







Redis Bloom、hll、漏斗限流
布隆过滤器
Redis Bloom使用
git clone https://github.com/RedisBloom/RedisBloom.git cd RedisBloom
make
cp redisbloom.so /path/to
vi redis.conf
# loadmodules /path/to/redisbloom.so
相关接口
# 为 key 所对应的布隆过滤器分配内存,参数是误差率以及预期元素,根据运算得出需要多少hash函数 以及所需位图大小
bf.reserve hotkey 0.0000001 10000
# 检测 key 所对应的布隆过滤器是否包含 field 字段
bf.exists key field
# 往 key 所对应的布隆过滤器中添加 field 字段
bf.add key field
测试
BF.RESERVE hotkey 0.0000001 10000
BF.ADD hotkey aaa
BF.ADD hotkey bbb
BF.ADD hotkey ccc
BF.EXISTS hotkey aaa
部署
-
部署在数据中心,如果只有一个数据中心,部署在数据中心,可以减少网络交互;
-
部署在redis中,如果有多个数据中心,避免维护多个布隆过滤器数据,可直接部署到redis当中;

hyperloglog
hyperloglog是一种对数计数方法,利用伯努利实验的原理用2^k去估算一个数出现N次。
在Redis实现中,每个键只使用 12kb 进行计数,使用 16384 ( 2^14) 个桶子(分桶是为了算调和平均数),标准误差为0.8125% ,并且对可以计数的项目数没有限制,除非接近 个项目数(这似乎不太可能)。
原理:
给定一系列的随机整数 N,记录低位连续零位的最大长度 K;随机整数数量 N 和 最大长度 K 的关系?

只记录最大长度!!可以用伯努利实验估算出
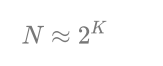
算法:
当一个元素到来时,它会散列到一个桶中,以一定的概率影响这个桶的计数值,因为是概率算法,单个桶的计数值并不准确,但是将所有的桶计数值进行调和均值累加起来,结果就会非常接近真实的计数值;(散列函数一定要符合均匀分布)
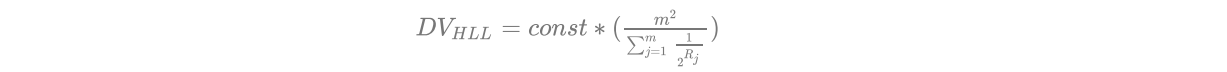
每个桶估计值
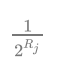
所有桶估计值的调和平均数
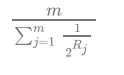
在 Redis 的HLL中 共有个桶,而每个桶是一个 6bit 的数组;hash 生成 64位整数,其中后 14 位用来索引桶子;后面 50位 共有 2^50
用来统计累计0的个数;保存对数的话最大值为 49;6位对应的是 对应整数值为 64 可以容纳存储 49;
漏斗限流
漏斗的结构特点:容量是有限的,当漏斗水装满,水将装不进去;水从漏嘴按一定速率流出,当流水速度大于灌水速度,那么漏斗永远无法装满;当流水速度小于灌水速度,一旦漏斗装满,需要阻塞等待漏斗腾出空间后再灌水;所以,漏斗的剩余空间就代表着当前行为可以持续进行的数量,流水速度代表着系统允许该行为的最大频率;
Redis-Cell
Redis-Cell 是一个扩展模块,它采用 rust 编写;它采用了漏斗算法,并提供了原子的限流指令;
# key 为某漏斗容器
# capacity 为某漏斗容器容量
# operations 为单位时间内某行为的操作次数
# seconds 为单位时间 operations / seconds = 流水速度
# quota 单次行为操作次数 默认值为 1
cl.thottle key capacity operations seconds quota
安装
# 源码安装 然后按照 readme.md 编译安装
git clone https://gitee.com/yaowenqiang/redis-cell.git
# bin安装 如下网址下载相应平台的 .so 动态库文件 https://github.com/brandur/redis-cell/releases
cp libredis_cell.so
/path/to
vi redis.conf
# loadmodules /path/to/libredis_cell.so
测试
CL.THROTTLE cell 1 1 10 1
1) (integer) 0 # 0 标识允许 1 表示拒绝
2) (integer) 2 # 漏斗容量
3) (integer) 1 # 漏斗剩余空间
4) (integer) -1 # 如果被拒绝了,需要多长时间后再试(单位秒)
5) (integer) 10 # 多长时间后,漏斗完全空出来















 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









