







今天继续学习,这次主要学了一些神经网络相关的知识(以鸢尾花分类为例)-然后运行示例感受学习率变化对网络中权重变化的影响(主要是1.1-1.2课程,视频链接:1.1 神经网络(连接主义)的程序流程_哔哩哔哩_bilibili)。
1.基本知识
1)输入数据
花萼长、花萼宽、花瓣长、花瓣宽
2)神经网络(简化的MP模型:少了非线性函数)
①(结果[1,3]=输入数据[1,4]*权重[4,3]+偏置[3, ])
(注:a.权重、偏置会随机初始化b.除喂入输入数据外,记得添加标签)
②损失函数(loss function):衡量预测值与标签
(标准答案)的差距
均方误差:
③目的:找一组权重和偏置使得损失函数最小
(注:a.梯度下降法:就是沿损失函数梯度下降方向寻找损失函数最小值,会寻找到最优参数b.梯度:函数对各个参数求偏导后的向量)
这里是学习率,如果学习率过小则收敛会很慢;如果学习率过大,梯度可能会在最小值附近来回震荡(甚至无法收敛)。
表示的是损失函数。
④反向传播:从后向前,逐层求损失函数对每层神经元参数的偏导,迭代更新所有参数。
2.运行代码-感受学习率等影响因素的作用
(视频链接11:45有代码提取连接:1.2 鸢尾花分类问题_哔哩哔哩_bilibili)
1)打开p13_backpropagation.py运行
(注:这里看代码能不能找到的原因是,前面作者把损失函数画了一下,用的损失函数不是MSE,而是
,那么
取得-1时有最小的损失函数。)
import tensorflow as tf
w = tf.Variable(tf.constant(5, dtype=tf.float32)) # 设计随机初始值
lr = 0.2 # 学习率
epoch = 40 # 循环迭代
for epoch in range(epoch): # for epoch 定义顶层循环,表示对数据集循环epoch次,此例数据集数据仅有1个w,初始化时候constant赋值为5,循环40次迭代。
with tf.GradientTape() as tape: # with结构到grads框起了梯度的计算过程。
loss = tf.square(w + 1) # 设计loss函数
grads = tape.gradient(loss, w) # .gradient函数告知谁对谁求导
w.assign_sub(lr * grads) # .assign_sub 对变量做自减 即:w -= lr*grads 即 w = w - lr*grads
print("After %s epoch,w is %f,loss is %f" % (epoch, w.numpy(), loss))
# lr初始值:0.2 请自改学习率 0.001 0.999 看收敛过程
# 最终目的:找到 loss 最小 即 w = -1 的最优参数w结果:
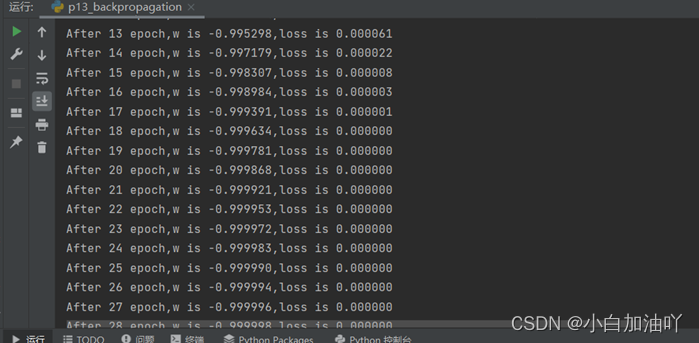
可以看到可以找到loss函数最小的值。
2)如果将学习率改为0.001
运行结果为:
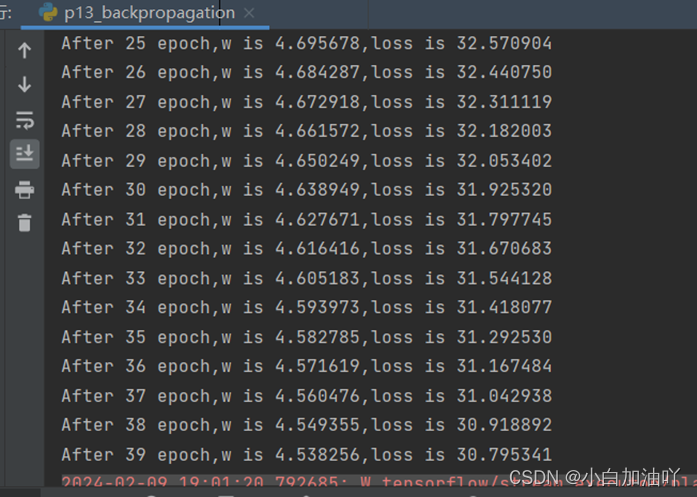
可以看到没有收敛。
3)如果把学习率改为0.99
运行结果为:
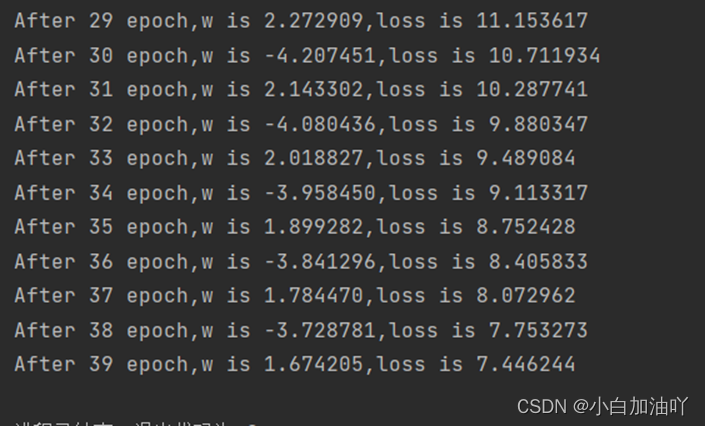
可以看到很难收敛。
3.总结
1)学习率不可以过大,也不能过小
2)涉及到的函数和结构
tf.Variable:tensorflow里生成随机数的函数
for epoch in range(epoch):for循环
tf.GradientTape():tensorflow里自动求导的函数
tf.square:tensorflow里求平方的函数
变量.assign_sub: 对变量做自减

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









