







SparkStreaming中DStream的转换操作分为两种,一种是无状态的转换操作,另外一种是有状态的转换操。
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。部分无状态转化操作列在了下表中。 注意,针对键值对的 DStream 转化操作(比如 reduceByKey())要添加import StreamingContext._ 才能在 Scala中使用。
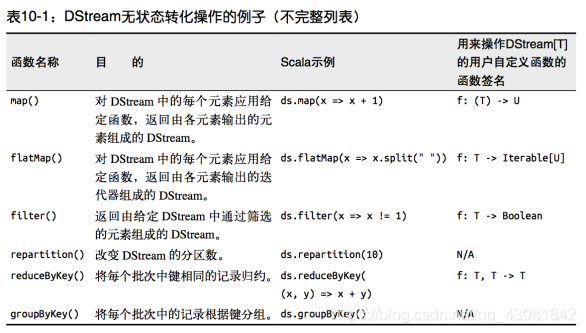
需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部是由许多 RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。例如, reduceByKey() 会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
举个例子,在之前的wordcount程序中,我们只会统计1秒内接收到的数据的单词个数,而不会累加。
无状态转化操作也能在多个 DStream 间整合数据,不过也是在各个时间区间内。例如,键 值对 DStream 拥有和 RDD 一样的与连接相关的转化操作,也就是 cogroup()、join()、 leftOuterJoin() 等。我们可以在 DStream 上使用这些操作,这样就对每个批次分别执行了对应的 RDD 操作。
我们还可以像在常规的 Spark 中一样使用 DStream 的 union() 操作将它和另一个 DStream 的内容合并起来,也可以使用 StreamingContext.union() 来合并多个流。
有状态转化操作
追踪状态变化UpdateStateByKey
UpdateStateByKey原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加wordcount)。针对这种情况,updateStateByKey() 为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件 更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对应的(键,状态)对组成的。
updateStateByKey操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,你需要做下面两步:
- 定义状态,状态可以是一个任意的数据类型。
- 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更新。
使用updateStateByKey需要对检查点目录进行配置,会使用检查点来保存状态。
更新版的wordcount:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WorldCount {
def main(args: Array[String]) {
// 定义更新状态方法,参数values为当前批次单词频度,state为以往批次单词频度
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint(".")
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("master01", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
//import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
// 使用updateStateByKey来更新状态,统计从运行开始以来单词总的次数
val stateDstream = pairs.updateStateByKey[Int](updateFunc)
stateDstream.print()
//val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
//wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
//ssc.stop()
}
}
启动nc –lk 9999
[root@master01 ~]$ nc -lk 9999
ni shi shui
ni hao ma
启动统计程序:
[root@master01 ~]$ ./hadoop/spark-2.1.1-bin-hadoop2.7/bin/spark-submit --class com.atguigu.streaming.WorldCount ./statefulwordcount-jar-with-dependencies.jar
17/09/06 04:06:09 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-------------------------------------------
Time: 1504685175000 ms
-------------------------------------------
-------------------------------------------
Time: 1504685181000 ms
-------------------------------------------
(shi,1)
(shui,1)
(ni,1)
-------------------------------------------
Time: 1504685187000 ms
-------------------------------------------
(shi,1)
(ma,1)
(hao,1)
(shui,1)
(ni,2)
[root@master01 ~]$ ls
2df8e0c3-174d-401a-b3a7-f7776c3987db checkpoint-1504685205000 data
backup checkpoint-1504685205000.bk debug.log
checkpoint-1504685199000 checkpoint-1504685208000 hadoop
checkpoint-1504685199000.bk checkpoint-1504685208000.bk receivedBlockMetadata
checkpoint-1504685202000 checkpoint-1504685211000 software
checkpoint-1504685202000.bk checkpoint-1504685211000.bk statefulwordcount-jar-with-dependencies.jar
Window Operations
Window Operations有点类似于Storm中的State,可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。
基于窗口的操作会在一个比 StreamingContext 的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
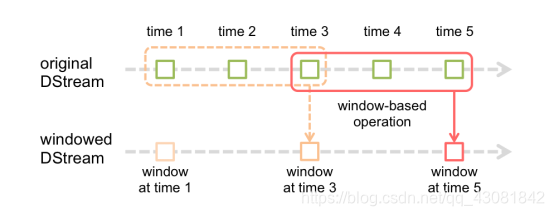
所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是 StreamContext 的批次间隔的整数倍。窗口时长控制每次计算最近的多少个批次的数据,其实就是最近的 windowDuration/batchInterval 个批次。如果有一个以 10 秒为批次间隔的源 DStream,要创建一个最近 30 秒的时间窗口(即最近 3 个批次),就应当把 windowDuration 设为 30 秒。而滑动步长的默认值与批次间隔相等,用来控制对新的 DStream 进行计算的间隔。如果源 DStream 批次间隔为 10 秒,并且我们只希望每两个批次计算一次窗口结果, 就应该把滑动步长设置为 20 秒。
假设,你想拓展前例从而每隔十秒对持续30秒的数据生成word count。为做到这个,我们需要在持续30秒数据的(word,1)对DStream上应用reduceByKey。使用操作reduceByKeyAndWindow.


reduceByWindow() 和 reduceByKeyAndWindow() 让我们可以对每个窗口更高效地进行归约操作。它们接收一个归约函数,在整个窗口上执行,比如 +。除此以外,它们还有一种特殊形式,通过只考虑新进入窗口的数据和离开窗 口的数据,让 Spark 增量计算归约结果。这种特殊形式需要提供归约函数的一个逆函数,比 如 + 对应的逆函数为 -。对于较大的窗口,提供逆函数可以大大提高执行效率 。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











