






一、ipv6的分级地址
我们都知道ipv6的地址是非常长的,那么这些地址段都代表什么意思呢?
在我们的ipv6中扩展了地址的分级概念,一共是有三个等级。
第一级,也叫做顶级,指明全球都知道的公共拓扑。
第二级,也叫做地点级,指明单个的地点。
第三级,指明单个的网络接口
二、dhcpv6
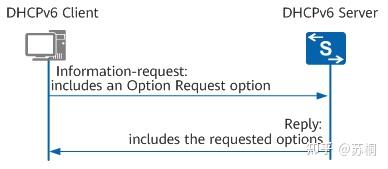
首先我们要知道什么是dhcpv6,dhcpv6是一种运行在客户端和服务器之间的协议,和ipv4中的dhcp一样,它们的所有报文都是基于UDP的,但是在dhcp中,报文是通过广播包进行传播的,在ipv6中没有广播报文,所以dhcpv6通过组播的方式来发送报文,客户端也不需要配置服务器的ipv6地址。
1、dhcpv6分配类型
在ipv4的dhcp中我们都知道,ipv4的地址分配分为三种,既手工分配地址、自动分配地址以及动态分配地址,那么在ipv6的dhcpv6中地址分配也是分为三种,接下来我们详细介绍这三种分配方式。
1、手动配置
这里的手动配置和ipv4的手工分配地址相似,既手动配置ipv6地址/前缀及其它的网络配置参数(DNS、NIS、SNTP服务器地址等参数)。
2、无状态自动分配地址
无状态自动分配地址是由接口ID生成链路本地地址,再根据路由通告报文RA包含的前缀信息自动配置本机地址。
在站点不要求主机使用精确的地址时,只要这个地址是唯一的,并且是可路由的,就使用无状态自动分配地址的方式。
它的特点就是不可控、难管理。在网络中只有网关,没有IP地址管理者。因此无人去识别客户端,每个客户端根据网关发送的相同RA报文内容,自行配置ipv6地址。
无状态地址自动配置的工作原理
无状态地址自动配置要求本地链路支持组播,而且网络接口能发送和接受组播包。
一个典型的ipv6主机单播地址由三部分组成:全局路由前缀、子网ID和64位接口ID。全局路由前缀通过路由宣告消息得到;子网ID又称为子网前缀,节点通过前缀发现机制来确定链路本地地址的子网前缀;64位接口ID由主机自动生成。
获得接口ID
在无状态地址自动配置方式下,接口ID由48位的mac地址转换得到,IEEE已经将网卡mac地址由48位改为64位,这个64位的mac地址通常就是接口ID,如果主机的网卡mac地址仍然是48位,则根据IEEE定义的eui
64转换算法得到。
获得链路本地单播地址
子网ID与接口ID构成链路本地单播地址,主机向该地址发出一个邻居发现请求,以验证该地址的唯一性。如果请求没有得到相应,则表明这个地址是卫衣的,否则,主机将使用一个随机产生的接口ID,与子网ID重新组成一个新的链路本地单播地址。
获得全局路由前缀
网络节点为获得全局路由前缀,以链路本地单播地址为源地址,向与它项链的所有路由器发出路由器请求消息,路由器收到网络节点的RS消息后,向该节点会送路由器宣告消息,消息的选项字段给出全局路由前缀。
网络节点在获得全局路由前缀后,与接口ID结合形成它的全局ipv6地址,这个地址全球唯一。至此,网络节点的无状态地址自动配置过程结束,就可以与互联网中的其它主机通信了。
3、有状态自动分配地址
当站点严格控制地址分配的时候,我们就可以使用有状态地址自动配置方式。
在有状态自动分配地址的方式下,主要是采用dhcp,需要配置一个专门的dhcp服务器。网络接口通过客户机/服务器模式从dhcp服务器处得到地址配置信息,dhcp服务器中维护着一个数据库,记录着主机和地址的分配信息。dhcpv6服务器会自动分配ipv6地址/pd前缀及其它的网络配置参数。
有状态自动分配地址的工作原理
在有状态自动分配地址的过程中分为两类,一个是dhcpv6四步交互分配过程,dhcpv6两步交互快速分配过程
dhcpv6四步交互
四步交互常用于网络中有多个DHCPv6服务器的情况。DHCPv6客户端首先通过组播发送Solicit报文来定位可以为其提供服务的DHCPv6服务器,在收到多个DHCPv6服务器的Advertise报文后,根据DHCPv6服务器的优先级选择一个为其分配地址和配置信息的服务器,接着通过Request/Reply报文交互完成地址申请和分配过程。
DHCPv6服务器端如果没有配置使能两步交互,无论客户端报文中是否包含Rapid
Commit选项,服务器都采用四步交互方式为客户端分配地址和配置信息。
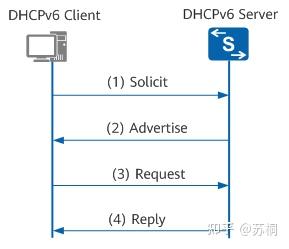
DHCPv6四步交互地址分配过程如下:
1、DHCPv6客户端发送Solicit报文,请求DHCPv6服务器为其分配IPv6地址和网络配置参数。
2、如果Solicit报文中没有携带Rapid Commit选项,或Solicit报文中携带Rapid
Commit选项,但服务器不支持快速分配过程,则DHCPv6服务器回复Advertise报文,通知客户端可以为其分配的地址和网络配置参数。
3、如果DHCPv6客户端接收到多个服务器回复的Advertise报文,则根据Advertise报文中的服务器优先级等参数,选择优先级最高的一台服务器,并向所有的服务器发送Request组播报文,该报文中携带已选择的DHCPv6服务器的DUID。
4、DHCPv6服务器回复Reply报文,确认将地址和网络配置参数分配给客户端使用。
dhcpv6两步交互
两步交互常用于网络中只有一个DHCPv6服务器的情况。DHCPv6客户端首先通过组播发送Solicit报文来定位可以为其提供服务的DHCPv6服务器,DHCPv6服务器收到客户端的Solicit报文后,为其分配地址和配置信息,直接回应Reply报文,完成地址申请和分配过程。
两步交换可以提高DHCPv6过程的效率,但在有多个DHCPv6服务器的网络中,多个DHCPv6服务器都可以为DHCPv6客户端分配IPv6地址,回应Reply报文,但是客户端实际只可能使用其中一个服务器为其分配的IPv6地址和配置信息。为了防止这种情况的发生,管理员可以配置DHCPv6服务器是否支持两步交互地址分配方式。
DHCPv6服务器端如果配置使能了两步交互,并且客户端报文中也包含Rapid
Commit选项,服务器采用两步交互方式为客户端分配地址和配置信息。
如果DHCPv6服务器不支持快速分配地址,则采用四步交互方式为客户端分配IPv6地址和其他网络配置参数。
\

DHCPv6两步交互地址分配过程如下:
1、DHCPv6客户端在发送的Solicit报文中携带Rapid
Commit选项,标识客户端希望服务器能够快速为其分配地址和网络配置参数。
2、DHCPv6服务器接收到Solicit报文后,将进行如下处理:
如果DHCPv6服务器支持快速分配地址,则直接返回Reply报文,为客户端分配IPv6地址和其他网络配置参数,Reply报文中也携带Rapid
Commit选项。
如果DHCPv6服务器不支持快速分配过程,则采用四步交互方式为客户端分配IPv6地址/前缀和其他网络配置参数。
4、dhcpv6的基础配置
设备DUID的配置
学习dhcpv6的配置,首先我们要知道一个关键的知识点,叫做DUID既设备唯一标识符。
DUID是dhcpv6设备的唯一标识符,每个服务器或客户端有且只有一个唯一的标识符,服务器使用DUID来识别不同的客户端,客户端则使用DUID来识别服务器。
DUID会采用以下两种方式生成:
基于链路层地址(LL):即采用链路层地址的方式来生成DUID。
基于链路层地址和时间组合(LLT):既采用链路层地址和时间组合方式来生成DUID。
那么在我们设备的缺省配置中设备的DUID是以LL的方式生成的。
执行命令dhcpv6 duid { ll | llt },配置设备DUID。
ipv6地址池的配置
DHCPv6服务器需要从地址池中选择合适的IPv6地址分配给DHCPv6客户端,用户需要创建地址池并配置IPv6地址池的相关属性,包括地址范围、配置信息刷新时间、不参与自动分配的IPv6地址以及静态绑定的IPv6地址。根据客户端的实际需要,IPv6地址分配方式可以选择动态分配或静态绑定方式。
执行命令dhcpv6 pool
{pool-name(地址池的名字)},创建IPv6地址池,同时进入IPv6地址池视图。
在缺省情况下,设备上是没有创建任何的ipv6地址池的。
有状态方式创建地址池
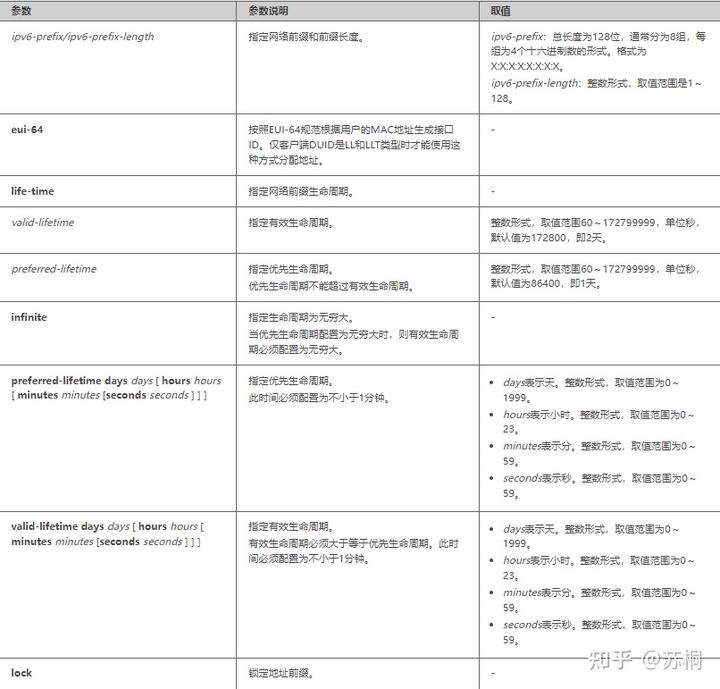
当需要DHCPv6服务器以DHCPv6有状态方式自动分配网络参数时,执行命令address
prefix {ipv6-prefix/ipv6-prefix-length(ipv6的前缀和长度)} [ eui-64 ]
[ life-time { valid-lifetime(有效生存周期) | infinite } {
preferred-lifetime(首选生存周期) | infinite }
],在IPv6地址池视图下配置网络前缀和生命周期。缺省情况下,IPv6地址池视图下未配置网络前缀和生命周期。
详细参数说明可以参考下图
无状态方式创建地址池
当需要DHCPv6服务器以DHCPv6无状态方式自动分配网络参数时,执行命令link-address
{ipv6-prefix/ipv6-prefix-length(网络前缀及长度)},在IPv6地址池视图下配置网络前缀。缺省情况下,IPv6地址池视图下未配置网络前缀。DHCPv6服务器通过配置的网络前缀来确定该地址池要为哪个网段的客户端分配网络参数。
使能dhcpv6服务器
参数配置完成后,我们需要将dhcpv6的服务给使能,使能就非常简单了
接口视图下使能dhcpv6服务器
执行命令system-view,进入系统视图。
执行命令dhcp enable,使能DHCP服务。
执行命令ipv6,全局使能IPv6功能。
执行命令interface {interface-type
interface-number(接口类型,接口编号)},进入接口视图。
(可选)对于以太网接口,执行命令undo
portswitch,配置接口切换到三层模式。
缺省情况下,以太网接口处于二层模式。
执行命令ipv6 enable,接口下使能IPv6服务。执行命令ipv6 address {
ipv6-address prefix-length
|ipv6-address/prefix-length(指定接口的ipv6地址)
},配置接口的全球单播IPv6地址。
执行命令dhcpv6 server {pool-name(地址池名字)} [ allow-hint |
preference {preference-value(优先级)} | rapid-commit | unicast ]
*,接口下使能DHCPv6服务器功能。
缺省情况下,接口下DHCPv6服务器功能处于未使能状态。
系统视图下使能dhcpv6服务器
执行命令system-view,进入系统视图。
执行命令dhcp enable,使能DHCP服务。
执行命令ipv6,全局使能IPv6功能。
(可选)执行命令dhcpv6 server { allow-hint | preference
{preference-value(优先级)} | rapid-commit | unicast }
*,在系统视图下配置DHCPv6服务器的行为。
缺省情况下,系统视图下未配置DHCPv6服务器的行为。
设备作为DHCPv6服务器时,可能配置了多个IPv6地址池,DHCPv6服务器接收到DHCPv6请求报文后,选择IPv6地址池的原则如下:
对于存在中继的场景,根据报文中第一个不为0的"link-address"字段(标识DHCPv6客户端所在链路范围),选择与地址池中已配置的网络前缀(执行命令link-address)或IPv6地址前缀(执行命令address
prefix)属于同一链路范围的地址池。
在系统视图下使能DHCPv6服务器时,对于不存在中继的场景,不支持以DHCPv6无状态方式为客户端分配网络参数。
针对缺省采用IPv6协议路由通告方式自动获取IPv6地址的客户端(例如PC),还需要在客户端的网关上配置RA消息的标志位,以实现客户端通过DHCPv6方式获取IPv6地址。
不存在DHCPv6中继的场景,且设备作为客户端的网关时
执行命令system-view,进入系统视图。
执行命令interface {interface-type
interface-number(接口类型,接口编号)},进入接口视图。
执行命令undo ipv6 nd ra
halt,使能设备发布RA报文功能。缺省情况下,RA报文的发送开关处于未打开状态。
执行命令ipv6 nd autoconfig
managed-address-flag,配置RA报文中的有状态自动配置地址的标志位。缺省情况下,未配置RA报文中的有状态自动配置地址的标志位。
执行命令ipv6 nd autoconfig
other-flag,配置RA报文中的有状态自动配置其他信息的标志位。缺省情况下,未配置RA报文中的有状态配置其他信息的标志位。配置RA报文中的有状态自动配置地址的标志位和有状态配置其他信息的标志位后,客户端可以通过DHCPv6方式获取IPv6地址。
5、ipv6 over ipv4隧道技术
IPv6 over
IPv4隧道可实现IPv6网络孤岛之间通过IPv4网络互连。由于IPv4地址的枯竭和IPv6的先进性,IPv4过渡为IPv6势在必行。因为IPv6与IPv4的不兼容性,所以需要对原有的IPv4设备进行替换。但是如果贸然将IPv4设备大量替换所需成本会非常巨大,且现网运行的业务也会中断,显然并不可行。所以,IPv4向IPv6过渡是一个渐进的过程。在过渡初期,IPv4网络已经大量部署,而IPv6网络只是散落在各地的"孤岛",IPv6
over
IPv4隧道就是通过隧道技术,使IPv6报文在IPv4网络中传输,实现IPv6网络之间的孤岛互连。
首先我们先介绍一下这几种隧道技术
双协议栈
双栈技术是IPv4向IPv6过渡的一种有效的技术。网络中的节点同时支持IPv4和IPv6协议栈,源节点根据目的节点的不同选用不同的协议栈,而网络设备根据报文的协议类型选择不同的协议栈进行处理和转发。双栈可以在一个单一的设备上实现,也可以是一个双栈骨干网。对于双栈骨干网,其中的所有设备必须同时支持IPv4/IPv6协议栈,连接双栈网络的接口必须同时配置IPv4地址和IPv6地址。单协议栈和双协议栈结构示例如下图所示。
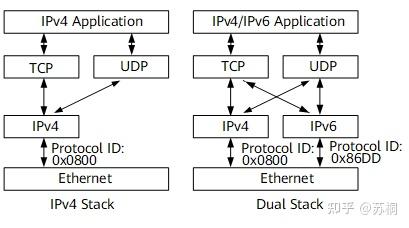
双协议栈具有以下特点:
多种链路协议支持双协议栈多种链路协议(如以太网)支持双协议栈。图中的链路层是以太网,在以太网帧上,如果协议ID字段的值为0x0800,表示网络层收到的是IPv4报文,如果为0x86DD,表示网络层是IPv6报文。
多种应用支持双协议栈多种应用(如DNS/FTP/Telnet等)支持双协议栈。上层应用(如DNS)可以选用TCP或UDP作为传输层的协议,但优先选择IPv6协议栈,而不是IPv4协议栈作为网络层协议。
下图为双协议栈的一个典型应用场景
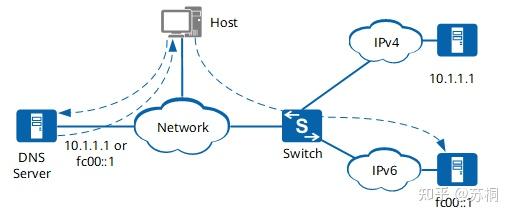
如图所示,主机向DNS服务器发送DNS请求报文,请求域名http://www.example.com对应的IP地址。DNS服务器将回复该域名对应的IP地址。如图所示,该IP地址可能是10.1.1.1或fc00::1。主机系统发送A类查询,则向DNS服务器请求对应的IPv4地址;系统发送AAAA查询,则向DNS服务器请求对应的IPv6地址。
图中Switch支持双协议栈功能。如果主机访问IPv4地址为10.1.1.1的网络服务器,则可以通过Switch的IPv4协议栈访问目标节点。如果主机访问IPv6地址为fc00::1的网络服务器,则可以通过Switch的IPv6协议栈访问目标节点。
IPv6 over IPv4隧道
隧道(Tunnel)是一种封装技术。它利用一种网络协议来传输另一种网络协议,即利用一种网络传输协议,将其他协议产生的数据报文封装在自身的报文中,然后在网络中传输。隧道是一个虚拟的点对点的连接。一个Tunnel提供了一条使封装的数据报文能够传输的通路,并且在一个Tunnel的两端可以分别对数据报文进行封装及解封装。隧道技术就是指包括数据封装、传输和解封装在内的全过程。隧道技术是IPv6向IPv4过渡的一个重要手段。
由于IPv4地址的枯竭和IPv6的先进性,IPv4过渡为IPv6势在必行。因为IPv6与IPv4的不兼容性,所以需要对原有的IPv4设备进行替换。但是IPv4设备大量替换所需成本会非常巨大,且现网运行的业务也会中断,显然并不可行。所以,IPv4向IPv6过渡是一个渐进的过程。在过渡初期,IPv4网络已经大量部署,而IPv6网络只是散落在各地的"孤岛",IPv6
over
IPv4隧道就是通过隧道技术,使IPv6报文在IPv4网络中传输,实现IPv6网络之间的孤岛互连。
下图为IPv6 over IPv4 隧道技术的基本原理
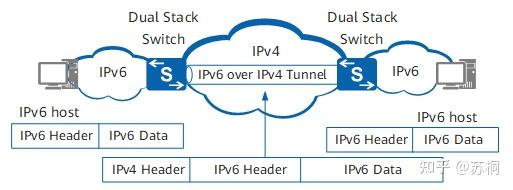
1、边界设备启动IPv4/IPv6双协议栈,并配置IPv6 over IPv4隧道。
2、边界设备在收到从IPv6网络侧发来的报文后,如果报文的目的地址不是自身且下一跳出接口为Tunnel接口,就要把收到的IPv6报文作为数据部分,加上IPv4报文头,封装成IPv4报文。
3、在IPv4网络中,封装后的报文被传递到对端的边界设备。
4、对端边界设备对报文解封装,去掉IPv4报文头,然后将解封装后的IPv6报文发送到IPv6网络中。一个隧道需要有一个起点和一个终点,起点和终点确定了以后,隧道也就可以确定了。IPv6
over
IPv4隧道的起点的IPv4地址必须为手工配置,而终点的确定有手工配置和自动获取两种方式。根据隧道终点的IPv4地址的获取方式不同可以将IPv6
over IPv4隧道分为手动隧道和自动隧道。
手动隧道:手动隧道即边界设备不能自动获得隧道终点的IPv4地址,需要手工配置隧道终点的IPv4地址,报文才能正确发送至隧道终点。
自动隧道:自动隧道即边界设备可以自动获得隧道终点的IPv4地址,所以不需要手工配置终点的IPv4地址,一般的做法是隧道的两个接口的IPv6地址采用内嵌IPv4地址的特殊IPv6地址形式,这样路由设备可以从IPv6报文中的目的IPv6地址中提取出IPv4地址。
根据IPv6报文封装的不同,手动隧道又可以分为IPv6 over IPv4手动隧道和IPv6
over IPv4 GRE隧道两种。
IPv6 over IPv4手动隧道
手动隧道直接把IPv6报文封装到IPv4报文中去,IPv6报文作为IPv4报文的净载荷。手动隧道的源地址和目的地址也是手工指定的,它提供了一个点到点的连接。手动隧道可以建立在两个边界路由器之间为被IPv4网络分离的IPv6网络提供稳定的连接,或建立在终端系统与边界路由器之间为终端系统访问IPv6网络提供连接。隧道的边界设备必须支持IPv6/IPv4双协议栈。其它设备只需实现单协议栈即可。因为手动隧道要求在设备上手工配置隧道的源地址和目的地址,如果一个边界设备要与多个设备建立手动隧道,就需要在设备上配置多个隧道,配置比较麻烦。所以手动隧道通常用于两个边界路由器之间,为两个IPv6网络提供连接。
IPv6 over IPv4手动隧道封装格式如下图所示。
 {.content_image
{.content_image
caption=“” rawheight=“39” rawwidth=“417” data-size=“normal” width=“417”}
IPv6 over
IPv4手动隧道转发机制为:当隧道边界设备的IPv6侧收到一个IPv6报文后,
根据IPv6报文的目的地址查找IPv6路由转发表,如果该报文是从此虚拟隧道接口转发出去,则根据隧道接口配置的隧道源端和目的端的IPv4地址进行封装。封装后的报文变成一个IPv4报文,交给IPv4协议栈处理。报文通过IPv4网络转发到隧道的终点。隧道终点收到一个隧道协议报文后,进行隧道解封装。并将解封装后的报文交给IPv6协议栈处理。
IPv6 over IPv4 GRE隧道
IPv6 over IPv4
GRE隧道使用标准的GRE隧道技术提供了点到点连接服务,需要手工指定隧道的端点地址。GRE隧道本身并不限制被封装的协议和传输协议,一个GRE隧道中被封装的协议可以是协议中允许的任意协议(可以是IPv4、IPv6、OSI、MPLS等)。
IPv6 over IPv4 GRE隧道封装和传输过程如下图所示。
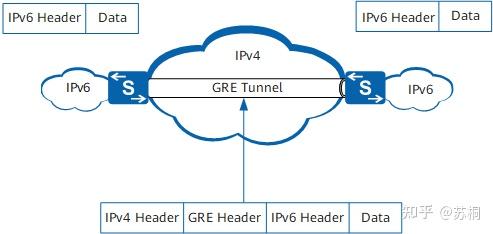
IPv6 over IPv4 GRE隧道的在隧道的边界路由器的传输机制和IPv6 over
IPv4手动隧道相同。
自动隧道
自动隧道中,用户仅需要配置设备隧道的起点,隧道的终点由设备自动生成。为了使设备能够自动产生终点,隧道接口的IPv6地址采用内嵌IPv4地址的特殊IPv6地址形式。设备从IPv6报文中的目的IPv6地址中解析出IPv4地址,然后以这个IPv4地址代表的节点作为隧道的终点。
根据IPv6报文封装的不同,自动隧道又可以分为6to4隧道和ISATAP隧道两种。
6to4隧道
6to4隧道也属于一种自动隧道,隧道也是使用内嵌在IPv6地址中的IPv4地址建立的。与IPv4兼容自动隧道不同,6to4自动隧道支持Router到Router、Host到Router、Router到Host、
Host到Host。这是因为6to4地址是用IPv4地址做为网络标识,其地址格式如下图所示。

- FP:可聚合全球单播地址的格式前缀(Format Prefix),其值为001。
- TLA:顶级聚合标识符(Top Level Aggregator),其值为0x0002。
- SLA:站点级聚合标识符(Site Level Aggregator)。
6to4地址可以表示为2002::/16,而一个6to4网络可以表示为2002:IPv4地址::/48。6to4地址的网络前缀长度为64bit,其中前48bit(2002:
a.b.c.d)被分配给路由器上的IPv4地址决定了,用户不能改变,而后16位(SLA)是由用户自己定义的。6to4隧道的封装和转发过程如下图所示。
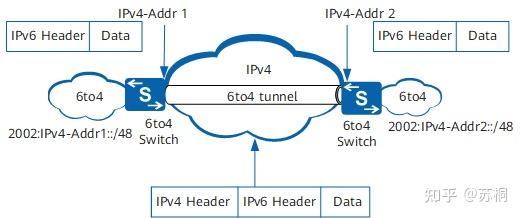
一个IPv4地址只能用于一个6to4隧道的源地址,如果一个边界设备连接了多个6to4网络使用同样的IPv4地址作为隧道的源地址,则使用6to4地址中的SLA
ID来区分,但这些6to4网络共用一个隧道。如下图所示。

ISATAP隧道
ISATAP(Intra-Site Automatic Tunnel Addressing
Protocol)是另外一种自动隧道技术。ISATAP隧道同样使用了内嵌IPv4地址的特殊IPv6地址形式,只是和6to4不同的是,6to4是使用IPv4地址做为网络前缀,而ISATAP用IPv4地址做为接口标识。其接口标识符格式如下图所示。

如果IPv4地址是全局唯一的,则u位为1,否则u位为0。g位是IEEE群体/个体标志。由于ISATAP是通过接口标识来表现的,所以,ISATAP地址有全局单播地址、链路本地地址、ULA地址、组播地址等形式。ISATAP地址的前64位是通过向ISATAP路由器发送请求来得到的,它可以进行地址自动配置。在ISATAP隧道的两端设备之间可以运行ND协议。ISATAP隧道将IPv4网络看作一个非广播的点到多点的链路(NBMA)。
ISATAP过渡机制允许在现有的IPv4网络内部署IPv6,该技术简单而且扩展性很好,可以用于本地站点的过渡。ISATAP支持IPv6站点本地路由和全局IPv6路由域,以及自动IPv6隧道。ISATAP同时还可以与NAT结合,从而可以使用站点内部非全局唯一的IPv4地址。典型的ISATAP隧道应用是在站点内部,所以,其内嵌的IPv4地址不需要是全局唯一的。
下图为ISATAP隧道一个典型应用场景。
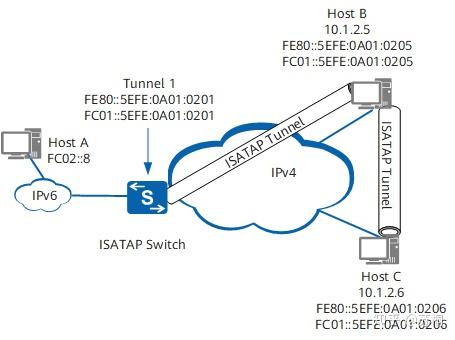
如上图所示,在IPv4网络内部有两个双栈主机Host B和Host
C,它们分别有一个私网IPv4地址。要使其具有ISATAP功能,需要进行如下操作:
首先配置ISATAP隧道接口,这时会根据IPv4地址生成ISATAP类型的接口ID。
根据接口ID生成一个ISATAP链路本地IPv6地址,生成链路本地地址以后,主机就有了在本地链路上进行IPv6通信的能力。
进行自动配置,主机获得IPv6全球单播地址、ULA地址等。
当主机与其它IPv6主机进行通讯时,从隧道接口转发,将从报文的下一跳IPv6地址中取出IPv4地址作为IPv4封装的目的地址。如果目的主机在本站点内,则下一跳就是目的主机本身,如果目的主机不在本站点内,则下一跳为ISATAP路由器的地址。
6PE
6PE是一种IPv4到IPv6的过渡技术,ISP可以利用已有的IPv4骨干网为分散用户的IPv6网络提供接入能力。6PE的主要思想是:IPv6供应商边缘6PE(IPv6
Provider
Edge)设备将用户的IPv6路由信息转换为带有标签的IPv6路由信息,并且通过内部边界网关协议IBGP(Internal
Border Gateway
Protocol)会话扩散到ISP的IPv4骨干网中。6PE设备转发IPv6报文时,首先会将进入骨干网隧道的数据流打上标签。隧道可以是GRE隧道或者MPLS
LSP等。当ISP想利用自己原有的IPv4或MPLS网络,使其通过MPLS具有IPv6能力时,只需要升级PE设备。所以对于运营商来说,使用6PE技术作为IPv6过渡机制是一个高效的解决方案。
6PE的典型组网图如下图所示。
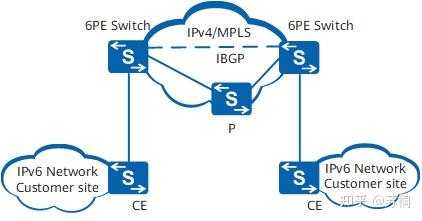
配置ipv4/ipv6双协议栈
实际上在ipv6 over
ipv4中几种隧道的配置方式都大差不大,下面来详细介绍一下。
使能ipv6报文转发能力
如果要使能接口对IPv6报文进行转发的功能,必须同时使能系统视图下和接口视图下的IPv6功能。
执行命令system-view,进入系统视图。
执行命令ipv6,使能IPv6报文转发能力。缺省情况下,设备不使能对IPv6报文的转发能力。如果要对IPv6报文进行转发,必须先在系统视图下使能设备的IPv6报文转发能力。否则即使在接口上配置有IPv6地址,设备无法转发IPv6的报文。
执行命令interface {interface-type
interface-number(接口类型,接口编号)},进入需要使能IPv6功能的接口视图。
执行命令ipv6
enable,使能接口的IPv6功能。如果要在接口视图下进行IPv6的相关配置,必须先在接口视图下使能IPv6功能。缺省情况下,接口下不使能IPv6功能。
使能配置接口的ipv4和ipv6地址
需要使能双协议栈的设备必须在IPv4网络侧和IPv6网络侧分别配置IPv4地址和IPv6地址。
执行命令system-view,进入系统视图。
执行命令interface vlanif
{vlan-id(vlan编号)},进入IPv4网络侧的接口视图。
执行命令ip address {ip-address { mask | mask-length
(掩码或掩码长度)}},配置接口的IPv4地址。
执行命令quit,返回系统视图。
执行命令interface vlanif
{vlan-id(vlan编号)},进入IPv6网络侧的接口视图。
请根据不同情况进行以下配置。
配置接口的自动链路本地地址,请执行命令ipv6 address auto link-local。
配置接口的自定义链路本地地址,请执行命令ipv6 address
{ipv6-address(v6的地址)} link-local。
配置接口的全球单播地址,请执行命令ipv6 address { ipv6-address
prefix-length |
ipv6-address/prefix-length(指定接口的ipv6地址及前缀长度) }。
配置接口的IPv6 EUI-64格式地址,请执行命令ipv6 address { ipv6-address
prefix-length | ipv6-address/prefix-length
(指定接口的ipv6地址及前缀长度)} eui-64。
配置IPv6 over IPv4隧道模式
在配置ipv6 over
ipv4隧道模式前需要隧道的源端交换机和目的端交换机上必须同时存在转发路由。
配置前还需要先行配置ipv4/ipv6双协议栈,以及业务环回聚合接口。
ipv6 over ipv4手动隧道
配置IPv6 over IPv4手动隧道时,请注意以下情况:
创建Tunnel接口,然后才能配置Tunnel的其他参数。
当指定的Tunnel源接口是物理接口时,建议Tunnel的编号与Tunnel的源物理接口的编号相同。
在Tunnel两端的设备上都需要进行下列配置。
在边界设备与IPv6网络相连的接口上必须配置IPv6地址,在边界设备与IPv4网络相连的接口上必须配置IPv4地址。为了支持动态路由协议,也需要配置Tunnel接口的网络地址。
执行命令system-view,进入系统视图。
执行命令interface tunnel
{interface-number(接口名称、序号)},创建Tunnel接口。
执行命令tunnel-protocol ipv6-ipv4,指定Tunnel为手动隧道模式。
执行命令eth-trunk
{trunk-id(聚合口ID编号)},将当前接口加入到指定Eth-Trunk中。
执行命令source { ip-address | interface-type interface-number
(源地址或者原接口编号)},指定Tunnel的源地址或源接口。
执行命令destination
{dest-ip-address(目的地址)},指定Tunnel的目的地址。
Tunnel的目的地址可以是物理接口地址,也可以是Loopback接口的地址。
执行命令ipv6 enable,使能接口的IPv6功能。
执行命令ipv6 address { ipv6-address prefix-length |
ipv6-address/prefix-length
(ipv6地址及前缀长度)},设置Tunnel接口的IPv6地址。
此时指定的Tunnel接口的IPv6地址的前缀,应该与边界设备所属的IPv6网络的地址前缀相同。
ipv6 over ipv4 GRE隧道
配置ipv6 over ipv4
GRE隧道前需要注意隧道的源端交换机和目的端交换机上必须同时存在转发路由。
在配置ipv6 over ipv4
GRE隧道前同样需要先行配置ipv4/ipv6双协议栈及业务环回聚合接口。
配置IPv6 over IPv4 GRE隧道时,需要注意以下情况:
创建Tunnel接口,然后才能配置Tunnel的其他参数。
当指定的Tunnel源接口是物理接口时,建议Tunnel的编号与Tunnel的源物理接口的编号相同。
在Tunnel两端的设备上都需要进行下列配置。
在边界设备与IPv6网络相连的接口上必须配置IPv6地址,在边界设备与IPv4网络相连的接口上必须配置IPv4地址。为了支持动态路由协议,也需要配置Tunnel接口的网络地址。
执行命令system-view,进入系统视图。
执行命令interface tunnel {interface-number(接口名)},创建Tunnel接口。
执行命令tunnel-protocol GRE,指定Tunnel为GRE隧道模式。
执行命令eth-trunk
{trunk-id(聚合口ID编号)},将当前接口加入到指定Eth-Trunk中。
执行命令source { ip-address | interface-type
interface-number(源地址或源接口) },指定Tunnel的源地址或源接口。
执行命令destination
{dest-ip-address(目的地址)},指定Tunnel的目的地址。
Tunnel的目的地址可以是物理接口地址,也可以是Loopback接口的地址。
执行命令ipv6 enable,使能接口的IPv6功能。
执行命令ipv6 address { ipv6-address prefix-length |
ipv6-address/prefix-length
(ipv6地址及前缀长度)},设置Tunnel接口的IPv6地址。
此时指定的Tunnel接口的IPv6地址的前缀,应该与边界设备所属的IPv6网络的地址前缀相同。
配置6to4隧道
配置6to4隧道时,请注意以下情况:
创建Tunnel接口,然后才能配置Tunnel的其他参数。
当指定的Tunnel源接口是物理接口时,建议Tunnel的编号与Tunnel的源物理接口的编号相同。
在配置6to4隧道时,只需确定Tunnel的源,Tunnel的目的地址是从原始的IPv6报文的目的地址中获取的。但两个6to4隧道的源不允许相同。
在边界设备与IPv6网络相连的接口上必须配置IPv6地址,在边界设备与IPv4网络相连的接口上必须配置IPv4地址。为了支持动态路由协议,也需要配置Tunnel接口的网络地址。
执行命令system-view,进入系统视图。
执行命令interface tunnel {interface-number(接口名)},创建Tunnel接口。
执行命令tunnel-protocol ipv6-ipv4 6to4,指定Tunnel为6to4隧道模式。
执行命令eth-trunk
{trunk-id(聚合口ID编号)},将当前接口加入到指定Eth-Trunk中。
执行命令source { source-ip-address | interface-type interface-number
(源地址或源接口)},指定Tunnel的源地址或源接口。
执行命令ipv6 enable,使能接口的IPv6功能。
执行命令ipv6 address { ipv6-address prefix-length |
ipv6-address|prefix-length
(ipv6地址及前缀长度)},设置Tunnel接口的IPv6地址。
此时指定的Tunnel接口的IPv6地址的前缀,应该与边界设备所属的IPv6网络的地址前缀相同。
配置ISATAP隧道
配置ISATAP隧道时,请注意以下情况:
创建Tunnel接口,然后才能配置Tunnel的其他参数。
当指定的Tunnel源接口是物理接口时,建议Tunnel的编号与Tunnel的源物理接口的编号相同。
在边界设备与IPv6网络相连的接口上必须配置IPv6地址,在边界设备与IPv4网络相连的接口上必须配置IPv4地址。为了支持动态路由协议,也需要配置Tunnel接口的网络地址。在Tunnel接口上的配置IPv6地址为ISATAP地址,前缀长度为64。
执行命令system-view,进入系统视图。
执行命令interface tunnel {interface-number(接口名)},创建Tunnel接口。
执行命令tunnel-protocol ipv6-ipv4 isatap,指定Tunnel为ISATAP模式。
执行命令eth-trunk
{trunk-id(聚合口ID编号)},将当前接口加入到指定Eth-Trunk中。
执行命令source { source-ip-address | interface-type interface-number
(源地址或源接口)},指定Tunnel的源地址或源接口。
执行命令ipv6 enable,使能接口的IPv6功能。
执行命令ipv6 address { ipv6-address prefix-length |
ipv6-address/prefix-length (ipv6地址及前缀长度)}
eui-64,设置Tunnel接口的IPv6地址。
执行命令undo ipv6 nd ra halt,允许发布路由器通告消息。
6、ipv4 over ipv6隧道技术
ipv4 over ipv6隧道
在IPv4 Internet向IPv6
Internet过渡的后期,IPv6网络已被大量部署,此时可能出现IPv4孤岛。利用隧道技术可在IPv6网络上创建隧道,从而实现IPv4孤岛的互连。这类似于在IP网络上利用隧道技术部署VPN。在IPv6网络上用于连接IPv4孤岛的隧道,称为IPv4
over IPv6隧道。
IPv4 over IPv6隧道的原理如下图所示
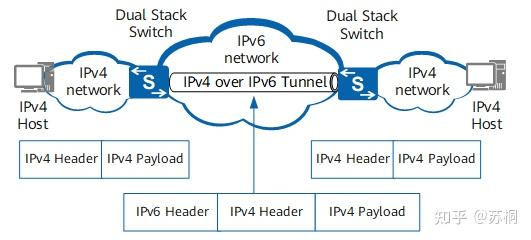
1、边界设备启动IPv4/IPv6双协议栈,并配置IPv4 over IPv6隧道。
2、边界设备在收到从IPv4网络侧发来的报文后,如果报文的目的地址不是自身,就要把收到的IPv4报文作为负载,加上IPv6报文头,封装到IPv6报文里。
3、在IPv6网络中,封装后的报文被传递到对端的边界设备。
4、对端边界设备对报文解封装,去掉IPv6报文头,然后将解封装后的IPv4报文发送到IPv4网络。
配置业务环回聚合接口
配置业务环回聚合接口时,请注意以下情况:在整个设备上只需要一个业务环回聚合接口。此处做业务环回聚合的接口必须是空闲的,没有承载业务的接口。
执行命令system-view,进入系统视图。
执行命令interface eth-trunk
{trunk-id(聚合口ID编号)},进入Eth-Trunk接口视图。
执行命令service type tunnel,指定该接口为业务环回聚合接口。
同一Eth-Trunk接口下service type tunnel命令不能与URPF功能同时配置。
使能业务环回聚合接口功能的Eth-Trunk接口,其STP功能自动去使能。去使能Eth-Trunk接口的业务环回聚合接口功能后,STP功能自动使能。
执行命令quit,返回系统视图。
执行命令interface {interface-type
interface-number(接口口编号)},进入接口视图。
执行命令eth-trunk
{trunk-id(聚合口编号)},将当前接口加入到指定Eth-Trunk中。
配置Tunnel接口
配置Tunnel接口信息包括隧道的协议类型、源地址、目的地址和隧道接口的IP地址,从而建立起一条IPv4
over IPv6隧道。
目前由于设备不支持对IPv4 over
IPv6隧道中传输的报文进行分片,所以配置Tunnel接口的IPv4的MTU时需要满足如下条件:
Tunnel接口的IPv4的MTU < (物理口的IPv6的MTU - IPv4 over
IPv6隧道报文中IPv6报文头长度)
执行命令system-view,进入系统视图。
执行命令interface tunnel
{interface-number(接口编号)},创建Tunnel接口。
执行命令tunnel-protocol ipv4-ipv6,将Tunnel类型指定为IPv4 over
IPv6隧道。
执行命令eth-trunk
{trunk-id(聚合口ID编号)},将当前接口加入到指定Eth-Trunk中。
执行命令source { source-ip-address | interface-type interface-number
(源地址或源接口)},设置Tunnel接口的源IPv6地址或源接口。
执行命令destination
{dest-ip-address(目的地址)},设置Tunnel接口的目的地址。
指定Tunnel接口的IPv4地址,选择如下方法之一:
执行命令ip address {ip-address { mask | mask-length }
(ipv4地址及掩码长度)}[ sub ],配置Tunnel接口的IPv4地址。
执行命令ip address unnumbered interface {interface-type
interface-number(接口类型及编号)},配置Tunnel接口借用IPv4地址。
三、ipv6静态路由配置
在创建IPv6静态路由时,可以同时指定出接口和下一跳。对于不同的出接口类型,也可以只指定出接口或只指定下一跳。
对于点到点接口,指定出接口。
对于NBMA(Non Broadcast Multiple Access)接口,指定下一跳。
对于广播类型接口,需指定下一跳地址。下一跳地址可以是链路本地地址,当下一跳地址为链路本地地址时,必须同时指定出接口。
在创建相同目的地址的多条IPv6静态路由时,如果指定相同优先级,则可实现负载分担,如果指定不同优先级,则可实现路由备份。
在创建IPv6静态路由时,如果将目的地址与掩码配置为全零,则表示配置的是IPv6静态缺省路由。缺省情况下,没有创建IPv6静态缺省路由。
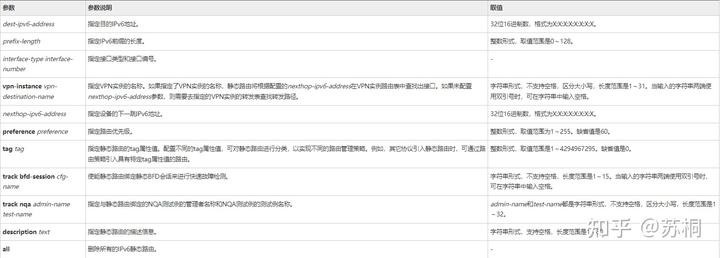
在公网上配置ipv6静态路由
ipv6 route-static {dest-ipv6-address prefix-length { interface-type
interface-number [ nexthop-ipv6-address ] | nexthop-ipv6-address }
}[ preference {preference} | tag {tag} ]
* [ description {text} ]
或ipv6 route-static {dest-ipv6-address prefix-length} vpn-instance
{vpn-destination-name} [ preference {preference} | tag {tag} ]
* [ description {text} ]
具体参数内容可参考下图
在VPN实例中配置IPv6静态路由
ipv6 route-static vpn-instance {vpn-instance-name dest-ipv6-address
prefix-length { [ interface-type interface-number ]
nexthop-ipv6-address | nexthop-ipv6-address} [ public ] |
vpn-instance {vpn-destination-name nexthop-ipv6-address } }[ preference
{preference} | tag {tag} ]
* [ description {text} ]
或ipv6 route-static vpn-instance {vpn-instance-name dest-ipv6-address
prefix-length} { public | vpn-instance {vpn-destination-name} } [
preference {preference} | tag {tag} ]
* [ description {text} ]
在静态路由负载分担的场景中,如果需要指定以太网接口的静态路由和其他静态路由形成负载分担,必须指定出接口和下一跳。
具体参数内容可参考下图
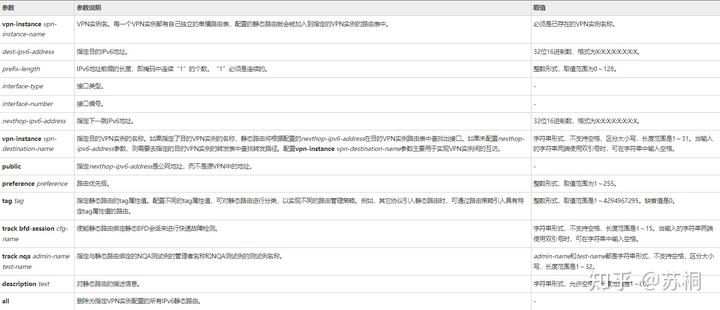
配置ipv6静态路由的优先级
配置IPv6静态路由缺省优先级可以影响路由的选路顺序。在配置静态路由时,如果没有指定优先级,就会使用缺省优先级。
执行命令system-view,进入系统视图。
执行命令ipv6 route-static default-preference
{preference(优先级)},配置IPv6静态路由的缺省优先级。缺省情况下,静态路由的缺省优先级为60。重新设置缺省优先级后,仅对新增的IPv6静态路由有效。


















 3806
3806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











