







论文题目:Avalon’s Game of Thoughts: Battle Against Deception through Recursive Contemplation
论文链接:https://arxiv.org/pdf/2310.01320
AVALON思维游戏:通过递归思考对抗欺骗
摘要
在当下AI领域,大型语言模型(LLMs)正迅速崛起,它们的能力在多个领域内得到了广泛的应用和认可。但是,一个不可忽视的问题是,这些模型在处理信息时往往默认信息的真实性,而在现实世界中,欺骗和误导信息无处不在。这一疏忽可能使得LLMs易受到恶意信息的影响,导致不可预知的后果。
针对这一问题,本研究选择了一个充满欺骗和策略的环境——Avalon游戏,作为探究LLMs在应对欺骗信息能力的试验场。Avalon不仅是一个娱乐活动,更是一场关于识别真相、战略思考的智力游戏。受到人类玩家在游戏中运用递归思考和多层次透视来揭示真相的启发,研究中提出了一种名为递归思考(ReCon)的框架,旨在增强LLMs对抗欺骗性信息的能力。
ReCon框架分为两个核心过程:
-
构思沉思。构思沉思负责产生初始的想法和言语表达
-
完善沉思。完善思考则在此基础上进一步细化和优化
此外,框架中还嵌入了一阶和二阶透视转换的概念。
-
一阶透视让LLMs可以推测他人的心理状态
-
二阶透视则进一步考虑其他人是如何理解代理人自身的心理状态
实验结果显示,当ReCon框架与LLMs结合使用时,即便不进行额外的微调和数据训练,也能有效提高模型识别和应对欺骗信息的能力。这项研究不仅展示了ReCon框架的实用性,还从一个新的角度审视了LLMs在安全性、推理能力、语言风格和表达格式等方面的当前局限,为未来的研究提供了新的思路和可能性。
总结来说,Avalon游戏为我们提供了一个独特的视角来理解和改善LLMs。正如人类的思想和记忆可以被外界所见,LLMs也应该具备洞察欺骗并保持透明度的能力。而ReCon框架正是向这一目标迈出的重要一步。
阿瓦隆游戏中的欺骗策略
阿瓦隆游戏以其深层的策略和欺骗元素获得了广泛的关注,玩家需要在其中展示出巧妙的策略和应对欺骗的能力。下面是阿瓦隆游戏的一些核心元素:
- 角色的秘密性:玩家的角色保密,好人需要找出彼此,而坏人已知彼此身份且需要欺骗好人。
- 团队投票:玩家通过投票确定执行任务的团队,坏人需要影响投票结果而不暴露自己。
- 任务执行:团队成员选择支持或破坏任务,坏人可根据策略破坏任务或暂时伪装合作。
- 推理讨论:玩家通过讨论揭示信息,好人尝试识别坏人,而坏人则散布虚假信息制造混乱。
大型语言模型的挑战
在探讨了游戏的核心机制后,我们转向LLMs在面对这些欺骗策略时的挑战:
- 抗击误导:LLMs可能被恶意内容误导,导致代理作为好人时做出不利决策。
- 隐私保护:LLMs需要保护自己的信息,避免在游戏中泄露关键策略。
- 团队平衡:LLMs必须平衡团队构成,推算出潜在的坏人并维护整个团队的稳定。
通过解决这些挑战,LLMs不仅能够在阿瓦隆这样的游戏中表现得更加出色,还能在现实世界中更好地理解和对抗欺骗和策略行为。我们期待AI在这一领域的进一步研究和发展。
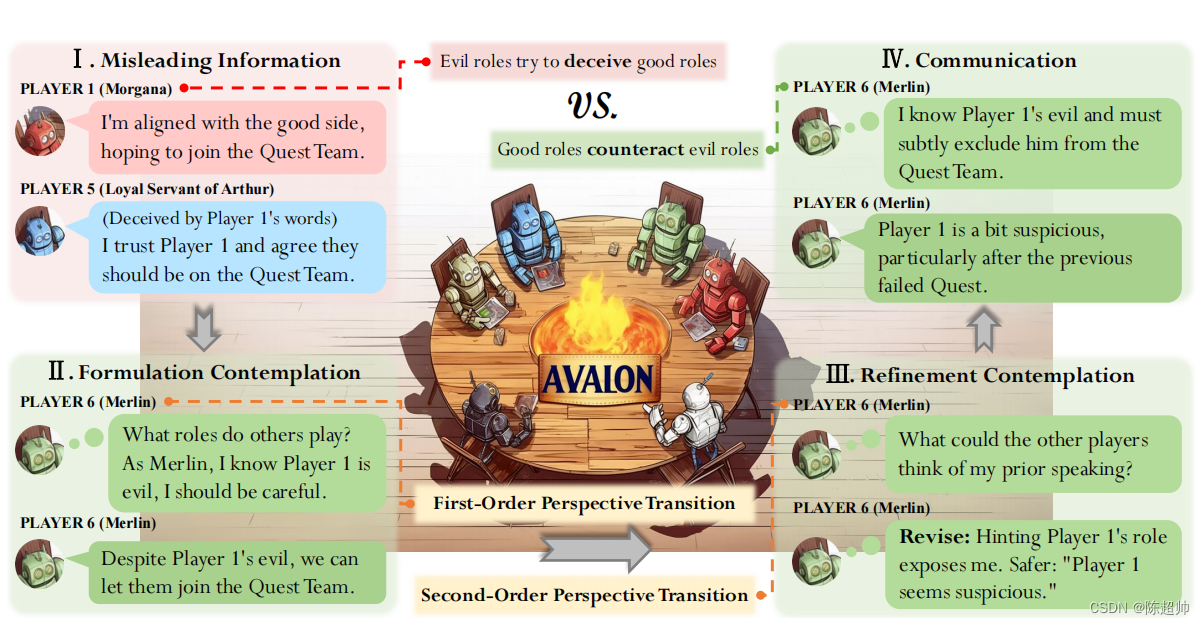
ReCon的两个关键机制:构思沉思、完善沉思
构思沉思:ReCon模型的核心思考过程
在技术创新的道路上,我们常常需要对现有模型进行深入的思考和改进,尤其是在人工智能领域,这一过程显得尤为重要。今天,我们将探讨ReCon模型的初步构思阶段——构思沉思(formulation contemplation),这一阶段至关重要,因为它定义了模型生成代理言辞内容时的基本框架。
为了解决代理在处理私人信息时可能出现的隐瞒或泄露问题,ReCon模型提出了一个独特的解决方案:在生成对外的言辞内容之前,进行一段内部的思考过程。这段内部的思考是私有的,只有模型自身能够访问,而生成的言辞则是公开的,供所有参与者查看。这样的设计可以让模型在不泄露敏感信息的情况下更好地模拟人类的思维过程。
一阶视角转换:推理的起点
为了使代理能够在思考时具备更高级的推理能力,ReCon模型引入了一种新的子过程,叫做一阶视角转换。简单来说,这个过程就是让代理尝试从自己的视角出发,推测其他参与者可能的想法和立场。这与我们人类在进行策略游戏时的行为很相似,我们会根据对方的行动和以往的表现来猜测对方的身份和意图,进而影响我们的行为和决策。
在实际操作中,代理会根据游戏的历史记录来做出对其他玩家角色的推断。一旦建立了对某个角色的假设,它就会被并入到后续的思考过程中,帮助代理构建更为合理的言辞内容。
完善沉思:提升思考质量
尽管代理已经进行了初步的思考,但有时仍可能发生错误,例如不慎暴露了角色信息。基于“三思而后行”的智慧,ReCon模型在初步思考之后加入了完善沉思的环节,目的是对初步生成的内部思考和言辞内容进行再次评估和改进。
二阶视角转换:深度反思
这个环节的核心是所谓的二阶视角转换,它要求代理从其他参与者的角度出发,重新审视自己最初的言辞内容。可以将其理解为“换位思考”的过程,代理需要考虑如果自己的言辞被好人和坏人听到,他们会如何反应和评价。
在Avalon游戏的背景下,这个过程被形象地转化为一个问题:“如果我说出我的初步言辞,其他角色会怎么看?”基于这种思考,代理会获得一个更为全面的视角来重新评估和完善它的言辞。
通过这些反复的思考过程,ReCon模型可以生成更加精细、周到的言辞内容,使其在游戏中的表现更加贴近人类玩家的思考模式,同时也能更好地保护私人信息不被泄露。
ReCon架构提供了一种新的视角,让我们理解机器如何能在复杂的人类沟通环境中,保持信息的安全性和有效沟通的平衡。通过模拟人类的思考过程,ReCon不仅增强了机器的策略沟通能力,也为我们提供了新的思考角度,去理解人与人之间沟通的复杂性。
附阿瓦隆游戏规则:
在探讨《阿瓦隆》游戏中的各种角色之前,了解游戏的流程和规则是很重要的,总结如下:
- 游戏设置:玩家秘密地被分配其中六个角色之一,包括1个梅林、1个派西维尔、1个莫甘娜、1个刺客和2个忠诚的仆从,所有角色都属于好方或者邪恶方。
- 团队选择:每一轮,领导者提议一个团队进行任务。在讨论后,玩家就提议的团队组成表达自己的意见。如果团队得到多数的批准,团队就最终确定下来,否则,平局或者少数支持都会导致拒绝。如果获得批准,游戏进入任务阶段;如果没有,领导权转移到下一个玩家,团队选择过程重新开始。
- 任务阶段:被选中的团队成员秘密决定是支持还是破坏任务。
好方的玩家必须投支持票,而邪恶方的玩家可以选择支持或者破坏。投票结果同时公布。如果没有玩家选择破坏,则任务成功;否则任务失败。 - 结局:如果好方在五个任务中有三个成功,好方获胜。相反,如果有三个任务失败,则邪恶方获胜。
- 终局情景:如果好方即将获胜,邪恶方的刺客必须正确地辨认出梅林,才能为邪恶方取得胜利。如果刺客正确辨认出梅林,则邪恶方获胜;否则,胜利归于好方。
完结!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









