







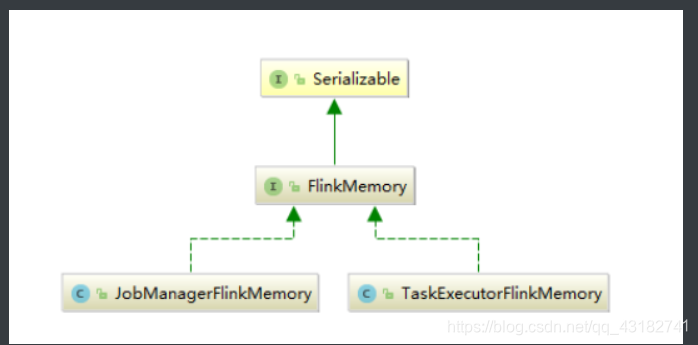
Flink的内存管理
目前,大数据计算引擎主要用Java或是基于JVM的编程语言实现的,例如Apache Hadoop、Apache Spark、Apache Drill、Apache Flink等。Java语言的好处在于程序员不需要太关注底层内存资源的管理,但同样会面临一个问题,就是如何在内存中存储大量的数据(包括缓存和高效处理)。Flink使用自主的内存管理,来避免这个问题。
JVM内存管理的不足:
- Java对象存储密度低。Java的对象在内存中存储包含3个主要部分:对象头、实例数据、对齐填充部分。例如,一个只包含boolean属性的对象占16byte:对象头占8byte,boolean属性占1byte,为了对齐达到8的倍数额外占7byte。而实际上只需要一个byte(1/8)就够了。
- Full GC会极大地影响性能。尤其时为了处理更大数据而开了很大内存空间的JVM来说,GC会达到秒级甚至分钟级。
- OOM问题影响稳定性。OutOfMemoryError是分布式计算光加经常会问到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
- 缓存未命中问题。CPU进行计算的时候,是从CPU缓存中获取数据。现代体系的CPU会有多级缓存,而加载的时候以Cache Line为单位加载。如果能够将对象连续存储,这样就会大大降低Cache Miss。使得CPU集中处理业务,而不是空转。(Java对象在堆上存储的时候并不是连续的,所以从内存中读取Java对象时,缓存的邻近的内存区域往往不是CPU下一步计算所需的,这就是缓存未命中。此时CPU需要空转等待从内存中重新读取数据。)
Flink并不是将大量对象存储在堆内存上,而是将对象都序列化到一个预分配的内存块上,这个内存块叫做MemorySegment,他代表了一段固定长度的内存(默认大小为32kB),也是Flink中最小的内存分配单元,并且提供了非常高效的读写方法,很多运算可以直接操作二进制数据,不需要反序列化即可执行。每条记录都会以序列化的形式存储在一个或多个MemorySegment中。如果需要处理的数据多于可以保存在内存中的数据,Flink的运算会将部分数据溢出到磁盘。、
- 内存模型
- JobManager内存模型
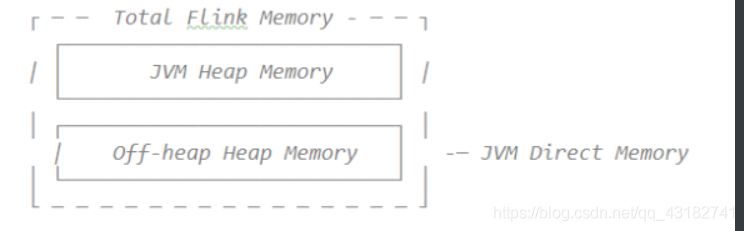
在1.10中,Flink统一了TM端的内存管理和配置,相应的在1.11中,Flink进一步对JM端的内存配置进行了修改,使它的选项和配置方式与TM端的配置方式保持一致。
1.10 版本 # The heap size for the JobManager JVM jobmanager.heap.size: 1024m 1.11 版本及以后 # The total process memory size for the JobManager. # # Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead. jobmanager.memory.process.size: 1600m
TaskManager内存模型
Flink1.10对TaskManager的内存模型和Flink应用程序的配置选项进行了重大修改,让用户能够更加严格地控制其内存开销。

TaskExecutorFlinkMemory
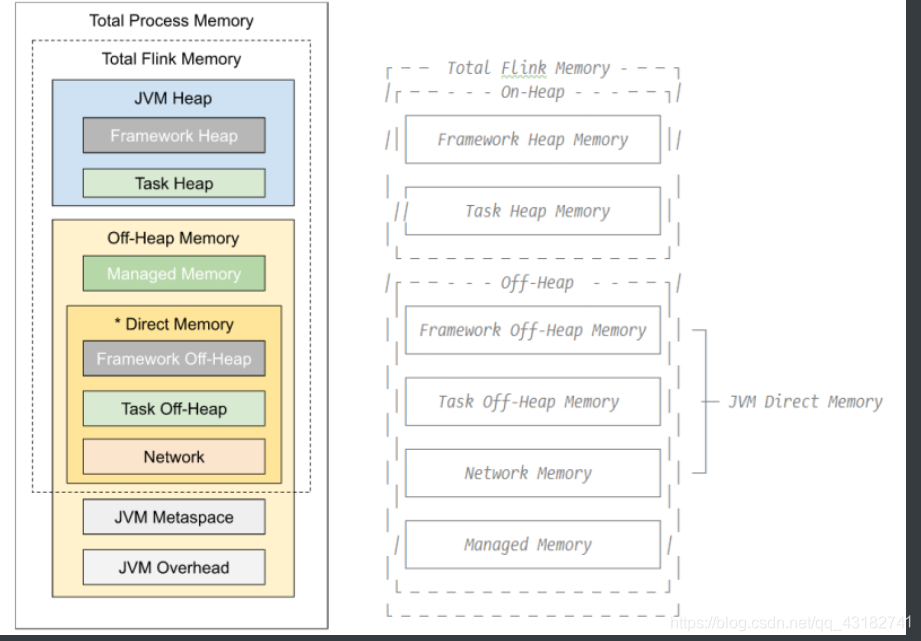
JVM Heap:JVM堆上内存
Framework Heap Memory:Flink框架本身使用的内存,即TaskManager本身所占用的堆上内存,不计入Slot的资源中。
#配置参数: taskmanager.memory.framework.heap.size=128MB,默认128MBTask Heap Memory:Task执行用户代码时所使用的堆上内存。
#配置参数: taskmanager.memory.task.heap.size
Off—Heap Memory:JVM堆外内存
DirectMemory:JVM直接内存
Framework Off-Heap Memory:Flink框架本身所使用的内存,即TaskManager本身所占用的堆外内存,不计入Slot资源。
#配置参数 taskmanager.memory.framework.off-heap.size=128MB,默认128MBTask Off-Heap Memory:Task执行用户代码所使用的堆外内存
#配置参数 taskmanager.memory.task.off-heap.size=0,默认 0Network Memory:网络数据交换所使用的堆外内存大小,如网络数据交换缓冲区。
#配置参数 taskmanager.memory.network.fraction: 0.1 taskmanager.memory.network.min: 64mb taskmanager.memory.network.max: 1gbManaged Memory:Flink管理的堆外内存,用于排序、哈希表、缓存中间结果即RocksDB State Backend的本地内存。
#配置参数 taskmanager.memory.managed.fraction=0.4 taskmanager.memory.managed.sizeJVM specific memory:JVM本身使用的内存
JVM metaspace:JVM元空间
JVM over-head执行开销:JVM执行时自身所需要的内容,包括线程堆栈、IO、编译缓存等所使用的内存。
#配置参数 taskmanager.memory.jvm-overhead.min=192mb taskmanager.memory.jvm-overhead.max=1gb taskmanager.memory.jvm-overhead.fraction=0.1总体内存
总进程内存:Flink Java应用程序(包括用户代码)和JVM运行整个进程所消耗的总内存。
总进程内存=Flink使用内存+JVM元空间+JVM执行开销
#配置 taskmanager.memory.process.size: 1728mFLink总内存:仅FLink Java应用程序消耗的内存,包括用户代码,但不包括JVM为其运行而分配的内存
Flink使用内存:框架堆内外+task堆内外+network+manage
#配置 taskmanager.memory.flink.size: 1280m内存数据结构
内存段
内存段在Flink内部叫MemorySegment,是Flink中最小的内存分配单元,默认大小32KB。它即可以是堆上内存(Java的byte数组),也可以是堆外内存(基于Netty DirectByteBuffer),同时提供了对二进制数据进行读取和写入的方法。
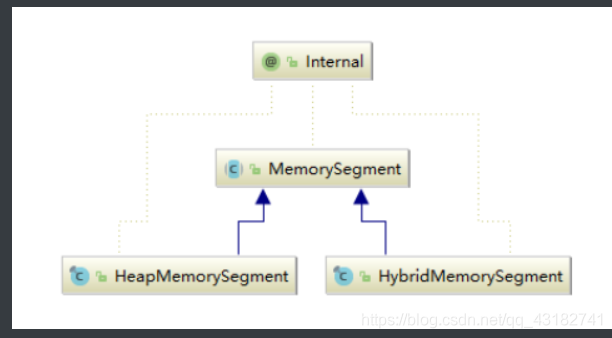
HeapMemorySegment:用来分配堆上内存 HybridMemorySegment:用来分配堆外内存和堆上内存,2017年以后的版本实际上只使用了HybridMemorySegment。 如下图展示一个内嵌型的Tuple3<Integer,Double,Person>对象的序列化过程;
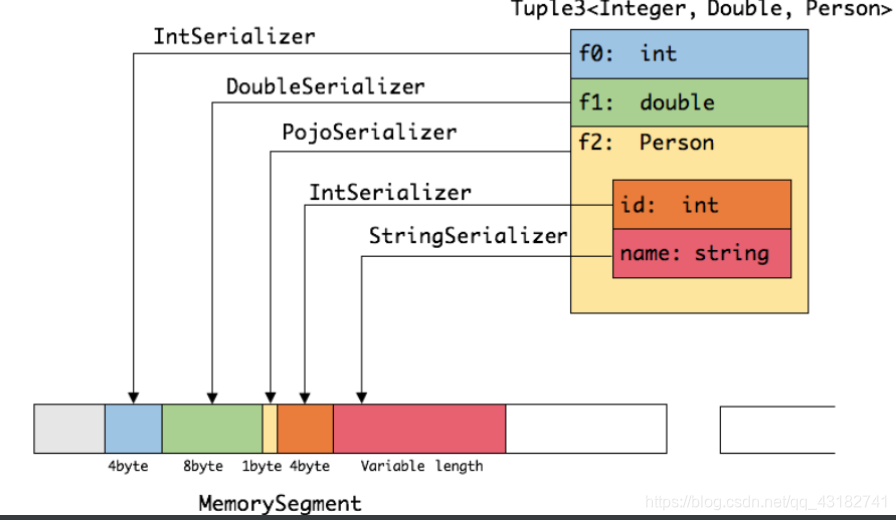
可以看出这种序列化方式存储密度是相当紧凑的。其中int占4字节,double占8字节,POJO多个一个字节的header,POJOSerializer只负责将header序列化进去,并委托每个字段对应的serializer对字段进行序列化。
内存页
内存页是MemorySegment之上的数据访问视图,数据读取抽象为DataInputView,数据写入抽象为DataOutputView。使用时就无需关心MemorySegment的细节,会自动处理跨MemorySegment的读取和写入。
Buffer
Task算子之间在网络层面上传输数据,使用的是Buffer,申请和释放由Flink自行管理,实现类为NetworkBuffer。一个NetworkBuffer包装了1个MemorySegment。同时继承了AbstractReferenceCountedByteBUf,是Netty中的抽象类。
Buffer资源池
BufferPool用来管理Buffer,包含Buffer的申请、释放、销毁、可用Buffer通知等,实现类是LocalBufferPool,每个Task拥有自己的LocalBufferPool。
BufferPoolFactory用来提供BufferPool的创建和销毁,唯一的实现类是NetworkBufferPool,每个TaskManager只有一个NetworkBufferPool。同一个TaskManager上的Task共享NetworkBufferPool,在TaskManager启动的时候创建并分配内存。
内存管理器
Memory Manager用来管理Flink中用于排序、Hash表、中间结果的缓存或使用堆外内存的状态后端(RocksDB)的内存。
1.10之前版本,负责Taskmanager所有内存
1.10版本开始,管理范围是Slot级别。
网络传输中的内存管理
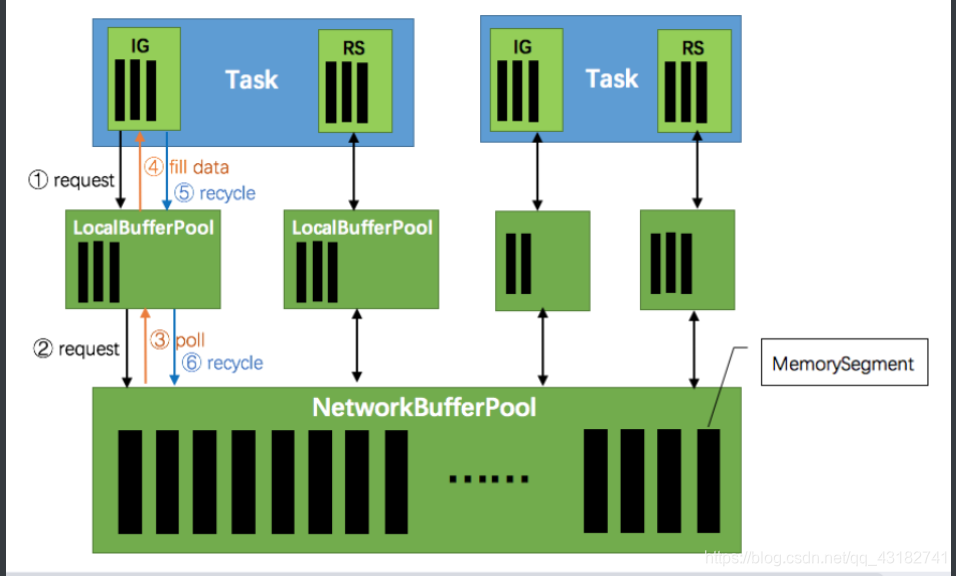
网络上传输的数据会写到Task的InputGate(IG)中,经过Task的处理后,在由Task写到ResultPartition(RS)中。每个Task都包括了输入和输出,输入和输出的数据存在Buffer中。Buffer是MemorySegment的包装类。
- TaskManager(TM)在启动时,会先初始化NetworkEnvironment对象,TM中所有与网络相关的东西都由该类来管理,其中就包括NetworkBufferPool。根据配置,Flink会在NetworkBufferPool中生成一定数量(默认2048)的内存块MemorySegment,内存块的总数量就代表了网络传输中所有可用的没存。NetworkEnvironment和NetworkBufferPool是Task之间共享,每个TM只会实例化一个。
- Task线程启动时,会向NetworkEnvironment注册,NetworkEnvironment会为Task的InputGate(IG)和ResultPartition(RS)分别创建一个LocalBufferPool(缓冲池)并设置可申请的MemorySegment(内存块)数量。IG对应的缓冲池初始的内存数块数量与IG中InputChannel数量一致,RS·对应的缓冲池初始的内存块数量与RS中的ResultSubjectpartition数量一致。不过,每当创建或销毁缓冲池时,NetworkBufferPool会计算剩余空闲的内存块数量,并平均分配给已创建的缓冲池。注意,这个过程知识指定了缓冲池所能使用的内存块数量,并没有真正分配内存块,只有当需要时分配。为什么动态地为缓冲池扩容哪?因为内存越多,意味着系统可以更轻松应对瞬时压力(如GC),不会频繁地进入反压状态,所以我们要利用那部分闲置的内存块。
- 在Task线程执行过程中,当Netty接收端收到数据时,为了将Netty中过的数据拷贝到Task中,InputChannel(实际是 RemoteInputChannel)会向其对应的缓冲池申请内存块(上图中的①)。如果缓冲池中也没有可用的内存块且已申请的数量还没有达到池子上限,则会向NetworkBufferPool申请内存块(上图中的②)并交给InputChannel填上数据(上图中的③和④)。如果缓冲池已申请的数量达到上限了呢?或者NetworkBufferPool也没有可用的内存块了呢?这时候,Task 的 Netty Channel 会暂停读取,上游的发送端会立即响应停止 发送,拓扑会进入反压状态。当 Task 线程写数据到 ResultPartition 时,也会向缓冲池请求内存块,如果没有可用内存块时,会阻塞在请求内存块的地方,达到暂停写入的目的。
果缓冲池已申请的数量达到上限了呢?或者NetworkBufferPool也没有可用的内存块了呢?这时候,Task 的 Netty Channel 会暂停读取,上游的发送端会立即响应停止 发送,拓扑会进入反压状态。当 Task 线程写数据到 ResultPartition 时,也会向缓冲池请求内存块,如果没有可用内存块时,会阻塞在请求内存块的地方,达到暂停写入的目的。- 当一个内存块被消费完之后(在输入端是指内存块中的字节被反序列化成对象了,在输出端是指内存块中的字节写入到Netty Channel了),会调用Buffer.recycle() 方法,会将内存块还给LocalBufferPool(上图中的⑤)。如果LocalBufferPool中当前申请的数量超过了池子容量(由于上文提到的动态容量,由于新注册的Task导致池子容量变小),则LocalBufferPool会将该内存块回收给NetworkBufferPool(上图中的⑥)。如果没超过池子容量,则会继续留在池子中,减少反复申请的开销。















 2283
2283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









