









目标:爬取站长素材中网页中的免费简历模板
前言:
——最近几天天气太冷,懒得写那么多,所以直接找到其中一个下载链接,然后写一个教程!如果需要下载多页内容数据,这里建议自己去补充代码,你可以使用“bs4”,“正则”或者“xpath”都可以。
—— 看到不少人说站长素材网站是收费才能下载……,其实还是免费的只是前一列如果下载需要收费而已,后面的都是免费呢!如下图所示哦!
图例1:
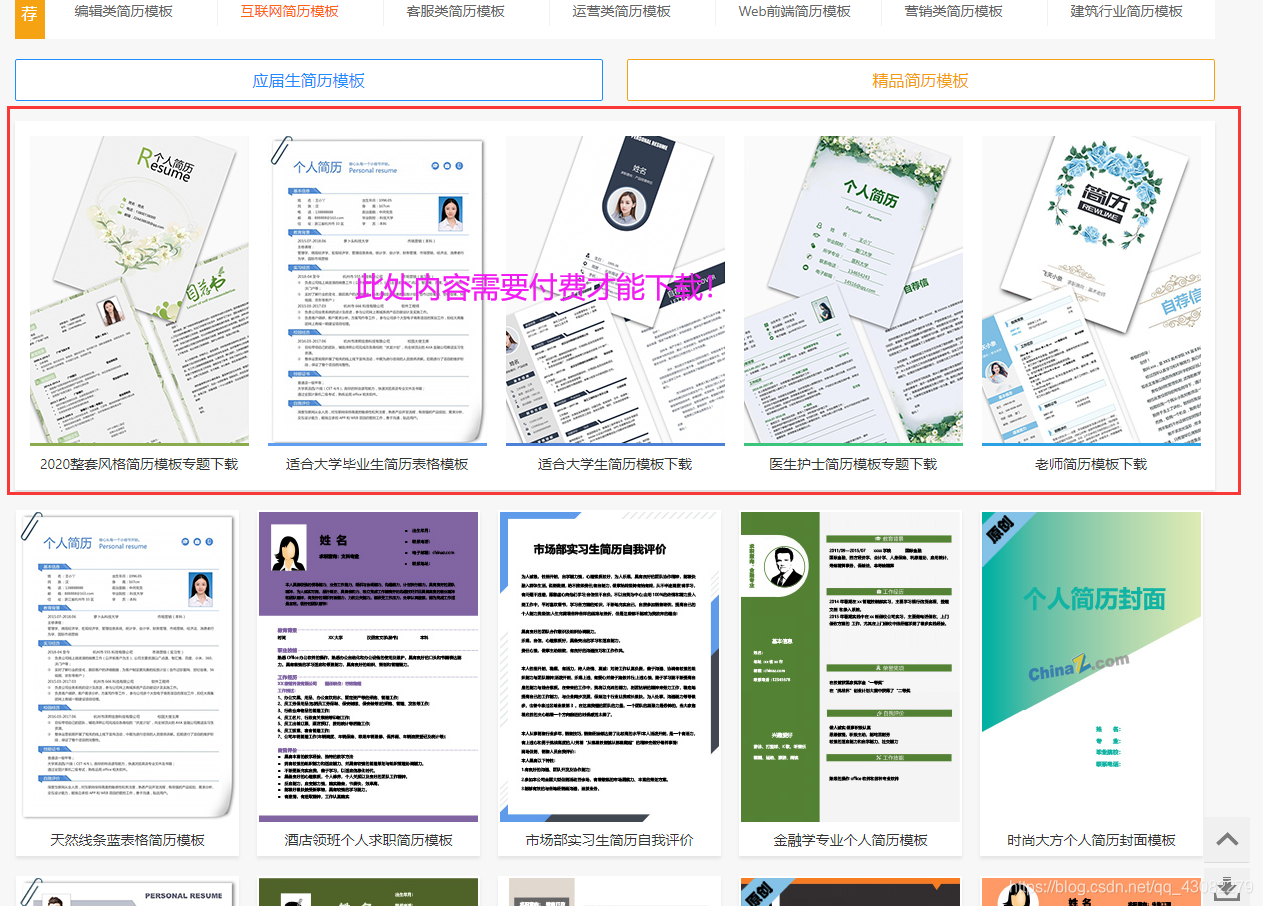
除了红色框里面的点进去是收费的后面的其实都是可以免费下载的!
# 导入网络请求库requests
import requests
# 程序入口
if __name__ == "__main__":
# 封装请求头参数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.57'}
# 封装url
url="https://downsc.chinaz.net/Files/DownLoad/jianli/202101/jianli14393.rar"
# 发起请求
response = requests.get(url=url,headers=headers)
# 打印一下状态码,如是200表示请求成功!
print(response.status_code)
# 打印一下requests返回的编码方式
# print(response.encoding)
# 自动获取网页编码方式(如果出现乱码,推荐使用自动获取,这里因为我们直接向rar下载url发送请求,所以不需要管编码对不对!)
# print(response.apparent_encoding)
# 获取相应数据
response_data = response.content
# # 数据存储(记得为二进制方式写入!)
with open('adi.rar','wb') as adi_data:
adi_data.write(response_data)
print('写入完成')
print('已end程序')
# 退出程序以免占用后台!
exit()
以上是个人练习经验总结!
温馨提示:
收费内容过滤办法:可以利用requests发送请求之后如果成功返回的状态码,如果等于200表示请求成功;如果不等于200,表示下载失败(欧了个欧)可以重新继续向下一个url发送请求哦!














 1974
1974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









