







1、Elasticsearch是什么?
Elasticsearch是基于Lucence的一款分布式实时搜索引擎( 仅支持JDK1.8以上 ),其跟Lucence一样是基于Java开发的,并以Lucence作为核心包来实现索引和搜索的功能。但是由于Lucence在开发使用时稍偏复杂,所以Elasticsearch通过Restful API的方式进行调用,直接隐藏了Lucence的复杂性。
2、Elasticsearch对比Solr、Lucence有什么区别?
Elasticsearch、Solr都是基于Java和Lucence的。Solr主要是通过POST请求的方式向服务器发出请求,Solr主要是通过xml的方式来进行索引的添加、删除、更新操作;而Solr的搜索是通过GET的方式来实现的,其对查询返回的Xml、Json等数据格式的查询结果进行解析。
Elasticsearch对比Solr
- 单纯只对已经存在的数据进行查询的话Solr的查询速度更快。
- 在实时建立索引方面,Solr由于会产生IO阻塞,所以其查询性能较差。Elasticsearch建立索引的速度几乎是实时的。
- 随着数据量的指数性增加,Solr的查询性能会大打折扣,而Elasticsearch的查询性能几乎不变,可以说是实时的。
- Solr是通过Zookeeper实现分布式管理的,而Elasticsearch自身携带分布式协调管理能力。
- Solr支持Xml、Json、Csv,而Elasticsearch仅支持Json。
- Solr查询快,但是删除、新增慢;Elasticsearch实时查询快。
3、安装,搭建Elasticsearch7.6.1平台
Elasticsearch相关(kibana、elasticsearch、ik-analyze、head)压缩包:
链接:https://pan.baidu.com/s/1aFEuBgR3VqM9O5KzfK2mFA 提取码:llhm
步骤
- 解压kibana(数据可视化操作平台)、elasticsearch、ik-analyze(分词器)、head(elasticsearch查询插件)压缩包到本地
- 由于每个组件都有不同端口号,所以需要配置elasticsearch支持跨域请求,es的config目录下找到elasticsearch.yml,新增 http.cors.enabled: true 和 http.cors.allow-origin: “*” 以支持跨域请求;kibana可以改为支持中文的方式 i18n.locale: "zh-CN"
- 分别启动相关组件即可,kibana默认5601端口,elasticsearch默认9200端口,head插件默认9100端口
注意,Kibana版本号一定要和Elasticsearch版本号一致
4、 Elasticsearch核心概念
Elasticsearch主要是面向文档的操作,以下为关系型数据库和Elasticsearch的客观对比
| 关系型数据库 | Elasticsearch |
|---|---|
| 数据库 | 索引(indicies) |
| 表 | 类型(type,基本被弃用了) |
| 行 | 文档(document) |
| 字段 | fields |
一个ES服务就是一个集群,其服务名为elasticsearch
- elasticsearch是面向文档的操作,索引和搜索的最小单位是文档;
- elasticsearch主要采用的是倒排索引的方式进行查询的;
5、了解倒排索引 ( 倒排索引有利于快速全文搜索 )
举例,以下有两个文档
文档1:Good good study day day up!forever and go on!
文档2:Study makes me happy!forever!
| term(关键词) | doc1 | doc2 |
|---|---|---|
| good | √ | × |
| study | √ | × |
| forever | √ | × |
| makes | × | √ |
| me | × | √ |
例如,现在要查询good good study!这里倒排索引就会挑选 √ 出现次数最多的文档
| term(关键词) | doc1 | doc2 |
|---|---|---|
| good | √ | × |
| study | √ | × |
因此,在doc1文档中的 √ 次数最多,在权重方面doc1大于doc2,其score值越高,优先搜索的就是doc1;而与MySQL中的正排索引不同,正排索引的查询方式是先扫描索引库中的所有内容,然后找到所有包含指定关键字的文档,然后根据打分模型对数据进行打分,排名后再呈现结果给用户。
总结:倒排索引不会查询无关的文档内容,而正排索引先是查询所有文档,再进行过滤;因此前者查询速度更快
6、IK分词器 ( ik-analyze是基于Lucence的中文分词器 )
ik-analyze区分为两种算法,ik_smart和ik_max_word
(1)ik_smart算法(最少划分)
- 满打满算,按断点打开,尽量把句子拆分成词库里面的每一个词语
美丽的山河和世文 => 美丽的、山河和世文
(2)ik_max_word(最细粒度划分)
- 细度划分,穷尽词库的所有可能进行划分
美丽的山河和世文 => 美丽、美丽的、山河、山河和、世文
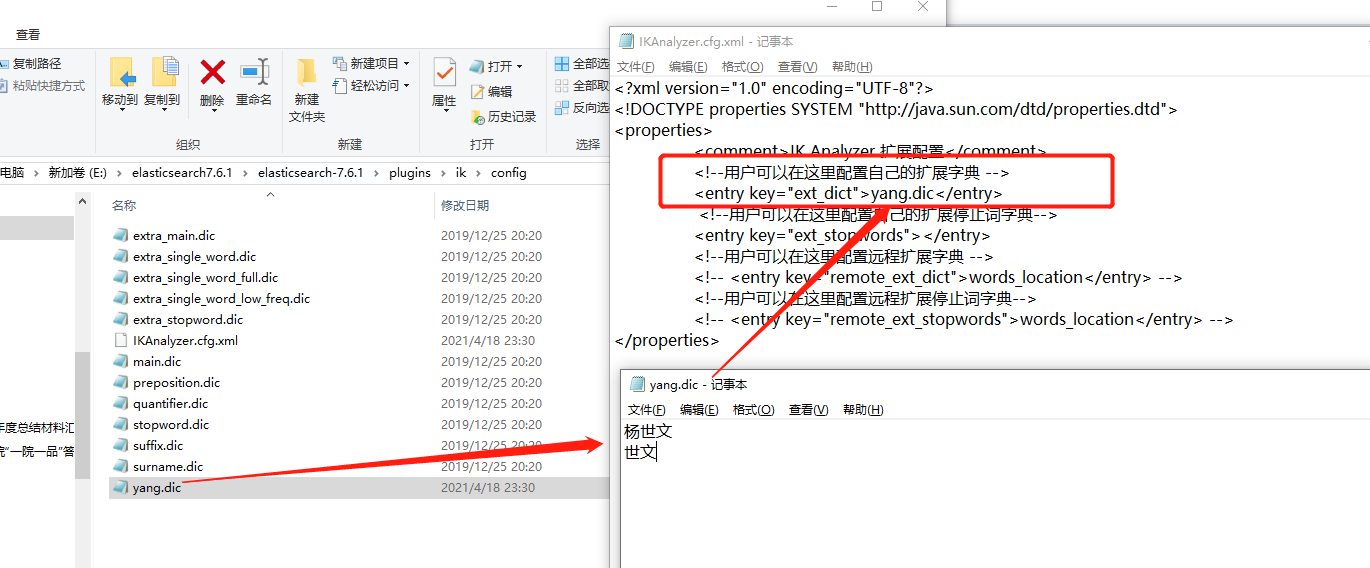
7、配置ik-analyze的中文词库
- 首先将ik-analyze文档解压,并将文件放到Elasticsearch目录下的
plugins文档下, - 在ik目录下的config文件中创建一个
xxx.dic作为自己的分词文档 - 修改config目录下的
IKAnalyzer.cfg.xml文档,将自己的分词文档配置进来,随后自行在xxx.dic文档中添加想要
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">yang.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
- 配置详情图示
8、kibana索引操作命令
| 请求方式 | url地址 | 描述 |
|---|---|---|
| PUT | PUT /索引名/_doc/id | 创建文档 |
| POST | POST /索引名/_doc/id | 创建文档 |
| POST | POST /索引名/_doc/id/_update | 修改文档 |
| DELETE | DELETE /索引名/_doc/id | 删除文档 |
| GET | GET /索引名/_doc/id | 通过id查询文档 |
| POST | POST /索引名/_doc/_search | 查询所有数据 |
新增文档
- 新增索引
PUT /test1/type1/1
{
"name":"世文",
"age": 18
}
- 指定文档类型
PUT /test3
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"birthday": {
"type": "date"
}
}
}
}
修改文档
- 修改索引依旧可以使用PUT,不过直接使用的话会直接覆盖的,一般最好用POST,并结合使用_update
POST /test2/_doc/2/_update
{
"doc": {
"name": "世文33333"
}
}
删除索引
DELETE /test2/_doc/2
花样新增文档
PUT /test4/_doc/4
{
"name": "世文1",
"age": 18,
"desc": "这里是描述内容",
"tags": ["开心","快乐","嗨皮"]
}
PUT /test4/_doc/5
{
"name": "阿姨5",
"age": 40,
"desc": "阿姨的天下",
"tags": ["嗯嗯","哦哦","嘿嘿"]
}
条件查询
GET /test4/_doc/_search?q=name:5
花样条件查询1
匹配查询
GET /yang_index_bulk/_doc/_search
{
"query": {
"match": {
"age" : 1 // 精确查询age = 1
}
},
"from": 0, // 分页pageNo
"size": 1, // 分页pageSize
"_source": ["userName", "age"], // 指定展示userName
"sort": [{
"age": {
"order": "desc" // 指定使用age进行降序排序
}
}]
}
花样条件查询2
must相当于and条件查询,must_not就是not条件查询
GET /yang_index_bulk/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"userName": "DD"
}
},
{
"match": {
"age": 1
}
}
]
}
}
}
花样条件查询3
相当于or查询
GET /yang_index_bulk/_doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"userName": "DD"
}
},
{
"match": {
"age": 2
}
}
]
}
}
}
花样条件查询4
filter过滤器
GET /yangshiwen/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "文文" // 姓名包含文文
}
}
],
"filter": {
"range": {
"age": {
"gte": 10, // 年龄大于等于10岁
"lte": 20 // 年龄小于等于20岁
}
}
}
}
}
}
花式查询5
多条件精确查询
GET testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"t1": {
"value": "22"
}
}
},
{
"term": {
"t1": {
"value": "33"
}
}
}
]
}
},
"from": 0,
"size": 1
}
高亮查询
GET /test3/_search
{
"query": {
"match": {
"name": "世文"
}
},
"highlight": {
"pre_tags": "<p class = 'key' style = 'color:red'>", // 前缀
"post_tags": "</p>", // 后缀
"fields": {
"name": {}
}
}
}
9、Elasticsearch整合springboot
- 第一步,导入maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- elasticsearch依赖, 其实它也是基于lucene的, 一定要和本地版本一致, 这里我用7.6.1 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
- 第二步,创建ES中的
RestHighLevelClient对象,放入spring容器
@Configuration
public class ElasticsearchConfig {
// spring = <bean id = "highLevelClient" class = "RestHighLevelClient">
// 这里需要将对象注入spring
@Bean
public RestHighLevelClient highLevelClient() {
// 如果是集群就配置多个, 如果不是集群就只配置一个
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
- 第三步,进行编码
package com.yang.elasticsearch;
import com.alibaba.fastjson.JSON;
import com.yang.elasticsearch.pojo.User;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.*;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
@SpringBootTest
class ElasticsearchApplicationTests {
// 默认注入, 这里需要注意对象类型和名字都需要对应, 否则需要用 @Qualifier("")
@Autowired
@Qualifier("highLevelClient")
private RestHighLevelClient client;
// 测试索引的创建 PUT 这里都是用rest请求 [ PUT yang_index/_doc ]
@Test
void createIndex() throws IOException {
// 1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest("yang_index");
// 2、客户端执行创建请求, 请求完了获得响应, 判断是否存在
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println("createIndexResponse = " + createIndexResponse.index());
}
// 测试获取索引 GET [GET yang_index] , 只能判断存不存在
@Test
void existIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("yang_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("getIndexResponse = " + exists);
}
// 测试删除索引 DELETE [DELETE yang_index]
@Test
void deleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("yang_index");
AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);
// 判断是否删除成功
System.out.println(response.isAcknowledged());
}
// 测试, 新增文档
@Test
void testAddDocument() throws IOException {
// 创建对象
User user = new User("世文", 3);
// 创建请求
IndexRequest request = new IndexRequest("yang_index");
// PUT /索引/_doc/1 不默认id为1的话会产生一个随机的id
request.id("1");
// 设置请求超时时间 request.timeout("1s");
request.timeout(TimeValue.timeValueSeconds(1));
// 将我们的数据放入请求 json 发出请求
request.source(JSON.toJSONString(user), XContentType.JSON);
// 客户端发出请求 获取响应结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println("indexResponse.toString() = " + indexResponse.toString());
// 对应命令返回状态
System.out.println("indexResponse.status() = " + indexResponse.status());
}
// 获取文档 判断是否存在 get /index/_doc/1
@Test
void existDocument() throws IOException {
GetRequest request = new GetRequest("yang_index", "1");
// 不获取 _source 上下文了
request.fetchSourceContext(new FetchSourceContext(false));
// 根据指定字段排序
request.storedFields("_none_");
// 文档id
System.out.println("request.id() = " + request.id());
// 命令
System.out.println("request.toString() = " + request.toString());
System.out.println("client.exists(request, RequestOptions.DEFAULT) = " + client.exists(request, RequestOptions.DEFAULT));
}
// 获取文档内容
@Test
void getDocument() throws IOException {
GetRequest request = new GetRequest("yang_index", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 获取指定字段 userName
response.getField("userName");
// 获取内容 或者可以封装成map或者其他内容
System.out.println("response.getSourceAsString() = " + response.getSourceAsString());
// 这里返回的内容跟是命令完全相同的
System.out.println("response = " + response);
}
// 更新文档
@Test
void updateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("yang_index", "1");
// 请求最大时长1s
request.timeout(TimeValue.timeValueSeconds(1));
User user = new User("世文说java", 18);
// 更新文档 POST /索引/_doc/文档/_update doc [field = ""]
request.doc(JSON.toJSONString(user), XContentType.JSON);
// 执行请求
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println("response = " + response);
}
// 删除文档
@Test
void deleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("yang_index", "1");
// 请求时间1s, 超时不请求了
request.timeout(TimeValue.timeValueSeconds(1));
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println("response = " + response.status());
}
// 批量插入数据
@Test
void batchAdd() throws IOException {
BulkRequest request = new BulkRequest();
request.timeout(TimeValue.timeValueSeconds(10));
List<User> userList = new ArrayList<>();
userList.add(new User("DD", 1));
userList.add(new User("CC", 2));
userList.add(new User("BB", 3));
userList.add(new User("EE", 4));
userList.add(new User("FF", 5));
userList.add(new User("GG", 6));
userList.add(new User("HH", 7));
// 批处理请求
for (int i = 0; i < userList.size(); i++) {
// 对应的批量更新和批量删除都在这里执行
request.add(
new IndexRequest("yang_index_bulk")
.id("" + (i + 1))
.source(JSON.toJSONString(userList.get(i)), XContentType.JSON));
}
// 执行请求
BulkResponse bulk = client.bulk(request, RequestOptions.DEFAULT);
System.out.println("bulk = " + bulk.hasFailures()); // 是否失败, false代表成功
}
// 批量查询
@Test
void bulkGet() throws IOException {
SearchRequest searchRequest = new SearchRequest("yang_index_bulk");
// 构建搜索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 分页
searchSourceBuilder.from(0);
searchSourceBuilder.size(10);
// 高亮构建
// searchSourceBuilder.highlighter();
// 构建条件查询
// 模糊查询
// MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("userName", "AA");
// 查询所有
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
// 精确查询
MatchPhraseQueryBuilder matchPhraseQueryBuilder = QueryBuilders.matchPhraseQuery("userName", "CC");
// 这个失效了, 可以使用上面的
// TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("userName", "AA");
searchSourceBuilder.query(matchPhraseQueryBuilder);
// 时间不能超过10s
// searchSourceBuilder.timeout(TimeValue.timeValueSeconds(10));
searchSourceBuilder.timeout(new TimeValue(10, TimeUnit.SECONDS));
// 放入请求
searchRequest.source(searchSourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
// 所有的数据都在hits里面
System.out.println("response.getHits() = " + JSON.toJSONString(response.getHits()));
System.out.println(" ============== ");
for (SearchHit documentFields : response.getHits().getHits()) {
// 打印数据
System.out.println(documentFields.getSourceAsMap());
}
}
}















 1032
1032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









