







 本文分析了RabbitMQ、RocketMQ和kafka这三大消息中间件在金融行业的应用,重点比较了它们的开源性、社区活跃度、可靠性、性能和适用场景,以及如何在SpringBoot中整合Kafka的示例。
本文分析了RabbitMQ、RocketMQ和kafka这三大消息中间件在金融行业的应用,重点比较了它们的开源性、社区活跃度、可靠性、性能和适用场景,以及如何在SpringBoot中整合Kafka的示例。
消息中间件
应用最为广泛的三大消息中间件:RabbitMQ、RocketMQ、kafka
在传统金融机构、银行、政府机构等有一些老系统还在使用IBM等厂商提供的商用MQ产品。
选取原则
1、首先,产品应该是开源的。开源意味着如果队列使用中遇到bug,可以很快修改,而不用等待开发者的更新。
2、其次,产品必须是最近几年比较流行的,要有一个活跃的社区。这样遇到问题很快就可以找到解决方法。同时意味着bug较少。流行的产品一般跟周边系统兼容性比较好。
3、最后,作为消息队列,要具备以下几个特性:
(1)消息传输的可靠性:保证消息不会丢失。
(2)支持集群,包括横向扩展,单点故障都可以解决。
(3)性能要好,要能够满足业务的性能需求。
RabbitMQ
RabbitMQ开始是用在电信业务的可靠通信,也是少有的几款支持AMQP协议的产品之一。
优点:
(1)轻量级、快速、部署方便。
(2)支持灵活的路由配置。RabbitMQ中,在生产者和队列之间有一个交换器模块。根据配置的路由规则,生产者发送的消息可以发送到不同的队列中。路由规则很灵活,还可以自己实现。
(3)RabbitMQ的客户端支持大多数的编程语言。
(4)RabbitMQ的延迟级低,在微妙级别。是三者中延迟最低的。
缺点:
(1)如果有大量消息堆积在队列中,性能会急剧下降。
(2)RabbitMQ的性能在kafka和RocketMQ中是最差的,每秒处理几万到几十万的消息,如果应用要求高的性能,不要选择RabbitMQ。
(3)RabbitMQ是Erlan开发的,功能扩展和二次开发代价很高。
RocketMQ
RocketMQ是一个开源的消息队列,使用java实现。借鉴了kafka的设计并做了很多改进。
优点:
(1)RocketMQ主要用于有序,事务,流计算,消息推送,日志流处理,binlog分发等场景。经过了历次的双11考研,性能,稳定性可靠性没得说。
(2)RocketMQ几乎具备了消息队列应该具备的所有特性和功能。
(3)Java开发,阅读源代码、扩展、二次开发很方便。
(4)对电商领域的相应延迟做了很多优化。在大多数情况下,响应在毫秒级。如果应用很关注响应时间,可以使用RocketMQ。
(5)性能比RabbitMQ高一个数量级,每秒处理几十万的消息。
缺点:
跟周边系统的整合和兼容不是很好。
kafka
(1)kafka的可靠性,稳定性和功能性基本满足大多数的应用场景。
(2)跟周边系统的兼容性是数一数二的,尤其是大数据和流计算领域,几乎所有相关的开源软件都支持kafka。
(3)kafka高效,可伸缩,消息持久化。支持分区、副本和容错。
(4)kafka是Scala和Java开发的,对批处理和异步处理做了大量的设计,因此kafka可以得到非常高的性能。它的异步消息的发送和接收是三个中最好的,但是跟RocketMQ拉不开数量级,每秒处理几十万的消息。
(5)如果是异步消息,并且开启了压缩,kafka最终可以达到每秒处理2000w消息的级别。但是由于是异步的和批处理的,延迟也会高,不适合电商场景。
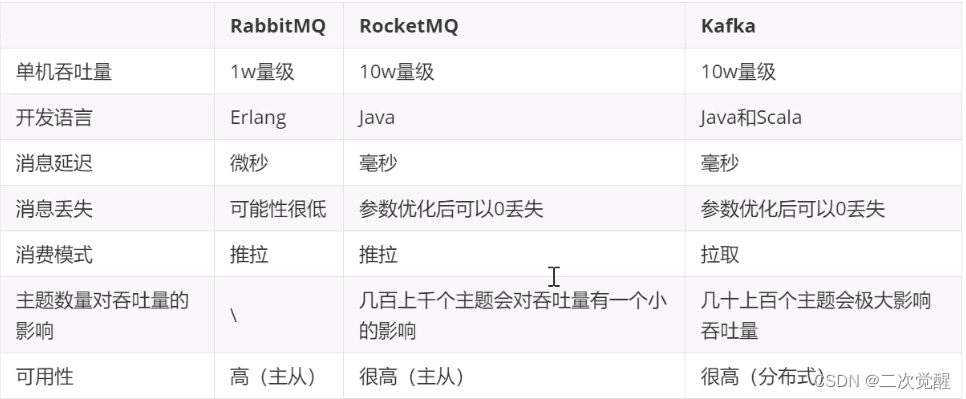
三者对比图
例:
一、springboot整合 Kafka
1、依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2、配置
spring:
application:
name: demo
kafka:
bootstrap-servers: 1.14.252.45:19092,1.14.252.45:19093,1.14.252.45:19094
producer: # producer 生产者
retries: 0 # 重试次数
acks: 1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
batch-size: 16384 # 批量大小
buffer-memory: 33554432 # 生产端缓冲区大小
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer: # consumer消费者
group-id: javagroup # 默认的消费组ID
enable-auto-commit: true # 是否自动提交offset
auto-commit-interval: 100 # 提交offset延时(接收到消息后多久提交offset)
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: latest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3、
下面示例创建了一个生产者,发送消息到topic1,消费者监听topic1消费消息。监听器用@KafkaListener注解,topics表示监听的topic,支持同时监听多个,用英文逗号分隔
KafkaTemplate调用send时默认采用异步发送,如果需要同步获取发送结果,调用get方法
@RestController
public class KafkaController {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
@GetMapping("/kafka/normal/{message}")
public void sendMessage1(@PathVariable("message") String normalMessage) {
kafkaTemplate.send("topic1", normalMessage);
}
@KafkaListener(topics = {"topic1"})
public void onMessage1(ConsumerRecord<?, ?> record){
// 消费的哪个topic、partition的消息,打印出消息内容
System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}
}
带回调的生产者
kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功 或 失败时做补偿处理,有两种写法
@GetMapping(“/kafka/callbackOne/{message}”)
public void sendMessage2(@PathVariable(“message”) String callbackMessage) {
kafkaTemplate.send(“topic1”, callbackMessage).addCallback(success -> {
// 消息发送到的topic
String topic = success.getRecordMetadata().topic();
// 消息发送到的分区
int partition = success.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = success.getRecordMetadata().offset();
System.out.println(“发送消息成功:” + topic + “-” + partition + “-” + offset);
}, failure -> {
System.out.println(“发送消息失败:” + failure.getMessage());
});
}
@GetMapping(“/kafka/callbackTwo/{message}”)
public void sendMessage3(@PathVariable(“message”) String callbackMessage) {
kafkaTemplate.send(“topic1”, callbackMessage).addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable ex) {
System.out.println(“发送消息失败:”+ex.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> result) {
System.out.println("发送消息成功:" + result.getRecordMetadata().topic() + "-"
+ result.getRecordMetadata().partition() + "-" + result.getRecordMetadata().offset());
}
});
}
分区策略
kafka中每个topic被划分为多个分区,那么生产者将消息发送到topic时,具体追加到哪个分区呢?这就是所谓的分区策略,Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。其路由机制为
若发送消息时指定了分区(即自定义分区策略),则直接将消息append到指定分区
若发送消息时未指定 patition,但指定了 key(kafka允许为每条消息设置一个key),则对key值进行hash计算,根据计算结果路由到指定分区,这种情况下可以保证同一个 Key 的所有消息都进入到相同的分区
patition 和 key 都未指定,则使用kafka默认的分区策略,轮询选出一个 patition

















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









