






什么是Decoding(解码)?
Decoding 是指:模型在每个时间步输出一个词的概率分布后,选择最终要生成的词的过程,在下面图中是用紫色框框标注出来的这一部分后续的处理。
通俗来说,就是模型“想了很多个可能的词”,然后我们用某种策略帮它选出一个。每个词的选择都依赖于前面生成的词,因此如果前面选错了,后面可能就会“越说越偏”。解码方法就是在准确性和多样性之间寻找平衡。

本文将详细介绍几种常见的解码策略,包括:
- Greedy Search(贪婪搜索)
- Beam Search(集束搜索)
- Top-k 抽样
- Top-p 抽样(又称 nucleus sampling,核采样)
- Temperature(温度调节)
- 联合采样(top-k + top-p + temperature)
1. Greedy Search(贪婪搜索)
思路:
每一步都选择概率最大的词作为当前时间步的输出。
优点:
- 简单、速度快
- 不需要额外的计算资源
缺点:
- 一旦出错,难以修正,错误会传递下去
- 文本单调,容易重复、不自然
- 容易陷入局部最优,不一定是最好的整体句子
2. Beam Search(集束搜索)
思路
不是只保留一个最可能的路径,而是保留前num_beams条最有希望的路径,最后从中选择得分最高的那一条。
步骤:
- 对于 beam 中的每条序列:使用模型计算其下一个 token 的概率分布(V个可能)
- 为每个 token 扩展出一个新序列 这样总共有 n u m _ b e a m s × V num\_beams × V num_beams×V个候选序列
- 对这 n u m _ b e a m s × V num\_beams × V num_beams×V 个序列: 根据累计 log 概率进行排序 选出前 k 个最优序列,组成新的 beam
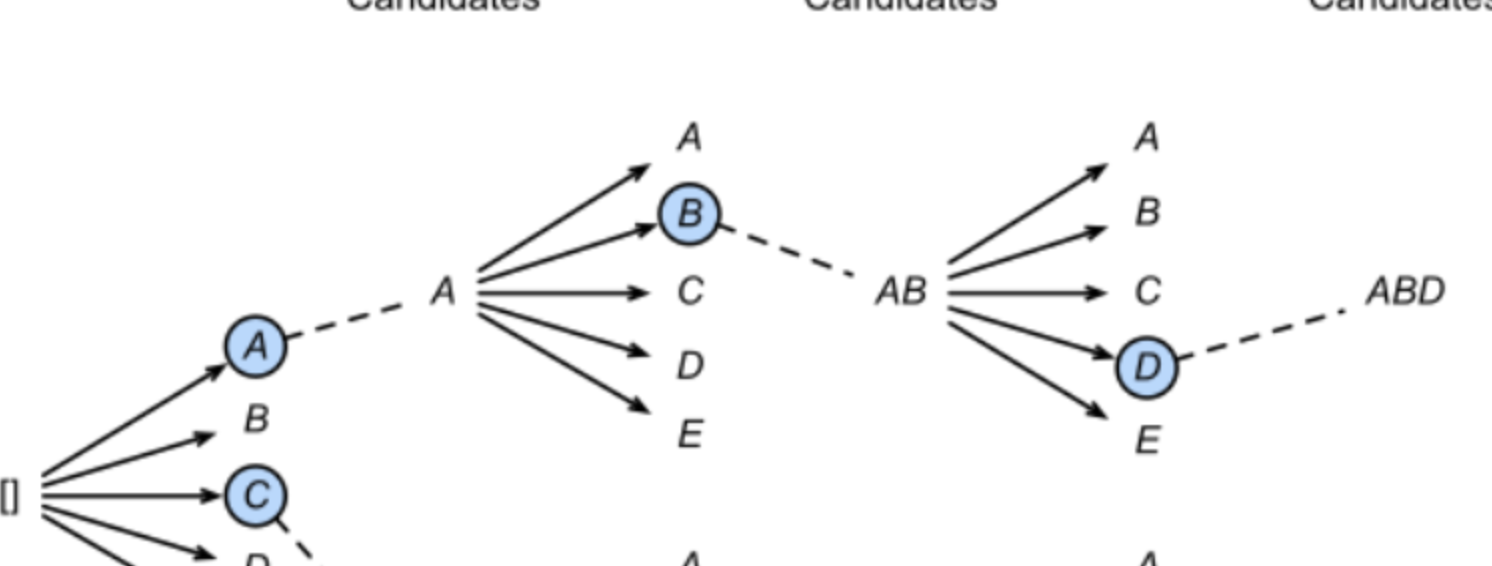
优点:
- 比 greedy 更容易找到全局更优的解
- 可调节 num_beams 来控制精度与效率
缺点:
- 可能仍然错过真正的最优解(搜索空间有限)
- 计算复杂度更高
- 生成的句子可能仍较死板,缺少多样性
3. Top-k 抽样(Top-k Sampling)
思路
不再总是选择概率最大的词,而是从概率前 k 个词中随机抽取一个。
比如:
若当前词的预测概率分布是:
{apple: 0.5, banana: 0.3, cat: 0.1, dog: 0.05, egg: 0.05}
设 k=3,那么只从 apple, banana, cat 中随机选一个。
优点:
- 加入随机性 → 提升多样性
- 防止模型重复输出固定句式
缺点:
- k不好调:太小会像 greedy,太大可能选到奇怪词
- 在分布陡峭时,仍可能选中低概率词,导致不合理输出
4. Top-p 抽样(Nucleus Sampling)
思路
从概率分布中动态选择一个最小集合,其累计概率 ≥ p,再从其中随机选一个词。
比如:
如果模型输出如下概率分布:
{apple: 0.5, banana: 0.2, cat: 0.1, dog: 0.08, egg: 0.05, fan: 0.03, grape: 0.02, ...}
设 p = 0.9,则前4个词的累计概率是 0.5+0.2+0.1+0.08 = 0.88,还不够,需再加一个 egg,累计0.93,凑够后从这5个词中抽样。
优点:
- 相比 Top-k 更灵活:根据概率分布自动确定候选词数
- 能适应不同的分布陡峭程度,适配性更强
缺点:
-
p的选择影响大:
- 太小 → 模型输出太保守
- 太大 → 生成内容太随机
5. Temperature(温度参数)
思路
在采样前对 logits(未归一化的输出)进行缩放控制“创造性”:
- 温度低(如0.3) → 概率差异被放大 → 模型倾向于选择高概率词
- 温度高(如0.9) → 概率差异被缩小 → 更愿意尝试不常见的词
数学上:
P i = softmax ( logits i temperature ) P_i = \text{softmax} \left( \frac{\text{logits}_i}{\text{temperature}} \right) Pi=softmax(temperaturelogitsi)
logits_i:模型对词表中第 i 个词的原始得分(未归一化的实数)。temperature:温度系数,是一个正数,通常 ∈ (0, ∞)。softmax():将调整后的 logits 转换为一个概率分布,所有概率加起来为 1。P_i:温度调整后,第 i 个词被采样的概率。
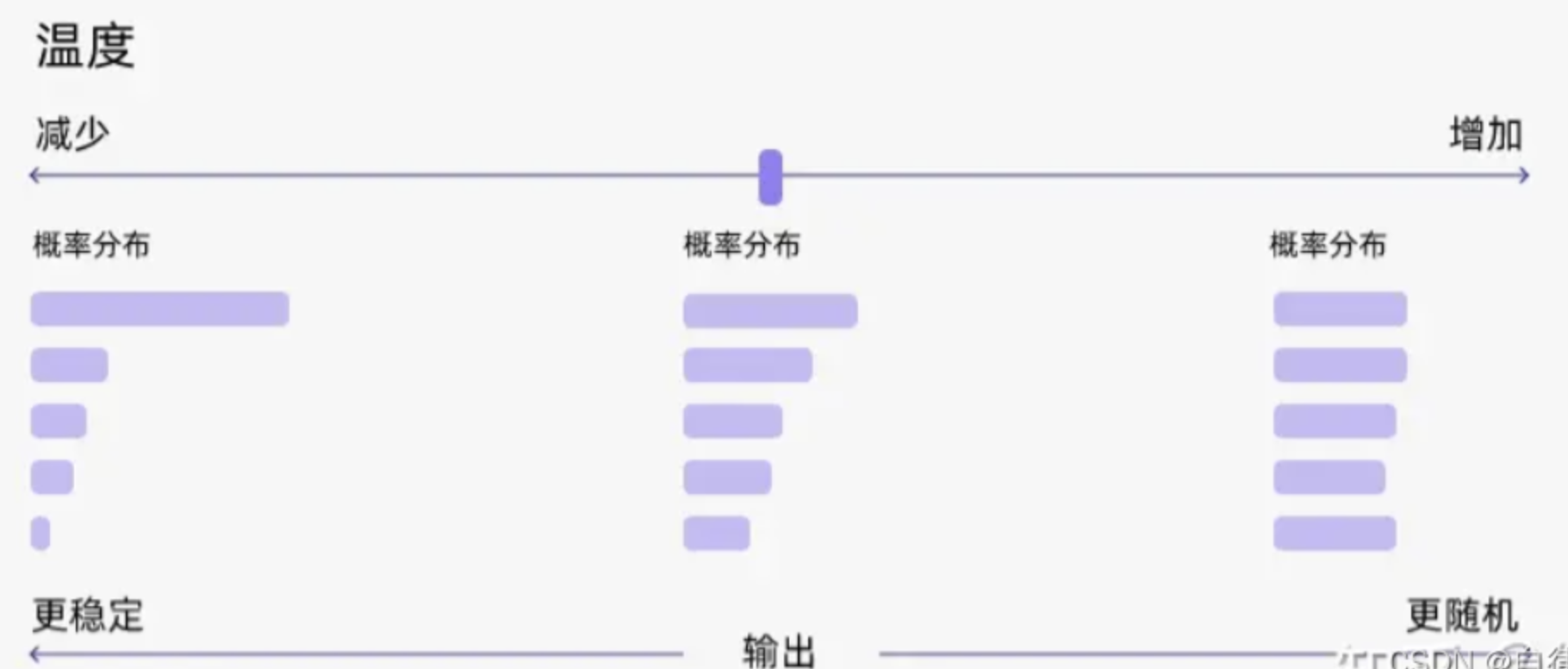
不同温度下的效果:
温度值 T | 效果 | 原因 |
|---|---|---|
| T = 1 | 原始 softmax,不做调整 | 模型原始输出 |
| T < 1 | 更“陡峭” → 概率更集中 → 更确定 | 放大 logits 差异,最大值更占优势 |
| T > 1 | 更“平缓” → 概率更分散 → 更随机 | 压缩 logits 差异,低概率词也有机会被选中 |
优点:
- 可控制模型“冒险程度”
- 配合其他方法提升生成文本的多样性
6. 联合采样:Top-k + Top-p + Temperature
思路
联合使用多个采样策略,按顺序:
Top-k → Top-p → Temperature
- 先从 top-k 里选出前 k 个候选词
- 在 top-k 的基础上,再筛出累计概率 ≥ p 的候选子集
- 再用温度调节其概率分布,进行最终采样
优点:
- 结合三者优点,增强多样性、控制稳定性
- 对复杂生成任务更适用(如对话系统、文本续写)
缺点:
- 参数多,调参成本高
- 不当配置可能使模型输出不连贯或太随机

















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









