








本文对MS MARCO Document Ranking 榜单的榜2 (截止至2022/4/11)—— UniRetriever 进行解读,原文地址请点击此处。
1. 背景介绍
EBR (Embedding Based Retireval)已广泛应用于许多应用,例如网络搜索、问答、在线广告和推荐系统。通用 EBR 系统专为同质目标而设计,例如,用户可能在推荐系统中点击的项目,或者在网络搜索中包含真实答案的网页。然而,赞助搜索(sponsored search)中的 EBR 由于需要服务于多个检索目的而更加复杂:一方面,检索到的广告必须在语义上接近用户指定的查询。另一方面,检索到的广告预计会被用户以高概率点击。以前的工作意识到了这样的问题,但对于具有高点击率和高相关性的广告检索的统一模型仍然缺乏系统的研究。
典型的 EBR 系统由两个基本组件组成:表示模型和 ANN(approximate nearest neighbour) 检索。近年来,预训练语言模型 (PLM) 被广泛用作表示模型的主干,此外,人们还为 EBR 预训练了特定的 PLM。除了主干模型,训练算法也是一个关键因素。大多数表示模型是使用对比学习进行训练的,其性能受负采样策略的影响:一方面,人们发现可以通过增加负样本的数量来提高表示质量,例如批量负采样(in-batch negative sample)和动量编码器。另一方面,表示质量也可能受益于hard negative sample(困难负样本)。
ANN 检索是 EBR 的另一个基本组件,通过它可以有效地从整个语料库中检索出最佳答案。然而,现有方法在应用于大规模(数十亿级别) EBR 时受到时间成本、内存使用或检索质量的限制。最新的研究例如 DiskANN、SPANN,建议联合利用向量量化和基于图形的索引来实现时间和内存可扩展的ANN。
2. 本文工作
- 提出了统一表示学习框架:Uni-Retriever,该框架集成了知识蒸馏和对比学习,可以检索高相关性和高点击率的广告以供用户查询。
- 结合向量量化和基于图形的索引策略,采用了针对检索场景设计的量化方法MoPQ和基于NSG演变的vamana图索引构建算法,以提高大规模向量检索的速度与精度。
3. Uni-Retriever
- 知识蒸馏:检索高相关性广告。交互式BERT作为教师模型,双塔共享BERT作为学生模型。教师模型首先为查询 q 和广告 a 生成相关性分数,学生模型用 q 与 a 的点积分数去拟合教师的相关性分数,损失函数使用MAE。
- 对比学习:检索高点击率广告。论文指出,对比学习的表现受两个因素的影响很大:1)负样本的规模,以及 2)负样本的硬度。
负样本规模使用分布式训练的方式扩大,需要额外广播embedding到其他GPU。对比学习一般采用In-batch negative sample的方式进行负采样,即使用同一batch内其他query的广告作为负样本,除此之外,还需要为每条query挑选足够硬(困难)的负样本,论文中给出了几种挑选方法,并做了对比实验,实验结果放在下面。 - Uni-Retriever的大体结构如下:
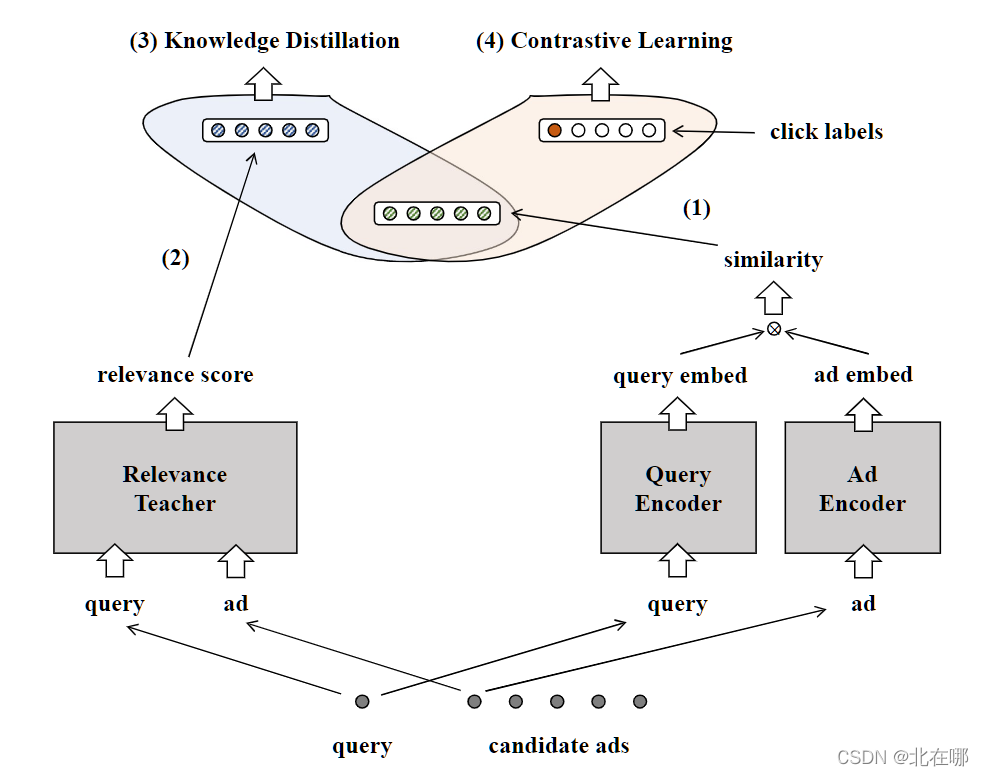
- 实验结果:
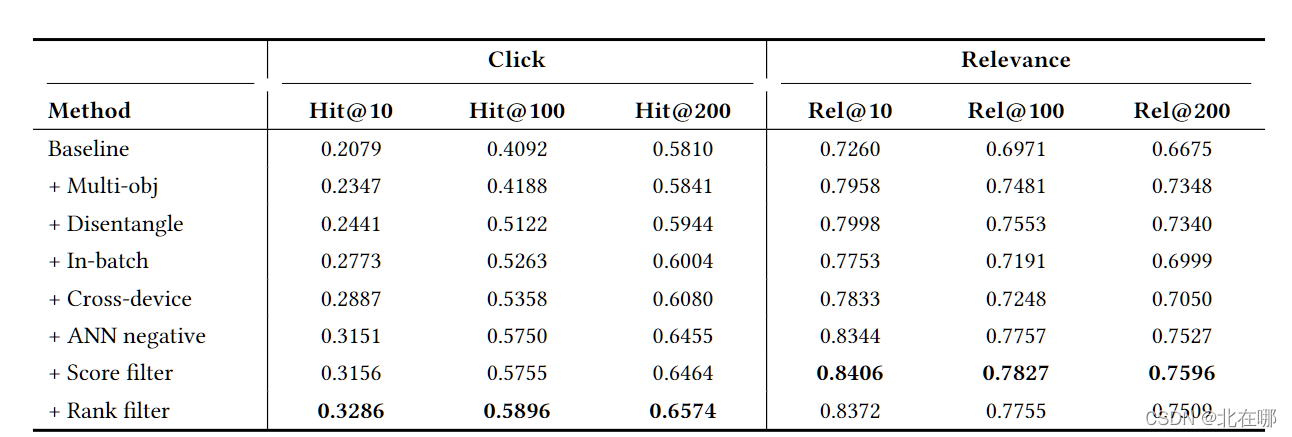
Baseline:仅使用对比学习方法训练双塔模型,负样本在广告库里随机采用10个;
+ Multi-obj:在Baseline基础上加入蒸馏任务;
+ Disentangle:蒸馏任务和对比学习任务分别使用不同的输出向量(使用任务特定的头对双塔模型输出向量进行变换)
+ In-batch:采用 in-batch negative sample;
+ Cross-device:使用分布式训练,并将每个GPU的样本都广播到其他GPU上,以扩大Batch规模;
+ ANN negative:在 in-batch negative sample 的基础上增加一个由ANN检索回来的负样本(从Top-200结果中随机抽取)
+ Score filter:从Top-200中相关性分数低于0.5的样本中挑选负样本;
+ Rank filter:使用相关性教师模型对ANN的Top-200结果进行重排序,从低相关性样本中(101~200)中挑选负样本。 - 实验结果表明:
通过为两个目标生成分离嵌入(+ Disentangled),相对于基本的多目标学习方法,可以进一步提高表示质量。使用“+ Score filter”和“+ Rank filter”可以实现额外的改进,因为可以有效地排除高相关性广告被选为负样本。
4. 两阶段ANN检索策略:应对数十亿规模的向量检索
fasis等检索工具可以轻松应对数百万规模的检索场景,但是当面临数十亿规模的向量检索时就捉襟见肘了。因此,论文采用了MoPQ(一种向量量化方法,针对检索场景设计)和vamana图(基于图的ANN检索算法,淘宝提出的NSG的变体)相结合的策略,执行粗粒度与细粒度相结合的两阶段检索。同时,鉴于广告embedding及其图连接太大而无法放入内存,采用了以下分层存储架构:
- 第一层存储:对广告embedding进行量化,将量化后的embedding保存在内存。量化压缩后的embedding可以比原始密集embedding轻一到两个数量级;因此,十亿规模的广告可以托管在具有数十GB RAM 使用量的主内存中。
- 第二层存储:在SSD硬盘中存储广告embedding的posting list,包括每条广告的ID、原始密集embedding、以及 Vamana 图上相邻广告的 ID 列表。
ANN检索则通过两个连续步骤执行:粗粒度搜索和细粒度后验证。
- 对于粗粒度搜索,输入查询在 Vamana 图上进行路由以获取其近似最近邻。从入口图节点(随机或选定)开始,探索与目标点最近但未访问过的入口节点的邻居,并将最近的候选者添加到固定大小的优先级队列中。检索过程中使用压缩embedding计算距离。一旦访问了图节点,其邻居的 ID 将被加载到 RAM 以供将来探索,访问节点的全精度密集embedding也将加载到 RAM 中。(拓展:13 种高维向量检索算法全解析!)
- 细粒度后验证。一旦探索完成,就会执行后验证,使用原始密集embedding对优先级队列中的候选者进行细化。优先级队列最终确定后,使用重排序函数进行重排序,综合考虑查询与广告的相关性,广告的点击率和出价三个因素,Top-K 的广告将作为最终结果返回。
此外,论文指出,原始的密集embedding学习以从整个语料库中检索高相关性和高点击率广告,对于一个高相关性(点击率)的广告和一个低相关性(点击率)的广告来说,它可以很好区分,但对于两个高相关性(点击率)的广告来说,判断他们谁的相关性更高就有些困难,这种功能需要特定的排序函数来实现,直接使用原始密集embedding对优先级队列中的候选者进行细化可能取不到很好的效果。为了缓解这个问题,作者通过从重新排序函数中提取知识,进一步调整 Uni-Retriever 以获得更好的后验证。















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









