









- 文献题目:LEARNING AUDIO-VISUAL SPEECH REPRESENTATION BY MASKED MULTIMODAL CLUSTER PREDICTION
- 发表时间:2022
- 发表期刊:ICLR
摘要
- 语音的视频记录包含相关的音频和视觉信息,为从说话者的嘴唇运动和产生的声音中学习语音表示提供了强大的信号。我们介绍了视听隐藏单元 BERT (AV-HuBERT),这是一种用于视听语音的自我监督表示学习框架,它掩盖了多流视频输入并预测自动发现和迭代细化的多模态隐藏单元。 AV-HuBERT 学习强大的视听语音表示,有利于唇读和自动语音识别。在最大的公共唇读基准 LRS3(433 小时)上,AV-HuBERT 仅用 30 小时的标记数据就达到了 32.5% 的 WER,超过了之前经过一千倍以上训练的最先进方法(33.6%)转录视频数据(31K 小时)(Makino 等人,2019 年)。当使用来自 LRS3 的所有 433 小时标记数据并结合自我训练时,唇读 WER 进一步降低到 26.9%。在相同的纯音频语音识别基准上使用我们的视听表示,与最先进的性能相比,WER 相对降低了 40%(1.3% 对 2.3%)。我们的代码和模型可在 https://github.com/facebookresearch/av_hubert获得。
- 人类对语音的感知本质上是多模态的,涉及听觉和视觉。 语音产生伴随着嘴唇和牙齿的运动,可以通过视觉解释来理解语音。 语音的视觉提示不仅在语前儿童的语言学习中发挥着重要作用(Meltzoff & Moore, 1977; Davies et al., 2008),而且还提高了嘈杂环境中的语音理解能力(Sumby & Pollack, 1954)并为语言障碍患者提供交流手段。 此外,感知研究 (McGurk & MacDonald, 1976) 表明,这种视觉线索可以改变感知到的声音。
- 对于机器学习模型,音频和视觉嘴唇运动信息之间的紧密耦合成为监督学习语音表示的自然来源,这在自监督语音表示学习文献中尚未广泛使用。最近成功的语音表征学习框架(例如,APC(Chung 等人,2019)、CPC(Oord 等人,2018;Kharitonov 等人,2021)、wav2vec 2.0(Baevski 等人,2020;Hsu 等人) ., 2021b)、DeCoAR2.0 (Ling & Liu, 2020)、HuBERT (Hsu et al., 2021c;a)) 大多完全建立在音频之上。本文解决的基本研究问题是,从嘴唇运动信息中学习到的自监督视听语音表示,以及视频记录中的音频信号,是否能够捕获跨模态相关性并提高视觉语音识别的下游性能(即,唇读)和自动语音识别(ASR)任务。现有的唇读 ML 模型严重依赖文本转录来达到可接受的准确度水平。最先进的唇读模型(Makino 等人,2019 年)需要 31K 小时的转录视频数据进行训练。对于世界上 7,000 种语言中的大多数语言来说,如此大量的标记数据是昂贵且难以获得的。强大的视觉语音表示学习框架的好处不仅仅是唇读。此外,它可以使广泛的应用受益,包括但不限于手语中的关键字定位(Albanie 等人,2020)、语音增强(Xu 等人,2020)和说话人脸生成(Chen 等人, 2018)。
- 在本文中,我们提出了视听隐藏单元 BERT (AV-HuBERT),一种多模态自监督语音表示学习框架。 它通过混合 ResNet-transformer 架构将屏蔽的音频和图像序列编码为视听特征,以预测离散集群分配的预定序列。 目标聚类分配最初是从基于信号处理的声学特征(例如 MFCC)生成的,并使用视听编码器通过 k-means 聚类学习的特征进行迭代细化。 AV-HuBERT 同时从唇部运动和音频流中捕获未掩蔽区域的语言和语音信息到其潜在表示中,然后对它们的长期时间关系进行编码以解决掩蔽预测任务。
- AV-HuBERT 学习的语境化表示对唇读任务表现出极好的可迁移性,其中只有视觉模态可用。对音频和视觉输入流的预训练比仅视觉输入产生了明显更好的结果。在仅使用来自 LRS3 的 30 小时标记数据的低资源设置中(Afouras 等人,2018b),我们的模型实现了 32.5% 的唇读 WER,优于之前最先进的模型(33.6% ) 训练了 31,000 小时的转录视频(Makino 等人,2019 年)。使用 LRS3 的完整 433 小时进一步将 WER 降低到 28.6%。我们进一步表明 AV-HuBERT 和自我训练是相辅相成的:两者结合创造了 26.9% 的新唇读 WER 记录。此外,我们表明从 AV-HuBERT 派生的多模态集群可用于预训练基于音频的语音识别的 HuBERT 模型,优于之前的最先进模型 (2.3%) 和单模态 HuBERT在音频集群上进行预训练(1.5%),幅度很大(1.3%)。
方法
预赛:Audio HuBERT
- 我们的研究建立在 Audio HuBERT (Hsu et al., 2021a) 的基础上,它是一个用于语音和音频的自我监督学习框架。它在两个步骤之间交替:特征聚类和掩码预测。在第一步中,将离散潜变量模型(例如,k-means)应用于一系列声学帧 A 1 : T A_{1:T} A1:T,从而产生一系列帧级分配 z 1 : T a z^a_{ 1:T} z1:Ta。基于信号处理的声学特征集群,例如梅尔频率倒谱系数 (MFCC),与语音输入的固有声学单元表现出非平凡的相关性。使用 ( A 1 : T , z 1 : T a ) (A_{1:T} , z^a_{ 1:T} ) (A1:T,z1:Ta) 对,第二步通过最小化掩码预测损失来学习新的特征表示,类似于 BERT 中的掩码语言建模 (Devlin et al., 2019)。预测掩蔽音频区域的集群分配的压力迫使模型学习未掩蔽区域的良好局部声学表示和潜在特征之间的长期时间依赖性。重复这两个步骤可以提高集群质量,从而提高学习表示的质量。
单模态和跨模态视觉HUBERT-
- 单模态视觉 HuBERT:将 HuBERT 扩展到视觉领域的最简单的方法是使用视觉特征生成目标。 形式上,给定一个图像序列 I 1 : T I_{1:T} I1:T,我们首先通过 k-means 将图像特征聚类成一系列离散单元 z 1 : T i z^i_{1:T} z1:Ti: z t i = k − m e a n s ( G ( I t ) ) ∈ { 1 , 2 , . . . , V } z^i_t = k-means(G(I_t)) ∈ \{1, 2, ..., V \} zti=k−means(G(It))∈{1,2,...,V},其中 G G G 是视觉特征提取器, V V V是码本大小。 聚类分配 z 1 : T i z^i_{1:T} z1:Ti 作为模型的预测目标。 最初, G G G 可以是工程图像特征提取器,例如方向梯度直方图 (HoG),类似于音频 HuBERT 中的 MFCC。 HuBERT 模型的中间层在后面的迭代中用作 G G G。
- 为了执行掩码预测任务,该模型首先使用 ResNet 将
I
1
:
T
I_{1:T}
I1:T 编码为中间视觉特征序列
f
1
:
T
v
f^v_{1:T}
f1:Tv,然后通过二元掩码
M
M
M 将其破坏为
f
~
1
:
T
v
\tilde{f}^v_{1:T}
f~1:Tv。具体而言,
∀
t
∈
M
∀t ∈ M
∀t∈M,
f
~
t
v
\tilde{f}^v_t
f~tv 被替换为学习的掩码嵌入。 我们在 HuBERT 中采用相同的策略来生成跨度掩码。 被掩蔽的视觉特征
f
1
:
T
v
f^v_{1:T}
f1:Tv 通过一个变换器编码器和一个线性投影层被编码成一系列上下文化特征
e
1
:
T
e_{1:T}
e1:T。 损失是在屏蔽区域和可选的未屏蔽区域上计算的(当
α
≥
0
α ≥ 0
α≥0 时):
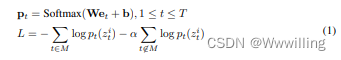
- 其中 ( W ∈ R d × V , b ∈ R V W ∈ R^{d×V}, b ∈ R^V W∈Rd×V,b∈RV) 是投影层的参数,它将特征映射到预测集群分配的 logit 中。
- 跨模态视觉 HuBERT:单模态视觉 HuBERT 旨在通过逐渐细化的图像特征来学习视觉语音表示。 但是,它不使用视频的音频流。 据推测,音频特征(例如 MFCC 或预训练的音频 HuBERT 模型)与手机的相关性比普通图像特征(例如 HoG)更好。 为此,我们基于对齐的音频帧序列 A 1 : T A_{1:T} A1:T 与视觉编码器并行训练音频编码器。 迭代训练在两个编码器之间交替进行。 在每次迭代中,使用音频编码器 E a E^a Ea 来生成目标集群分配 z 1 : T a z^a_{1:T} z1:Ta。 随后使用 ( I 1 : T , z 1 : T a I_{1:T} , z^a_{1:T} I1:T,z1:Ta) 训练视觉编码器 E v E^v Ev。 z 1 : T a z^a_{1:T} z1:Ta 还用于训练音频编码器 E a E^a Ea 的下一次迭代以进行细化。
- 跨模态视觉 HuBERT 可以看作是通过从音频流中提取知识来对视觉输入进行建模,其中 z 1 : T a z^a_{1:T} z1:Ta 代表音频方面的知识。 我们假设音频特征比视觉特征更有利于语音表示学习,这在 E.1 节中得到了验证。 对于唇读下游任务至关重要,HuBERT 使用的蒙面预测目标强制模型捕获时间关系,这有助于预测同音词,它们是具有相同视觉形状的声音组(例如,‘p’-‘b’, ‘f’-‘v’, ‘sh’-‘ch’) 使用单个图像帧无法区分。
AUDIO-VISUAL HUBERT
- 我们在这项工作中的主要模型是 Audio-Visual HuBERT (AV-HuBERT),如图 1 所示,它通过以类似于 Visual HuBERT 的方式在特征聚类和掩码预测之间交替进行迭代训练,但有四个主要改进:

- 图1:AV-HuBERT 的插图。 仅针对三个中间帧计算屏蔽预测损失,因为这些帧至少屏蔽了一种模态。 有关单模态和跨模态视觉 HuBERT 的比较,请参见 A 节。
- 视听输入:AV-HuBERT 模型同时使用声学和图像帧进行掩蔽预测训练,从而能够更好地建模和提炼两种模式之间的相关性。 具体来说,图像序列和声学特征通过它们的轻量级特定于模态的编码器产生中间特征,然后将其融合并馈送到共享的主干变压器编码器中,以预测掩蔽的集群分配。 目标是从聚类音频特征或从 AV-HuBERT 模型的先前迭代中提取的特征生成的。 当针对唇读进行微调时,我们放弃了音频输入以仅与视觉输入一起工作。 输入差异通过下面描述的模态丢失来解决。
- 模态丢失:视听语音识别模型可以比视觉输入流更轻松地将音频输入与词汇输出联系起来,正如文献中所观察到的(Afouras 等人,2018a;Ma 等人,2021b)。 这导致音频模态主导模型决策。 这个问题在我们的设置中更加严重,因为目标集群分配最初是从声学特征生成的。 为了防止模型过度依赖我们的联合模型中的音频流,我们只使用线性层对声学输入进行编码,以强制音频编码器学习简单的特征。
- 此外,在将音频和视频输入融合到主干变压器编码器之前,会应用 dropout 来掩盖一种模态的全部特征; 我们将其称为模态辍学。 在概率
p
m
pm
pm 下,两种模式都被用作输入。 当仅使用一种模态时,选择音频流的概率为
p
a
pa
pa。 形式上,给定编码的音频和视觉特征序列
f
1
:
T
a
f^a_{1:T}
f1:Ta 和
f
1
:
T
v
f^v_{1:T}
f1:Tv,等式 2 显示了配备模态丢失的特征融合:
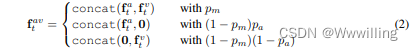
- 其中 concat 表示通道级连接。 请注意,模态丢弃是在序列级别而不是帧级别应用的,这有效地任务 AV-HuBERT 以仅视觉、仅音频或视听输入执行掩蔽预测。 模态丢失可防止模型忽略视频输入,并鼓励模型生成预测,而不管使用什么模态作为输入。 此外,由于微调和推理阶段仅使用视觉流(无音频输入),这种模态丢弃机制弥合了预训练(多模态)和微调/推理(单模态)之间的差距。 在之前的工作中使用了类似的 dropout 机制(Zhang 等人,2019a;Makino 等人,2019;Neverova 等人,2014;Abdelaziz 等人,2020),以提高多模态设置中的鲁棒性。 我们在 D 节中验证了模态丢失的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









