







1.架构介绍
WebMagic 的结构分为Downloader(下载)、PageProcessor(处理)、Scheduler(管理)、Pipeline(持久)四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。WebMagic的设计参考了Scapy,但是实现方式更Java化一些。
Spider则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic 逻辑的核心。.

-
Request:
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。
-
Page:
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。在第四章的例子中,我们会详细介绍它的使用。 -
ResultItems:
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
所需依赖
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
<!-- <scope>test</scope>-->
</dependency>
<!--webmagic-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.4</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.4</version>
</dependency>
2.1 实现PageProcessor
2.1.1 抽取元素Selectable
WebMagic里主要使用了三种抽取技术:XPath、正则表达式和CSS选择器。另外,对于JSON格式的内容,可使用JsonPath进行解析。.
1. XPath:
// Xpath解析
page.putField("div2",page.getHtml().xpath("//div[@id=shortcut-2014]/div/ul/li/a"));
2.使用CSS选择器(主要使用方式):
// 解析返回的数据page,并且把解析的结果放到ResultItems中
page.putField("div",page.getHtml().css("ul.fr li a.link-login").all());
3.使用正则表达式(难度较大):
如果想要使用,自行百度正则表达式使用规则
// 使用正则表达式
page.putField("div3",page.getHtml().css("div#shortcut-2014 a").regex(".*我的.*").all());
以上三种方法可以组合使用,例如使用正则表达式的那一节
2.1.2抽取部分API:
| 方法 | 说明 | 示例 |
|---|---|---|
| xpath(String xpath) | 使用XPath选择 | html.xpath("//div[@class=‘title’]") |
| $(String selector) | 使用Css选择器选择 | html.$(“div.title”) |
| $(String selector,String attr) | 使用Css选择器选择 | html.$(“div.title”,“text”) |
| css(String selector) | 功能同$(),使用Css选择器选择 | html.css(“div.title”) |
| links() | 选择所有链接 | html.links() |
| regex(String regex) | 使用正则表达式抽取 | html.regex("(.*?)") |
| regex(String regex,int group) | 使用正则表达式抽取,并指定捕获组 | html.regex("(.*?)",1) |
| replace(String regex, String replacement) | 替换内容 | html.replace("","") |
2.1.3 获得结果API
当链式调用结束时,我们一般都想要拿到一个字符串类型的结果。这时候就需要用到获取结果的API了。
我们知道,一条抽取规则,无论是XPath、CSS选择器或者正则表达式,总有可能抽取到多条元素。WebMagic对这些进行了统一,你可以通过不同的API获取到一个或者多个元素。
| 方法 | 说明 | 示例 |
|---|---|---|
| get() | 返回一条String类型的结果 | String link= html.links().get() |
| toString() | 功能同get(),返回一条String类型的结果 | String link= html.links().toString() |
| all() | 返回所有抽取结果 | List links= html.links().all() |
| match() | 是否有匹配结果 | if (html.links().match()){ xxx; } |
测试:
// 处理结果的api
page.putField("div3",page.getHtml().css("div#shortcut-2014 a").regex(".*我的.*").all());
page.putField("div4",page.getHtml().css("div#shortcut-2014 a").regex(".*我的.*").get());
page.putField("div5",page.getHtml().css("div#shortcut-2014 a").regex(".*我的.*").toString());
page.putField("div6",page.getHtml().css("div#shortcut-2014 a").regex(".*我的.*").match());
结果:

2.1.4 获取链接
目的: 爬取页面当中的链接信息,抓取下来,并且自动进行download操作,在对打开的链接信息进行分析
例如: 爬取京东快报的这个信息
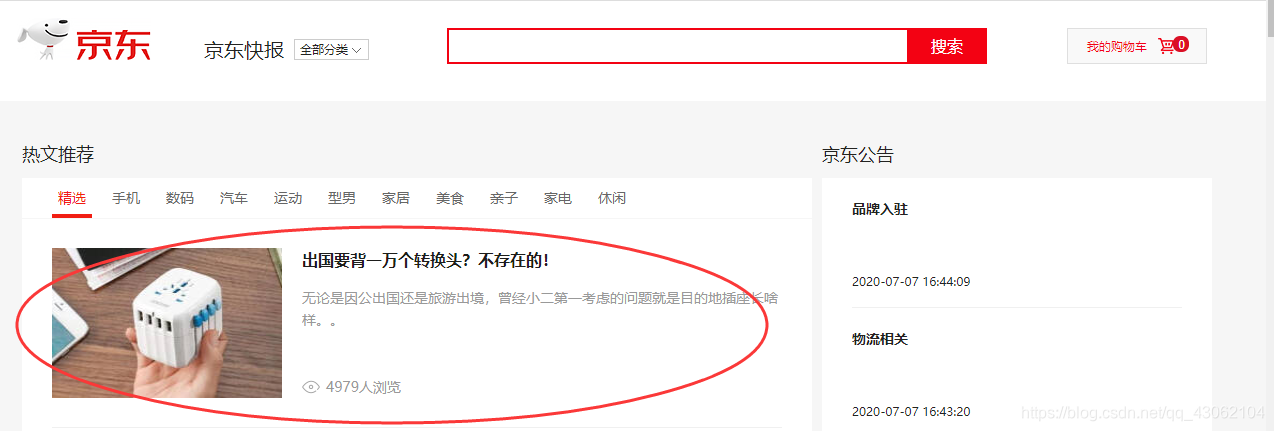

使用webmagic自动的爬取这个链接中的网址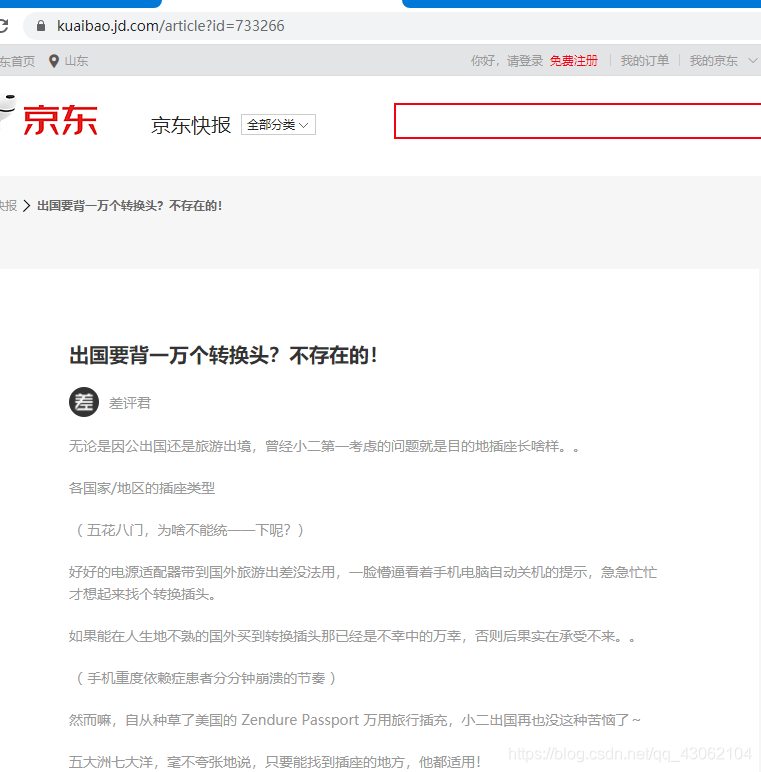
爬取失败,抓取不到页面的信息
// 这里因为京东的反爬虫做的太好了,爬取不下来
// 这里可以自动执行多次链接的内容,只需要放入到page当中就可以自动执行,可以用于小说章节的爬取
page.addTargetRequests(page.getHtml().css("div._3oESJEbA6EDqNUcNu8namk ul#list-646 li._22Oix1ELZz1MDoP6GMIm0F").links().all());
page.putField("url",page.getHtml().css("div._2CD7_2MZBYElpXw5FMiwuK h3[clstag]").all());
3.2 使用和定制Pipeline
3.2.1 简单使用Pipeline
WebMagic用于保存结果的组件叫做Pipeline。例如我们通过“控制台输出结果”这件事也是通过一个内置的Pipeline完成的,它叫做ConsolePipeline。那么,我现在想要把结果用文件的格式保存下来,怎么做呢?我只需要将Pipeline的实现换成"FilePipeline"就可以了
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor())
//从"https://github.com/code4craft"开始抓
.addUrl("https://github.com/code4craft")
.addPipeline(new FilePipeline("D:\\webmagic\\"))
//开启5个线程抓取
.thread(5)
//启动爬虫
.run();
}
3.2.2 WebMagic已经提供的几个Pipeline
WebMagic中已经提供了将结果输出到控制台、保存到文件和JSON格式保存的几个Pipeline:
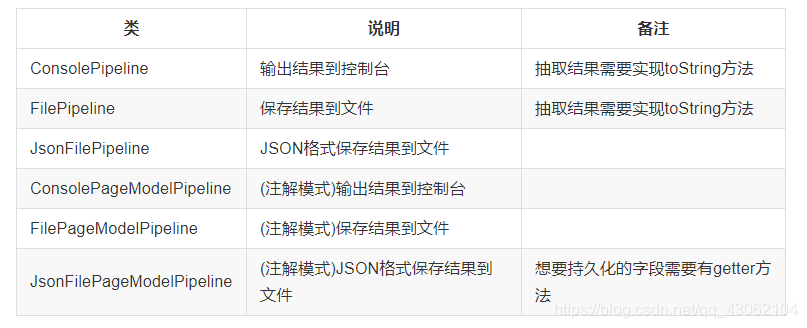
3.2.3 定制Pipeline,保存结果到数据库中
定制Pipeline: 需要定义一个类,实现Pipeline接口,例如:
MybatisPipeline.java
@Component
public class MybatisPipeline implements Pipeline {
@Autowired
private JobInfoService jobInfoService;
@Override
public void process(ResultItems resultItems, Task task) {
// 获取封装好的招聘详情对象
JobInfo jobInfo = resultItems.get("jobInfo");
// 判断数据是否不为空
if (jobInfo != null){
// 如果不为空,则将其保存到数据库当中
jobInfoService.save(jobInfo);
}
}
}
则在PageProcessor中 引入定制的 Pipeline,并且在Spider添加进去
//将自定义的 PipeLine注入到Process中
@Autowired
private MybatisPipeline mybatisPipeline;
// 开启定时任务(initialDelay: 初始化的任务开启时间(项目启动多久后开启这个任务),fixedDelay:间隔多久再次开启)
@Scheduled(initialDelay = 1000, fixedDelay = 100 * 1000) // 单位毫秒 1000毫秒 = 1秒
public void process() {
Spider.create(new JobProcessor())
.addUrl(url)
// 设置Scheduler和布隆过滤器
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)))
.thread(10) //10个线程进行爬取
// 添加Pipeline
.addPipeline(mybatisPipeline)
.run();
}
3.3 爬虫的配置、启动和终止
3.3.1 Spider
Spider是爬虫启动的入口。在启动爬虫之前,我们需要使用一个PageProcessor创建一个Spider对象,然后使用run()进行启动。同时Spider的其他组件(Downloader、Scheduler、Pipeline)都可以通过set方法来进行设置。
| 方法 | 说明 | 示例 |
|---|---|---|
| create(PageProcessor) | 创建Spider | Spider.create(new GithubRepoProcessor()) |
| addUrl(String…) | 添加初始的URL | spider .addUrl(“http://webmagic.io/docs/”) |
| addRequest(Request…) | 开启n个线程 | spider.thread(5) |
| run() | 启动,会阻塞当前线程执行 | spider.run() |
| start()/runAsync() | 异步启动,当前线程继续执行 | spider.start() |
| stop() | 停止爬虫 | spider.stop() |
| addPipeline(Pipeline) | 添加一个Pipeline,一个Spider可以有多个Pipeline | spider .addPipeline(new ConsolePipeline()) |
| setScheduler(Scheduler) | 设置Scheduler,一个Spider只能有个一个Scheduler | spider.setScheduler(new RedisScheduler()) |
| setDownloader(Downloader) | 设置Downloader,一个Spider只能有个一个Downloader | spider .setDownloader(new SeleniumDownloader()) |
| get(String) | 同步调用,并直接取得结果 | ResultItems result = spider .get(“http://webmagic.io/docs/”) |
| getAll(String…) | 同步调用,并直接取得一堆结果 | List results = spider .getAll(“http://webmagic.io/docs/”, “http://webmagic.io/xxx”) |
3.3.2 爬虫配置Site
对站点本身的一些配置信息,例如编码、HTTP头、超时时间、重试策略等、代理等,都可以通过设置Site对象来进行配置。
| 方法 | 说明 | 示例 |
|---|---|---|
| setCharset(String) | 设置编码 | site.setCharset(“utf-8”) |
| setUserAgent(String) | 设置UserAgent | site.setUserAgent(“Spider”) |
| setTimeOut(int) | 设置超时时间,单位是毫秒 | site.setTimeOut(3000) |
| setRetryTimes(int) | 设置重试次数 | site.setRetryTimes(3) |
| setCycleRetryTimes(int) | 设置循环重试次数 | site.setCycleRetryTimes(3) |
| addCookie(String,String) | 添加一条cookie | site.addCookie(“dotcomt_user”,“code4craft”) |
| setDomain(String) | 设置域名,需设置域名后,addCookie才可生效 | site.setDomain(“github.com”) |
| addHeader(String,String) | 添加一条addHeader | site.addHeader(“Referer”,“https://github.com”) |
| setHttpProxy(HttpHost) | 设置Http代理 | site.setHttpProxy(new HttpHost(“127.0.0.1”,8080)) |
private Site site = new Site()
.setCharset("utf8") //设置编码格式
.setTimeOut(10000) //单位是毫秒
.setRetrySleepTime(3000) // 设置重试间隔时间(单位是毫秒)
.setRetryTimes(3) // 设置重试次数
;
3.4 代理的使用
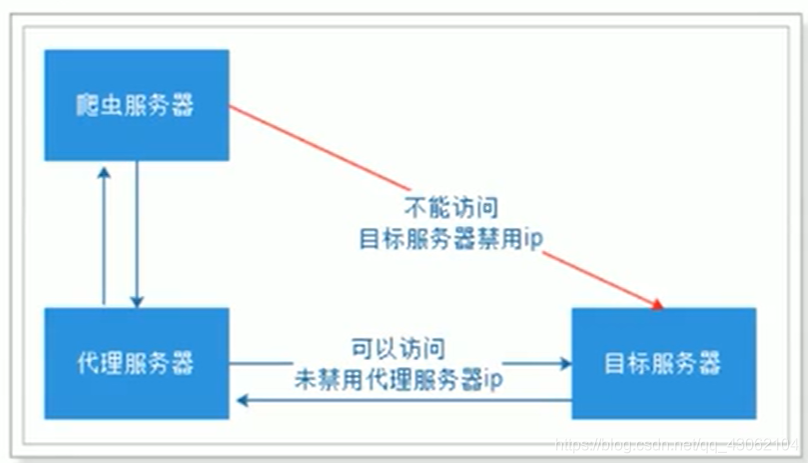
有些网站不允许爬虫进行数据爬取,因为会加大服务器的压力。其中一种最有效的方式是通过ip+时间进行鉴别,因为正常人不可能短时间开启太多的页而,发起太多的请求。
我们使用的WebMagic可]以很方便的设置爬取数据的时间。但是这样会大大降低我们爬取数据的效率,如果不小心ip 被禁了,会让我们无法爬去数据,那么我们就有必要使用代理服务器来爬取数据。.
3.4.1 代理服务器
代理(英语:Proxy),也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。
提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(ProxyServer)。一个完整的代理请求过程为:客户端首先与代理服务器创建连接,接着根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或者获得目标服务器的指定资源
具体流程:
测试用: 免费代理服务器:
https://proxy.mimvp.com/freesecret
3.4.2 使用代理
从0.7.1版本开始,WebMagic开始使用了新的代理APIProxyProvider。因为相对于Site的“配置”,ProxyProvider定位更多是一个“组件”,所以代理不再从Site设置,而是由HttpClientDownloader设置。

ProxyProvider有一个默认实现:SimpleProxyProvider。它是一个基于简单Round-Robin的、没有失败检查的ProxyProvider。可以配置任意个候选代理,每次会按顺序挑选一个代理使用。它适合用在自己搭建的比较稳定的代理的场景。
如果需要根据实际使用情况对代理服务器进行管理(例如校验是否可用,定期清理、添加代理服务器等),只需要自己实现APIProxyProvider即可。
设置代理
@Scheduled(fixedDelay = 1000)
public void process(){
//创建下载器Downloader
HttpClientDownloader httpClientDownloader= new HttpClientDownloader();
//给下载器设置代理服务器信息
httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("112.192.146.102",32261)));
Spider.create(new ProxyTest())
.addUrl("http://ip.chinaz.com/")
//设置下载器
.setDownloader(httpClientDownloader)
.run();
}
入门程序:
JobProcessor.java
package cn.itcast.webmagic.test;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.pipeline.JsonFilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class JobProcessor implements PageProcessor {
//解析页面
@Override
public void process(Page page) {
// 解析返回的数据page,并且把解析的结果放到ResultItems中
page.putField("div",page.getHtml().css("ul.fr li a.link-login").all());
// Xpath解析
page.putField("div2",page.getHtml().xpath("//div[@id=shortcut-2014]/div/ul/li/a"));
// 使用正则表达式
page.putField("div3",page.getHtml().css("div#shortcut-2014 a").regex(".*我的.*").all());
// 处理结果的api
page.putField("div4",page.getHtml().css("div#shortcut-2014 a").regex(".*我的.*").get());
page.putField("div5",page.getHtml().css("div#shortcut-2014 a").regex(".*我的.*").toString());
page.putField("div6",page.getHtml().css("div#shortcut-2014 a").regex(".*我的.*").match());
// 获取链接
//page.getHtml().css("div._3oESJEbA6EDqNUcNu8namk ul#list-646 li._22Oix1ELZz1MDoP6GMIm0F a[href]")
//page.putField("div7",page.getHtml().css("li").all());
// 这里因为京东的反爬虫做的太好了,爬取不下来
// 这里可以自动执行多次链接的内容,只需要放入到page当中就可以自动执行,可以用于小说章节的爬取
//page.addTargetRequests(page.getHtml().css("div._3oESJEbA6EDqNUcNu8namk ul#list-646 li._22Oix1ELZz1MDoP6GMIm0F").links().all());
//page.putField("url",page.getHtml().css("div._2CD7_2MZBYElpXw5FMiwuK h3[clstag]").all());
}
private Site site = new Site()
.setCharset("utf8") //设置编码格式
.setTimeOut(10000) //单位是毫秒
.setRetrySleepTime(3000) // 设置重试间隔时间(单位是毫秒)
.setRetryTimes(3) // 设置重试次数
;
@Override
public Site getSite() {
return site;
}
//主函数执行爬虫
public static void main(String[] args) {
Spider.create(new JobProcessor())
.addUrl("https://kuaibao.jd.com/?ids=238170687,238297163,174072062,238048103") //设置爬取数据的页面
//.addPipeline(new FilePipeline("C:\\Users\\ZRE\\Desktop\\result")) // 将结果以json文件的方式输出到指定路径
.thread(5) // 使用多线程方式,设置用5个线程处理
.run(); //执行爬虫
}
}














 1729
1729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









