






关于Java里面的String.getBytes()方法
Java里面的String类型的编码方式是Unicode,根据你项目字符串的编码方式无关,这是写死的。但是如果你jvm平台使用的是GBK编码方式,那么你通过string里面的getBytes()方式获取的字符的字节是2。如果使用的是UTF-8编码的方式,那么一个字符getBytes()方式获取的字符的字节长度应该是3.
下面给个例子进行展示:
String str ="你好"; //project的字符集是UTF-8
byte[] B = str.getBytes(); //所以这里默认应该使用UTF-8进行编码
System.out.println(B.length);
System.out.println(Charset.defaultCharset());
//结果是:(果然是6)
//6
//UTF-8
这里的**str.getBytes()**方法官方给出的解释是:
Encodes this String into a sequence of bytes using the platform’s default charset, storing the result into a new byte array.
就是说**getBytes()**函数会根据平台的默认字符串返回byte[]数组,这个platform’s default charset并跟操作系统有关。当然你可以在Eclipse中设置你的项目使用的编码方式,更改项目文件的编码方式能改变平台的中的默认编码方式。
在Eclipse中可以通过选定项目,然后通过上方的工具栏Project–>Properties–>Resource处更改项目编写的文件的encoding方式。
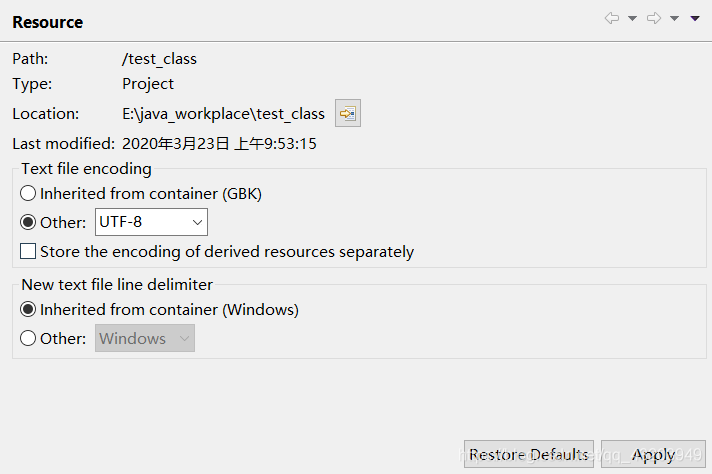
如果我更改成默认的GBK,那么下面的例子返回的字节长度就会变成4
String str ="你好"; //project的字符集是GBK
byte[] B = str.getBytes(); //
System.out.println(B.length);
System.out.println(Charset.defaultCharset());
//结果是:
//4
//GBK















 7121
7121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









