







今天跟着曹老师学了鸢尾花分类问题的数据预处理和实现部分的课程(网页地址:1.6 鸢尾花分类问题数据预处理_哔哩哔哩_bilibili),做了一些笔记,并分享了曹老师在视频中展示的代码。
1.数据处理
1)数据集构成
鸢尾花数据集,共有150组,每组包括花萼长、花萼宽、花瓣长和花瓣宽四个特征,一组特征对应一个鸢尾花的类别,类别包括,狗尾草鸢尾花(Setosa Iris)、杂色鸢尾(Versicolour Iris)、弗吉尼亚鸢尾(Virginica Iris),分别用0、1、2表示。
2)数据获取
可以从sklearn包datasets读入数据集,语法为:
from sklearn.datasets import load_iris
x_data=datasets.load_iris().data # 返回iris数据集所有输入特征
y_data=datasets.load_iris().target # 返回iris数据集所有标签
示例代码为
from sklearn import datasets
from pandas import DataFrame
import pandas as pd
x_data = datasets.load_iris().data # .data返回iris数据集所有输入特征
y_data = datasets.load_iris().target # .target返回iris数据集所有标签
print("x_data from datasets: \n", x_data)
print("y_data from datasets: \n", y_data)
x_data = DataFrame(x_data, columns=['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']) # 为表格增加行索引(左侧)和列标签(上方)
pd.set_option('display.unicode.east_asian_width', True) # 设置列名对齐
print("x_data add index: \n", x_data)
x_data['类别'] = y_data # 新加一列,列标签为‘类别’,数据为y_data
print("x_data add a column: \n", x_data)
#类型维度不确定时,建议用print函数打印出来确认效果(注:①Pandas 是 Python 语言的一个扩展程序库,提供高性能、易于使用的数据结构和数据分析工具(找了一个比较全的介绍:Pandas 教程 | 菜鸟教程 (runoob.com))。②为表格增加索引:pandas.DataFrame( data(一组数据), index(索引值/行标签), columns(列标签), dtype(数据类型,默认为0,1,2……), copy(拷贝数据,默认为False))③给表格设置显示格式:pd.set_option('display.max_columns'(显示列)/ 'display.max_rows'(显示行)/ 'display.float_format'(显示小位数)/ 'display.width'(显示宽度)/ 'display.unicode.east_asian_width'(设置列名对齐), None(展示所有列/所有行)/数字(最多展示的列/行数或宽度)/ lambda x: '%.2f'%x(展示两位小数))④给表格增加列:data[‘列标签’]=新增列的数据)
运行代码,发现出现提示没有安装sklearn包:

解决方案:
①打开终端

②输入安装sklearn包的命令
pip install scikit-learn
(注:如果使用视频中的命令pip install sklearn会报错)
运行程序,发现还会报错

解决方案
①打开终端
②输入安装pandas包的命令
pip install pandas
运行程序,可以看到相应的结果

2.使用神经网络实现鸢尾花分类
1)准备数据
①数据读入
输入代码:
from sklearn.datasets import load_iris
x_data=datasets.load_iris().data # 返回iris数据集所有输入特征
y_data=datasets.load_iris().target # 返回iris数据集所有标签
②数据集乱序
原因:因为信息进入大脑的实际情况是杂乱无章的,那么数据喂入网络也应该乱序的
输入代码:
np.random.seed(116) # 使用相同的seed,使得输入特征和标签是一一对应的
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116)
(注:①np.random.seed()可以按顺序产生一组固定的数组,如果使用相同的seed()值,则每次生成的随机数都相同。如果不设置这个值,那么每次生成的随机数不同。但是,只在调用的时候seed()一下并不能使生成的随机数相同,需要每次调用都seed()一下,表示种子相同,从而生成的随机数相同。其中116代表的是选取的第116堆种子。②np.random.shuffle():在原数组上进行,改变自身序列,无返回值(多维矩阵中,只对第一维(行)做打乱顺序操作)。③tf.random.set_seed(116):生成全局种子,就是使用之后不需要一个一个再设置一次seed,就是可以跨会话生成相同随机数。)
③生成训练集和测试集(即x_train/y_train,x_test/y_test)
将前120个数据集作为训练集:
x_train=x_data[:-30] # 逗号左边是行范围,逗号右边是列范围;冒号左边是起始值。冒号右边代表终止值,如果是带负号则是倒着数第几个。这个代表从开始到倒数三十行数据全部列。
y_train=y_data[:-30]
将后30个数据集作为测试集:
x_test=x_data[-30:]
y_test=y_data[-30:]
④配成(输入特征,标签)对,每次读入一小撮(batch)
给输入特征和标签对打包batch方法就是在配对的函数后边加.batch(每个包数据个数):tf.data.Dataset.from_tensor_slices((输入特征,标签)).batch(每个包数据的个数)。
train_db=tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db= tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
2)搭建网络
定义神经网络中所有可训练的参数
w1=tf.Variable(tf.random.nomal([4,3],saddev=1,seed=1))
b2=tf.Variable(tf.random.nomal([3],saddev=1,seed=1))
(注:这里的seed表示的是随机数种子,设置以后,每次生成的随机数都一样,也就是说w1和b1每次训练的初始值是一样的)
3)参数优化
嵌套循环迭代,with结构更新参数,显示当前loss
for epoch in range(epoch): # 蓝色的range(epoch)意思是生成0-epoch个数,而红色的epoch是接收这个数
for stape,(x_train,y_train) in enumerate(train_db): # 遍历刚才分割好的训练数据,一次送入一个batch里边所有的数据,所以stape=训练数据总数/batch(每个包的元素个数)
with tf.GrandientTape() as tape: # 记录梯度
前向传播计算y
计算总loss # 计算y和loss具体可以看完整代码这一部分(注:一定要将存储每轮的loss的表提前定义出来:train_loss_results = [])
grads=tape.gradient(loss,[w1,b1]) # 计算梯度
w1.assign_sub(lr*grads[0]) # w1自更新
b1.assign_sub(lr*grads[1]) # b1自更新
print(“Epoch{},loss:{}”.format(epoch,loss_all/4)) # 这里loss_all/4 是因为总数据为120组,一个batch里有32组数据,所以一共有step=4,所以所有数据循环训练一次的loss的均值就要除以4,也就是要除以step。(注:Python format 格式化函数 | 菜鸟教程 (runoob.com)这个连接里边有详细的写为什么要用{}和.format结构和这个结构怎么用)
4)测试效果
测试部分:计算当前参数前向传播后的准确率,显示当前acc(注:每epoch都要测试一次看效果,所以这个是在for epoch in range(epoch)这节添加的)
for x_train,y_train in test_db
y=tf.matmul(h,w)+b # y的预测结果
y=tf.nn.softmax(y) # 使y符合概率分布
pred=tf.argmax(y,axis=1) # 跨列找最大的索引
pred=tf.cast(pred,dtype=y_test.dtpe) # 强制转换数据类型与标签一致
correct=tf.cast(tf.equal(pred,y_test),dtype=tf.int32) # tf.equal(A, B)是对比这两个矩阵或者向量的相等的元素,如果是相等的那就返回True,反正返回False,返回的值的矩阵维度和A是一样的
correct=tf.reduce_sum(correct) # 将每个batch中的correct数加起来
total_correct+=int(correct) # 将所有batch中的correct加起来(注:int()表示转换成整型)
total_number+=x_test.shape[0] # (注:shape[0]读取矩阵第一维度的长度,以此类推)
acc=total_correct/total_number # 准确率 (注:一定要把存储每一轮的acc值得列表提前定义出来:test_acc = [])
print(“test_acc:”,acc)
5)acc/loss可视化
把准确率画成曲线
plt.title(‘Acc curve’) # 图片标题
plt.xlabel(‘Epoch’) # x轴名称
plt.ylabel(‘Acc’) # y轴名称
plt.plot(test_acc,label=”$Accuracy$”) # 逐点画出test_acc值并连线
plt.legend() # 创建图例
plt.show()
(注:具体画图可以看连接Matplotlib Pyplot | 菜鸟教程 (runoob.com))
3.完整代码
这个代码来自1.7 鸢尾花分类问题tensorflow实现代码示例_哔哩哔哩_bilibili之前给的代码包中class1>p45_iris.py
# 利用鸢尾花数据集,实现前向传播、反向传播,可视化loss曲线
# 导入所需模块
import tensorflow as tf
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
# 导入数据,分别为输入特征和标签
x_data = datasets.load_iris().data
y_data = datasets.load_iris().target
# 随机打乱数据(因为原始数据是顺序的,顺序不打乱会影响准确率)
# seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样(为方便教学,以保每位同学结果一致)
np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应
np.random.shuffle(x_data)
np.random.seed(116)
np.random.shuffle(y_data)
tf.random.set_seed(116)
# 将打乱后的数据集分割为训练集和测试集,训练集为前120行,测试集为后30行
x_train = x_data[:-30]
y_train = y_data[:-30]
x_test = x_data[-30:]
y_test = y_data[-30:]
# 转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错
x_train = tf.cast(x_train, tf.float32)
x_test = tf.cast(x_test, tf.float32)
# from_tensor_slices函数使输入特征和标签值一一对应。(把数据集分批次,每个批次batch组数据)
train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)
# 生成神经网络的参数,4个输入特征故,输入层为4个输入节点;因为3分类,故输出层为3个神经元
# 用tf.Variable()标记参数可训练
# 使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed)
w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1))
b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1))
lr = 0.1 # 学习率为0.1
train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据
test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据
epoch = 500 # 循环500轮
loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和
# 训练部分
for epoch in range(epoch): #数据集级别的循环,每个epoch循环一次数据集
for step, (x_train, y_train) in enumerate(train_db): #batch级别的循环 ,每个step循环一个batch
with tf.GradientTape() as tape: # with结构记录梯度信息
y = tf.matmul(x_train, w1) + b1 # 神经网络乘加运算
y = tf.nn.softmax(y) # 使输出y符合概率分布(此操作后与独热码同量级,可相减求loss)
y_ = tf.one_hot(y_train, depth=3) # 将标签值转换为独热码格式,方便计算loss和accuracy
loss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方误差损失函数mse = mean(sum(y-out)^2)
loss_all += loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确
# 计算loss对各个参数的梯度
grads = tape.gradient(loss, [w1, b1])
# 实现梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_grad
w1.assign_sub(lr * grads[0]) # 参数w1自更新
b1.assign_sub(lr * grads[1]) # 参数b自更新
# 每个epoch,打印loss信息
print("Epoch {}, loss: {}".format(epoch, loss_all/4))
train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中
loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备
# 测试部分
# total_correct为预测对的样本个数, total_number为测试的总样本数,将这两个变量都初始化为0
total_correct, total_number = 0, 0
for x_test, y_test in test_db:
# 使用更新后的参数进行预测
y = tf.matmul(x_test, w1) + b1
y = tf.nn.softmax(y)
pred = tf.argmax(y, axis=1) # 返回y中最大值的索引,即预测的分类
# 将pred转换为y_test的数据类型
pred = tf.cast(pred, dtype=y_test.dtype)
# 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型
correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32)
# 将每个batch的correct数加起来
correct = tf.reduce_sum(correct)
# 将所有batch中的correct数加起来
total_correct += int(correct)
# total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数
total_number += x_test.shape[0]
# 总的准确率等于total_correct/total_number
acc = total_correct / total_number
test_acc.append(acc) # 把每一轮的acc记录下来
print("Test_acc:", acc)
print("--------------------------")
# 绘制 loss 曲线
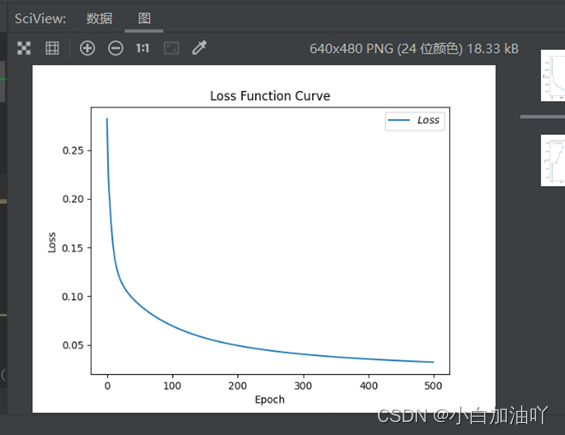
plt.title('Loss Function Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Loss') # y轴变量名称
plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss
plt.legend() # 画出曲线图标
plt.show() # 画出图像
# 绘制 Accuracy 曲线
plt.title('Acc Curve') # 图片标题
plt.xlabel('Epoch') # x轴变量名称
plt.ylabel('Acc') # y轴变量名称
plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy
plt.legend()
plt.show()点击运行,会出现错误,显示没有安装matplotlib包,解决方案是:①进入终端②输入:pip install matplotlib
然后再点击运行,就出现了准确率和损失值函数图像

4.总结
1)每次训练和测试都是要走完一遍整个数据集的,epoch是进行多少次这个过程。
2)每次走完一遍数据集,都应该对应一个平均损失值和准确率。
3)如果提示没有安装包,可以在pycharm的“终端”输入“pip install 包名”。
















 825
825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









