






SLAM面经
- 视觉SLAM相关
- 1、ORB-SLAM2为了特征点均匀化做了哪些处理?
- 2、H矩阵是什么?说出几个典型的使用场景
- 3、IMU预积分为什么可以避免重复传播?
- 4、so(3)和se(3)的区别是什么,如何在算法中使用?
- 5、VINs-Mono的初始化和ORB-SLAM3的初始化有啥区别?
- 6、为什么单目视觉SLAM 会有尺度不确定性,而双目视觉SLAM却不会有?简述单目视觉SLAM尺度不确定的原因?
- 7、BA当中雅可比矩阵的维度如何计算?
- 8、用自己的语言讲一下逆深度的含义和作用?
- 9、如何理解视觉重投影误差?
- 10、ORB-SLAM3与VINS-Mono的前端有何区别?并分析这些区别的优缺点
- 11、Ceres solver 怎么加残差的权重,这样做的原理是?
- 12、特征点法SLAM中,如何增强特征描述子之间的区分度?
- 13、在没有groundtruth情况下如何判断自己的置信度?
- 14、光流跟踪在快速运动过程中,跟踪容易失败,有什么解决办法?
- 15、简述一下PnP原理,适用的场景是什么?
- 16、简述如何在slam框架基础上添加语义分割网络?
- 17、ORB-SLAM中的B是什么?ORB和FAST的区别?
- 18、回环检测如何理解?请简述你熟悉的开源框架实现流程
- 19、说说多目相机的标定原理和主要流程
- 20、用自己的语言描述下预积分原理和过程?
- 21、光流法和直接法的区别
- 22、谈一谈你对边缘化的理解和它的意义?
- 23、剔除离群点有哪些方法?
- 24、SLAM后端不收敛怎么办?
- 25、在机器人仅定位阶段,如果实际地图与加载地图发生较大差异,应该如何处理?
- 26、PnP位姿最少需要几个点?有几组解?误差来源于哪里?
- 27、描述一下关键帧是什么?有什么用?如何选择关键帧?
- 28、ORB-SLAM3中如何存储关键帧、地图点及数据结构?
- 29、ORB-SLAM单目初始化的时候为什么要同时计算H矩阵和F矩阵?
- 30、ORB-SLAM的共视图是什么结构?内部如何存储的?
- 31、ORB-SLAM3中特征点是如何均匀化的?你还知道哪些均匀化方法?各有什么优劣
- 32、SLAM里多传感器松耦合与紧耦合的区别?
- 33、请用自己的语言阐述BA优化原理?
- 34、ORBSLAM怎么克服尺度漂移问题?
- 35、ORB-SLAM3回环过程是怎么实现的,要估计哪些量?
- 36、ORBSLAM的哪个部分最耗时?有什么加速建议?
- 37、什么情况下无法正确计算E矩阵,为什么?
- 38、SLAM与SFM的区别?
- 39、选取某个你熟悉的SLAM算法,谈谈可以提升算法的运行速度的思路?
- 40、说出ORB-SLAM的原版加速的一些track?
- 41、 ceres库为什么可以自动求解雅克比?
- 42、SLAM过程中如何降低动态物体的影响?
- 43、解释相机内参、外参的含义。图片放大两倍,内参如何变化?
- 44、左乘和右乘一个扰动是相同的吗?请解释原因
- 45、BA和pose graph 优化的区别是什么?
- 46、ceres库中huber什么作用?是怎么设置的 ?
- 47、单目地图初始化过程对相机运动有哪些要求?如何能够稳定快速的初始化?
- 激光SLAM
- 1、LOAM和LeGO-LOAM的区别
- 2、请对比几种激光配准算法(ICP,NDT,PL-ICP,CSM-cartographer)的优缺点
- 3、LEGO-LOAM中划分出地面点与非地面点的目的是什么?首先一点共识就是lego-loam适用于平坦路面,因此其划分路面点和非路面点是算法对平坦路面的特殊处理:
- 4、LeGO-LOAM怎么判断找到的最近5个点是不是线特征?
- 5、Cartographer算法后端有哪些问题?请提供优化思路
- 6、激光SLAM中回环检测的主流方法有哪些?请选一个熟悉的方法详细分析?
- 7、三维点云地图怎么转换成二位概率栅格地图?
- 8、lego-loam 中关键帧提取的依据是?
- 9、请描述点云运动畸变的校正过程?
- 10、LIO-SAM相对LEGO-LOAM的改进有哪些?
- 11、请简述cartographer中分支定界的原理?
- 12、相机和激光雷达联合标定的精度如何评估?
- c++
- 1、虚函数有什么作用,析构函数为什么定义为虚函数?
- 2、include 后面使用双引号 " " 和尖括号 <> 的区别
- 3、常量指针和指针常量有什么区别?
- 4、C++中智能指针相比普通指针的优势和劣势?
- 5、在函数定义的时候,经常看到使用引用作为函数的参数或者返回值,这样做的好处在哪里?
- 6、无序map和有序map的查找复杂度?
- 7、C++中释放内存的方式有 delete 和 delete[] 两种,它们的区别是什么呢?
- 8、C++11新特性
- 9、什么情况会内存泄漏?
- 10、类的拷贝构造函数和拷贝赋值运算符有何不同?使用需要注意什么?
- 11、如何找四边形的边界,给出C++编程实现思路及伪代码?
- 12、C++中的智能指针是如何工作的?
- 13、请说说new/delete与malloc/free的区别?
- 14、什么是运行时多态?
- 15、谈谈你对C++多线程的理解,并列举在SLAM系统中的具体应用
- 16、虚函数相关
- 17、纯虚函数是什么?有什么用?
- 18、构造函数和析构函数可以是虚函数吗?
- 19、sizeof 与 strlen 的区别?
- 20、strcpy 、strncpy 和 memcpy 的区别?
- 21、哈希冲突是什么?如何解决?
- 22、右值引用是什么,它有什么用?
- 其他
下面是来自各个渠道总结的,如果有什么不对的或需要补充的欢迎评论区补充,一起学习一起进步…
视觉SLAM相关
1、ORB-SLAM2为了特征点均匀化做了哪些处理?
- 构造图像金字塔,对每层金字塔计算目标特征点数目
- 对每层图像做均匀分块划分,对每个块提取目标数目特征点
- 对所有提取到的的特征点进行四叉树均匀化
具体做法:
1)构建图像金字塔,构建八层的图像金字塔,在每层图像上提取特征点,具体每层提取多少数量的特征点都事先通过缩放因子计算好;
2)提取的时候,会将图像划分成一个个网格,分别在网格上进行特征点的提取。这时候特征点的数量往往是超过我们需要的点的数量,且只是初步进行了一个均匀化;
3)紧接着会使用四叉树均匀化的方法,这里就涉及到提取器节点的这么一个类。就是最开始整幅图像是一个节点,然后会对该节点进行划分,分成四个,然后将特征点都分别分配到这四个节点。后面就是不断重复类似的操作,划分节点,直到节点数等于所需的特征点数,然后只保留响应值最大的那个特征点。其实这里的操作也有点是把图像进行分块,直到分出来的块数等于所需的节点数,然后只留下质量最好的特征点。做完均匀化之后还会利用灰度质心法计算
4)通过上面的步骤就提取完特征点,然后这时候特征点的坐标还是不同图层下的坐标,因此需要将所有特征点坐标转到第0层图像下的坐标;
5)然后会进行高斯模糊,计算描述子
2、H矩阵是什么?说出几个典型的使用场景
H矩阵指单应矩阵,当相机发生纯旋转时,此时平移为零,基础矩阵自由度下降,基础矩阵误差较大,选用单应矩阵来恢复位姿。一般如果所有特征点都落在同一平面上,可以利用这种矩阵进行运动估计。
3、IMU预积分为什么可以避免重复传播?
IMU预积分与通常积分相比,解决了初始状态更新时以及加速度计、陀螺仪偏差变化时所导致的积分重新计算问题。其主要思路是计算两个关键帧之间的状态增量,当初始状态变化,就在原来增量基础上乘以初始状态的变化量;当偏差变化时,则通过求取预积分量关于偏差的雅各比,实现预积分的一阶线性近似更新。
4、so(3)和se(3)的区别是什么,如何在算法中使用?
so3旋转矩阵的李代数表示,se3位姿变换矩阵的李代数表示,二者可以通过指数-对数关系实现转换,sophus中将旋转矩阵利用Log函数转换成对应的旋转向量,在算法中扰动模型更新时,常将一个扰动向量通过指数映射关系转换成相应的扰动矩阵,左乘或右乘旋转矩阵实现更新
5、VINs-Mono的初始化和ORB-SLAM3的初始化有啥区别?
| 初始化异同 | ORB-SLAM3 | VINS-MONO |
|---|---|---|
| 成功的准则 | 加速度大于重力的0.5%(引用论文里有)代码中没看到 | 估计出来的重力大小误差在10%以内,IMU的测量值有一定的变化范围 |
| 是否估计加速计bias | 同时估计了加速度计和陀螺仪的bias | 不估计加速度计的bias,认为加速度bias与重力(g)值相比很小,难以估计 |
| 有无单独估计陀螺仪bias | 陀螺仪bias放在目标函数中一起估计 | 陀螺仪bias单独拿出来估计 |
| 尺度恢复策略 | 初始值设置为1,初始化后100内每隔10秒优化一次尺度 | 只在初始化的时候恢复该尺度 |
| 姿态参数化 | SO(3) | 基于四元数 |
| 惯性系对其方式 | 优化过程中同时优化惯性系到第一帧的旋转矩阵 | 优化得到重力在第一帧的测量值,然后对重力重新参数化,以限制其模长,最后重新来一次优化 |
| 求解过程 | 三次非线性优化(LocalMapping, Inertial only optimization, FULL BA) | 三次非线性优化(sfm, 求解陀螺仪bias和Full BA), 两次线性求解(求尺度和速度的初值)和求相机-IMU外参 |
| 相同点 | 都以视觉作为基础,最终都对齐到惯性系,都在固定窗口内进行初始化。最后都进行FullBA,完成初始化 |
6、为什么单目视觉SLAM 会有尺度不确定性,而双目视觉SLAM却不会有?简述单目视觉SLAM尺度不确定的原因?
从理论上来讲,单目视觉SLAM的初始化运动是一个2D-2D的求解问题,是通过对极几何解决的。我们通过本质或者基础矩阵的分解来得到相机运动,对极约束是等式为0的约束,因此具有尺度等价性,由分解出的平移量乘以任意非零常数任然满足对极约束,因此平移量是具有一个不确定的尺度的,即我们放大任意倍数,都是成立的,导致了单目尺度的不确定性。从直觉感官角度来讲,从一张图像中,我们无法判断图像中物体的实际大小,因为不知道物体的远近。双目相机拍摄一次能够获得具有视差的左右目两张图像,在已知基线的情况下,计算视差,可以通过三角测量原理直接得出深度信息,因此不存在尺度不确定性。
7、BA当中雅可比矩阵的维度如何计算?
如纯视觉情况下,误差量要么是重投影误差,要么是光度误差,维度都为2。
此时状态量有两个:位姿和空间点,那么空间点维度为3,李代数表示位姿的话维度为6。
所以最后雅可比就是2维误差量分别对6维位姿(2x6)、3维空间点(2x3)求导,结果就是2x9。
所以最终结论就是:雅可比维度=误差维度x状态量维度
8、用自己的语言讲一下逆深度的含义和作用?
1.和3D位置相比,逆深度维度更小;
2.在实际应用过程中,可能会看到类似天空这样比较远的点,导致z很大。那么即使产生了微小的变化量,也会给优化带来巨大的干扰。但是使用逆深度就可以这种情况。
3.逆深度的分布更符合高斯分布。
9、如何理解视觉重投影误差?
在SLAM初始化完成后,我们可以通过世界坐标系中的3D点位置和图像中的2D点匹配关系,由PNP算法初步求解两帧图像间的位姿变换。这个位姿变换并不准确,因此采用视觉重投影误差的方式进行进一步优化。重投影,意为利用我们估计的并不完全准确的位姿对三维空间点再次投影。我们已知特征点在图像中的实际位置,即观测值,利用初步求解的位姿,通过投影关系,再次将世界坐标系中的三维点投影到二维成像平面上,得到特征点像素坐标的估计值,与实际的观测值作差,对于n个特征点,构建最小二乘问题,认为差值越小,越符合实际的投影,估计越准确,最后得到优化后的位姿。
10、ORB-SLAM3与VINS-Mono的前端有何区别?并分析这些区别的优缺点
ORB-SLAM3跟踪线程的输入为图像帧(单目/双目/RGB-D)及IMU数据。对于图像数据,首先对图像进行金字塔分层,对每层金字塔提取ORB(Fast角点+二进制描述子)信息,并基于四叉树进行特征点均匀化,同时进行高斯模糊以及去畸变。之后进行地图初始化,ORB-SLAM3和ORB-SLAM2一样都是使用纯视觉的方法进行初始化,再之后开始进行两个阶段的跟踪。第一阶段包括恒速模型跟踪、参考关键帧跟踪以及重定位跟踪,目的是为了跟得上,但估计出的位姿可能没有那么准确。第二阶段是局部地图跟踪,是利用PNP进行最小化重投影误差求解,得到更准确的位姿。最后决定是否新建关键帧。对于IMU信息,ORB-SLAM3还需要进行IMU预积分,但IMU三个阶段的初始化是在局部建图线程完成。此外,在恒速模型跟踪中,如果有IMU数据,恒速模型的速度将根据IMU信息得到。有IMU的话,还会有一个RECENT_LOST来记录刚刚丢失的状态。
VINS-Mono前端的输入为单目RGB图像和IMU数据。对于RGB信息,首先对图像应用金字塔LK光流检测算法,这里金字塔的使用不同于ORB-SLAM3那样进行不同分辨率的特征提取,而是避免跟踪陷入局部最优。之后进行特征点均匀化,VINS的特征点均匀化策略是以特征点为中心画圈,这个圆内不允许提取其他特征点,并使用逐次逼近去畸变。再之后使用OpenCV提供的光流跟踪状态位、图像边界、对极约束进行outlier的剔除。最终前端输出结果包含特征点像素坐标、去畸变归一化坐标、特征点ID以及特征点速度。对于IMU信息,VINS-Mono还需要计算IMU预积分。ORB-SLAM3和VINS的预积分都没有依赖GTSAM,都是自己实现的。
具体的优缺点上,ORB-SLAM3是对每一帧图像都提取Fast角点和BRIEF描述子,并进行描述子匹配。而BRIEF描述子的计算和匹配非常耗时。虽然ORB-SLAM3使用了SearchByBoW等策略加速匹配,但仍然需要较多的计算时间。相较之下,LK光流只需要提取每帧图像中跟丢的特征点,计算时间大大降低。不过ORB特征的全局一致性更好,在中期、长期数据关联上要优于光流法。我觉得VINS课程讲师的描述很贴切:“VINS更适合一条路跑到头进行定位建图,ORB-SLAM3更适合具有回环的轨迹”
11、Ceres solver 怎么加残差的权重,这样做的原理是?
残差加权重的话,需要在代价函数表达式里加入信息矩阵。但Ceres Solver中只接受最小二乘优化,也就是说代价函数定义(自动求导和数值求导是重载括号运算符bool operator(),解析求导是重载虚函数virtual bool Evaluate())里没办法直接写信息矩阵表达式。因此需要对信息矩阵进行Cholesky分解,把分解后的矩阵跟原来的残差乘到一起变为新的残差。
12、特征点法SLAM中,如何增强特征描述子之间的区分度?
ORB中有个方法采用运动模型,利用上一帧位姿粗略估计当前针位姿,然后利用3D-2D的匹配,计算投影点的附近圆形区域内所有特征点的匹配程度,减少匹配的计算量
提升精度方面,最近看到一个GMS的匹配算法。考虑特征点附近区域内特征描述子点来提高特征描述子的区分度
13、在没有groundtruth情况下如何判断自己的置信度?
- 走一个回环到原地 看看误差
- 如果是室外环境的话,可以用谷歌地图,像VINS论文里在港科大校园里跑的那样。有雷达的话可以把雷达轨迹当作视觉的参考。然后就是找同类型的主流算法做对比了,跟主流算法轨迹差不多应该也能说明精度。
14、光流跟踪在快速运动过程中,跟踪容易失败,有什么解决办法?
硬件加持:
- 采用全局快门相机;
- 引入imu(解决相机过速退化的外部硬件首选),通过imu得到一个相对准确的位姿,这样光流法跟踪最小化光度误差的时候可以得到一个较好的像素点位置初值。
算法加持: - 加上光度标定(参考dso);
- 引入线性约束(参考直接法点线slam的工作,如edplvo)
- 参考svo直接法➕间接法模式。
- 利用多层金字塔光流跟踪,先在分辨率小的金字塔层上进行光流跟踪得到在该层金字塔上的最优像素点坐标,然后恢复到下一层金字塔表示的像素点坐标,下一层金字塔以该像素点坐标为初值,在进行光流跟踪,以此类推,直到最底层金字塔
15、简述一下PnP原理,适用的场景是什么?
PnP(Perspective-n-Point)是求解 3D 到 2D 点对运动的方法。它描述了当我们知道n 个 3D 空间点以及它们的投影位置时,如何估计相机所在的位姿。两张图像中,其中一张特征点的 3D 位置已知,那么最少只需三个点对(需要至少一个额外点验证结果)就可以估计相机运动。特征点的 3D 位置可以由三角化,或者由 RGB-D 相机的深度图确定。因此,在双目或 RGB-D 的视觉里程计中,我们可以直接使用 PnP 估计相机运动。而在单目视觉里程计中,必须先进行初始化,然后才能使用 PnP。3D-2D 方法不需要使用对极约束,又可以在很少的匹配点中获得较好的运动估计,是最重要的一种姿态估计方法。
16、简述如何在slam框架基础上添加语义分割网络?
最简单的思路就是做动态特征点剔除,在图像帧上使用YOLO等目标检测网络,或者使用SegNet等语义分割网络检测动态物体,对于候选区域就不再提取特征点了,然后进行运动一致性检查进一步提高检测精度。
这种方法高效、鲁棒。缺点主要有两个,一个是只能检测训练过的类别,对于未训练的运动目标无法检测。另一个是很难检测目前静止的潜在运动对象。
17、ORB-SLAM中的B是什么?ORB和FAST的区别?
ORB的B指的是brief描述子,是一个二进制的描述子,计算和匹配的速度都很快。区别在于ORB特征描述子具备旋转不变性,而FAST不具备。并且orb-slam利用灰度质心法计算了旋转不变性,利用金字塔在不同分辨率图像上进行特征提取和匹配。
17.1 ORB特征的旋转不变性是如何做的,BRIEF算子是怎么提取的?
ORB特征点由关键点和描述子两部分组成,关键点称为“Oriented FAST”,是一种改进的FAST角点,相较于原版的FAST,ORB通过灰度质心法计算特征点的主方向(对特征点周围像素的坐标根据灰度值加权平均得到中心坐标)然后计算旋转后的BRIEF描述子。
BRIEF描述子通过对前一步关键点的周围图像区域选取128对点,根据每对点灰度值大小关系分别取0、1,得到128维0、1组成的向量即描述子。
18、回环检测如何理解?请简述你熟悉的开源框架实现流程
SLAM运行过程中会产生轨迹漂移,回环检测就是当机器人回到以前运行过的场景时,利用约束将轨迹漂移拉回来。
视觉SLAM回环的主流方法就是词袋,即用词袋建立数据库,看关键帧中有没有在数据库中有比较“接近”的关键帧。但是词袋的使用方式有所不同。
ORBSLAM3的闭环线程流程:
- 首先检测缓冲队列中是否有新的关键帧进来;
- 然后检测共同区域,如果检测到公共区域并且公共区域发生在当前地图和非活跃地图就执行地图合并,如果公共区域在当前地图内,就执行闭环。
- 具体的公共区域检测流程也和ORBSLAM2不一样,ORB2是连续3个闭环候选关键帧组都检测到了回环关系才认为是回环,要检查时间连续性和几何连续性,延时较高,容易漏掉回环。而ORB3的重点是检查几何一致性,主要是说当前关键帧的5个共视关键帧只要有3个和候选关键帧组匹配成功,就认为检测到了共同区域,如果不够3个,再检查后续新进来关键帧的时间一致性,以略高的计算成本为代价,提高了召回率和精度。之后利用共视关系来调整位姿和地图点。
VINS-Mono的闭环检测:
- 首先对所有新老角点进行BRIEF描述,计算当前帧与词袋的相似度分数,进行闭环一致性检测,获得闭环的候选帧。
- 当检测到闭环后,开启快速重定位,将之前帧的位姿和相关特征点作为视觉约束项,加到后端非线性优化的整体目标函数中,根据优化得到的相对位姿关系,对滑窗内所有帧进行调整。当从滑窗内滑出的帧与数据库中的帧为闭环帧时,则对数据库中的所有帧进行闭环优化。
19、说说多目相机的标定原理和主要流程
对于双目相机来说,首先要对左右目的两个相机进行单目标定,得到各自的内参矩阵和畸变系数。然后标定左右目相机之间的外参,当两个相机位于同一平面时,旋转矩阵可近似为单位阵,标定平移外参可得到基线长度b。
主要流程为:
- 准备一张棋盘格,粘贴于墙面,用直尺测量黑白方格的真实物理长度。
- 使用双目相机分别从不同角度拍摄得到一系列棋盘格图像。
- 进行左目相机标定,得到左目内参矩阵K1、左目畸变系数D1。
- 进行右目相机标定,得到右目内参矩阵K2、右目畸变系数D2。
- 将标定得到的参数K1、K2、D1、D2作为输入,再同时利用左右目对齐后的棋盘格图片,调用OpenCV的stereoCalibrate函数,输出左右目的旋转矩阵R、平移向量T。
- 基于标定得到的K1、K2、D1、D2、R、T进行双目视觉的图像校正。
20、用自己的语言描述下预积分原理和过程?
IMU可以获得每一时刻的加速度和角速度,通过积分就可以得到两帧之间的由IMU测出的位移和旋转。但IMU的频率远高于相机,在基于优化的VIO算法中,当被估计的状态量不断调整时,每次调整都需要在它们之间重新积分,传递IMU测量值,这个过程会导致计算量的爆炸式增长。因此提出了IMU预积分,希望对IMU的相对测量进行处理,使它与绝对位姿解耦,或者只要线性运算就可以进行矫正,从而避免绝对位姿被优化时进行重复积分。
ORB-SLAM3没有依赖GTSAM库,整个预积分的过程都是自己实现的。具体思路为:
- 由积分引出预积分,得到旋转、速度、位置的预积分表达式,重点是消除第i时刻对积分的影响并保留重力。、
- 噪声分离,推导出标定好的imu噪声对预积分的影响。
- 噪声递推,之前的推导结果要么是求和,要么是多积导致每次新来一个数据都需要从头计算,这给计算平台来带来资源的浪费,因此要推出误差的递推形式。还需要计算协方差矩阵
- 由于偏置在VIO算法中会作为状态量来优化,因此要推出当偏置变化时直接求得新的预积分结果。
- 定义残差对于旋转、速度、位置的残差。
21、光流法和直接法的区别
光流法和直接法都是基于灰度不变假设。光流法提取关键点后,根据灰度不变假设得到关于像素点速度的欠定方程,之后通过对极约束、PNP、ICP计算R、t。但光流法只是一个粗略匹配,很容易陷入局部极值(VINS使用金字塔来改善),直接法相当于在光流基础上对前面估计的相机位姿进一步优化,即将下一帧位置假设为1/z*K(RP+t),之后利用光度误差来优化R、t。
光流法和直接法根据提取关键点数量可分为稀疏、半稠密、稠密。相较于特征点法来说,提取速度很快,但要求相机运动较慢,或者采样频率较高,对光照变化也不够鲁棒。
22、谈一谈你对边缘化的理解和它的意义?
SLAM属于渐进式算法,需要使用一定数目的关键帧进行BA运算以求得位姿和地图点。但随着关键帧数目的增多,滑窗(或者说ORB-SLAM3的共视图)的计算量会越来越大。因此需要想办法去掉老的关键帧,来给新关键帧腾地方。直接做法是把最老帧以及相关地图点直接丢弃,但最老帧可能包含了很强的共视关系,直接删除可能会导致BA效果变差。
而边缘化就是指,既从滑窗/共视图里剔除了老的关键帧,又能保留这个关键帧的约束效果,其核心算法是舒尔补。总体来说,就是本身要被扔掉的最老帧,他可能和后面的帧有约束关系(一起看到某个地图点,和下一帧之间有IMU约束等),扔掉这个第0帧的数据的话,这些约束信息需要被保留下来。相当于建立起地图点和地图点之间的约束关系。
23、剔除离群点有哪些方法?
- 只对多个图像帧都观测到的点进行BA运算,观测太少的点就不参与优化了
- ORB-SLAM2/3中对于深度超过40倍基线的点,由于估计的平移分量非常不准,因此认为是外点,剔除
- 在重投影计算时,如果投影误差超过一定阈值,则不让这个点参与优化,ORB-SLAM2/3是通过卡方检验实现
- VINS-Fusion将追踪到的光流再反向追踪回来,然后比较追踪回来的特征点与原先的特征点之间的距离,过大就认为是外点去掉
- VINS-Mono中通过opencv的findFundamentalMat函数自带的ransac来消除外点
- 鲁棒核函数
- MAD(median absolute deviation)算法: 即绝对中位值偏差,其大致思想是通过判断每一个元素与中位值的偏差是否处于合理的范围内来判断该元素是否为离群值.
- 标准差法-3σ法: 因标准差本身可以体现数据的离散程度,和MAD算法类似,只是标准差法用到的不是中位值,而是均值,并且离群阈值为3σ,即|x_out - x_mean| > 3σ.
- 百分位法: 百分位算法类似于比赛中"去掉几个最高分,去掉几个最低分"的做法,基本步骤如下: 1)将数据值进行排序,一般用升序排序,这里排序函数可自定义;2)去掉排位百分位高于90%或排位百分位低于10%的数据值.
24、SLAM后端不收敛怎么办?
- 第一次进入后端优化就不收敛,这时候就应该分析优化变量和约束条件的理论和code是否正确;
- 前面优化收敛,突然当前优化不收敛,这时候需要判断下是否加入了错误的回环约束:删除回环约束,重新本次优化,如果OK,则应该是回环错误。
- 迭代次数不够,增加迭代次数。
- 优化方法的问题:使用高斯牛顿法时,可能出现JJT(H的近似)为奇异矩阵或者病态的情况,此时增量稳定性较差,导致算法不收敛。(残差函数在局部不像一个二次函数,泰勒展开不是很准确),导致算法不收敛。而且当步长较大时,也无法保证收敛性改进更换增量方程的求解方法,如果使用的是高斯牛顿法,可尝试使用LM法算法。
25、在机器人仅定位阶段,如果实际地图与加载地图发生较大差异,应该如何处理?
可以减小环境匹配约束(如scan-to-map)的权重,具体可以通过设置核函数:环境匹配残差较小时正常引入环境约束,过大时根据残差与设定阈值的比例设置权重。
26、PnP位姿最少需要几个点?有几组解?误差来源于哪里?
PnP位姿估计最少需要7个点(3对点以及一个验证点),通过SVD分解求解位姿时会得到4组解。
误差来源主要是:
- 特征匹配正确性(数据关联正确程度)
- 测量数据的噪声情况(特征点是否去畸变,是否坐标精确)
- 其次光照变化、运动变化都会带来误差。
27、描述一下关键帧是什么?有什么用?如何选择关键帧?
关键帧是在一系列普通帧中选择出的最有代表性的一帧。
- 降低信息冗余度。
- 减少待优化的帧数,节省计算资源。
- 选取关键帧时进行了筛选,防止无用或错误信息进入优化过程。
选取的指标主要有(都要满足):
- 距离上一关键帧的帧数是否足够多(时间)。
- 距离最近关键帧的距离是否足够远(空间)/运动。比如相邻帧根据pose计算运动的相对大小,可以是位移也可以是旋转或者两个都考虑,运动足够大(超过一定阈值)就新建一个关键帧,这种方法比第一种好。但问题是如果对着同一个物体来回扫就会出现大量相似关键帧。
- 跟踪质量(主要根据跟踪过程中搜索到的点数和搜索的点数比例)/共视特征点
28、ORB-SLAM3中如何存储关键帧、地图点及数据结构?
关键帧和地图点都是以类的方式存储的。
关键帧中除了包括位姿之外,还包括相机内参,以及从图像帧提取的所有ORB特征(不管是否已经关联了地图点云,这些特征点都已经被畸变矫正过)。
地图点中除了存储空间点坐标,同时还存储了3D点的描述子(其实就是BRIFE描述子),用来快速进行与特征点的匹配,同时还用一个map存储了与其有观测关系的关键帧以及其在关键帧中的Index等等。
29、ORB-SLAM单目初始化的时候为什么要同时计算H矩阵和F矩阵?
H矩阵和F矩阵适用于当前场景的不同状态。
F矩阵(基础矩阵)在纯旋转以及空间点在一个平面上的情况时效果不好,H矩阵(单应矩阵)推导即针对特征点在同一平面时计算出的,一定程度上弥补其缺陷。
因此当计算出两个矩阵的值后分别计算重投影误差得到分数,比较哪个矩阵的得分占比更高则取哪个矩阵恢复位姿,在ORB-SLAM系列中作者倾向于采取H矩阵恢复,当比值大于0.4时即选择H矩阵。
30、ORB-SLAM的共视图是什么结构?内部如何存储的?
- ORB-SLAM中由关键帧构成了几种重要的图结构,包括共视图、本质图和生成树;
- 共视图是无向加权图,每个顶点都是关键帧。如果两个关键帧之间满足一定的共视关系(至少有15个共视地图点),则它们就会连成一条边,边的权重是共视点数;
- ORB-SLAM使用两个链表
list<KeyFrame*>、list<int>分别保存按照权重从大到小排列后的共视关键帧及其权重。
31、ORB-SLAM3中特征点是如何均匀化的?你还知道哪些均匀化方法?各有什么优劣
- 构建图像金字塔,构建八层的图像金字塔,在每层图像上提取特征点,具体每层提取多少数量的特征点都事先通过缩放因子计算好;
- 在提取阶段将每层图像金字塔分割为一个个网格,分别在每个网格内提取特征点并采用非极大值抑制。(对关键点进行非极大值抑制,即抑制掉那些周围有更强响应的关键点,只保留那些相对来说比较独特或者突出的关键点。这样可以使得检测到的关键点更加鲁棒,同时也能够减少冗余的关键点,提高算法的效率。)
- 进一步用四叉树对上述提取的特征点均匀化。这里用到提取器节点的这么一个类。就是最开始整幅图像是一个节点,然后会对该节点进行划分,分成四个,然后将特征点都分别分配到这四个节点。后面就是不断重复类似的操作,划分节点,直到节点数等于所需的特征点数,然后只保留响应值最大的那个特征点。
vins:设置mask限制特征点之间的距离,在现有的特征点范围内画一个mask在这个mask范围内不再提取特征点。
32、SLAM里多传感器松耦合与紧耦合的区别?
以IMU和相机两种传感器为例。视觉传感器和惯性传感器有一定的互补性,IMU更适合估计短时间的高速运动,视觉传感器更适合估计长时间低速的运动。
两种耦合方式的区别:
- 松耦合:IMU和相机分别进行自身运动估计,然后对位姿估计结果进行融合。松耦合情况下,存在两个优化问题,即视觉测量优化问题和惯性测量优化问题。两个优化问题分别利用视觉测量信息(如检测到的特征点)和惯性测量信息(加速度、角速度)对各自的状态向量进行优化,最终结果只是把两个优化过程得到的位姿估计结果进行融合。
(2) 紧耦合:IMU和相机共同构建运动方程和观测方程,再进行状态估计。紧耦合方式只存在一个优化问题,它将视觉和惯性放在同一个状态向量中,利用视觉测量信息(如特征点)和惯性测量信息构建(如加速度、角速度)包含视觉残差和惯性测量残差的误差项,同时优化视觉状态变量和惯性测量状态变量。
一般采取紧耦合方案,因为这样可以更好的利用两类传感器的互补性质,使两类传感器相互校正,达到更好的效果。
对于更多传感器,紧耦合只是根据各传感器的特点,在系统状态向量中加入新的状态,同时利用各传感器的测量信息构建各自的误差项,最终通过使总误差最小,对状态向量进行优化。
33、请用自己的语言阐述BA优化原理?
BA是指通过调整相机的位姿和特征点的3D位置,使总体的重投影误差最小。
从非线性优化的角度来看,代价函数是特征点的像素坐标与三维点经过投影后的像素坐标进行作差得到的重投影误差,优化变量是相机位姿和三维点位置,优化方法一般可以采取高斯牛顿法(GN)或列文伯格-马夸尔特法(LM)。
BA优化的过程是通过对最小二乘形式的代价函数进行求解,将相机位姿和三维点位置(优化变量)从粗略的初始值调整到更精确的值。
34、ORBSLAM怎么克服尺度漂移问题?
单目vo的尺度漂移是由于,尺度不确定,以及位姿估计,地图点的估计。位姿估计和地图点估计相辅相成,计算误差,测量误差,会在这个过程中一步一步的传播下去。
要解决这个尺度漂移的话问题,可以考虑中断这个误差传播链条,比如双目,rgbd相机可以直接计算特征点的深度,所以地图点的误差就被固定在一定范围,从而限制了整个估计的误差传播发散。
同时imu传感器可以提供绝对尺度,虽然imu位姿长时间发散严重,但是短时间内的位姿估计可以认为误差有个上限,从而vio也可以在位姿估计上限制误差传播。
35、ORB-SLAM3回环过程是怎么实现的,要估计哪些量?
- 检查是否有新关键帧,如果检测到公共区域,非活跃地图则地图融合,活跃地图则闭环
- NewDectectCommonRegions()寻找后选关键帧,找到当前帧共有公共单词的关键帧,计算得分,得到三个组的最高分关键帧。
- 定义局部窗口,在窗口内找到候选帧和当前关键帧匹配的地图点。
- 使用最近邻ORB特征点对之间的几何约束关系,通过RANSAC算法估计当前帧与之前某一帧之间的运动模型
- 将之前所有关键帧及其之间的相对位姿组成的图形优化,以最大化一个目标函数,有重投影误差、平移和旋转的惩罚项
- 如果回路检测失败,则尝试通过当前帧与之前某一关键帧之间的RANSAC检测和全局优化来重定位,即计算当前帧的绝对位姿。
36、ORBSLAM的哪个部分最耗时?有什么加速建议?
全流程BA优化最耗时,但优化是单独一个线程,且不要求实时进行,所以没有特别强的加速需求。一般加速考虑从前端跟踪部分着手,特征提取方面ORB速度已经是目前比较快的策略,但特征匹配比较耗时,可以考虑采用GMS等更新的特征匹配算法替换。
37、什么情况下无法正确计算E矩阵,为什么?
当相机做纯旋转,平移为0的时候无法计算E矩阵,因为推导本质矩阵E和基础矩阵F的过程是通过两不同位置对同一3D点观测列两组方程,联立推导出对极约束,而当没有平移时不满足不同位置,推到中的t=0,本质矩阵E也为0,无法计算。
38、SLAM与SFM的区别?
区别:
- slam的目标是定位,SFM的目标是3D重建;
- SLAM要求实时,数据是线性有序的,无法一次获得所有图像,部分SLAM算法会丢失过去的部分信息;基于图像SFM不要求实时,数据是无序的,可以一次输入所有图像,利用所有信息
- SLAM是个动态问题,会涉及滤波,运动学相关的知识,而SFM主要涉及的还是图像处理的知识;
联系:
基本理论都是一致–多视图几何。传统方法都是做特征点提取与匹配,都需要最小化视觉投影误差。
39、选取某个你熟悉的SLAM算法,谈谈可以提升算法的运行速度的思路?
ORB-SLAM2和3系列在特征匹配部分可以采用GMS算法,准确率更高速度也能适当提升;另外前端跟踪部分可以用光流法跟踪普通帧,关键帧仍采用特征点进行跟踪,这个应该已经有论文实现了;但对这种方法应该可以调整关键帧插入策略,在用光流法跟踪大部分普通帧之后可以根据设计当前环境的光流跟踪难度系数,避免出现光流跟不上的情况。
40、说出ORB-SLAM的原版加速的一些track?
- 求本质和单应矩阵开双线程加速;
- 计算关键点灰度质心方向时,利用圆的对称性每次循环求解对称的两组值;
- 最后使用FastAtan2函数加速计算角度;
- 通过近邻窗口半径(提取特征时预先分配至网格)、投影后坐标窗口附近、Bow词袋等几种方法加速特征匹配;
- 每次先将某些变量的倒数值计算出来存放至inverse变量,减少函数循环计算时除法的计算量;
- 循环或函数开始前先把vector等变量reserve扩容至足够大,防止循环时因容量不够发生临时扩容;
- 计算双目特征匹配时,只在某近邻像素行范围内查找,不全局暴力匹配;
- 访问多线程加锁数据时,快速解锁,避免长时间独占共享数据;
- 正确选用合适的容器,如存储特征点的vector(频繁随机访问,变化较小:提取完成后很少再进行插入和删除);存储共视关键帧的map容器(单次查询是否为共视帧的性能稳定,个人猜测不用unordered map的原因是求共视关键帧排序时需要使用迭代器迭代,而无序map迭代性能差);四叉树均匀化分配特征点以及记录连接关键帧、局部地图点(如lLocalMapPoints)时使用list链表(不经常随机访问,而是遍历迭代访问,经常需要插入,list插入效率高);Map中的地图点和关键帧用set容器,因为经常需要做插入删除动作(印象中orbslam2这里地图点的删除没实现,可能会造成内存泄漏)set有序,无重复元素,方便转vector(返回关键帧集合转化的vector给可视化和BA优化程序用)
41、 ceres库为什么可以自动求解雅克比?
Ceres库中的自动求导是基于Jet类型实现的,利用链式法则来计算函数的导数。在计算图中,每个节点代表一个计算步骤,节点的输入是前一步的输出,输出是当前步骤的计算结果,节点是Jet类型,其向量部分存储该点处函数的导数值
42、SLAM过程中如何降低动态物体的影响?
- 利用深度学习技术识别图像中特定的物体,结合运动物体的先验知识(汽车、行人、动物),去除潜在的动态区域,该方法是最为简单高效的方案,也是目前主流的技术方案。但对于移动的椅子、停在路边的汽车等,该方法往往会做出错误的判断。
- 多视图几何检测动态特征点,原理是用多帧图像的位姿约束,剔除误差较大的特征点。常用的方法为极线约束。
- 对于两张图像,稠密光流能很好的描述每个像素在二维平面中运动的情况,是检测运动区域很好的方法,一般来说运动物体的区域所产生的光流会远高于静态的背景区域。
43、解释相机内参、外参的含义。图片放大两倍,内参如何变化?
相机内参在相机出厂之后是固定的,有fx,fy,cx,cy四个参数,相机内参描述了从图像坐标系到像素坐标系之间的关系,即进行单位变换和平移。
- 在图像坐标系中坐标x,y的单位是米,像素坐标系中单位是像素:fx,fy是将单位为米的f缩放为单位为像素;
- 在图像坐标系中图像中心为坐标系原点,像素坐标系中左上角为坐标系原点:cx,cy分别代表两个坐标系原点在x,y方向上的平移,一般是图像长和宽的一半。
四个参数的单位均为像素。所以当图片方法两倍,四个内参数均放大两倍。
相机外参即相机的位姿R,t,描述的是世界坐标系和相机坐标系之间的关系,外参会随着相机运动发生改变。
44、左乘和右乘一个扰动是相同的吗?请解释原因
定义Global坐标系为固定坐标系,如导航中常用的东北天坐标系;local坐标系为绑定在运动体上的坐标系,是随动的。
一般旋转扰动的定义是在机体local坐标系上添加一个小的旋转θ ,这样扰动的旋转角比较小,可以保证比较好的线性而且避免奇异性。
- 当
pose表达在Global坐标系时,根据旋转的叠加方式,添加的是右扰动; - 当
pose表达在local坐标系时,根据旋转的叠加方式,添加的是左扰动。
原因见下图:
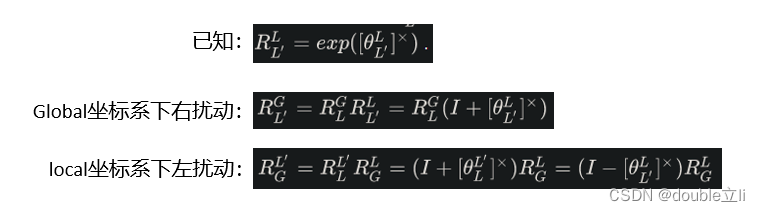
45、BA和pose graph 优化的区别是什么?
BA:是把所有的三维点和位姿放在一起作为自变量进行非线性优化;
pose graph:是优化所有的位姿,目的是将位姿之间的不同方式计算得到约束残差最小;
本质上BA包含了pose graph优化,两种优化方法都会转换为求解正规方程,两者形式完全一样;
pose graph与BA的区别,仅仅体现在BA中使用三维点间接地表达pose间的约束关系。
46、ceres库中huber什么作用?是怎么设置的 ?
Huber是设置LossFunction时设置的,是核函数的一种,主要就是减少异常值对优化结果的影响,一般定义语句就是loss_function = new ceres::HuberLoss(value)
47、单目地图初始化过程对相机运动有哪些要求?如何能够稳定快速的初始化?
对相机的运动要求:单目初始化应该避免纯旋转,要有一定程度上的平移。但是还需要注意,平移不能太小,如果太小会导致较大的深度不确定性;如果平移太大的话,图像内容变化大的话由可能导致特征匹配成功数量降低。
激光SLAM
1、LOAM和LeGO-LOAM的区别
- 提取地面点对z,pitch,roll做约束,优化后的结果作初始值再用其他点对x,y,yaw做约束
- 基于BFS广度优先搜索做了一个聚类剔除外点的处理,聚类主要就是以角度为阈值划分是不是同一个物体
2、请对比几种激光配准算法(ICP,NDT,PL-ICP,CSM-cartographer)的优缺点
一、原理:
- ICP:基于最小二乘法的最优配准方法,根据target点云构建kdtree,遍历source点中每一点求取距target点云中最近距离,以距离为残差,以旋转和平移为优化变量,求解最小二乘问题。
- PL-ICP:ICP改进版,利用kdtree搜寻target中最近的两个点,以source点到直线(这两个点构成)的距离为残差,求解方法同上。
- NDT:把target点云分割成多个cell,计算每个cell中点云高斯分布概率密度函数,再计算source点云落在cell中相应的概率分布函数,以-log(此函数)为残差,求解最小二乘问题。
- CSM-cartographer:采用分支定界方法,代替暴力搜索(旋转,平移一步一步搜索),通过栅格地图分块分支,通过改变栅格分辨率的方法定界(即高分辨率得分一定小于低分辨率得分),得分指点云落入栅格分的总和,不详细说明了。
二、优缺点 - ICP:需要构建kdtree,相对NDT耗时更长(NDT的cell尺寸不是特小情况下),精度相对NDT高一些,对初值敏感,否则容易陷入局部最优解。以点到点距离为残差略不合理,因为激光雷达扫描的点不能一一对应,引入误差。
- PL-ICP:相对ICP,在一定程度上减轻了第二个问题的影响。
- NDT:一般情况下,相比ICP计算快,对初值不像ICP那么敏感,但太差了也不太行,精配准不及ICP。
- CSM-cartographer:分支定界方法,肯定是比暴力搜索强,个人认为是牺牲内存换取速度的方法,2D还不错,3D使用好像较少。
3、LEGO-LOAM中划分出地面点与非地面点的目的是什么?首先一点共识就是lego-loam适用于平坦路面,因此其划分路面点和非路面点是算法对平坦路面的特殊处理:
- 在平坦路面,划分所得路面点具有更好的面特征信息,可以更好地提供点-面残差约束;
- 在计算Lidar Odometry时分为了两步,第一步先用点-面残差计算初始[t_z,t_roll,t_pitch],然后第二步基于第一步基础上计算[t_x, t_y, t_yaw],这样可以提升计算效率。而可以这样计算的原因是因为地面信息在相邻帧间变化不大,因此可以优先用于计算竖直维度相关量,然后再在其基础上计算水平维度变化量。
- 避免非地面点云中的平面与地平面点云的误匹配
4、LeGO-LOAM怎么判断找到的最近5个点是不是线特征?
在构建点-线残差之前,Lego-LOAM已经进行了特征提取操作,将属于边缘点的点云加至Fme,将属于平面点的点云加至Fmp,因此找最近点构建点线残差时,从直线特征集中选择的5个点。
- 计算这5个点的协方差矩阵
- 进行SVD分解求其特征值和特征向量
- 根据特征值是否存在一个明显大于另外两个的来判断是否为直线
5、Cartographer算法后端有哪些问题?请提供优化思路
6、激光SLAM中回环检测的主流方法有哪些?请选一个熟悉的方法详细分析?
7、三维点云地图怎么转换成二位概率栅格地图?
8、lego-loam 中关键帧提取的依据是?
9、请描述点云运动畸变的校正过程?
10、LIO-SAM相对LEGO-LOAM的改进有哪些?
11、请简述cartographer中分支定界的原理?
12、相机和激光雷达联合标定的精度如何评估?
c++
1、虚函数有什么作用,析构函数为什么定义为虚函数?
虚函数用来实现C++的多态,在父类对象成员函数前面加上virtual,然后在子类中重写这个函数,具体思想是在程序运行时用父类指针来执行子类对象中不同的函数。如果不使用虚函数,那么函数地址在编译阶段就已经确定,执行时还是调用的父类函数。使用虚函数后,函数地址是在运行阶段才确定的,这样执行时就可以调用子类函数。
析构函数不一定都要定义为虚函数,只有子类对象在堆区开辟了数据才需要。这是因为父类指针在释放时无法调用到子类的析构函数,造成内存泄漏。虚析构函数就是通过父类指针释放子类对象。
2、include 后面使用双引号 " " 和尖括号 <> 的区别
尖括号< > 括起来表明这个文件是一个工程或标准头文件。查找过程会检查预定义的目录,我们可以通过设置搜索路径环境变量或命令行选项来修改这些目录。
如果文件名用一对" "引号括起来则表明该文件是用户提供的头文件,查找该文件时将从当前文件目录(或文件名指定的其他目录)中寻找文件,然后再到标准位置寻找文件。
3、常量指针和指针常量有什么区别?
const的优点:
- 便于类型检查,如函数的函数 func(const int a) 中a的值不允许变,这样便于保护实参。
- 功能类似于宏定义,方便参数的修改和调整。如 const int max = 100;
- 节省空间,如果再定义a = max,b=max…等就不用在为max分配空间了,而用宏定义的话就一直进行宏替换并为变量分配空间
- 为函数重载提供参考,即可以添加const进行重载。
int a = 1;
int b = 2;
int c = 3;
int const *p1 = &b; // const在前,p1为常量指针
int *const p2 = &c; // * 在前,p2为指针常量
//注意:允许将非const对象的地址赋给指向const对象的指针,所以第4行代码是正确的
常量指针p1:即指向const对象的指针,指向的地址可以改变,但其指向的内容(即对象的值)不可以改变。
//p1可以改变,但不能通过p1修改其指向的对象(即 b)的值;不过,通过其他方式修改b的值是允许的
p1 = &a; //正确,p1是常量指针,可以指向新的地址(即&a),即p1本身可以改变
*p1 = a; //错误,*p1是指针p1指向对象的值,不可以改变,因此不能对*p重新赋值
指针常量p2:指针本身是常量,即指向的地址本身不可以改变,但内容(即对象的值)可以改变。
p2 = &a; //错误,p2是指针常量,本身不可以改变,因此将a的地址赋给p2是错误的
*p2 = a; //正确,p2指向的对象允许改变
补充:要分辨是常量指针还是指针常量,可以从右向左来看其定义,具体如下:
①对于 int const *p1=&b,先将*和p1结合,即p1首先是一个指针,然后再左结合const,即常量指针,它指向了const对象,因此我们不能改变 *p1的值。
②对于 int *const p2=&c,现将const和p2结合,即p2首先是一个常量,然后再左结合*,即指针常量,它本身是一个常量,因此我们不能改变p2本身。另外因为p2本身是const,而const必须初始化,因此p2在定义时必须初始化,即不能直接 int *const p2;
4、C++中智能指针相比普通指针的优势和劣势?
普通指针如果delete不当会造成内存泄露或者生成野指针,而智能指针实际上是对指针加了一层封装机制,使得它可以方便的管理对象的生命周期。在智能指针中,一个对象什么时候被析构是受智能指针本身决定的,用户不需要进行管理。
优点:智能指针不需要手动释放空间,能够避免内存泄露
缺点:1、有传染性,用了一处之后导致很多传参的位置也得修改;2、如果类的内部组合或者聚合了一些别的类,这些类的析构又不想在这个类处理的时候,智能指针析构的不确定性会导致这些类无法按要求进行管理
5、在函数定义的时候,经常看到使用引用作为函数的参数或者返回值,这样做的好处在哪里?
引用就是某一变量(目标)的别名,对引用的操作与对变量直接操作完全一样。
引用传参的好处:
- 在函数内部会对此参数进行修改
- 提高函数调用和运行效率
引用作为函数返回值:
- 以引用返回函数值,定义函数时需要在函数名前加 &
- 用引用返回一个函数值的最大好处是:在内存中不产生被返回值的副本
<div style="background-color:white">
#include <iostream>
using namespace std;
float temp; //定义全局变量temp
float fn1(float r); //声明函数fn1
float &fn2(float r); //声明函数fn2
float fn1(float r) //定义函数fn1,它以返回值的方法返回函数值
{
temp=(float)(r*r*3.14);
return temp;
}
float &fn2(float r) //定义函数fn2,它以引用方式返回函数值
{
temp=(float)(r*r*3.14);
return temp;
}
int main()
{
float a=fn1(10.0); //第1种情况,系统生成要返回值的副本(即临时变量)
//float &b=fn1(10.0); //第2种情况,编译不通过,左值引用不能绑定到临时值
float &d=fn2(10.0); //第3种情况,系统不生成返回值的副本,可以从被调函数中返回一个全局变量的引用
float c=fn2(10.0); //第4种情况,变量c前面不用加&号,这种也是可以的
cout<<a<<endl<<c<<endl<<d<<endl;
return 0;
}
</div>
引用作为返回值,必须遵守以下规则:
- 不能返回局部变量的引用。主要原因是局部变量会在函数返回后被销毁,因此被返回的引用就成为了"无所指"的引用,程序会进入未知状态。
- 不能返回函数内部new分配的内存的引用。虽然不存在局部变量的被动销毁问题,可对于这种情况(返回函数内部new分配内存的引用),又面临其它尴尬局面。例如,被函数返回的引用只是作为一个临时变量出现,而没有被赋予一个实际的变量,那么这个引用所指向的空间(由new分配)就无法释放,造成memory leak。
- 引用与一些操作符的重载。流操作符<<和>>,这两个操作符常常希望被连续使用,例如:cout << “hello” << endl; 因此这两个操作符的返回值应该是一个仍然支持这两个操作符的流引用。
6、无序map和有序map的查找复杂度?
std::map对应的数据结构是红黑树。红黑树是一种近似于平衡的二叉查找树,里面的数据是有序的。在红黑树上做查找、插入、删除操作的时间复杂度为O(logn)。
而std::unordered_map对应哈希表,哈希表的特点就是查找效率高,时间复杂度为常数级别O(1), 而额外空间复杂度则要高出许多。
7、C++中释放内存的方式有 delete 和 delete[] 两种,它们的区别是什么呢?
对于像 int/char/long 等等这些基本数据类型,使用new分配的不管是数组还是非数组形式的内存空间,delete和delete[]都可以正常释放,不会存在内存泄漏。原因是:分配这些基本数据类型时,其内存大小已经确定,系统可以记忆并且进行管理,在析构时不会调用析构函数,它通过指针可以直接获取实际分配的内存空间。
int *a = new int[10];
delete a; //正确
delete [] a; //正确
对于自定义的Class类,delete和delete[]会有一定的差异。先看一段代码示例:
class T {
public:
T() { cout << "constructor" << endl; }
~T() { cout << "destructor" << endl; }
};
int main() {
T* p1 = new T[3]; //数组中包含了3个类对象
cout << hex << p1 << endl; //输出P1的地址
delete[] p1; //这里会输出3个destructor,调用三次析构函数
T* p2 = new T[3];
cout << p2 << endl; //输出P2的地址
delete p2; //这里只输出1个destructor,调用1次析构函数
return 0;
}
delete[]会调用析构函数对数组的所有对象进行析构;而delete只调用了一次析构函数,即数组中第一个对象的析构函数,而数组中剩下的对象的析构函数没有被调用,因此造成了内存泄漏。
8、C++11新特性
- 初始化列表,即用花括号来进行初始化。C++11中可以直接在变量名后面跟上初始化列表来进行对象的初始化,使用起来更加方便,例如:
vector<int> vec; //C++98/03给vector对象的初始化方式
vec.push_back(1);
vec.push_back(2);
vector<int> vec{1,2}; //C++11给vector对象的初始化方式
vector<int> vec = {1,2};
- auto关键字
- 范围for循环
- nullptr关键字
- lambda表达式
- 智能指针
- 右值引用
9、什么情况会内存泄漏?
- 堆内存泄漏 (Heap leak):堆内存指的是程序运行中根据需要分配通过malloc,realloc,new等从堆中分配的一块内存,在完成相关操作后必须通过调用对应的 free或者delete 删掉。如果程序的设计的错误导致这部分内存没有被释放,那么此后这块内存将不会被使用,就会产生Heap Leak。
- 系统资源泄露(Resource Leak):主要是指系统分配给程序的资源没有使用相应的函数释放掉(比如 Bitmap,handle,socket等),导致系统资源的浪费,严重可导致系统效能降低,系统运行不稳定。
- 没有将基类的析构函数定义为虚函数:当基类指针指向派生类对象时,如果基类的析构函数不是virtual,那么子类的析构函数将不会被调用,子类的资源没有正确是释放,因此造成内存泄露。
- 在释放对象数组时没有使用delete[]而是使用了delete:当一个数组中的多个元素均为对象时,在使用delete释放该数组时必须加上方括号([]),否则就只会调用一次析构函数释放数组的第一个对象,而剩下的数组元素没有被析构掉,造成了内存泄漏。
- 缺少拷贝构造函数:如果类中没有手动编写拷贝构造函数,用该类对象进行拷贝赋值时,会使用默认的拷贝构造函数,即浅拷贝,浅拷贝的缺陷之一被赋值对象原本的内存没被释放,因此造成了内存泄漏。
10、类的拷贝构造函数和拷贝赋值运算符有何不同?使用需要注意什么?
类的拷贝构造函数是在类对象被创建时调用的,是在新对象被创建时,用一个已有对象来初始化新对象。拷贝构造函数的形式为:
class_name (const class_name & object);
赋值构造函数只能是在已存在的对象调用,赋值构造函数是在一个已有对象被赋值给另一个对象时被调用。赋值构造函数的形式为:
class_name & operator= (const class_name & object);
判断两者的方法是看是否有新对象实例生成。
注意点:如果类中有指针成员变量,那么需要重载拷贝构造函数和赋值构造函数来进行深拷贝,避免出现悬空指针或野指针的问题
11、如何找四边形的边界,给出C++编程实现思路及伪代码?
Mat image = imread("image.jpg");
Mat gray;
cvtColor(image, gray, COLOR_BGR2GRAY); // Step 2: 将图像转换为灰度图
GaussianBlur(gray, gray, Size(3,3), 0);// Step 3: 使用高斯滤波对图像进行平滑
// Step 4: 计算图像的梯度幅值和方向
Mat grad_x, grad_y;
Sobel(gray, grad_x, CV_32F, 1, 0);
Sobel(gray, grad_y, CV_32F, 0, 1);
Mat grad;
magnitude(grad_x, grad_y, grad);
// Step 5: 使用阈值进行边缘检测
Mat edges;
threshold(grad, edges, 50, 255, THRESH_BINARY);
// Step 6: 使用霍夫变换检测直线
vector<Vec4i> lines;
HoughLinesP(edges, lines, 1, CV_PI/180, 50, 50, 10);
// Step 7: 找到四边形的边界
for (Vec4i line : lines) {
// 使用线段坐标来找到四边形的边界
}
12、C++中的智能指针是如何工作的?
C++的标准模板库(STL)中提供了4种智能指针:auto_ptr、unique_ptr、share_ptr、weak_ptr,其中后面3种是C++11的新特性,而 auto_ptr 是C++98中提出的,已经被C++11弃用了,取而代之的是更加安全的 unique_ptr
1. auto_ptr
智能指针 auto_ptr 由C++98引入,定义在头文件 中,在C++11中已经被弃用了,因为它不够安全,而且可以被 unique_ptr 代替。那它为什么会被 unique_ptr 代替呢?先看下面这段代码:
#include <iostream>
#include <string>
#include <memory>
using namespace std;
int main() {
auto_ptr<string> p1(new string("hello world."));
auto_ptr<string> p2;
p2 = p1; //p2接管p1的所有权
cout << *p2<< endl; //正确,输出: hello world.
//cout << *p1 << endl; //程序运行到这里会报错
//system("pause");
return 0;
}
2. unique_ptr
unique_ptr 同 auto_ptr 一样也是采用所有权模式,即同一时间只能有一个智能指针可以指向这个对象 ,但之所以说使用 unique_ptr 智能指针更加安全,是因为它相比于 auto_ptr 而言禁止了拷贝操作, unique_ptr 采用了移动赋值 std::move()函数来进行控制权的转移。
3. share_ptr
共享指针 share_ptr是一种可以共享所有权的智能指针,定义在头文件memory中。
它允许多个智能指针指向同一个对象,多个指针引用同一个变量时会增加其引用次数,指针消亡时会自动减少引用次数,直到引用次数到零时将内存空间回收。并使用引用计数的方式来管理指向对象的指针(成员函数use_count()可以获得引用计数),该对象和其相关资源会在“最后一个引用被销毁”时候释放。
share_ptr是为了解决 auto_ptr 在对象所有权上的局限性(auto_ptr 是独占的),在使用引用计数的机制上提供了可以共享所有权的智能指针。
4. weak_ptr
weak_ptr 弱指针是一种不控制对象生命周期的智能指针,它指向一个 share_ptr 管理的对象,进行该对象的内存管理的是那个强引用的 share_ptr ,也就是说 weak_ptr 不会修改引用计数,只是提供了一种访问其管理对象的手段,这也是它称为弱指针的原因所在。
此外,weak_ptr 和 share_ptr 之间可以相互转化,share_ptr 可以直接赋值给weak_ptr ,而weak_ptr 可以通过调用 lock 成员函数来获得share_ptr 。
share_ptr无法解决循环引用的问题,即A引用了B,B同时也引用了A,这种情况会导致引用计数机制失效,解决方法是将其中一个指针转换为weak_ptr,就是仅保存指针但是不负责计数,在需要使用的时候lock住,使用完成后释放。
13、请说说new/delete与malloc/free的区别?
-
new和delete是C++的关键字,是一种操作符,可以被重载 -
malloc和free是C语言的库函数,并且不能重载 -
malloc使用时需要自己显示地计算内存大小,而new使用时由编译器自动计算
int *q = (int *)malloc(sizeof(int) * 2); //显示计算内存大小
int *p = new int[2]; //编译器会自动计算
-
malloc分配成功后返回的是void*指针,需要强制类型转换成需要的类型;而new直接就返回了对应类型的指针 -
new和delete使用时会分别调用构造函数和析构函数,而malloc和free只能申请和释放内存空间,不会调用构造函数和析构函数
注意:delete和free被调用后,内存不会立即回收,指针也不会指向空,delete或free仅仅是告诉操作系统,这一块内存被释放了,可以用作其他用途。但是由于没有重新对这块内存进行写操作,所以内存中的变量数值并没有发生变化,这时候就会出现野指针的情况。因此,释放完内存后,应该把指针指向NULL。
14、什么是运行时多态?
多态的实现主要分为静态多态和动态多态,静态多态主要是重载overload,在编译时就已经确定;而动态多态是通过虚函数机制来实现,在运行时动态绑定。
- 动态多态是指基类的指针指向其派生类的对象,通过基类的指针来调用派生类的成员函数
- C++类的多态性是通过虚函数来实现的。如果基类通过引用或指针调用的是虚函数时,我们并不知道执行该函数的对象是什么类型的,只有在运行时才能确定调用的是基类的虚函数还是派生类中的虚函数,这就是运行时多态。
int main() {
Base a;
Derived b; //派生类的对象
Base *p1 = &a; //基类的指针,指向基类的对象
Base *p2 = &b; //基类的指针,指向派生类的对象
//f1()是虚函数,只有运行时才知道真正调用的是基类的f1(),还是派生类的f1()
p1->f1(); //p1指向的是基类的对象,所以此时调用的是基类的f1()
p2->f1(); //基类的指针调用派生类重写的虚函数 Derived::f1(), 打印结果为 Derived::f1
return 0;
}
如果基类通过引用或者指针调用的是非虚函数,无论实际的对象是什么类型,都执行基类所定义的函数。即:
int main() {
Base a;
Derived b;
Base *p = &a; //基类的指针,指向基类的对象
Base *p0 = &b; //基类的指针,指向派生类的对象
//f()是非虚函数,所以无论指向是基类的对象a还是派生类的对象b,执行的都是基类的函数f()
p->f();
p0->f();
return 0;
}
**多态性其实就是想让基类的指针具有多种形态,能够在尽量少写代码的情况下让基类可以实现更多的功能。**比如说,派生类重写了基类的虚函数f1()之后,基类的指针就不仅可以调用自身的虚函数f1(),还可以调用其派生类的虚函数f1()。
15、谈谈你对C++多线程的理解,并列举在SLAM系统中的具体应用
多线程是实现并发的一种手段,一个进程可以有多个线程,每个线程负责不同的事情,多个线程可以提高代码执行效率。 不同进程数据很难共享,同一进程下的不同线程数据可以共享,不同线程可以使用互斥锁,共享锁来处理多个线程的共享内存 。
ORB中有主线程(跟踪),局部建图线程,闭环线程
16、虚函数相关
虚函数知识点:
- 虚函数是指在基类内部声明的成员函数前添加关键字
virtual指明的函数 - 虚函数存在的意义是为了实现多态,让派生类能够重写
override其基类的成员函数 - 派生类重写基类的虚函数时,可以添加
virtual关键字,但不是必须这么做 - 虚函数是动态绑定的,在运行时才确定,而非虚函数的调用在编译时确定
- 虚函数必须是非静态成员函数,因为静态成员函数需要在编译时确定
- 构造函数不能是虚函数,因为虚函数是动态绑定的,而构造函数创建时需要确定对象类型
- 析构函数一般是虚函数
- 虚函数一旦声明,就一直是虚函数,派生类也无法改变这一事实
虚函数的工作机制:
主要思路:虚函数表 + 虚表指针
具体实现:
- 编译器在含有虚函数的类中创建一个虚函数表,称为vtable,这个vtable用来存放虚函数的地址。另外还隐式地设置了一个虚表指针,称为vptr,这个vptr指向了该类对象的虚函数表。
- 派生类在继承基类的同时,也会继承基类的虚函数表。
- 当派生类重写(override)了基类的虚函数时,则会将重写后的虚函数的地址 替换掉 由基类继承而来的虚函数表中对应虚函数的地址。
- 若派生类没有重写,则由基类继承而来的虚函数的地址将直接保存在派生类的虚函数表中。
注意:每个类都只有一个虚函数表,该类的所有对象共享这个虚函数表,而不是每个实例化对象都分别有一个虚函数表。
C++类的多态性是通过虚函数来实现的。如果基类通过引用或指针调用的是虚函数时,我们并不知道执行该函数的对象是什么类型的,只有在运行时才能确定调用的是基类的虚函数还是派生类中的虚函数,这就是运行时多态。
17、纯虚函数是什么?有什么用?
class Cat {
public:
virtual void eat()=0;
};
- 纯虚函数只在基类中声明,但没有定义,因此没有函数体。
- 纯虚函数的声明只需在虚函数形参列表后面添加 =0 即可。
- 含有纯虚函数的类都是抽象类。
- 只含有纯虚函数的类称为接口类。
含有纯虚函数的类称为抽象类。抽象类有以下几个特点:
- 抽象类不能实例化对象。
- 抽象类的派生类也可以是抽象类(会继承),也可以通过实现全部的纯虚函数使其变成非抽象类,从而可以实例化对象。
- 抽象类的指针可以指向其派生类对象,并调用派生类对象的成员函数。
接口类:
- 只含有纯虚函数的类称为接口类。
- 接口类没有任何数据成员,也没有构造函数和析构函数。
- 接口类的指针也可以指向其派生类对象
18、构造函数和析构函数可以是虚函数吗?
构造函数不能是虚函数,原因是构造函数在创建对象时必须确定对象类型。具体的理解就是:
- 首先,在创建一个对象时必须确定其类型。因为类型规定了对象可以进行哪些操作,所以创建对象时必须确定类型,以防止一些不恰当的操作,否则编译器就会报错。
- 其次,因为虚函数是在运行时才确定对象的类型的,如果构造函数声明为虚函数,那么在构造对象时,由于这个对象还没创建成功,编译器就不知道对象的实际类型(比如基类还是派生类),就会报错。
- 另外,从内存的角度来看,虚函数的调用需要虚表指针,而该指针存放在内存空间中,如果构造函数声明为虚函数,由于对象还没创建,就没有内存空间,因此就没有虚表指针来调用虚函数(构造函数)了。
析构函数可以是虚函数吗?
可以,如果基类存在虚函数以实现多态,而基类的析构函数没有声明为虚函数,那么在析构一个指向派生类的基类指针时,就只会调用基类的析构函数,不会调用派生类的析构函数,因此会造成内存泄漏的问题。
19、sizeof 与 strlen 的区别?
区别:
strlen是一个函数,要在运行时才能计算。只能以char*(字符串)作为参数(当数组名作为参数传入时,实际上数组就退化成指针了),用来计算指定字符串str的长度,但不包括结束字符'\0'。所以其参数必须是以'\0'作为结束符才可以正确统计其字符长度,否则是个随机数,具体看下面的代码。sizeof是一个运算符,它的参数可以是数组、指针、字符串、对象等等,计算的是参数所对应内存空间的实际字节数。由于在编译时计算,因此sizeof不能用来返回动态分配的内存空间的大小
#include <bits/stdc++.h>
using namespace std;
int main() {
char* s1 = "0123456789";
cout<<sizeof(s1)<<endl; // 输出 8,因为这时的参数 s 是一个指向字符串常量的字符指针,因此计算的是指针的大小,注意这里不同编译器得到的值可能不同,也有可能是4
cout<<sizeof(*s1)<<endl; // 输出 1,*s 是第一个字符
cout<<strlen(s1)<<endl; // 输出 10,有10个字符,strlen是个函数,内部实现是用一个循环计算到\0之前为止
//strlen(*s1); // 报错,因为strlen函数的参数类型只能是 char* 即字符串
char s2[] = "0123456789"; // 数组
cout<<sizeof(s2)<<endl; // 结果为11,数组名虽然本质上是一个指针,但是作为sizeof的参数时,计算的是整个数组的大小,这点要特别注意。且在求动态数组的大小时,sizeof统计到第一个结束字符'\0'处结束
cout<<strlen(s2)<<endl; // 结果为10
cout<<sizeof(*s2)<<endl; // 结果为1,*s是第一个字符
char s3[100] = "0123456789";
cout<<sizeof(s3)<<endl; // 结果为100,因为内存给数组 s3分配了字节数为100的空间大小
cout<<strlen(s3)<<endl; // 结果为10
int s4[100] = {0,1,2,3,4,5,6,7,8,9};
cout<<sizeof(s4)<<endl; // 结果为400,因为int数组中每个元素都是int型,int型占用4字节
//strlen(s4); // 报错,strlen不能以int* 作为函数参数
char p[] = {'a', 'b','c','d','e', 'f', 'g','h'};
char q[] = {'a', 'b','c','d','\0', 'e', 'f', 'g'};
cout<<sizeof(p)<<endl; // 结果为8
cout<<strlen(p)<<endl; // 结果是一个随机数,因为字符串数组中没有结束字符 '\0', 因此该函数会一直统计下去,直到碰到内存中的结束字符
cout<<sizeof(q)<<endl; // 结果还是8
cout<<strlen(q)<<endl; // 结果为4, 结束字符 '\0'前有4个字符
return 0;
}
另外sizeof在统计结构体的大小时还有一个内存对齐的问题,具体如下:
struct Stu {
int i;
int j;
char k;
};
Stu stu;
cout<<sizeof(stu)<<endl; // 输出 12
这个例子是结构体的内存对齐所导致的,计算结构变量的大小就必须讨论数据对齐问题。为了CPU存取的速度最快(这同CPU取数操作有关),C语言在处理数据时经常把结构变量中的成员的大小按照4或8的倍数计算,这就叫数据对齐(data alignment)。这样做可能会浪费一些内存,但理论上速度快了。当然这样的设置会在读写一些别的应用程序生成的数据文件或交换数据时带来不便。
c/c++中获取字符串长度。有以下函数:str.size()、sizeof() 、strlen()、str.length();
strlen(str)和str.length()和str.size()都可以求字符串长度。- 其中
str.length()和str.size()是用于求string类对象的成员函数 strlen(str)是用于求字符数组的长度,其参数是char*。
举例:
char* ss = "0123456789";
//sizeof(ss)为8,ss是指向字符串常量的字符指针,sizeof 获得的是指针所占的空间,则为8
//sizeof(*ss)为1,*ss是第一个char字符,则为1
char ss[] = "0123456789";
//sizeof(ss)为11,ss是数组,计算到'\0'位置,因此是(10+1)
//sizeof(*ss)为1,*ss是第一个字符
char ss[100] = "0123456789";
//sizeof(ss)为100,ss表示在内存中预分配的大小,100*1
//strlen(ss)为10,它的内部实现用一个循环计算字符串的长度,直到'\0'为止。
int ss[100] = {0,1,2,3,4,5,6,7,8,9};
//sizeof(ss)为400,ss表示在内存中预分配的大小,100*4
//strlen(ss)错误,strlen参数只能是char*,且必须是以'\0'结尾
char[] a={'a','b','c'};
//sizeof(a)的值应该为3。
char[] b={"abc"};
//sizeof(b)的值应该是4。
string str={'a','b','c','\0','X'};
//sizeof(str)为5,strlen(str)为3。
sizeof(),strlen()两者区别:
sizeof操作符的结果类型是size_t,它在头文件中typedef为unsigned int类型。该类型保证能容纳实现所建立的最大对象的字节大小。sizeof是运算符,strlen是函数。sizeof可以用类型做参数,strlen只能用char*做参数,且必须是以\0结尾的。sizeof还可以用函数做参数,比如:printf("%d\n", sizeof(f()));- 数组做
sizeof的参数不退化,传递给strlen就退化为指针了。 - 大部分编译程序 在编译的时候就把
sizeof计算过了,是类型或是变量的长度。这就是sizeof(x)可以用来定义数组维数的原因 strlen的结果要在运行的时候才能计算出来,用来计算字符串的长度,不是类型占内存的大小。sizeof后如果是类型必须加括弧,如果是变量名可以不加括弧。这是因为sizeof是个操作符不是个函数。
c++中的size()和length()没有区别
为了兼容,这两个函数一样。 length()是因为沿用C语言的习惯而保留下来的,string类最初只有length(),引入STL之后,为了兼容又加入了size(),它是作为STL容器的属性存在的,便于符合STL的接口规则,以便用于STL的算法。 string类的size()/length()方法返回的是字节数,不管是否有汉字
20、strcpy 、strncpy 和 memcpy 的区别?
strcpy:
函数原型:char *strcpy(char *dest, const char *src)
char* strcpy(char* dest,const char* src)//src到dest的复制
{
if(dest == nullptr || src == nullptr)
return nullptr;
char* strdest = dest;
while((*strdest++ = *src++) != '\0') {};
return strdest;
}
函数功能:把 src 地址开始且包括结束符的字符串复制到以 dest 开始的地址空间,返回指向 dest 的指针。需要注意的是,src 和 dest 所指内存区域不可以重叠且 dest 必须需有足够的空间来容纳 src 的字符串,strcpy 只用于字符串复制。
安全性:strcpy 是不安全的,strcpy在遇到结束符时才会正常的结束运行,会因为 src 长于 dest 而造成 dest 栈空间溢出以致于崩溃异常,它的结果未定,可能会改变程序中其他部分的内存的数据,导致程序数据错误,不建议使用。
代码举例:
char src1[10] = "hello";
strcpy(src1, src1+1);
cout<<"src1:"<<src1<<endl; // 输出 ello。
char src2[10] = "hello";
strcpy(src2+1, src2);
cout<<"src2:"<<src2<<endl; // 输出 hhello,按照内存重叠逻辑理解,应该输出 hhhhh……,后面是随机两才对,因为'\0'被覆盖,而strcpy要遇到'\0'才会停止复制。
// 可能对于内存重叠的问题,每种编译器的定义不一样
char src3[10] = "hello";
char dest3[3];
strcpy(dest3, src3);
cout<<"dest3:"<<dest3<<endl; // 输出 hello,非常奇怪的是居然没报错,dest3的空间不是比src3的小吗?
// 注意下面这个用例体现了 strcpy 与 strncpy 的区别
char *src4 = "best";
char dest4[30] = "you are the best one.";
strcpy(dest4+8, src4);
cout<<"dest4:"<<dest4<<endl; // 输出 you are best。字符串最后一个字节存放的是一个空字符——“\0”,用来表示字符串的结束。
// 把src4复制到dest4之后, src4中的空字符会把把复制后的字符串隔断,所以会显示到best就会结束。
strncpy:
函数原型:char* strncpy(char* dest,const char* src,size_t n)
char *strncpy(char *dest, const char *src, int len)
{
assert(dest!=NULL && src!=NULL);
char *temp;
temp = dest;
for(int i =0;*src!='\0' && i<len; i++,temp++,src++)
*temp = *src;
*temp = '\0';
return dest;
}
函数功能:将字符串src中最多n个字符复制到字符数组 dest 中(它并不像strcpy一样只有遇到 NULL 才停止复制,而是多了一个条件停止,就是说如果复制到第n个字符还未遇到 NULL,也一样停止),返回指向 dest 的指针。只适用于字符串拷贝。如果src指向的数组是一个比n短的字符串,则在 dest 定义的数组后面补'\0'字符,直到写入了n个字符。
注意:如果 n>dest 串长度,dest 栈空间溢出产生崩溃异常。一般情况下,使用 strncpy 时,建议将n置为dest串长度,复制完毕后,为保险起见,将dest串最后一字符置NULL。
安全性:比较安全,当dest的长度小于n时,会抛出异常。
如果想把一个字符串的一部分复制到另一个字符串的某个位置,显然strcpy()函数是满足不了这个功能的,因为strcpy()遇到结束字符才停止。但是 strncpy可以:
char *src5 = "best";
char dest5[30] = "you are the best one.";
strncpy(dest5+8, src5, strlen(src5));
cout<<"dest5:"<<dest5<<endl; // 输出 you are bestbest one,注意这里与上面代码最后一个示例的区别
memcpy:
函数原型:void* memcpy(void* dest, const void* src, size_t n)
void *memcpy(void *memTo, const void *memFrom, size_t size)
{
if((memTo == NULL) || (memFrom == NULL)) //memTo和memFrom必须有效
return NULL;
char *tempFrom = (char *)memFrom; //保存memFrom首地址
char *tempTo = (char *)memTo; //保存memTo首地址
while(size-- > 0) //循环size次,复制memFrom的值到memTo中
*tempTo++ = *tempFrom++ ;
return memTo;
}
函数功能:与strncpy类似,不过这里提供了一般内存的复制,即memcpy对于需要复制的内容没有任何限制,可以复制任意内容,因此,用途广泛。
注意:memcpy没有考虑内存重叠的情况,所以如果两者内存重叠,会出现错误。
char *src6 = "best";
memcpy(src6+1, src6, 3); // 报错,内存重叠
三者的区别:
- 复制的内容不同。
strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。 - 复制的方法不同。
strcpy不需要指定长度,它遇到被复制字符的串结束符"\0"才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。 - 用途不同。通常在复制字符串时用
strcpy,而需要复制其他类型数据时则一般用memcpy
使用情况:
dest指向的空间要足够拷贝;使用strcpy时,dest指向的空间要大于等于src指向的空间;使用strncpy或memcpy时,dest指向的空间要大于或等于n。- 使用
strncpy或memcpy时,n应该大于strlen(src),或者说最好n >= strlen(s1)+1;这个1 就是最后的“\0”。 - 使用
strncpy时,确保dest的最后一个字符是“\0”。
21、哈希冲突是什么?如何解决?
哈希冲突产生的原因:
因为通过哈希函数产生的值是有限的,而数据可能比较多,导致通过哈希函数映射后仍有很多不同的数据对应了相同的哈希值,这时候就产生了哈希冲突。
解决哈希冲突的四种方法:
- 开放地址法(也称再散列法)
基本思想是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,直到找出一个不冲突的哈希地址,将相应元素存入其中。
这种方法有一个通用的再散列函数形式:
H i = ( H ( k e y ) + d i ) % m , i = 1 , 2 , . . . , n . H_{i} = (H(key)+d_{i})\%m,\ \ i=1,2,...,n.\ Hi=(H(key)+di)%m, i=1,2,...,n.H(key)为哈希函数, m m m为表长, d i d_{i} di为增量序列。增量序列 d i d_{i} di的取值方式不同,相应的再散列方式也不同,主要有以下三种:
(1)线性探测:
d i = 1 , 2 , . . . , m − 1 d_{i} = 1,2,...,m-1 di=1,2,...,m−1
其特点是:在发生冲突时,顺序查看表中下一单元,直到找出一个空单元或查遍全表,将冲突的元素存放进去。
(2)再平方探测:
d i = 1 2 , − 1 2 , 2 2 , − 2 2 , . . . , k 2 , − k 2 , ( k < = m / 2 ) d_{i}=1^2,-1^2,2^2,-2^2,...,k^2,-k^2,(k<=m/2) di=12,−12,22,−22,...,k2,−k2,(k<=m/2)
其特点是:在发生冲突时,在表的左右进行跳跃试探,比较灵活。
(3)伪随机探测
具体实现时,建立一个伪随机数发生器生成伪随机序列(如2,5,9,…),在发生冲突时,先令 d i = 2 d_{i} = 2 di=2,算出 H i H_i Hi,如果还有冲突,则再令 d i = 5 d_{i} = 5 di=5,算出 ,若还有冲突,则继续下去…
2. 链式地址法
基本思想:将所有哈希地址为的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第 个单元中,因而查找、插入和删除都比较方便。
3. 建立公共溢出区
基本思想:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表中。
4. 再哈希表
基本思想:对于冲突的哈希值,再构造另一个哈希函数进行处理,直至没有哈希冲突,也就是同时使用多个哈希函数来处理。
22、右值引用是什么,它有什么用?
右值为临时值,不能存在于等号左边的值,不可以取地址;右值引用可以提高效率,提高的手段是:把拷贝对象变成移动对象来提高程序运行效率。右值引用就是为了应付移动构造函数和移动赋值运算符用的,而移动构造函数和移动赋值运算符是为了提高程序运行效率。
其他
1、Eigen中矩阵求逆,用了哪些数学上的技巧?
Eigen提供了直接求逆的方法inverse(),但是只针对小矩阵。求解大矩阵的话需要用一些数学分解算法,然后调用solve()函数。solve()函数其实是用来求解线性方程组ax=b,ab是系数矩阵,x是变量,b为单位阵时x为a的逆矩阵。具体的分解算法包括部分主元LU分解(对应Eigen中的PartialPivLU)、全主元LU分解(FullPivLU)、Householder QR分解(HouseholderQR)、列主元Householder QR分解(ColPivHouseholderQR)、全主元Householder QR分解(FullPivHouseholderQR)、完全正交分解COD(CompleteOrthogonalDecomposition)、标准Cholesky分解(LLT)、鲁棒Cholesky分解(LDLT)、双对角分治SVD分解(BDCSVD)、雅各比svd分解(JacobiSVD)。
2、卡尔曼滤波状态预测的协方差矩阵怎么计算?
卡尔曼滤波状态预测的协方差矩阵,表示了状态量的间的相关性,对角线表示状态量的协方差
卡尔曼滤波预测过程中:该协方差矩阵和状态量的转移矩阵
Φ
k
,
k
+
1
\Phi_{k,k+1}
Φk,k+1,系统噪声的协方差矩阵有关。该过程状态量的协方差矩阵是个放大的过程;
卡尔曼滤波更新过程中:可以简写为
(
I
−
K
H
)
P
k
+
1
,
k
(I-KH)P_{k+1,k}
(I−KH)Pk+1,k,是一个协方差矩阵减小的过程。因为观测进来以后修正了状态量,从而协方差矩阵减小。控制住了原系统状态量误差的传播过程。
根据该协方差矩阵,一般可以判断滤波器是否收敛,过度收敛等情况,一般在滤波器中可以对该矩阵设置下限。
该协方差矩阵初始值设定中,对于可观性强的状态量,可以设置的较大;对于可观性不强的状态量,设置不宜过大,状态量初始值应该尽量准确;
可以强跟踪的卡尔曼滤波器,可以通过增加一个系数给该协方差矩阵,使得其变大,滤波器将基于观测更多的权重,从而实现短时强跟踪。
3、如何存储稀疏矩阵?
- 直接存每个非零元素的坐标和值,一种思路是维护一个大的容器,每个位置存一个三元组放x坐标、y坐标、值
- 另一种思路是维护三个数组,分别存放x坐标、y坐标、值。
- 或者做个字典,键是tuple放坐标,值放矩阵值。在实际操作时要以行或者列排序,这样能更快得查找。
- 使用压缩稀疏行格式Compressed Sparse Row(CSR),维护三个数组。首先传入数据,然后指定一个indices数组放每一行的非0元素的列位置,最后另外指定一个indptr数组放每一行的数据在indices中开始的位置。当然也可以使用压缩稀疏列格式Compressed Sparse Column(CSC),思路类似。
- 链表形式:十字链表。存储原则:每一个非零元素用结点表示,该结点除了(row,col,value)以外,还要有两个域。right:用于同一行中的下一个非零元素。down:用于同一列中的下一个非零元素。结构示意图:
row col value
down right
优点:灵活地插入、删除因运算而产生的新非零元素,实现矩阵的各种运算
4、多传感器如何做时间同步(Lidar,IMU,GPS,Odom)?
主要是进行硬同步和软同步。软同步是利用时间戳进行不同传感器的匹配,将各传感器数据统一到某个基准上,可以借助ROS::message_filter实现。硬同步可以借助PTP协议。
5、线性方程组 Ax=b 的求解方法以及优缺点(LU,QR,SVD等)?
LU 分解法是将矩阵 A 分解成两个矩阵 L 和 U,其中 L 是一个下三角矩阵,U 是一个上三角矩阵。然后通过消元的方法来求解线性方程组。
优点是求解速度快,算法稳定,常用于求解方程组的解。缺点是只能求解正定矩阵。
QR 分解法是将矩阵 A 分解成两个矩阵 Q 和 R,其中 Q 是一个正交矩阵,R 是一个上三角矩阵。然后通过消元的方法来求解线性方程组。
优点是求解速度快,算法稳定,常用于求解线性方程组的解。缺点是只能求解满秩矩阵。
SVD 分解法是将矩阵 A 分解成三个矩阵 U、Σ 和 V,其中 U 和 V 是正交矩阵,Σ 是一个对角矩阵。SVD 分解法通常用于求解线性方程组的最小二乘解,广泛应用于数据拟合和回归分析。
优点是算法稳定,能求解非满秩矩阵,能求解最小二乘解。缺点是求解速度较慢,不适用于求解大规模线性方程组。
6、Rp怎么对R求导(R是SO3,p是三维点)?
利用扰动模型,对李群左乘以微小扰动,然后对扰动求导
7、谈谈你对协方差矩阵的认识?
对于二阶矩协方差,描述了样本数据偏离均值的统计情况,越大则代表数据偏离程度越高,即数据越不稳定.
因此考虑slam的状态变量时,状态的协方差也就代表了当前状态估计正确程度。SLAM中协方差矩阵表达了对状态估计的不确定程度,也就是说在多传感器融合过程中我们认为哪个传感器估计的状态更准,就给哪个估计施加更大的权重。比如VINS-Mono中,引用沈邵劼老师的话就是“IMU和视觉信息融合也可以粗暴的叫做加权平均,那么加权就是每个测量值对应的协方差矩阵”。
另一方面来说,在进行图优化时,误差是要分摊给每一条边的。那么每条边应该分摊多少呢?显然均摊是不合适的,因为有的观测可能很准。这时候协方差矩阵就确定了应该给每条边分摊多少。
8、请简述特征值和特征向量的物理意义,并列举在3D视觉中是如何应用的?
矩阵乘法对应了一个变换,是把任意一个向量变成另一个方向或长度都大多不同的新向量。在这个变换的过程中,原向量主要发生旋转、伸缩的变化。如果矩阵对某一个向量或某些向量只发生伸缩变换,不对这些向量产生旋转的效果,那么这些向量就称为这个矩阵的特征向量,伸缩的比例就是特征值。
Ax=λx,矩阵*向量=特征值*向量
一个向量左乘一个矩阵,相当于将该向量伸长或缩短多少。
Rn=1·n,旋转矩阵*旋转向量=1*该旋转向量。
利用旋转矩阵求其对应旋转向量时则是用的该意义。旋转向量(转轴)因为与R表示的转动一致,因此转动后还是其本身(1*n)
9、如何求解线性方程Ax=b?SVD和QR分解哪个更快?
- 若A为方阵,则可用高斯消元求解,x有精确解。
- 若A非方阵,此时没有精确解,只有最小二乘解,通常采用矩阵分解求解。
| 矩阵形式 | 几何意义 |
|---|---|
| 普通矩阵 | 线性变换 |
| 正交矩阵 | 坐标的旋转 |
| 对角矩阵 | 缩放 |
| 三角矩阵 | 切边 |
一个普通矩阵的几何意义是对坐标进行某种线性变换,而正交矩阵的几何意义是坐标的旋转,对角矩阵的几何意义是坐标的缩放,三角矩阵的几何意义是对坐标的切边。因此对矩阵分解的几何意义就是将这种变换分解成缩放、切边和旋转的过程。
QR分解:
是一项广泛用于稳定求解病态最小二乘问题的方法,可采用QR分解的前提是A列满秩,此时采用施密特正交化方法使A=QR,Q为酉矩阵(正交矩阵),R为上三角阵,在视觉SLAM中相当于将A分解成一个旋转矩阵和一个上三角的标定阵。
优点是求解速度快,算法稳定,常用于求解线性方程组的解。缺点是只能求解满秩矩阵
SVD分解:
即奇异值分解,A=UDV',其中U、V均为酉矩阵,D为对角阵,对角线元素为各奇异值,且衰减速度通常较快,SVD几何意义可以写成AV=UD,即当矩阵A作用于任何基向量v时,会把v变换到u的方向,同时将u的长度变成对应奇异值σ。也可以看成先旋转然后缩放再旋转的过程。
SVD分解可靠性最好,能求解非满秩矩阵,但计算时间复杂度比QR要高
LU 分解:
法是将矩阵 A 分解成两个矩阵 L 和 U,其中 L 是一个下三角矩阵,U 是一个上三角矩阵。然后通过消元的方法来求解线性方程组。
优点是求解速度快,算法稳定,常用于求解方程组的解。缺点是只能求解正定矩阵
10、MLE和MAP的关系是?
最大似然估计(MLE,Maximum Likelihood Estimation)是一种参数估计方法,它根据已知的样本数据,寻找使数据出现概率最大的参数。其目标是最大化似然函数,即观测数据的概率。在最大似然估计中,并不考虑参数的先验分布。
最大后验概率估计(MAP,Maximum A Posteriori Estimation)是一种贝叶斯参数估计方法,它在最大似然估计的基础上,引入了参数的先验分布。其目标是最大化后验概率,即在给定样本数据的条件下,参数的概率。
MLE与MAP的主要区别在于是否考虑参数的先验分布。MAP是在考虑参数先验分布的情况下进行的估计,而MLE则是忽略参数先验分布的特殊情况。当参数的先验分布为均匀分布或者对估计问题没有影响时,MAP估计会退化为MLE估计。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









