










1.动机
通常情况下,BERT类模型总是需要一些样例来更新模型的参数从而让模型更加适应当前的任务,而GPT-3却号称可以“告别微调”,可以仅仅通过一个自然语言提示(prompt)以及少量甚至无需样例(标注样本)就可以作出正确的预测,即GPT-3可以通过不使用一条样例的Zero-shot、仅使用一条样例的One-shot和使用少量样例的Few-shot来完成推理任务。下面是对比微调模型和GPT-3三种不同的样本推理形式图:

以机器翻译任务为例,在Zero-shot场景下,GPT-3只需在输入前拼接一段关于任务的自然语言描述,用来告诉模型这是机器翻译类任务,同时在输入后拼接引导符“=>”,引导模型输出翻译结果。在One-shot和Few-shot场景下,bert类模型会使用已有的标注样例进行微调并迭代更新模型参数,而在GPT-3中,样例是直接作为上下文拼接到了输入中作为提示,不需要额外的训练,模型的参数也无需更新。下面是GPT-3模型在TriviaQA数据集上的实验结果图:

从上图中可以看出,在TriviaQA数据集上最大的GPT-3仅使用一条样本的One-shot就已经和最好效果的微调模型效果相当,使用64条样本的Few-shot的模型效果已经超越了最好效果的微调模型,这足以说明GPT-3模型的强大。但美中不足的是,GPT-3的参数量过于庞大(1750亿),在现有的硬件条件下,落地还是比较困难。此外,GPT-3采用的是从左到右的建模方式,模型在任意时刻只能看到输入文本的上文,对于需要结合上下文的NLU任务来说,GPT-3显得不是很擅长。
受到GPT-3的启发,这篇论文研究了一个更符合实际场景的小样本学习问题:(1)使用可以在普通硬件资源上访问的中等大小的语言模型(如BERT),降低对硬件资源的要求。(2)借鉴GPT-3基于提示(prompt)的微调方法,减少对领域内有标注数据的过分依赖,降低对领域内少量有标注数据过拟合的风险。
2.基于提示(prompt)的微调方法
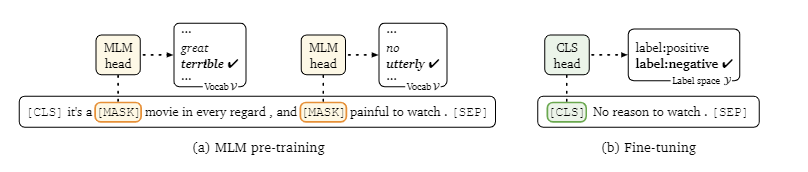
在标准的微调方法中(如上图b所示),以分类任务为例,一般是在[CLS]部分添加一个额外的分类器(线性层+softmax),然而新初始化的参数的数量(独立于原始预训练模型外的参数)可能会很大,例如基于RoBERTa-large的二分类任务会新引入2048个参数,会使从小样本(如32个标注数据) 中学习变得困难。
上图a是BERT主要的预训练任务之一:masked language modeling (MLM) ,将输入原有的token用[mask]遮盖,驱使模型恢复原有的token。为了不引入新的参数,同时充分利用预训练模型的知识,这篇论文借鉴了MLM的方式,将下游任务直接转化为MLM任务,即:为特定的任务构建特定的提示模板,然后通过语言模型对「提示模板」进行“自动补全”。这就是论文所称的「 基于提示的微调方法」。
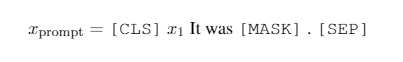
以情感分析任务为例,给定一个句子x1(e.g., “No reason to watch it .”),判断该句的情感是positive还是negative。基于提示的微调方法首先会构建如上图的提示模板,[MASK]包含在提示模板中;然后对[MASK]预测,预测输出是标签词(label words),与具体标签建立映射关系:例如,标签positive对应单词great,标签negative对应单词terrible。
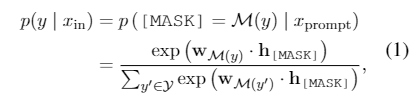
这样,训练目标就从最大化真实标签的概率转变成了最大化[mask]标记处真实标签词的概率,非常自然地重用了预训练模型的MLM参数,同时也减少了预训练与微调之间的差距,因为[mask]标签在微调阶段又出现了🤣。
由上述分析,我们可以得知「prompt」由两部分构成:
- 模板Template:例如 It was [MASK] 。
- 标签词映射M(y) :即[MASK]位置预测输出的词汇集合,与真实标签y构成映射关系。例如,标签positive对应单词great,标签negative对应单词terrible。
为了更好地理解什么是好的模板或标签词,论文对 SST-2 和 SNLI 数据集进行了试点研究,实验结果如下图所示:

可以看到,不同的模板和标签词选择其实对最终结果影响很大,使用相同「标签词」,即使对「模板」进行较小改动(如删除标点)也会呈现不同结果;使用相同「模板」,不同的「标签词」效果不一样,例如cat/dog和dog/cat就不同了,而互换great和terrible指标则会大幅下降。上述「prompt」是根据人工直觉设计的,可以更好的完成相关类似任务。但是,找到一个合适的、正确的「prompt」,既需要专业知识、又需要对语言模型内部的运作方式有着充分的理解。 因此,论文提出,我们应该试图去自动化构建提示: 自动构建一种与任务无关的廉价方法。
3. 自动选择标签词
论文将模板与标签词的自动化构建分开,首先研究了如何在给定固定模板 T 的情况下构建一个标签词映射 M(我愿称之为半自动化😅),使其可以最大限度提高微调的准确性。论文中采用了一种相对简单的搜索策略,可以分为三步:
- 通过未经微调的预训练模型,对于训练集中的每一个类别,选择top-k的单词使得条件概率最大。大白话来讲就是,先将每个类别中样例输入预训练模型,直接取[mask]处概率最大的top-k个单词作为该类别的候选标签词。
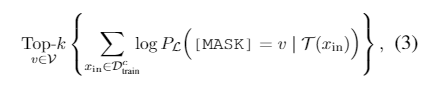
- 综合每个类别下的候选标签词,然后找出使得训练集正确率最大的top-n个分配方式。
- 进行微调,通过验证集的准确率从n个分配方式中选择最佳的一个标签词分配方式,构建标签映射关系M。
4. 自动生成模板
固定标签词,使用Google提出的T5模型自动生成模板。T5 经过预训练以在其输入中填充缺失的跨度(由 T5的mask 标记替换,例如 < X > 或 < Y >)。比如,给定一个mask后的输入“Thank you < X > me to your party < Y > week”,T5会生成这样一串文本“< X > for inviting < Y > last < Z >”,意味着“for inviting”可以替代< X >,“last”可以替代< Y >。论文认为T5这种方式特别适合模板的生成,因为无需事先为需要填充的位置指定token的数量。主要步骤如下:
- 固定标签词映射关系。
- 在标签词前后添加填充位(作者列出了三种填充位的方法,如下图),然后将其喂入T5模型中,自动生成模板序列。
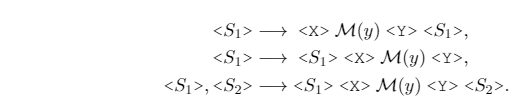
- T5模型输出解码时,采用beam search解码多个在训练集上表现良好的模板,然后对每一个候选模板进行微调,选择其中一个最佳模板。
5. 利用示例进行微调
除了引入prompt外,作者还加入了一些in-context信息,这里也是借鉴了GPT-3的思想。上面有提到,GPT-3采用添加上下文样本示例的方式进行微调,其随机挑选32个训练样本,以上下文的形式直接拼接到输入样本句子上,论文认为该做法存在两个问题:
- 可添加的演示样例的数量受模型的最大输入长度限制(GPT-3最大输入长度是2048,而bert只有512)
- 不同类型的大量随机示例混杂在一起,会产生很长的上下文,不利于模型学习。
为了解决这些问题,论文提出了一个简单的解决方案:对于每一个输入句子 x,从训练样本中的每一类中只随机采样一个样本,每个采样出来的样本都与模板拼接形成prompt,然后全部与输入样本拼接形成最终输入,拼接后如下图所示。

6. 实验结果
使用到的数据集(8个单句、7个句子对任务):

其中,|y|表示类别数(STS-B数据集是回归任务),L表示句子(对)的平均长度。
主要的实验结果如下图所示:

使用的模型是RoBERTa-large,每个类别采样K=16个样本模拟小样本学习,其中:
- Majority :使用训练集中频率最高的类别作为预测结果;
- Prompt-based zero-shot :零样本设置,使用手动设计的模板、并不引入额外的样本示例;
- “GPT-3” in-context learning:零样本设置,使用手动设计的模板,与GPT-3相同,从训练集中随机抽取示例,以上下文的形式添加到每个输入中。
- Fine-tuning :小样本设置,标准微调方式,引入新的参数。
- Fine-tuning(full) :使用全量的标注数据进行标准微调;
- Prompt-based FT(man) :本文的微调方法,使用人工手动设计的提示模板;
- Prompt-based FT(auto) :本文的微调方法,自动构建提示模板;
- +demonstrations :引入额外样本示例到上下文中;
通过上述实验结果可以发现:
- 基于提示的零样本预测(Prompt-based zero-shot)比直接使用多数类预测的性能更好,体现了 RoBERTa 中预编码知识的作用。
- GPT-3方式的上下文学习( “GPT-3” in-context learning)并不是总优于基于提示的零样本预测,这可能是因为较小的语言模型表达能力不足,无法像 GPT-3 那样使用现成的知识。
- 基于提示模板的微调方法,明显超越普通的标准微调方法。但CoLA(该任务主要是对一个给定句子,判定其是否语法正确)是一个例外,可能是因为其输入包含许多非语法句子,而这超出了预训练模型的表示范围。
- 一般来说,自动搜索的模板可以达到与手动相当甚至更高的结果,特别是对于构建强大的手动模板不太直观的任务(比如 TREC,QNLI和MRPC)
- 最后,在上下文中使用演示可以在大多数任务中获得一致的收益。总之,论文的组合解决方案——使用自动搜索模板和采样演示集进行微调——与标准微调相比,SNLI数据集提高了 30%,平均提高了 11%。虽然在小样本条件下,基于提示的微调可大幅领先标准微调 ,但其相较于使用全量数据的标准微调仍然落后。
此外,论文也将基于提示的微调和标准微调在不同K(每个类别下的标注样本数量)下进行了比较,如下图所示。在小样本的情况下,基于提示的微调始终优于标准微调,直到两者收敛于 K= 256。

7. 总结
本文介绍了一种简单但有效的小样本微调方法,主要包括:
- 使用基于提示的微调和自动搜索的提示;
- 选定任务演示(训练示例)作为输入上下文的一部分。
实验表明,该方法优于普通微调高达 30%(平均 11%)。但也有一些局限性:
- 该方法仍落后基于全量标注数据的标准微调方法;
- 基于beam search的自动提示生成方法意味着搜索空间不能过大,只能用于少量类别的分类任务中;
- 虽说是自动化生成提示,但生成模板前需要人工选择并确定标签词集合,生成标签词之前也需要人工确定模板,这有可能将搜索偏向于我们可能已经想象的搜索空间区域。
- 该方法更适用于特定的某些任务,这些任务 (1) 可以自然地作为“填空”问题; (2) 具有相对较短的输入序列; (3) 不包含许多输出类。问题 (2) 和 (3) 可能会通过较长上下文的语言模型得到改善,而对于在提示中无法直接制定的任务,例如结构化预测,这是未来工作需要解决的一个较大的问题。
参考文献:
【2020.12】Making Pre-trained Language Models Better Few-shot Learners (LM-BFF)
【预训练语言模型】Making Pre-trained Language Models Better Few-shot Learners(LM-BFF)
GPT-3的最强落地方式?陈丹琦提出小样本微调方法,比普通微调提升11%















 1439
1439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









