







- 单线程的redis为什么速度比较块
- redis是基于内存操作的,cpu不是redis性能瓶颈,redis的瓶颈是根据机器的内存和网络带宽。
- redis是将所有的数据放在内存中的,所以说使用单线程操作去操作效率就是最高的,多线程(CPU上下文切换,耗时的操作),对于内存系统来说,如果没有上下问切换,效率就是最高的。
- redis 使用全局哈希表来存储数据。使用哈希表难免会有冲突,
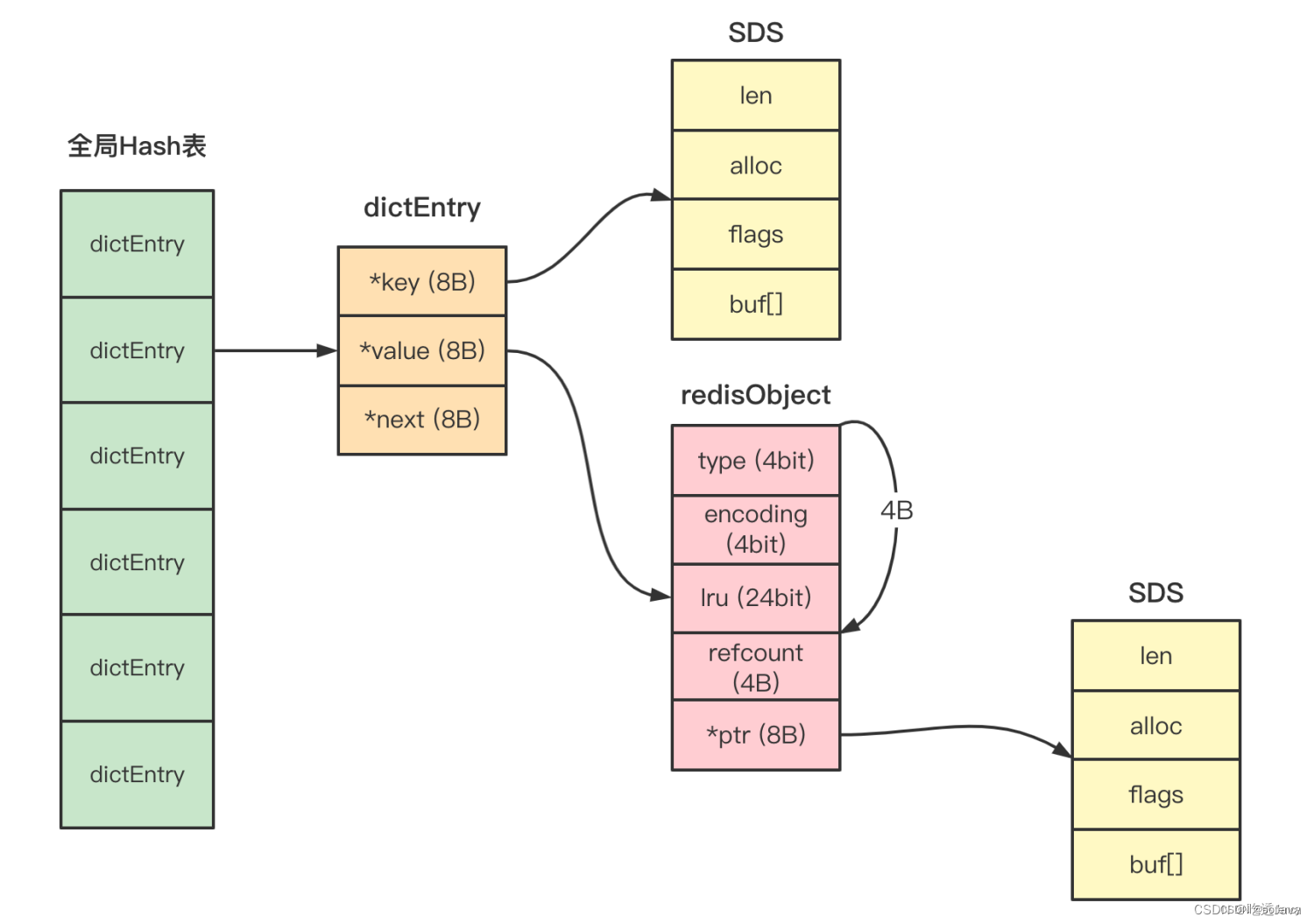
1. 链式hash,对于hash值相同的位置使用链表结构处理 2. 链表长度达到一定程度时使用渐进式rehash方法,(把大块迁移数据的开销,平摊到多次小的操作中,目的是降低主线程的性能开销) 触发渐进式rehash的情况: 增删改查时,每次迁移一个哈希桶。 定时rehash,如果dict一直没有操作,无法渐进式迁移数据,那么主线程会默认每间隔100ms执行一次迁移操作。 这里一次会以100个桶迁移数据,并限制如果一次操作耗时超过1ms 就结束本次任务,待下次触发迁移
定时rehash只会迁移全局哈希表中的数据,不会迁移Hash/Set/Sorted set的数据,这些只会在操作数据时实时的渐进式rehash。
```
- Hyperloglog基数统计
简介:是用来做基数统计的算法!什么叫做基数 (1,2,3,4,2) 基数是一组数列中不重复的数字的个数 所以这是 4
常用的命令pfadd mykey a b c s d f //添加基数 pscount mykey //查询下里面有多少个基数 得出是6 pfadd mykey1 4 3 2 1 2 //添加基数 //基数的合并 psmerge mykey3 mykey mykey1 将两个基数列表合并到mykey3中 pscount mykey3 查询合并之后的基数个数 - redis的事务操作
redis单条命令保存原子性,但是事务不保证原子性。
multi命令开始事务
开始输入命令
exec 执行命令

放弃事务
discard 放弃事务。
出现异常的情况 如果命令写错的话 那么事务中的所有命令都失效,如果事务中的命令在执行过程中出现异常,那么其他的命令不会失效。
-
redis 实现乐观锁
使用watch命令监视变量的变化。如果在开启事务的情况下,还没执行完,其他的线程,对监控的数据进行了修改,那么事务就会执行失败。执行完成之后注意使用unwatch解除监视。 -
redis的持久化操作
rdb方式
在指定的时间间隔内将内存中的数据集写入到磁盘中,恢复时将快照文件直接读到内存中。redis会单独创建一个子进程来进行持久化,会先将数据写入到临时文件中,待持久化过程结束了,再用这个临时文件替换上次持久化好的临时文件,整个过程中主进程是不进行任何的IO操作的,这就确保了极高的性能。
默认的存储文件名是dump.rdb,
rdb方式有专属的文件存储机制,例如下面
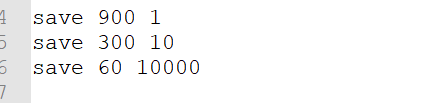
使用save的方式 save time times ,在时间经过time秒后中存在times次操作,就进行存储到文件中
触发机制- save的规则满足的情况下,会自动触发rdb规则
- 执行flushall命令也会出发rdb规则
- 退出redis 也会出发rdb文件。
恢复rdb文件
- 只需要将rdb文件放在我们redis启动目录就可以,redis启动的时候会自动检查dump.rdb 恢复其中的数据。
- 查看需要存在的位置
config get dir
优点:
适合大规模的数据恢复
对数据的完整性要求不高
缺点:
最后一次持久话的数据如果宕机的话,可能数据丢失。aof方式
介绍:将我们所有的命令都存储下来,这样数据恢复的时候,会把所有的命令都执行一遍。默认该种方式是不开启的。因为比较消耗时间。
如果aof中文件有错位,这时候redis是启动不起来的,我们需要修复这个aof文件,redis给我们提供了
redis-check-aof --fix appendonly.aof优点:每次修改都同步,文件的完整性比较好,每秒同步一次,可能会丢失一秒的数据。
缺点:
相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢
aof运行效率也要比rdb慢















 6019
6019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









