







环境
scrapy1.03 + ubuntu14.04 + python2.7
scrapy 安装
pip install Scrapy
注:非root用户的话需在命令前加上:sudo,不然可能会因为权限问题装不上
更多关于scrapy的详细资料请参考 scrapy0.24 中文文档吧
创建爬虫项目并进入该目录下
scrapy startproject douban
cd douban
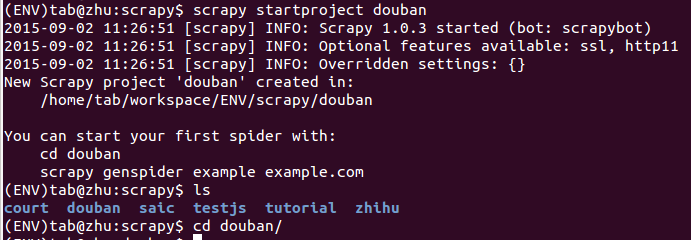
此时,我们的项目下包含以下文件:
douban
├── douban
│ ├── init.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── init.py
└── scrapy.cfg
这些文件分别是:

定义Item
# items.py 文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import scrapy
class DoubanItem(scrapy.Item):
""" 定义需要抓取的字段名 """
name = scrapy.Field() # 书名
author = scrapy.Field() # 作者
press = scrapy.Field() # 出版社
date = scrapy.Field() # 出版日期
page = scrapy.Field() # 页数
price = scrapy.Field() # 价格
score = scrapy.Field() # 读者评分
ISBN = scrapy.Field() # ISBN号
author_profile = scrapy.Field() # 作者简介
content_description = scrapy.Field() # 内容简介
link = scrapy.Field() # 详情页链接定义爬虫Spider
在终端中输入以下命令,创建我们的第一个spider
scrapy genspider books book.douban.com
注:books是爬虫的名字,book.douban.com是允许爬取的域名,可在终端中输入: scrapy genspider -h 查看更多关于该命令的用法
在spiders文件夹下会多了个books.py脚本,在编写spider爬虫代码之前,我们先看看 豆瓣图书Top250 翻页的url和html源码都有哪些规律
1、列表页翻页存在哪些规律
第二页的url: http://book.douban.com/top250?start=25
第三页的url: http://book.douban.com/top250?start=50
第四页的url: http://book.douban.com/top250?start=75
很自然的你会发现url后面的数字是有规律递增的,知道这个就好办了,于是用于翻页的url正则表达式我们可以这样写:
r”http://book.douban.com/top250\?start=\d+”
注:python中 r 表示的是原始字符的意思
2、列表页的html源码分析
当我们用谷歌浏览器进行审查元素时

就会发现每一本书的详情页链接都类似,只是后面的一串数字不同而已
因此我们又可以得出在列表页中查找图书详情页ulr的正则表达式了
3、书籍详情页html源码分析
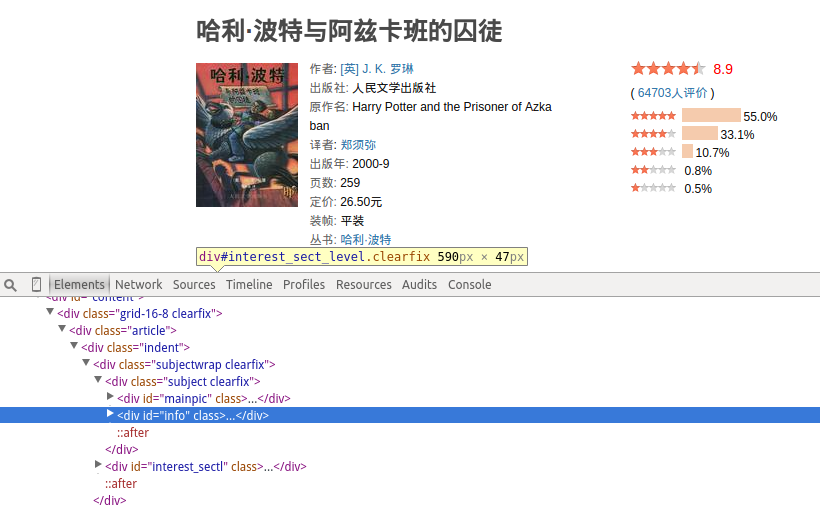
直接把鼠标移到我们想查看的元素上,右键–>审查元素,就可以看到该元素在html的哪个标签下了,用xpath抓取具体元素时需要用到
4、编写spider代码
# books.py 文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from scrapy.selector import Selector
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors import LinkExtractor
from douban.items import DoubanItem
class BooksSpider(CrawlSpider):
name = "books"
allowed_domains = ["book.douban.com"]
start_urls = (
'https://book.douban.com/top250',
)
rules = (
# 列表页url
Rule(LinkExtractor(allow=
r"https://book.douban.com/top250\?start=\d+"))),
# 详情页url
Rule(LinkExtractor(allow=
r"https://book.douban.com/subject/\d+")), callback="books_parse")
)
def books_parse(self, response):
sel = Selector(response=response)
item = DoubanItem()
item["name"] = sel.xpath("//div[@id='wrapper']/h1/span/text()").extract()[0].strip()
item["score"] = sel.xpath("//div[@class='rating_wrap']/p[1]/strong/text()").extract()[0].strip()
item["link"] = response.url
# 豆瓣中并非每一本书籍都有作者和书籍内容简介,所以我们得在找不到该html标签时则给该字段赋空字符串值
try:
contents = sel.xpath("//div[@id='link-report']//div[@class='intro']")[-1].xpath(".//p//text()").extract()
item["content_description"] = "\n".join(content for content in contents)
except:
item["content_description"] = ""
try:
profiles = sel.xpath("//div[@class='related_info']//div[@class='indent ']//div[@class='intro']")[-1].xpath(".//p//text()").extract()
item["author_profile"] = "\n".join(profile for profile in profiles)
except:
item["author_profile"] = ""
datas = response.xpath("//div[@id='info']//text()").extract()
datas = [data.strip() for data in datas]
datas = [data for data in datas if data != ""]
# 打印每一项内容
#for i, data in enumerate(datas):
#print "index %d " %i, data
for data in datas:
if u"作者" in data:
if u":" in data:
item["author"] = datas[datas.index(data)+1]
elif u":" not in data:
item["author"] = datas[datas.index(data)+2]
# 找出版社中有个坑, 因为很多出版社名包含"出版社"
# 如: 上海译文出版社,不能用下面注释的代码进行查找
#elif u"出版社" in data:
# if u":" in data:
# item["press"] = datas[datas.index(data)+1]
# elif u":" not in data:
# item["press"] = datas[datas.index(data)+2]
elif u"出版社:" in data:
item["press"] = datas[datas.index(data)+1]
elif u"出版年:" in data:
item["date"] = datas[datas.index(data)+1]
elif u"页数:" in data:
item["page"] = datas[datas.index(data)+1]
elif u"定价:" in data:
item["price"] = datas[datas.index(data)+1]
elif u"ISBN:" in data:
item["ISBN"] = datas[datas.index(data)+1]
# 这是一个debug代码
#if "subject" in response.url:
# from scrapy.shell import inspect_response
# inspect_response(response, self)
return item我们可以在终端中用以下命令来进行debug,验证我们spider中的代码是否准确无误抓取到了我们想要的字段
scrapy shell “http://book.douban.com/subject/1071241/”

下面进行spider中一些代码的解释
datas = response.xpath(“//div[@id=’info’]//text()”).extract()
上面的xpath表达式主要是获取书籍的基本信息


由于此时的datas对象含有大量的换行符之类的,于是我们进行去除多余的换行符操作
datas = [data.strip() for data in datas]

列表中还是含有空项,所以我们继续去除空的列表项
datas = [data for data in datas if data != “”]

此时我们打印一下列表中的每一项看看
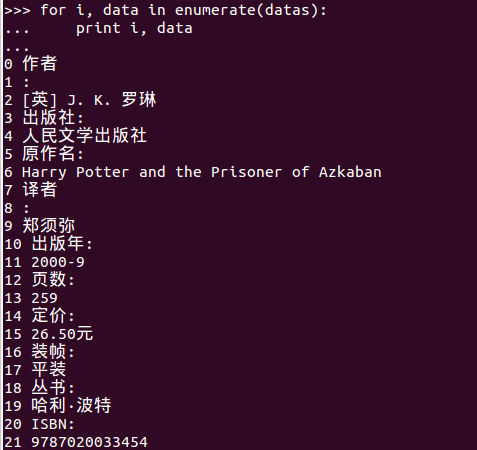
Item Pipeline(管道)
以下代码可以把抓取的到的数据存于json文件中也可以存于mysql数据库中
# pipelines.py 文件
#!/usr/bin/env python
# -*- coding: utf-8
import json
from twisted.enterprise import adbapi
from scrapy import log
import MySQLdb
import MySQLdb.cursors
class DoubanPipeline(object):
""" 将抓取到的数据存入json文件中 """
def __init__(self):
self.file = open("./books.json", "wb")
def process_item(self, item, spider):
# 由于scrapy在spider中抓取的所有字段都会转换成unicode码
# 所以我们在存入json文件之前先将每一项都转换成utf8
# 不转的话,我们存入json文件中的数据也是unicode码,中文显示方式不是我们想要的
for k in item:
item[k] = item[k].encode("utf8")
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
class MySQLPipeline(object):
""" 将抓取到的数据存入mysql数据中 """
def __init__(self):
self.dbpool = adbapi.ConnectionPool("MySQLdb",
db = "dbname", # 你的数据库名
user = "username", # 你的数据库用户名
passwd = "password", # 登录数据库的密码
cursorclass = MySQLdb.cursors.DictCursor,
charset = "utf8",
use_unicode = False
)
def process_item(self, item, spider):
query = self.dbpool.runInteraction(self._conditional_insert, item)
query.addErrback(self.handle_error)
return item
def _conditional_insert(self, tb, item):
# tablename 你的表名
tb.execute("insert into tablename (name, author, press, date, page, price, score, ISBN, author_profile,\
content_description, link) values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)",\
(item["name"], item["author"], item["press"], item["date"],\
item["page"], item["price"], item["score"], item["ISBN"],\
item["author_profile"], item["content_description"], item["link"]))
log.msg("Item data in db: %s" % item, level=log.DEBUG)
def handle_error(self, e):
log.err(e)当你选择把数据写入到数据库中时,请确保已安装mysql和MySQLdb库,可用以下命令进行安装
sudo apt-get install mysql-server
sudo apt-get install python-MySQLdb
以下是创建表的sql语句,当然你也可以用图形工具界面操作来创建表
create table dbname.tablename(id int primary key auto_increment, name varchar(100) NOT NULL, author varchar(50) NULL, press varchar(100) NULL, date varchar(30) NULL, page varchar(30) NULL, price varchar(30) NULL, score varchar(30) NULL, ISBN varchar(30) NULL, author_profile varchar(1500) NULL, content_description varchar(1500) NULL, link varchar(255) NULL )default charset=utf8;
数据不能写入表一般是sql语句写错了
1、如:表中某字段是字符串类型,而插入语句中插入的值却是整形
2、表中定义的字段名和插入语句中的字段名不相同
写入到表中的数据乱码了(中文)
一般是我们表的字符集与所插入数据的字符集类型不同所导致的,更改其一字符集便可
查看表中的字符集方法
mysql -u username -p
show create table tablename;

最后一行中的:charset=utf8 就是表的字符集类型
settings(爬虫设置)
我们需要在settings.py 文件中把我们刚才编写的管道添加进去,以及添加一些防止豆瓣反爬虫机制识别的设置
# settings.py 文件
# -*- coding: utf-8 -*-
# 如果你想把数据存放在mysql数据库中,则把存入json文件的管道对象注释点,反之一样
ITEM_PIPELINES = {
# "douban.pipelines.DoubanPipeline": 300
"douban.pipelines.MySQLPipeline": 400
}
# 为防止被识别为爬虫,应设置下载页面的延时时间
DOWNLOAD_DELAY = 2
# 模拟浏览器头部
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
}运行spider(爬虫)
scrapy crawl books
接下来你应看着屏幕中滚动的字符,好好享受自己编写的程序跑起来了的那种喜悦(码农专属)!静静等待爬虫完成你给她安排的任务。
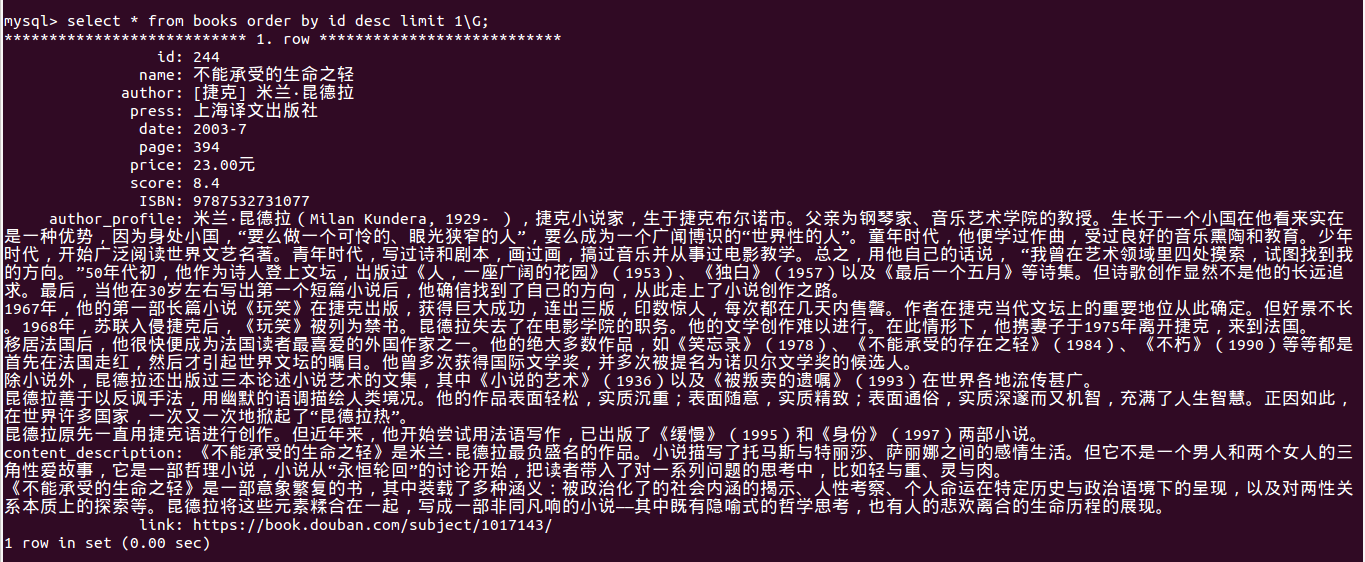
数据库中的数据
json格式的数据

此项目的完整源码可到:https://github.com/Tangugo/douban下载
最后希望大家发现有哪些错误的地方都能告诉我,谢谢!也祝大家有个愉快的反法西斯假期 ^_^















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









