解析:
| 特点 | 描述 |
|---|---|
| 长度外推能力强 | 无需学习每个位置向量,线性偏置函数天然支持任意长度输入。 |
| 参数效率高 | 不引入额外的参数矩阵,仅通过数学偏置即可达到效果。 |
| 更稳健的关注机制 | 近处信息被优先关注,但不会彻底忽略远处信息。 |
(2)XLENT:三角相对位置编码(三角距离 + 向量分解)
XLENT 是一种引入了 更加细致的相对位置编码方法,强化了 Transformer 在理解“相对位置”上的能力。
✅ 核心思路:
- 从绝对位置编码出发(原始 Transformer 是使用 Q = X W Q + p i Q = X W_Q + p_i Q=XWQ+pi, K = X W K + p j K = X W_K + p_j K=XWK+pj)。
- XLENT 把 p j p_j pj 替换成 相对位置向量 R i − j R_{i-j} Ri−j。
- 同时将原始的 Q i Q_i Qi 拆成两个可学习向量 u 和 v,以分离位置/内容依赖。
✅ 注意力打分修改:
A i , j = Q i T K j + u T R i − j + v T R i − j A_{i,j} = Q_i^T K_j + u^T R_{i-j} + v^T R_{i-j} Ai,j=QiTKj+uTRi−j+vTRi−j
这中间, R i − j R_{i-j} Ri−j 是可训练的相对位置嵌入, u , v u, v u,v 为全局向量。
✅ 优势:
- 支持对称注意力结构(i到j、j到i一体化)。
- 可解释性强,结构上可以看作是引入了“相对距离的解耦影响”。
(3)桶式编码(Relative Position Bucketing)
T5 在位置编码上也做出了重要创新:位置桶(Position Bucketing)+ 精简注意力项。
✅ 核心思想:
-
Transformer 中的打分通常包含四部分:
- 内容-内容(query-key)
- 内容-位置
- 位置-内容
- 位置-位置
T5 认为:后面三项(位置相关)信息冗余,可裁剪掉其中两项,仅保留“内容-内容”和“位置-位置”。
-
相对位置通过一个离散桶函数 b ( i − j ) ∈ [ 0 , 31 ] b(i - j) \in [0, 31] b(i−j)∈[0,31] 映射后,再为每个桶训练一个偏移向量 r b ( i − j ) r_{b(i-j)} rb(i−j)。
-
只保留:
A i , j = Q i T K j + r b ( i − j ) A_{i,j} = Q_i^T K_j + r_{b(i-j)} Ai,j=QiTKj+rb(i−j)
✅ 桶函数的好处:
- 小距离映射得更精细,大距离压缩更粗糙,符合语言中近处信息更重要的先验。
- 映射范围有限,参数开销极小(比如32个桶)。
(4)Disentangled Position Encoding
DeBERTa = Decoding-enhanced BERT with Disentangled Attention。
它的创新点是 彻底解耦“位置”和“内容”在注意力中的贡献,并精细控制每种依赖方式的作用。
✅ 注意力结构:
DeBERTa 的注意力打分分为三项:
A i , j = Q i T K j + Q i T P i − j + P i T K j A_{i,j} = Q_i^T K_j + Q_i^T P_{i-j} + P_i^T K_j Ai,j=QiTKj+QiTPi−j+PiTKj
即:
- 内容-内容
- 内容-相对位置
- 位置-内容
与 T5 相反,它去掉的是“位置-位置”那项。
✅ 技术细节:
- 引入一个裁剪函数 δ ( i , j ) ∈ [ − k , k ] \delta(i, j) \in [-k, k] δ(i,j)∈[−k,k],对相对距离限制。
- Softmax 校准系数使用 3 d \sqrt{3d} 3d,而不是标准 d \sqrt{d} d,以提升数值稳定性。
- 在结构上拆分为两部分:前 11 层只用相对位置(Encoder),后 2 层加入绝对位置(Decoder),兼顾相对建模与全局表示。
📊 总结对比表
| 方法 | 核心思想 | 依赖位置类型 | 参数引入 | 是否可外推 | 是否修改注意力公式 | 特点概括 |
|---|---|---|---|---|---|---|
| ALiBi | 注意力打分中加入线性距离偏置 | 相对位置 | ❌ | ✅ | ✅ | 极简高效,泛化好 |
| XLENT | 使用三角相对向量 + 可学习方向向量 | 相对位置 | ✅ | 部分支持 | ✅ | 精细建模,兼容复杂依赖 |
| T5 | 去除位置-输入/输入-位置项 + 桶映射 | 相对位置 | ✅ | ✅(有限桶) | ✅ | 工程友好,参数少 |
| DeBERTa | 解耦内容/位置,删“位置-位置”项 | 相对+绝对 | ✅ | ✅ | ✅ | 精细建模,分层使用位置类型 |
绝对位置编码和相对位置编码对比总结
| 特性 | 绝对位置编码 | 相对位置编码 |
|---|---|---|
| 关注点 | 当前词在序列中的具体位置 | 当前词与其他词之间的相对位置关系 |
| 表示方式 | 为每个位置生成固定向量 | 为每个相对距离生成向量 |
| 实现复杂度 | 较简单(如 Sin/Cos 函数) | 较复杂,需要修改注意力机制 |
| 泛化能力 | 可以外推到长序列 | 通常更灵活,更适合长文本或生成任务 |
| 模型示例 | 原始 Transformer | Transformer-XL、T5、DeBERTa 等 |
四、RoPE
RoPE(旋转位置编码,Rotary Position Embedding)**是近年来在 Transformer 架构中被广泛应用的位置编码方法(如 LLaMA、ChatGLM、GLM-130B 等都采用了 RoPE)。
1. 为什么是“旋转”?(通俗语言的理解)
RoPE 借用了复数空间的“旋转矩阵”思想:
我们可以把一个向量的二维子空间视作一个复平面,给定一个固定角度的旋转,我们可以通过乘一个旋转矩阵来旋转这个向量。
换句话说:
- token 表示向量中,相邻的两个维度(比如第 0 和第 1 维,第 2 和第 3 维)组成一个 2D 向量;(维度其实可以是任何两个维度)
- 然后根据该 token 所在的位置 m m m,以一个特定角度来“旋转”这些 2D 向量;
- 所有位置的旋转角度不同,于是位置信息就被编码进向量了。
- 当把词旋转了之后:两个词的“角度差”就能表示它们之间的“距离”;
2.RoPE 的数学原理
有了rope的大体的理解,接下来我们从数学基础讲起。
概念:旋转矩阵
二维旋转矩阵为:
R ( θ ) = [ cos θ − sin θ sin θ cos θ ] R(\theta) = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} R(θ)=[cosθsinθ−sinθcosθ]
如果我们有一个二维向量 x = [ x 1 , x 2 ] T x = [x_1, x_2]^T x=[x1,x2]T,则其旋转结果为:
x ′ = R ( θ ) ⋅ x x' = R(\theta) \cdot x x′=R(θ)⋅x
3.RoPE 的做法:
- 将向量按维度两两分组(维度数为偶数,如 2、4、6…);
-
设 query 或 key 向量为:
x = [ x 0 , x 1 , x 2 , x 3 , . . . , x d − 2 , x d − 1 ] x = [x_0, x_1, x_2, x_3, ..., x_{d-2}, x_{d-1}] x=[x0,x1,x2,x3,...,xd−2,xd−1]
将其视为:
[ ( x 0 , x 1 ) , ( x 2 , x 3 ) , . . . , ( x d − 2 , x d − 1 ) ] [(x_0, x_1), (x_2, x_3), ..., (x_{d-2}, x_{d-1})] [(x0,x1),(x2,x3),...,(xd−2,xd−1)]
- 对每组 2D 向量计算不同频率的旋转角度
-
对于整个向量来说,前面的频率大,后面的频率小,可以看 ω k = 10000 − 2 k / d \omega_k = 10000^{-2k/d} ωk=10000−2k/d, k k k越大,频率越小,这样可以表示不同频率的信息。
旋转角度 θ m \theta_m θm 又与位置 m m m 成正比,比如:
θ m = m ⋅ ω k 其中 ω k = 10000 − 2 k / d \theta_m = m \cdot \omega_k \quad\text{其中 }\omega_k = 10000^{-2k/d} θm=m⋅ωk其中 ωk=10000−2k/d
- 旋转
-
每一对 ( x 2 k , x 2 k + 1 ) (x_{2k}, x_{2k+1}) (x2k,x2k+1) 表示一个二维子空间,我们对每个子空间执行旋转:
[ x 2 k ′ x 2 k + 1 ′ ] = [ cos ( θ m k ) − sin ( θ m k ) sin ( θ m k ) cos ( θ m k ) ] ⋅ [ x 2 k x 2 k + 1 ] \begin{bmatrix} x_{2k}' \\ x_{2k+1}' \end{bmatrix} =\begin{bmatrix} \cos(\theta_m^k) & -\sin(\theta_m^k) \\ \sin(\theta_m^k) & \cos(\theta_m^k) \end{bmatrix} \cdot \begin{bmatrix} x_{2k} \\ x_{2k+1} \end{bmatrix} [x2k′x2k+1′]=[cos(θmk)sin(θmk)−sin(θmk)cos(θmk)]⋅[x2kx2k+1]
其中:
- θ m k = m ⋅ ω k \theta_m^k = m \cdot \omega_k θmk=m⋅ωk
- ω k = 1 / 10000 2 k / d \omega_k = 1 / 10000^{2k/d} ωk=1/100002k/d,和 Transformer 的 sinusoid 编码频率一样
4. RoPE矩阵流程
接下来我们用矩阵的流程重新过一遍,方便更深的了解rope在注意力机制中如何作用的:
- 输入矩阵(Query Q Q Q 和 Key K K K)
-
形状:
- Q ∈ R L × d Q \in \mathbb{R}^{L \times d} Q∈RL×d
- K ∈ R L × d K \in \mathbb{R}^{L \times d} K∈RL×d
-
作用:
每个 token 的查询(Query)与键(Key)向量,来自线性变换后的 embedding。
2. 旋转矩阵 R θ ( m ) R_\theta(m) Rθ(m)
-
形状:
- R θ ( m ) ∈ R d × d R_\theta(m) \in \mathbb{R}^{d \times d} Rθ(m)∈Rd×d
- 是由 d 2 \frac{d}{2} 2d 个 2 × 2 2 \times 2 2×2 旋转子矩阵组成的 块对角矩阵(block-diagonal)
-
形式(以 d = 4 d = 4 d=4 为例):
R θ ( m ) = [ cos ( m θ 1 ) − sin ( m θ 1 ) 0 0 sin ( m θ 1 ) cos ( m θ 1 ) 0 0 0 0 cos ( m θ 2 ) − sin ( m θ 2 ) 0 0 sin ( m θ 2 ) cos ( m θ 2 ) ] R_\theta(m) = \begin{bmatrix} \cos(m\theta_1) & -\sin(m\theta_1) & 0 & 0 \\ \sin(m\theta_1) & \cos(m\theta_1) & 0 & 0 \\ 0 & 0 & \cos(m\theta_2) & -\sin(m\theta_2) \\ 0 & 0 & \sin(m\theta_2) & \cos(m\theta_2) \end{bmatrix} Rθ(m)= cos(mθ1)sin(mθ1)00−sin(mθ1)cos(mθ1)0000cos(mθ2)sin(mθ2)00−sin(mθ2)cos(mθ2)
3. 旋转后的 Query 和 Key( Q rot Q^{\text{rot}} Qrot、 K rot K^{\text{rot}} Krot)
-
形状:
- Q rot ∈ R L × d Q^{\text{rot}} \in \mathbb{R}^{L \times d} Qrot∈RL×d
- K rot ∈ R L × d K^{\text{rot}} \in \mathbb{R}^{L \times d} Krot∈RL×d
-
计算方式(对每个位置 m m m、每两个维度):
[ Q m , 2 k Q m , 2 k + 1 ] rot = [ cos ( m θ k ) − sin ( m θ k ) sin ( m θ k ) cos ( m θ k ) ] [ Q m , 2 k Q m , 2 k + 1 ] \begin{bmatrix} Q_{m,2k} \\ Q_{m,2k+1} \end{bmatrix}^{\text{rot}} =\begin{bmatrix} \cos(m\theta_k) & -\sin(m\theta_k) \\ \sin(m\theta_k) & \cos(m\theta_k) \end{bmatrix} \begin{bmatrix} Q_{m,2k} \\ Q_{m,2k+1} \end{bmatrix} [Qm,2kQm,2k+1]rot=[cos(mθk)sin(mθk)−sin(mθk)cos(mθk)][Qm,2kQm,2k+1]
对 K K K 同理。
对于矩阵来说:
-
Q rot = Q R θ ( m ) Q^{\text{rot}} = QR_\theta(m) Qrot=QRθ(m)
-
K rot = K R θ ( n ) K^{\text{rot}} = KR_\theta(n) Krot=KRθ(n)
-
4. 输出处理之后的矩阵
-
形状:
- Q rot ( K rot ) T ∈ R L × L Q^{\text{rot}} (K^{\text{rot}})^T \in \mathbb{R}^{L \times L} Qrot(Krot)T∈RL×L
处理之后的矩阵 = Q rot ( K rot ) T = Q m R θ ( m ) R θ ( n ) T K n T = Q m R θ ( m − n ) K n T 处理之后的矩阵= Q^{\text{rot}} (K^{\text{rot}})^T \\ =Q_m R_\theta(m ) R_\theta(n)^TK_n^T\\ =Q_m R_\theta(m-n) K_n^T 处理之后的矩阵=Qrot(Krot)T=QmRθ(m)Rθ(n)TKnT=QmRθ(m−n)KnT
其中 R θ ( n − m ) R_\theta(n - m) Rθ(n−m) 为相对旋转矩阵,反映 token 间的相对位置信息, R θ ( n ) T = R θ ( − n ) R_\theta(n)^T=R_\theta(-n) Rθ(n)T=Rθ(−n)这一步是旋转矩阵的性质,可以通过公式推导证明的。
🎯 RoPE 的优势
| 优点 | 解释 |
|---|---|
| ✅ 统一相对和绝对位置编码 | 使用绝对位置进行旋转,但计算出的 attention 具有相对位置特性 |
| ✅ 支持任意长度 | 理论上位置编码不限长度,训练长度外的 extrapolation 能力强 |
| ✅ 结构简单,计算高效 | 本质是按位旋转,支持并行矩阵操作 |
| ✅ 衰减性 | 与位置差异越大,attention score 的影响越弱,有天然衰减性 |
🧪 应用:RoPE 在大模型中的广泛使用
RoPE 是目前 最受欢迎的位置编码之一,被多个主流模型采用,例如:
| 模型 | 使用情况 |
|---|---|
| LLaMA / LLaMA2 / LLaMA3 | 主力位置编码方式 |
| GLM / ChatGLM | 自研系列也采用 RoPE |
| Baichuan / InternLM | 中文大模型普遍使用 |
| Phi / Qwen | 都采用 RoPE 作为位置编码 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









