







作者 | gongyouliu
编辑 | gongyouliu
我们在第5章「推荐系统业务流程与架构」中讲到推荐系统一般会分为召回和排序两个阶段,召回可以看成是推荐前的初筛过程,排序是对初筛的结果进行精细打分的过程。我们在前面4章中介绍完了推荐系统召回算法相关的知识点,从本章开始,我们会花4章的篇幅来介绍排序算法。
本章是关于排序的第一章,在这一章我们会对排序算法的基本概念、常用的排序算法、排序算法的应用场景和使用排序算法的一些说明等4个方面来展开讲解,希望本章的知识点可以给大家做一个铺垫,方便大家可以更好地理解后面3章介绍的排序算法的细节知识。我们先来介绍一下排序算法的基本概念。
10.1 什么是排序算法
所谓推荐系统排序算法是采用某种机器学习算法来对召回阶段的结果(推荐系统一般会使用多种召回算法)进行二次打分排序,获得对召回结果的统一评价。这里的评价是指某种业务指标,比如评分、点击率、播放时长等,不同的产品,不同的业务形态关注的业务指标都是不一样的。业务指标一般是排序算法的目标函数。下面图1对排序算法的逻辑进行了简单说明,相信读者看完这个图可以更好地理解召回算法与排序算法的关系。
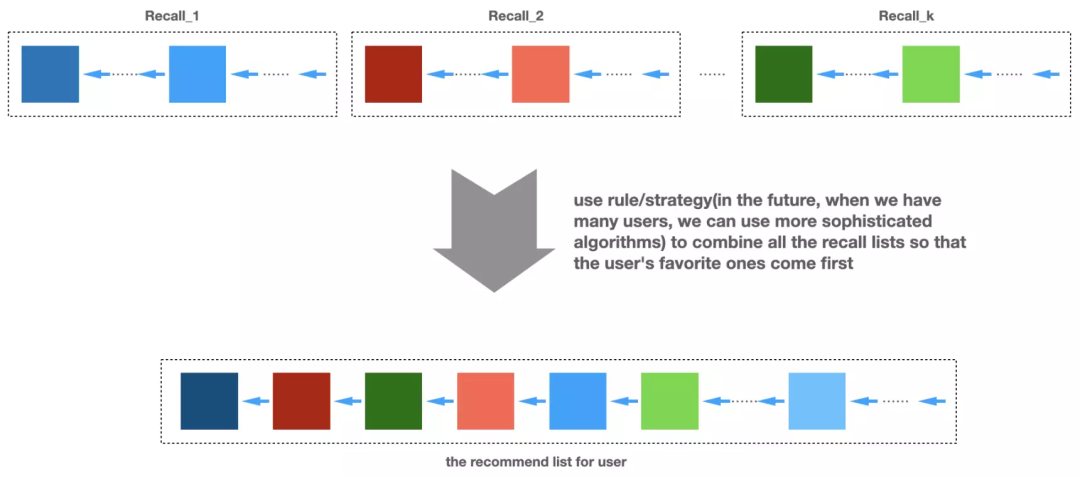
图1:排序算法的逻辑说明
由于召回的结果一般不会很多(几十个到几百个),排序算法需要打分的物品是比较少的,所以在数据量比较大,特征比较丰富的情况下,排序算法一般可以用稍微复杂一些的算法来训练模型获得更好的排序结果,并且也能保证做完排序的时间控制在合理的范围,不影响用户体验。
任何机器学习模型都需要基于一定的特征来训练,排序模型也不例外。特征的丰富程度及有效性决定了模型的质量,所以一般排序算法可以使用各种类型的特征,包括用户相关的特征(比如年龄、性别、收入、用户id等)、行为相关的特征(点击、浏览、播放、购买、收藏、点赞、评论等)、物品相关的特征(标题、标签、价格、尺寸、产地等)、场景相关的特征(时间、地域、位置、天气、心情等)、交叉特征(前面几类特征之间的交叉或者同一类特征之间的交叉)等5大类特征。
排序算法需要充分利用上述介绍的5大类特征,以便更好地预测用户的行为,获得更好的商业价值。排序学习是机器学习中一个重要的研究领域,广泛应用于信息检索、搜索引擎、推荐系统、计算广告等的排序任务中,有兴趣的读者可以参考微软亚洲研究院刘铁岩博士的专著(见参考文献1)。排序算法根据预测对象的组织形式可以分为pointwise、pairwise、listwise三类,见下面图2。
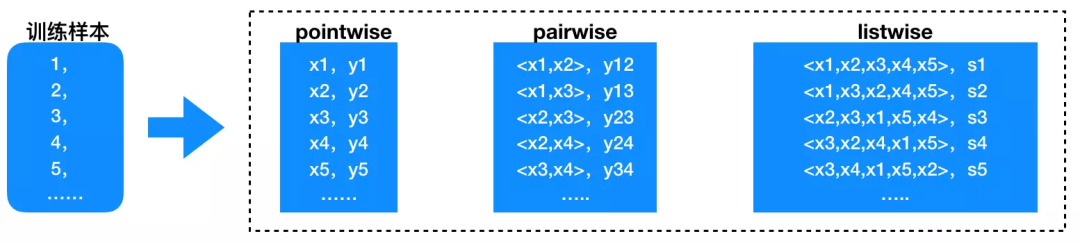
图2:三类排序学习算法框架
上图中x1,x2,... 代表的是训练样本1,2,... 的特征,y1,y12,s1,... 等是训练集的label(目标函数值)。pointwise学习单个样本,如果最终预测目标是一个实数值,就是回归问题,如果目标是概率预测,就是一个分类问题,例如CTR预估。pairwise和listwise分别学习一对有序对和一个有序序列的样本特征,考虑得更加精细。
在推荐系统中常用pointwise方法来做排序,它更直观,易于理解,也更简单。本系列文章中没有特别说明,我们的排序
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











