







文章目录
实现内核线程
执行流
当处理器只有一个内核时,操作系统的运行方式是单任务操作系统,即无论有多少任务要执行,它们的执行顺序都是串行的,一个任务彻底完成后才会接着执行下一个任务,假设前面某个任务执行的时间特别长,例如 2 天,则后一个任务就需要等 2 天,效率非常低。
于是,在处理器不变的前提下,多任务操作系统出现了,它采用了一种称为多道程序设计的方式,使处理器在所有任务之间来回快速切换,这就使用户产生了所有任务并行执行的错觉,具体切换到哪个任务,这个就由操作系统中的任务调度器决定。
任务调度器在内核中维护一个任务表(也称进程表、线程表或调度表),然后按照一定的算法,从任务表中选择一个任务,然后将其放到处理器上执行。
调度算法采用较为公正的时间片轮转算法,也称轮询。
代码运行过程中,程序计数器指向下一条指令所组成的执行轨迹称为程序的控制执行流。
执行流就是一段逻辑上独立的指令区域,是人为安排的处理单元。
执行流是独立的,它的独立性体现在每个执行流都有自己的栈、寄存器或内存资源等。
任何代码块都可以是执行流,只需要为其提供上下文即可(因为它是独立的)。
在任务调度器中,只有执行流才是调度单元,即处理器上运行的都是调度器给分配的执行流,只要成为执行流就能独立上处理器运行了。
线程到底是什么
它是一个函数,但这个函数不一般,它不像平常的函数调用,让主线程调用函数去执行,该函数是独立的,有自己的上下文环境,是一个执行流,它独立在处理器上运行。
只要是独立执行流就可以被调度器视为一个调度单元,就可以享受处理器的单独服务。
我们需要做的就是:给任何想单独上处理器的代码块准备好它所依赖的上下文环境,从而使其具备独立性,使之称为执行流,即调度单元。
进程与线程的关系、区别简述
进程拥有整个地址空间,即是资源的所有者,而线程没有自己的地址空间,线程依赖于进程的地址空间,也就是说线程依赖于进程中的资源,因此线程被称为轻量级进程。
在显示创建线程后,任务调度器就可以把它所对应的代码块从进程中分离出来,单独调度上处理器执行。
在没有线程这个概念之前,进程就是个执行流(也就是现在所说的线程),但有了线程这个概念之后,执行流便专指细粒度更细的线程,所以说程序都有执行流,若未显示创建线程,则当前进程中的指令自然也是执行流,也就是只存在一个线程(即单线程程序),若进程中显示创建多个线程,则称为多线程程序。
线程的作用是为了提速:实现多个执行流的伪并行。
- 协助完成主线程任务:假设一个任务 A 需要完成一个复杂的任务,A 显示的创建了多个线程去并行协助主线程完成,这多个线程是相互之间无依赖的。
- 避免阻塞进程:当程序需要进入输入时,该进程就无法继续执行,此时操作系统会将该进程挂起,从就绪状态中去除,等输入完成,再将其送回就绪队列。
各个进程都有用自己的地址空间,正常情况下相互之间无法访问,因为进程之间的安全性是由操作系统的分页机制来保证的,只要操作系统不要把相同的物理页分配给多个进程就行了。
但进程内的线程共享的是进程内的同一片地址空间,它们可以相互访问对方的数据,也就是说可以进行篡改,这是不安全的。
任务进程都有自己的执行流,若只有一个执行流,该执行流可以称为主线程,因为其它新线程也都需要通过此主线程创建。
进程是资源的整合体,经调度台送上处理器执行的程序都是线程(即执行流),一切执行流都是线程,因为任何时候进程中都至少存在一个线程。
进程、线程的状态
没啥好说…,共三个状态:就绪、运行、阻塞
进程的身份证 —— PCB
每个进程都有自己的 PCB,所有 PCB 放到一张表格中维护,这就是进程表,调度器根据这张表选择上处理器运行的进程。
实现线程的两种方式 —— 内核或用户进程
在用户空间中实现线程
注意:线程只由用户进程来实现,操作系统中无线程机制。
在用户空间实现线程的好处:可移植性强,由于是用户进程实现,故而在不支持线程的操作系统上页可以完美支持线程。
怎么做:需要实现进程内的线程调度器,还需要自己在进程内维护线程表。
用户进程中,很少有人亲自写线程调度器,因此一般由某个权威机构发布一个用户级的线程包,也就是线程库。
优点:
- 线程的调度算法由用户程序自己实现,可以根据实际应用情况为某些线程加权调度。
- 将线程的寄存器映像转载到 CPU 时,可以在用户空间完成,即不在需要陷入到内核态,这样就免去了进入内核时的入栈及出栈操作。
缺点:
-
进程中某个线程若出现阻塞状态,操作系统并不知道进程中存在线程(因为操作系统不支持线程,因此以进程为调度单位,即认为都是单线程程序),因此会将整个进程挂起,也就是说进程内的所有线程都无法运行。
-
因为目前操作系统的调度单位为进程,因此我们无法将进程中的线程直接送上处理器执行,这是属于进程的家务事,由进程这个大管家负责。
导致的后果:若在用户空间实现线程,但凡进程中的某个线程开始在处理器上执行时,只要该线程不主动退出处理器,此进程的其它线程都没机会运行。简而言之就是在用户空间中实现线程,并没有一套完整的机制去合理的分配线程的执行时间,使其避免单一线程过度使用处理器,而其它线程没有被调度的机会。
解决方案:通过人为控制,调用线程退出相关的函数,例如 pthread_yield 或 pthread_exit 等,使其线程让出处理器的使用权。不是将整个进程的处理器使用权交还给操作系统,而是将使用权交给此进程自己的线程调度器。
-
线程在用户空间实现和内核空间实现相比,只是内部调度时少了陷入内核的代价,这里确实提速了,但由于整个进程的时间片是有限的,在有限的时间下,还需要将时间分配给进程中的线程,因此每个线程执行时间都非常非常短暂,再加上进程内的线程调度器维护线程表、运行调度算法的时间片消耗,反而还抵消了内部调度所带来的提速。
在内核空间中实现线程
注意:内核空间实现线程指的是由内核提供原生线程机制。
优点(相对于用户空间实现线程):
- 内核提供的线程多占了处理器资源。例如线程 A 和单线程 B,A 显示创建 3 个线程,此时 A 共有 4 个线程(加上主线程),加上 B 就有 5 个线程,在内核调度器眼中便是 5 个独立的执行流,尽管其中 4 个进程都属于 A,但这里一样会被内核调度器所调度,因此调度完一圈后,进程 A 占用了 80% 的处理器资源,这才是真正的提速。
- 若进程中某一线程阻塞后,由于是内核空间实现的线程,因此操作系统认识它,所以只会阻塞这一个线程,此线程所在进程并不受到影响。
缺点(相对于用户空间实现线程):用户进程需要通过系统调用陷入内核,这需要进行现场保护,因此会有一些栈操作,会消耗处理器的一些时间,但和优点相比,这不足为惧。
多线程调度
thread/thread.c:
#define PG_SIZE 4096
struct task_struct* main_thread; // 主线程PCB
struct list thread_ready_list; // 就绪队列
struct list thread_all_list; // 所有任务队列
static struct list_elem* thread_tag;// 用于保存队列中的线程结点
extern void switch_to(struct task_struct* cur, struct task_struct* next);
/* 获取当前线程pcb指针 */
struct task_struct* running_thread() {
uint32_t esp;
asm ("mov %%esp, %0" : "=g" (esp));
/* 取esp整数部分即pcb起始地址 */
return (struct task_struct*)(esp & 0xfffff000);
}
// 由 kernel_thread 去执行 function(func_arg)
static void kernel_thread(thread_func* function, void* func_arg) {
// 在执行 function 前要先打开中断,避免后面的时钟中断被屏蔽,而无法调度其它线程
intr_enable();
function(func_arg);
}
// 初始化线程栈 thread_stack, 将待执行的函数和实参放到 thread_stack 中相应的位置
void thread_create(struct task_struct* pthread, thread_func function, void* func_arg) {
// 先预留中断使用栈的空间
pthread -> self_kstack -= sizeof(struct intr_stack);
// 留出线程栈的空间
pthread -> self_kstack -= sizeof(struct thread_stack);
struct thread_stack* kthread_stack = (struct thread_stack*) pthread -> self_kstack;
kthread_stack -> eip = kernel_thread;
kthread_stack -> function = function;
kthread_stack -> func_arg = func_arg;
kthread_stack -> ebp = kthread_stack -> ebx = kthread_stack -> esi = kthread_stack -> edi = 0;
}
// 初始化线程基本信息
void init_thread(struct task_struct* pthread, char* name, int prio) {
memset(pthread, 0, sizeof(*pthread));
strcpy(pthread -> name, name);
if(pthread == main_thread)
pthread -> status = TASK_RUNNING;
else
pthread -> status = TASK_READY;
// self_kstack 是线程自己在内核态下使用的栈顶地址
pthread -> self_kstack = (uint32_t*) ((uint32_t) pthread + PG_SIZE);
pthread -> priority = prio;
pthread -> ticks = prio;
pthread -> elapsed_ticks = 0;
pthread -> pgdir = NULL;
pthread -> stack_magic = 0x19870916; // 自定义的魔数,用于栈边界判断
}
// 创建一个优先级为 prio 的线程,线程名为 name,线程所执行的函数是 function(func_arg)
struct task_struct* thread_start(char* name, int prio, thread_func function, void* func_arg) {
// 申请一页内核空间(内含PCB,这是每个线程必备的)
struct task_struct* thread = get_kernel_pages(1);
init_thread(thread, name, prio);
thread_create(thread, function, func_arg);
/* 确保之前不在队列中 */
ASSERT(!elem_find(&thread_ready_list, &thread->general_tag));
/* 加入就绪线程队列 */
list_append(&thread_ready_list, &thread->general_tag);
/* 确保之前不在队列中 */
ASSERT(!elem_find(&thread_all_list, &thread->all_list_tag));
/* 加入全部线程队列 */
list_append(&thread_all_list, &thread->all_list_tag);
return thread;
}
// 将 kernel 中的 main 函数完善为主线程
static void make_main_thread(void) {
// 因为 main 线程早已运行,在 loader.S 中进入内核时设置 mov esp, 0xc009f000
// 便是为其预留 PCB,地址为 0xc009f00,因此不需要通过 get_kernel_page 另分配一页
main_thread = running_thread();
init_thread(main_thread, "main", 31);
// main 函数是当前线程,当前现在不在 thread_read_list 中
// 所以需要将其加入到 thread_all_list 队列中
ASSERT(!elem_find(&thread_all_list, &main_thread -> all_list_tag));
list_append(&thread_all_list, &main_thread -> all_list_tag);
}
// 任务调度
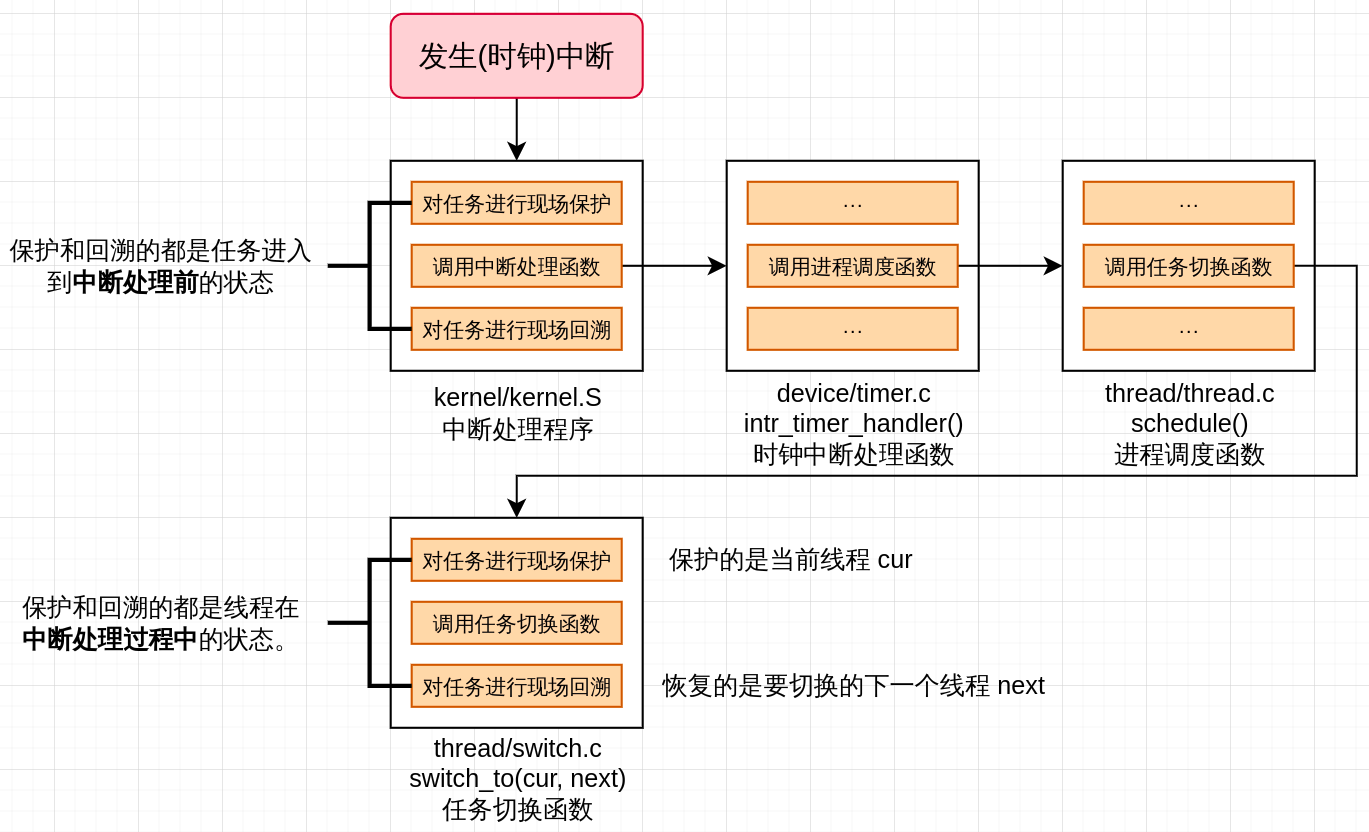
void schedule() {
ASSERT(intr_get_status() == INTR_OFF);
struct task_struct* cur = running_thread(); // 获取当前正在执行的线程的 PCB 地址
if(cur -> status == TASK_RUNNING) { // 判断当前线程的时间片是否到期
ASSERT(!elem_find(&thread_ready_list, &cur -> general_tag));
// 那么就加入就绪队列
list_append(&thread_ready_list, &cur -> general_tag);
cur -> ticks = cur -> priority; // 重置时间片
cur -> status = TASK_READY; // 重置状态为就绪状态
} else {
/* 若此线程需要某事件发生后才能继续上cpu运行,
不需要将其加入队列,因为当前线程不在就绪队列中。
*/
}
ASSERT(!list_empty(&thread_ready_list));
thread_tag = NULL;
// 弹出队列的首元素,准备将其调度上处理器上执行
thread_tag = list_pop(&thread_ready_list);
struct task_struct* next = elem2entry(struct task_struct, general_tag, thread_tag);
next -> status = TASK_RUNNING;
switch_to(cur, next);
}
// 初始化线程环境
void thread_init(void) {
put_str("thread_init start\n");
list_init(&thread_ready_list);
list_init(&thread_all_list);
// 将当前 main 函数创建为线程
make_main_thread();
put_str("thead_init done\n");
}
thread_start() 开启一个线程,并且对其相关结构与数据进行初始化。
make_main_thread() 主线程早已运行,是程序第一个线程,要对主线程进行线程初始化,完善其基本信息。
device/timer.c:
// ...
// 时钟的中断处理函数
static void intr_timer_handler(void) {
struct task_struct* cur_thread = running_thread();
ASSERT(cur_thread -> stack_magic == 0x19870916); // 检查栈是否溢出
cur_thread -> elapsed_ticks++; // 记录此线程占用处理器的总时间数
ticks++; // 用户态和内核态的总时间数
if(cur_thread -> ticks == 0) // 若线程的时间片用完了就开始调度新的进程上处理器
schedule();
else // 将当前线程的时间片 -1
cur_thread -> ticks--;
}
/* 初始化PIT8253 */
void timer_init() {
// ...
register_handler(0x20, intr_timer_handler);
// ...
}
kernel/main.c:
void k_thread_a(void*);
void k_thread_b(void*);
int main(void) {
put_str("I am kernel\n");
init_all();
thread_start("k_thread_a", 31, k_thread_a, "argA ");
thread_start("k_thread_b", 8, k_thread_b, "argB ");
intr_enable(); // 打开中断,使其时钟中断起作用
while(1) put_str("Main ");
return 0;
}
// 在线程中运行的函数
void k_thread_a(void* arg) {
char* para = arg;
while(1) put_str(para);
}
void k_thread_b(void* arg) {
char* para = arg;
while(1) put_str(para);
}
获取当前线程 PCB 首地址的方式 && 队列中的结点与线程的关系
先看如下代码片段 thread/thread.c:
// 创建一个优先级为 prio 的线程,线程名为 name,线程所执行的函数是 function(func_arg)
struct task_struct* thread_start(char* name, int prio, thread_func function, void* func_arg) {
// ...
/* 加入就绪线程队列 */
list_append(&thread_ready_list, &thread->general_tag);
/* 加入全部线程队列 */
list_append(&thread_all_list, &thread->all_list_tag);
return thread;
}
可以发现添加入队列的并不是 struct thread_task 类型,而是 list_elem 类型。
再看来着 lib/kernel/list.h 的代码片段:
#define offset(struct_type,member) (int)(&((struct_type*)0)->member)
#define elem2entry(struct_type, struct_member_name, elem_ptr) \
(struct_type*)((int)elem_ptr - offset(struct_type, struct_member_name))
其中 elem2entry 用于找到当前结点 elem_ptr(这实际上是个 list_elem 类型结点)所属的线程的 PCB 首地址。offset 这个宏用于获取 member 成员属性在 struct_type 结构中的偏移量。
假设 struct_type 的地址为 A,member 的地址为 B,那么 B-A 的差就是 member 距离 struct_type 的偏移量。这样绕一圈回来有点麻烦,那么是否可以直接得到 member 的偏移量呢?是可以的,我们只需要把 struct_type 的地址 A 直接置为 0 即可,就如宏 offset 一样。
得到偏移量后,将 elem_ptr 地址减去得到的偏移量便可得到 elem_ptr 所属的线程对应的 PCB 首地址。
将线程中的 list_elem 代表其线程结点,通过 elem2entry 可以找到对应所属的线程结点,这样做可以大大的节约存储空间。
上面所描述的即是获取线程 PCB 首地址的方式之一,也说明了队列中的结点 list_elem 和线程之间的关系。
而另一种获取当前线程 PCB 的方式是通过 0xFFFFF000 & (&(PCB.general_tag)),代码如下 thread/thread.c:
/* 获取当前线程pcb指针 */
struct task_struct* running_thread() {
uint32_t esp;
asm ("mov %%esp, %0" : "=g" (esp));
/* 取esp整数部分即pcb起始地址 */
return (struct task_struct*)(esp & 0xfffff000);
}
图解














 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









