







使用python的scrapy框架简单的爬取豆瓣读书top250
一、配置scrapy环境
1. 配置相应模块
如果没有配置过scrapy环境的一般需要安装lxml、PyOpenssl、Twisted、Pywin32、scrapy这几样模块,都可以
pip install *方式安装,如pip install lxml。
2. **测试是否安装成功 **

直接在cmd输入scrapy,出现版本号就说明安装成功
二、爬虫项目
下面就直接开始爬取
1.创建项目scrapy startproject douban_book

这个就是创建好的scrapy文件
2.创建爬虫scrapy genspider douban_book_spider book.douban.com
“book.douban.com”是目标域

3.明确目标
就是我们要确定我们需要爬那些目标资源(红框的是本次项目要的资源)

然后在items.py中明确
class DoubanBookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 图片链接
img_url = scrapy.Field()
# 书名
book_name = scrapy.Field()
# 书本具体信息
specific_information = scrapy.Field()
# 评星
star_num = scrapy.Field()
# 多少人评价
people_num = scrapy.Field()
# 描述
describe = scrapy.Field()
4.爬虫逻辑
setting.py文件配置
在文件添加user_agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0'
编写douban_book_spider.py
class DoubanBookSpiderSpider(scrapy.Spider):
name = 'douban_book_spider'
allowed_domains = ['book.douban.com']
start_urls = ['https://book.douban.com/top250']
def parse(self, response):
print(response.text)
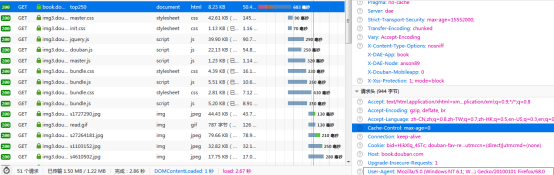
测试是否有返回值
在cmd输入scrapy crawl douban_book_spider
这样说明有返回值了
在douban_book_spider.py编写xpath逻辑
定位到涵盖这页的所有书的html的地方

以此为基础xpath
//div[@class=‘indent’]//table

在基础xpath下找到图片的链接
.//tr[@class=‘item’]//td//a[@class=‘nbg’]//img/@src
其他元素同理
class DoubanBookSpiderSpider(scrapy.Spider):
name = 'douban_book_spider'
allowed_domains = ['book.douban.com']
start_urls = ['https://book.douban.com/top250']
global thispage
def parse(self, response):
book_list = response.xpath("//div[@class='indent']//table")
for item in book_list:
book_item = DoubanBookItem()
book_item['img_url'] = item.xpath(".//tr[@class='item']//td//a[@class='nbg']//img/@src").extract_first()
book_item['book_name'] = item.xpath(".//tr[@class='item']//td[2]//div[@class='pl2']//a/@title").extract_first()
book_item['specific_information'] = item.xpath(".//tr[@class='item']/td[2]/p[@class='pl']/text()").extract_first()
book_item['star_num'] = item.xpath(".//tr[@class='item']/td[2]/div[@class='star clearfix']/span[2]/text()").extract_first()
people_num = item.xpath(".//tr[@class='item']/td[2]/div[@class='star clearfix']/span[3]/text()").extract_first()
book_item['people_num'] = people_num.replace(" ", "")
book_item['describe'] = item.xpath(".//tr[@class='item']/td[2]/p[@class='quote']/span/text()").extract_first()
yield book_item
每一次分页都是“后页”,最后一页就“后页”不能点击,所以可以从这里试一下

这是第一页,后页是有链接的
 这是最后一页,后页是没有链接的
这是最后一页,后页是没有链接的
所以判断“后页”有没有链接,如果有就回调,继续爬,没有就结束
class DoubanBookSpiderSpider(scrapy.Spider):
name = 'douban_book_spider'
allowed_domains = ['book.douban.com']
start_urls = ['https://book.douban.com/top250']
global thispage
def parse(self, response):
book_list = response.xpath("//div[@class='indent']//table")
for item in book_list:
book_item = DoubanBookItem()
book_item['img_url'] = item.xpath(".//tr[@class='item']//td//a[@class='nbg']//img/@src").extract_first()
book_item['book_name'] = item.xpath(".//tr[@class='item']//td[2]//div[@class='pl2']//a/@title").extract_first()
book_item['specific_information'] = item.xpath(".//tr[@class='item']/td[2]/p[@class='pl']/text()").extract_first()
book_item['star_num'] = item.xpath(".//tr[@class='item']/td[2]/div[@class='star clearfix']/span[2]/text()").extract_first()
people_num = item.xpath(".//tr[@class='item']/td[2]/div[@class='star clearfix']/span[3]/text()").extract_first()
book_item['people_num'] = people_num.replace(" ", "")
book_item['describe'] = item.xpath(".//tr[@class='item']/td[2]/p[@class='quote']/span/text()").extract_first()
yield book_item
next = response.xpath(".//div[@class='indent']/div[@class='paginator']/span[@class='next']/a/@href").extract_first()
if next:
yield scrapy.Request(next, callback=self.parse)
至此250本书的信息就爬下来了!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









