







[tensor management] DeepUM: Tensor Migration and Prefetching in Unified Memory.Jaehoon Jung, Jinpyo Kim, Jaejin Lee. ASPLOS’23
论文地址:https://dl.acm.org/doi/pdf/10.1145/3575693.3575736
这篇文章主要介绍了一个叫做 DeepUM 的框架,它利用 CUDA Unified Memory(UM,统一内存)来实现深度神经网络(DNNs)的 GPU 内存过量订阅。
- 统一内存允许通过页面错误机制来实现内存的过量订阅,但页面迁移带来了巨大的开销。
DeepUM 使用了一种新的相关预取技术来隐藏页面迁移的开销,这种技术是完全自动的,对用户是透明的。此外,文章还提出了两种优化技术,以尽量减少 GPU 错误处理的时间。
这里首先需要解释一下CUDA Unified Memory(UM,统一内存)
CUDA Unified Memory (UM) 是 NVIDIA 提供的一种内存管理技术,它为 CPU 和 GPU 提供了一个统一的内存空间。这种技术允许 CPU 和 GPU 共享同一块内存,从而简化了数据在 CPU 和 GPU 之间的传输。
在没有统一内存的情况下,当你编写涉及 GPU 计算的代码时,通常需要手动分配 GPU 内存,将数据从 CPU 内存复制到 GPU 内存,然后执行 GPU 计算,最后再将结果从 GPU 内存复制回 CPU 内存。这个过程相当繁琐,也容易出错。
而有了统一内存,你只需要分配统一内存,然后就可以在 CPU 和 GPU 之间自由地使用这块内存,而不需要做任何显式的数据传输。当你在 GPU 上访问统一内存中的数据时,如果这些数据还没有在 GPU 内存中,则会触发一个页面错误,CUDA 运行时会自动将这些数据从 CPU 内存复制到 GPU 内存。
然而,这种自动数据迁移也会带来一定的开销,尤其是当数据需要频繁在 CPU 和 GPU 之间移动时。因此,如何有效地管理和优化统一内存的使用,是一个重要的挑战。
UM 是一种虚拟内存,所有的内存对象都以 4KB 页面为单位进行管理。因此,它受到内存碎片的影响较小,更有可能无问题地运行大型 DNN 模型。
在这篇文章中,作者通过使用相关预取技术和优化 GPU 错误处理时间,有效地解决了这个问题。
在本文中,我们先来关心一下目前GPU内存的解决方案,由于这篇论文是23年的,我认为还是比较有参考价值的
为了解决这种内存容量问题,已经进行了许多研究,如数据压缩[6, 10, 18, 26, 34],混合精度算术[11, 17, 28],数据重计算[8, 16, 55],以及内存交换[5, 6, 21, 24, 33, 45, 49–51, 55]。在这些方法中,作者关注的是 GPU 内存交换,以解决 DNNs 的内存容量问题。
我这里放一下相关的论文列表,有助于后期深入研究
数据压缩[6, 10, 18, 26, 34]:
- FlashNeuron: SSD-Enabled Large-Batch Training of Very Deep Neural Networks. 2021
- Buddy Compression: Enabling Larger Memory for Deep Learning and HPC Workloads on GPUs.(已读) 2020.
- Learning Both Weights and Connections for Efficient Neural Networks. 2015.
- Gist: Efficient Data Encoding for Deep Neural Network Training. 2018.
- A Framework for Memory Oversubscription Management in Graphics Processing Units.2019.
混合精度算术[11, 17, 28]:
- BinaryConnect: Training Deep Neural Networks with Binary Weights during Propagations.2015.
- Deep Learning with Limited Numerical Precision. 2015.
- Proteus: Exploiting Numerical Precision Variability in Deep Neural Networks. 2016.
数据重计算[8, 16, 55]:
- Training deep nets with sublinear memory cost. 2016.
- Memory-Efficient Backpropagation through Time. 2016.
- Superneurons: Dynamic GPU Memory Management for Training Deep Neural Networks. 2018.
内存交换[5, 6, 21, 24, 33, 45, 49–51, 55] (6,55已经列在上面,不赘述):
- OC-DNN: Exploiting Advanced Unified Memory Capabilities in CUDA 9 and Volta GPUs for Out-of-Core DNN Training. 2018.
- AutoTM: Automatic Tensor Movement in Heterogeneous Memory Systems Using Integer Linear Programming. 2020.
- SwapAdvisor: Pushing Deep Learning Beyond the GPU Memory Limit via Smart Swapping. 2020.
- TFLMS: Large Model Support in TensorFlow by Graph Rewriting. 2018.
- Capuchin: Tensor-Based GPU Memory Management for Deep Learning.(已读) 2020.
- DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. 2020.
- Sentinel: Efficient Tensor Migration and Allocation on Heterogeneous Memory Systems for Deep Learning. 2021.
- vDNN: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design.2016.
由于地址转换和页面错误处理带来的显著开销,基于 UM 的 GPU 内存交换研究很少。因为 UM 使用需要进行每个内存请求地址转换的虚拟内存,所以可能会对性能产生重大影响。此外,处理页面错误需要在 CPU 和 GPU 之间进行昂贵的 I/O 操作,以在它们之间迁移页面。
这就是本文存在的意义。
DeepUM 修改了一个最初用于缓存行预取的相关预取技术来预取 GPU 页面。在各种预取技术中,作者选择相关预取,因为它与 UM 相协同。由于 UM 基于页面错误机制,因此页面错误处理程序会监控错误访问。DeepUM 可以使用从页面错误处理程序获取的错误地址轻松记录错误页面之间的关系。DeepUM 利用的事实是,**内核执行模式和它们的内存访问模式在 DNN 训练工作负载中主要是固定和重复的。**因此,记住重复的模式并通过相关预取利用信息是可取的。DeepUM 的相关表记录了 DNN 训练阶段内核执行和页面访问的历史。**它根据相关表中的信息预取页面,通过预测下一个将要执行的内核。**而传统的相关预取使用单个表存储历史并记录 CPU 缓存行之间的关系,DeepUM 的相关预取使用两种不同的表结构。
DNN 训练工作负载中主要是固定和重复的,这个思想在Capuchin中写过。Capuchin是2020年的文章。这篇是2023的文章,应用场景不同而已。
为了最小化错误处理时间,DeepUM 提出了两种优化技术,用于 NVIDIA 设备驱动程序的部分 GPU 错误处理例程。
-
一种是基于相关表信息的页面预先驱逐。当 GPU 内存被过度订阅时,页面驱逐会增加页面错误处理时间,因为页面驱逐逻辑位于页面错误处理例程的关键路径上。
"页面驱逐逻辑位于页面错误处理例程的关键路径上"这句话的意思是,在处理页面错误的过程中,页面驱逐(Page Eviction)的操作是十分关键且不可避免的一步。
让我们来解析一下这个过程:
- 页面错误(Page Fault):当 GPU 尝试访问其内存中不存在的数据时,就会发生页面错误。这通常发生在数据被存储在 CPU 的内存中,而 GPU 尝试访问这些数据时。
- 页面驱逐(Page Eviction):为了解决页面错误,系统需要将数据从 CPU 内存移至 GPU 内存。但是,如果 GPU 内存已满,系统首先需要驱逐(即删除)一些已存在于 GPU 内存中的数据,以便为新数据腾出空间。这就是页面驱逐
如果能够优化页面驱逐的过程,那么处理页面错误的总时间就可以得到显著的减少,从而提高整体的系统性能。这也是 DeepUM 框架的优化策略之一。
-
另一种优化是在页面驱逐受害者预计不再被 PyTorch 使用时,使 GPU 内存中的页面失效。这种优化删除了 CPU 和 GPU 之间不必要的内存流量。
如果我们知道某个页面不再会被 PyTorch 使用,那么就没有必要将其移动回 CPU 内存,直接在 GPU 内存中废弃掉就可以。这样就避免了不必要的数据传输
回顾一下NVIDIA GPU的结构:
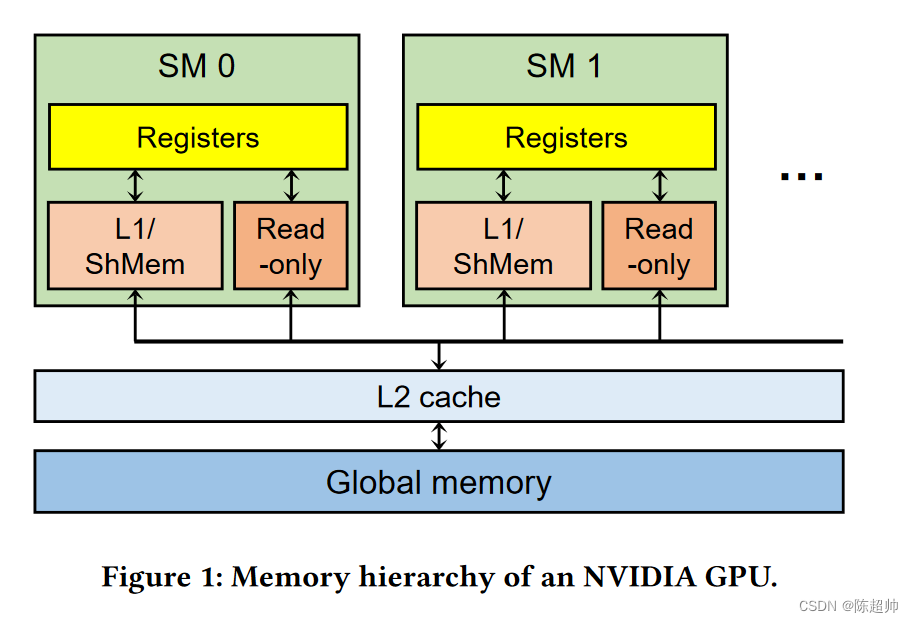
NVIDIA GPU 内存层次结构:一个 GPU 由数十个流处理器 (Streaming Multiprocessors, SMs) 组成。网格中的每个线程块都映射到 GPU 中的一个 SM。每个 SM 包含数百个 CUDA 核心。线程块中的线程映射到一个 CUDA 核心,一个 SM 可以同时处理几个线程块。每个 SM 有不同类型的内存单元,如寄存器、L1 缓存、共享内存(暂存内存)和常量内存(只读内存)。寄存器对每个线程是私有的,而其他内存单元在 SM 内部是共享的。在 SM 外部,有一个所有 SMs 共享的 L2 缓存。全局内存是一个离芯片 DRAM,一般有几个 GB 到几十个 GB。与通常情况一样,距离 CUDA 核心(SMs)更近的内存单元拥有更低的延迟和更小的容量。尽管 GPU 提供了几十 GB 的全局内存,但深度神经网络 (DNN, Deep Neural Network) 工作负载严重缺乏全局内存。
GPU页面错误
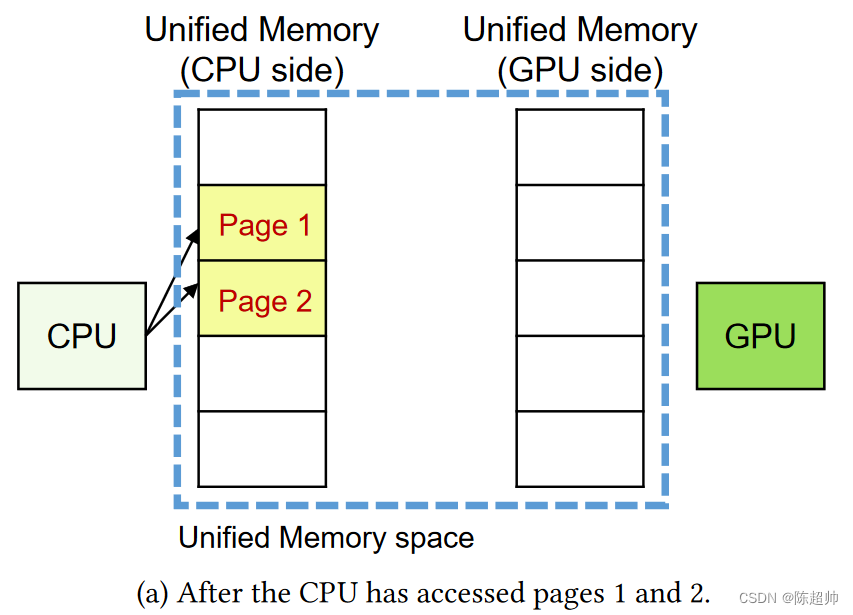
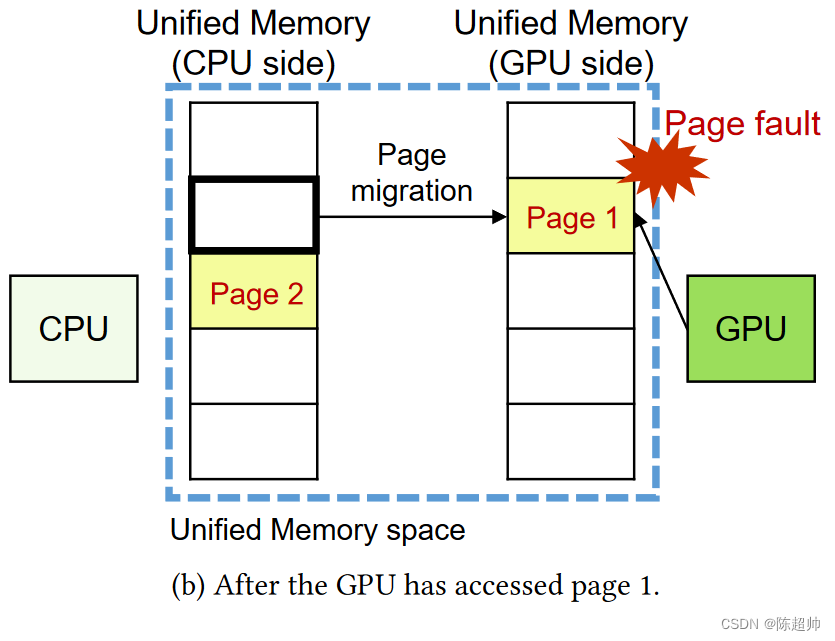
在图2(a)中(也就是下图),程序员创建了一个统一内存(UM)区域。这个区域在主机(即CPU)的主内存中有一份,也在GPU的内存中有一份。假设CPU已经访问了页面1和页面2,那么这两个页面就会存放在主机的UM区域中。在图2(b)中,GPU试图访问页面1。但是由于页面1在主机的UM区域中,GPU会产生一个页面故障中断信号。然后,NVIDIA的设备驱动程序会将页面1从主内存迁移到GPU内存。当迁移完成后,GPU会重新尝试访问之前产生故障的页面。
每个 GPU 中的流处理器 (SM) 都有一个翻译后援缓冲器 (Translation Lookaside Buffer, TLB)。当 GPU 的流处理器(SM)出现页面错误时,对应的翻译后援缓冲器(TLB)会被锁定,直到所有来自该 SM 的页面错误都被解决为止。这实际上意味着,在所有页面错误都被解决之前,TLB 无法进行新的地址转换过程,也就是说,无法将虚拟内存地址转换为物理内存地址。因此,在所有页面错误都被解决之前,这个流处理器无法正常地访问新的内存页面。
页面错误处理程序
当NVIDIA GPU产生一个页面故障中断信号时,NVIDIA驱动程序会捕获这个中断信号并进行处理。故障缓冲区是NVIDIA GPU中的一个循环队列,它储存了发生故障的访问信息。GPU可以同时产生多个故障,并且在故障缓冲区中可以有同一页面的多个故障条目。
统一内存块(UM block)是最多512个连续页面的一组,也是NVIDIA驱动程序的管理单元。一个UM块的最大大小是 4KB × 512 = 2MB,同一UM块中的所有页面都由NVIDIA驱动程序一起处理。每个UM块对象包含了UM块中所有页面的信息,例如哪个处理器拥有这些页面,以及这些页面是否与读保护或写保护映射。如果一个UM块包含了一个故障页面,我们之后就称这个UM块为故障UM块。
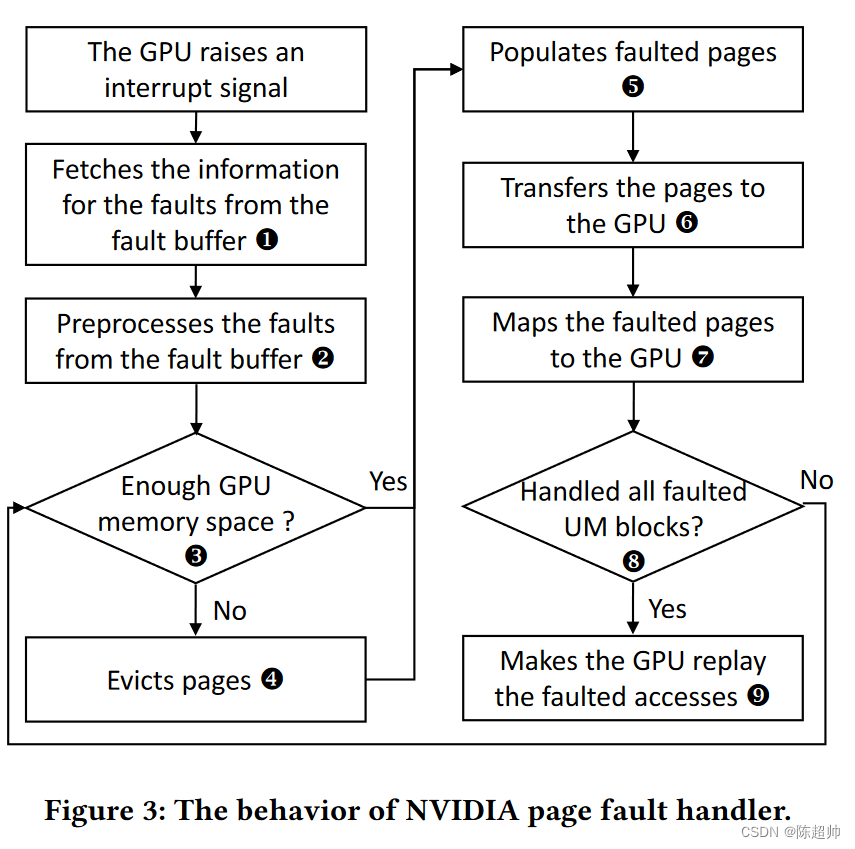
图3展示了页面故障处理的流程图。首先,NVIDIA驱动程序从GPU的故障缓冲区中获取发生故障的页面地址和访问类型(步骤1)。然后,NVIDIA驱动程序预处理这些故障(步骤2),它移除重复的地址并根据它们的UM块进行分组。接下来,NVIDIA驱动程序检查每个故障UM块的可用GPU内存空间(步骤3)。如果没有可用的GPU内存空间用于故障UM块,它会将一些页面从GPU驱逐到CPU(步骤4)。然后,它在GPU中填充故障页面(步骤5)(也就是为故障页面分配GPU内存空间),并将页面传输到GPU(步骤6)。当传输完成时,UM块的故障页面被映射到GPU(步骤7)。这个过程重复,直到所有的故障UM块都被处理(步骤8)。最后,NVIDIA驱动程序向GPU发送一个重播信号,故障处理器完成处理(步骤9)。
这里注意几个细节:
在处理页面故障时,NVIDIA的驱动程序首先需要对这些故障进行预处理。预处理的一部分包括移除重复的地址。这意味着,如果在故障缓冲区中存在多个条目引用了同一个虚拟地址(也就是同一个页面),驱动程序会将这些重复的条目合并为一个。这样可以避免对同一个页面进行重复的处理,从而提高处理效率。
另一部分预处理是将故障根据它们的UM块进行分组。也就是说,驱动程序会将属于同一个UM块的所有故障页面聚集在一起,然后作为一个整体进行处理。这是因为UM块是驱动程序管理内存的单位,将同一个UM块的页面一起处理可以提高内存操作的效率。
DeepUM的架构
PyTorch运行在DeepUM运行时之上。它由DeepUM运行时和DeepUM驱动程序组成。
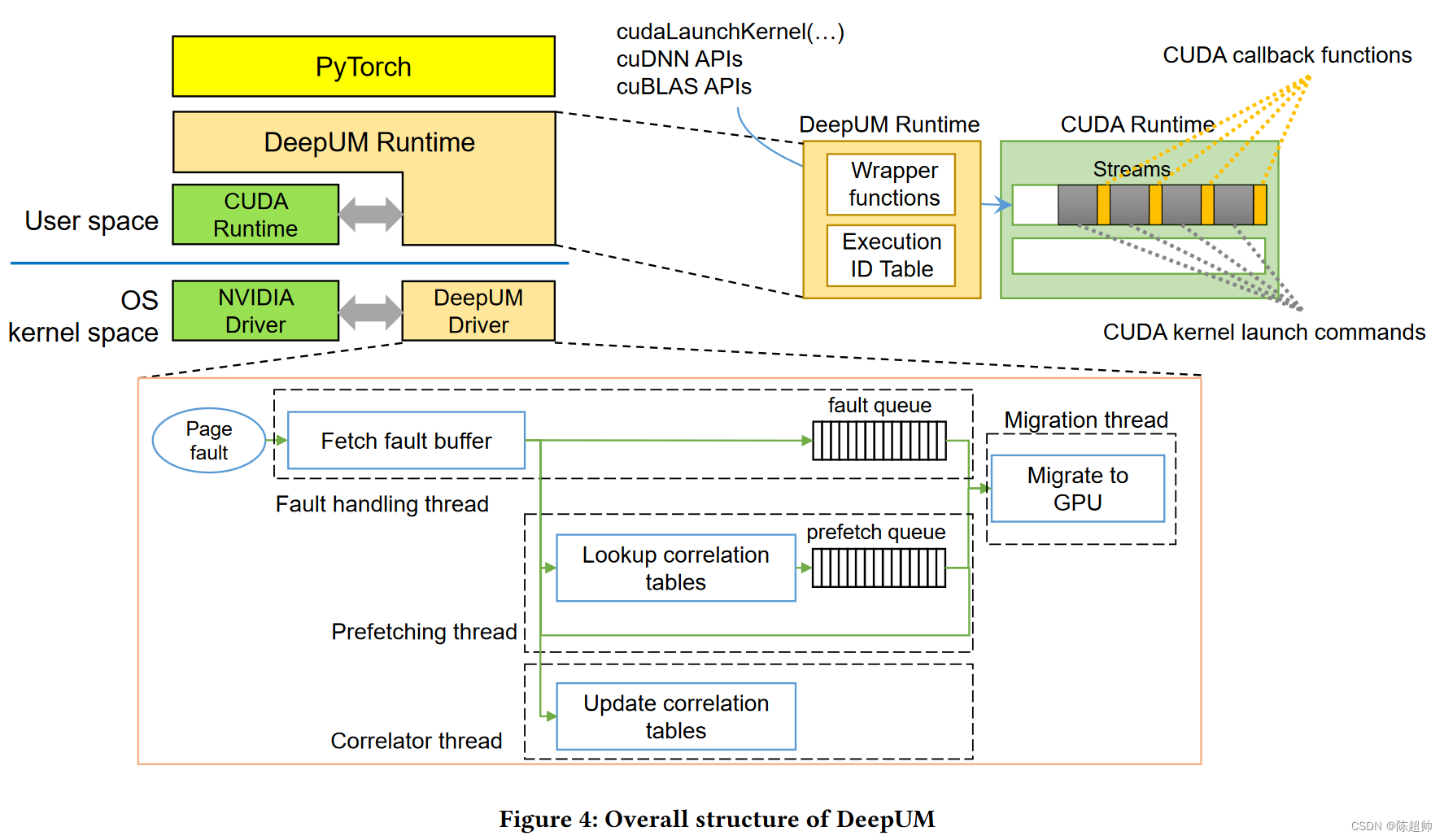
DeepUM运行时:
-
DeepUM运行时为CUDA内存分配API函数提供封装函数,以将所有GPU内存分配请求切换为统一内存(UM)空间分配请求。它通过在UM空间中分配所有GPU内存对象,轻松实现GPU内存超额订阅。此外,DeepUM运行时为CUDA内核启动命令和其他CUDA库函数(如cuDNN和cuBLAS中的函数)提供封装函数。注意,CUDA库函数也会启动CUDA内核。
-
DeepUM运行时管理一个叫做执行ID表的表格。该表格保存了内核启动历史,并包含每个内核名称和参数的哈希值。当一个新的内核启动命令来到DeepUM运行时,它计算内核名称和参数的哈希值。然后,它查找执行ID表以找到具有相同哈希值的命令。如果找到了匹配的命令,就将相同的执行ID赋予内核。否则,它为内核分配一个新的执行ID,并将信息保存在表格中。最后,DeepUM运行时在将内核启动命令入队之前,将一个CUDA回调函数入队到CUDA运行时。回调函数通过Linux ioctl命令将后续内核启动命令的执行ID传递给DeepUM驱动程序。DeepUM驱动程序使用传递的执行ID进行相关性预取。
DeepUM驱动程序。
-
DeepUM驱动程序处理GPU页面故障,并预取页面到GPU。我们观察到,在DNN的训练阶段,内核执行模式和内核内的内存访问模式是固定的并会重复。因此,记住重复的模式并利用这些信息进行预取是可取的。DeepUM驱动程序管理的相关表记录了DNN训练阶段的内核执行历史和它们在页面访问期间的情况。DeepUM驱动程序根据相关表中的信息预取页面,通过预测下一个执行的内核。稍后将描述DeepUM驱动程序使用的相关性预取机制。
-
DeepUM驱动程序中有四个内核线程:故障处理线程,关联器线程,预取线程和迁移线程。
- 故障处理线程使用NVIDIA驱动程序中实现的函数处理GPU页面故障,如访问故障缓冲区和向GPU发送重播信号。如上面所述,NVIDIA GPU有一个硬件故障缓冲区,用于累积故障访问的信息。DeepUM驱动程序拦截到NVIDIA驱动程序的页面故障中断信号,并且故障处理线程读取故障缓冲区。故障处理线程将故障访问的信息传递给其他三个线程。故障队列是一个单生产者/单消费者队列,存储故障页面的统一内存块地址。它持有驱动程序中需要处理的最高优先级的项目,以使GPU尽快重播故障访问。
- 关联器线程管理相关表。它根据故障处理线程的故障信息更新相关表。稍后将讨论相关表的结构以及关联器线程如何更新它们。
- 预取线程:预取线程查找相关表,并根据故障的块地址计算预取的统一内存块地址。然后,它将预取命令入队到预取队列,一个单生产者/单消费者队列。一个预取命令由预取的统一内存块地址和预测将用到对应统一内存块的执行ID组成。
- 迁移线程:最后,迁移线程在CPU和GPU之间迁移统一内存块。故障队列比预取队列具有更高的优先级。它首先处理故障处理线程管理的故障队列中的命令。当故障队列为空时,它处理预取线程管理的预取队列中的命令。
这个部分比较抽象,让我们来讲一个故事来帮助理解。
让我们想象一个叫做DeepUM的城市,这个城市特别适合深度神经网络(DNNs)居住。DeepUM城市的优势在于,它拥有一种特殊的“统一内存(UM)”空间,可以让DNN的居民们轻松地使用超过他们自身内存限制的数据,而不需要担忧空间不足的问题。
DeepUM城市由两个主要部分组成:DeepUM运行时和DeepUM驱动程序。你可以把它们想象成城市的管理部门和服务部门。
DeepUM运行时像一个城市规划部门,它负责将所有的内存请求都导向统一内存空间,就好像是在城市中规划土地使用一样。为了高效的管理土地,DeepUM运行时还维护了一个执行ID表,这个表记录了所有的建筑(也就是内核)的名称和参数的哈希值,类似于城市的土地使用历史记录。当有新的建筑请求出现时,DeepUM运行时会查看这个建筑是否已经在执行ID表中存在,如果存在,就给建筑分配相同的执行ID,如果不存在,就分配一个新的执行ID并记录下来。
DeepUM驱动程序可以看作是城市的服务部门,负责处理页面故障(类似于城市中的基础设施问题)并预取页面到GPU(类似于提前为城市建设做好准备)。DeepUM驱动程序注意到,在DNN的训练阶段,内核执行和内存访问的模式是固定并重复的,就像城市中的交通模式一样,所以它决定利用这些重复的模式进行预取。
在DeepUM驱动程序中,有四个专门的线程作为服务人员,包括故障处理线程、关联器线程、预取线程和迁移线程。
故障处理线程就像是城市的维修队伍,负责处理GPU页面故障,也就是处理城市中出现的基础设施问题。关联器线程管理着一个相关表,就像城市的历史记录,记录了DNN训练阶段的内核执行历史和他们在页面访问期间的情况,类似于记录城市的交通流量和使用情况。
预取线程的工作就像是城市的规划者,根据已知的历史记录(相关表)和当前的需求(故障的块地址),预先计算和安排需要的资源(预取的统一内存块地址)。
最后的迁移线程,可以想象成一个专门负责在CPU和GPU之间搬运统一内存块的运输工人,他们根据故障队列和预取队列中的命令,决定什么时候、怎么样迁移这些内存块。
相关预取 (Correlation Prefetching)
它基于原始的“相关预取”技术进行了修改。
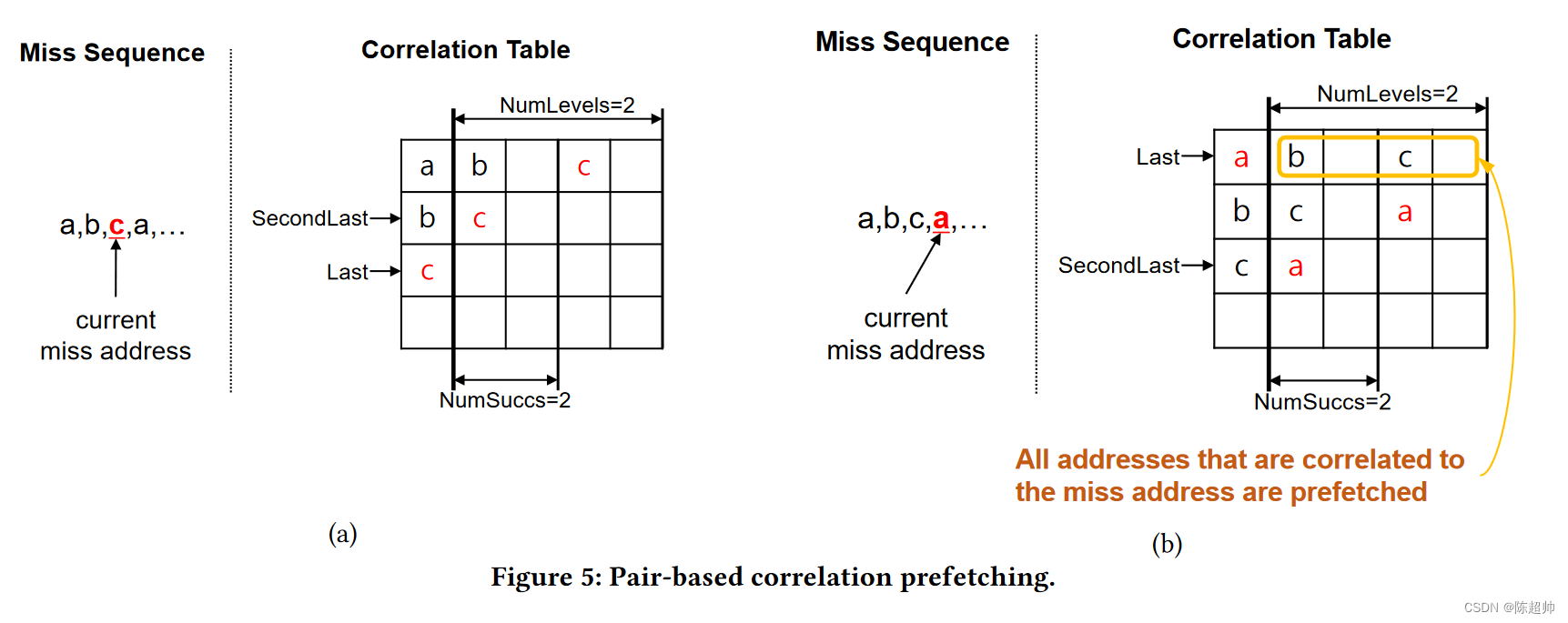
基于对的相关预取
基于对的相关预取通过在相关表中记录过去未命中地址的序列。当缓存未命中时,它将查找相关表,并预取所有与未命中地址相关的地址
相关表的每一行都有 𝑁 -way 关联性 (Assoc),以减少映射到同一行的 UM 块之间的地址冲突。每个集合都有 NumLevels 级的后继未命中地址。在每个级别中,NumSucc 条目从左到右按 MRU 排序。“Last” 和 “SecondLast” 是指向最后和倒数第二个未命中的条目的指针。
看下面的图,有点抽象。
- 左边的图,a和b都已经miss过了,然后此时是c miss。所以last指针指向了c,secondlast指针指向了b。此时的表里,c的后面是没有东西的(第三行);b的后面miss的是c(第二行);a的后面miss的是b和c(第一行),至于为啥第三列是空出来的,我猜可能是NumLevel=2,为了做一个区分,a的后面是b是加一个单位,b的后面是c是加两个单位。
- 右边的图,a再次miss,此时是在c后面miss的,那么就会更新这个表格。last指向了a,secondlast指向了c。读取缺失的a的时候,会一起读取同一行的所有,也就是b和c,这就是提前预取。而表也会随着更新,c的后面补充了a(第三行),b的后面是c和a(第二行)。
- MRU 排序:这是一种排序方式,MRU 是 Most Recently Used 的缩写,意思是最近最经常使用的地址会被放在最前面。
DeepUM 中的相关预取
DeepUM 中的相关预取旨在通过预取 CUDA 内核预期访问的页面来减少页面错误。与原始的相关预取不同,DeepUM 使用两种类型的相关表:执行 ID 和 UM 块。这两种类型的表都有单级 (𝑁𝑢𝑚𝐿𝑒𝑣𝑒𝑙𝑠 = 1),因为预取线程执行链式操作。此外,由于 DNN 工作负载的特性,没有必要维护多个级别。
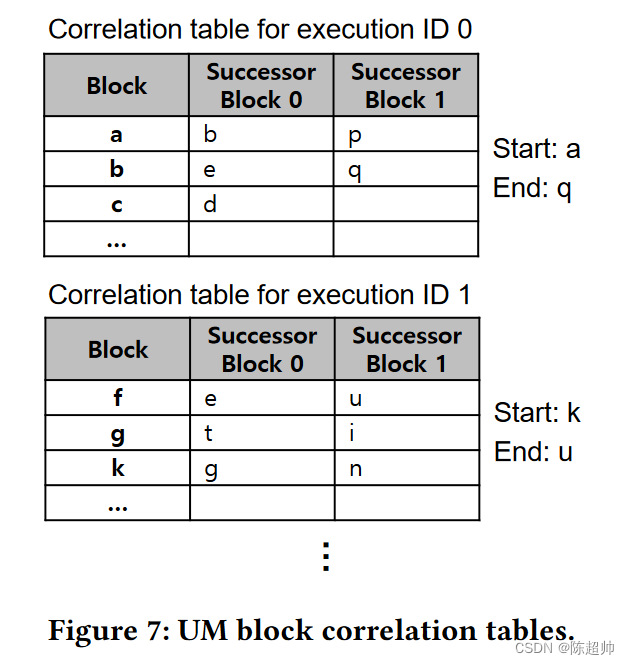
- 执行 ID 相关表(简称执行表):
- 记录了 CUDA 核心的执行 ID 的执行历史,整个系统中只存在一个这样的表。执行 ID 来自 DeepUM 运行时。图 6 显示了一个执行表的示例。执行表的每个条目都保存了一组相关的执行 ID。
- 每组由四个执行 ID 组成。前三个 ID 代表最后一个核心(更新表时正在执行的核心)之前刚刚执行的核心。因此,最后一个 ID 表示预取发生时接下来要执行的核心。
- 例如,执行 ID 为 0 的条目有一个记录(7,9,92,75)。这个记录意味着已经执行了执行 ID 为 7,9,和 92 的核心,执行 ID 为 0 的核心当前正在执行。它预测接下来要执行的核心的执行 ID 为 75。
- 这个执行表的作用就像是一本历史记录册,它记录了每个核心执行的顺序,这样在预取时就可以根据这个顺序来预测下一个可能会执行的核心,从而提前预取相应的页面,提高性能。
- 每个条目包含的记录数是可变的,也就是说,一个核心的后继核心的数量是可变的。因此,每个条目可以持有所有后继核心执行 ID 的历史。DeepUM 选择这种方案是为了尽可能准确地预测下一个要执行的核心。即使预测下一个要访问的 UM 块的结果不准确,成本也不高,但预测下一个要执行的核心的结果不准确,成本就很高。

UM 块相关表(简称块表)记录的是 UM 块级别的历史,而不是记录错误页面地址的历史。选择这种粒度的原因有两个。
- 一个是大规模 DNN 有太多的页面地址需要管理。
- 另一个是让 DeepUM 与 NVIDIA 驱动程序具有相同的页面管理粒度更有效。
图 7 显示了一个块表的示例。每个执行 ID 都有一个块表,记录了相应 CUDA 核心内的 UM 块访问历史。它类似于原始相关预取中使用的表。然而,一个块表包含了指向最后一个被预取的 UM 块的结束 UM 块的地址,以及指向在相应核心执行中首次出错的 UM 块的开始 UM 块的地址。这两个指针被用来实现链式操作。在当前执行的核心转换过程中,开始 UM 块和结束 UM 块都会被捕获。结束 UM 块是页面所在的 UM 块,该页面在执行 ID 转换之前最后出错。开始 UM 块是第一个出错的页面所在的 UM 块,这个错误发生在执行 ID 转换之后。
"核心执行 ID 转换"指的是 CUDA 核心从执行一个任务(或者说,一个核心)切换到执行另一个任务的过程。每个任务都有一个唯一的执行 ID 来标识它,当核心从一个任务切换到另一个任务时,我们就说发生了“核心执行 ID 转换”。
让我们用一个简单的例子来理解这两个指针“开始 UM 块”和“结束 UM 块”。
- 假设我们有一组连续的 UM 块,他们的标签分别是 A, B, C, D, E, F。现在,假设我们的 CUDA 核心在这些 UM 块上进行操作。
首先,当核心开始执行时,它首先访问 UM 块 A,这就导致了一个页面错误。在这个情况下,A 就是“开始 UM块”,因为它是当前执行的核心首次出错的 UM 块。- 然后,核心继续执行,依次访问了 UM 块 B, C, D, E。当核心访问 UM 块 E 时,又发生了一个页面错误。在这个情况下,E 就是“结束 UM 块”,因为它是在核心执行 ID 转换之前最后出错的 UM 块。
- 现在,假设核心完成了当前的执行,开始了新的执行。第一个访问的 UM 块是 F,这导致了一个页面错误。在这个情况下,F 就成了新的“开始 UM块”。
- 所以,“开始 UM 块”和“结束 UM 块”就像是一个范围的指标,标记了在一个核心执行过程中,首次和最后一次出错的 UM 块。这两个指针有助于我们理解和记录核心在执行过程中访问数据的模式,从而更精确地预测下一个可能会访问的 UM 块,提高性能。
"开始 UM 块"和"结束 UM 块"这两个指针主要用于实现链式操作,也就是链接在一起的 UM 块的访问序列。
让我们来理解这两个指针对链式操作的帮助:
- 当一个新的核心开始执行时,“开始 UM 块"是第一个发生页面错误的 UM 块,然后核心会按照一定的顺序访问其他 UM块。这个顺序可以由"开始 UM 块"开始,通过链式操作一直找到"结束 UM 块”。这个过程就像是在一个链条上从一端到另一端的过程。
- 这种链式操作的好处在于,它可以帮助我们更好地理解和预测核心访问 UM 块的模式。例如,如果我们知道在过去的一次核心执行中,核心从"开始 UM块" A 访问到"结束 UM 块" B,那么在下一次核心执行时,如果核心又访问了 A,我们就可以预测它接下来可能会访问到B。这样,我们就可以提前预取 B,以提高性能。
- 总的来说,"开始 UM 块"和"结束 UM 块"这两个指针是实现链式操作的关键,它们帮助我们记录和预测核心访问 UM块的模式,从而优化性能。
预取机制和链式操作
当页面错误发生时,DeepUM 驱动程序会通过查找当前执行内核的 UM 块相关表,预取所有在与错误 UM 块相关的 UM 块中的页面。当 DeepUM 的预取线程遇到与 UM 块相关表中的结束块相同的 UM 块时,它会结束对内核的预取,并通过查找执行 ID 表来预测下一个将要执行的内核。然后,它开始从预测内核的 UM 块相关表中的开始 UM 块预取。这个过程被称为链式操作。
设想图 7 中的块表,假设 DeepUM 正在为执行 ID 为 0 的内核预取 UM 块 b。同时假设执行 ID 为 1 的内核将紧接着执行 ID 为 0 的内核执行。
-
首先,DeepUM 驱动程序正在为执行 ID 为 0 的内核预取 UM 块 b,这是因为它发生了页面错误。然后,预取线程会查找块 b 的后继 UM 块,这些后继 UM 块是 e 和 q。它会按照一定的顺序(可能是根据某种优先级或者策略)预取这些后继 UM 块。
-
当预取线程预取到 UM 块 q 时,它发现 q 是执行 ID 为 0 的内核的结束 UM 块(也就是在这个内核执行过程中最后一次出错的 UM 块)。这时,预取线程知道它已经预取了当前内核需要的所有 UM 块,所以它停止为执行 ID 为 0 的内核预取。
-
接下来,预取线程开始为下一个预计将要执行的内核预取 UM 块。在这个例子中,下一个内核的执行 ID 是 1。预取线程会查找执行 ID 为 1 的内核的 UM 块相关表,找到开始 UM 块(也就是在这个内核执行过程中首次出错的 UM 块),在这个例子中,开始 UM 块是 k。然后,预取线程就开始从 k 开始,为执行 ID 为 1 的内核预取 UM 块。
-
这个过程就像是一个链条,从一个 UM 块链接到下一个 UM 块,然后再链接到下一个 UM 块,这就是所谓的链式操作。当新的页面错误发生,或者预取线程无法预测下一个将要执行的内核时,链式操作就会结束。
这里讲一个故事来帮助理解吧!
假设你有一个大型超市,每个人都有他们的购物清单。超市中的商品代表这个"页面",而购物清单代表"程序",每个人(程序)需要在超市(内存)中找到他们需要的商品(页面)。
我们的目标是让每个人都能在最短的时间内完成购物。一种方法是提供一个"预取"服务,也就是超市工作人员会根据你的购物清单,提前为你准备好商品。
基于对的相关预取
在这个例子中,"基于对的相关预取"就像是一个记录你过去购物行为的超市工作人员。他们会观察你的购物习惯,例如,你可能会在买牛奶之后去买麦片,或者在买面包之后去买果酱。他们会把这些信息记录下来,然后下次你再来购物的时候,他们会根据你的购物习惯,提前为你准备好商品。
DeepUM 中的相关预取
在这个例子中,"DeepUM 中的相关预取"就像是一个更专业的超市工作人员,他们不仅记录你的购物习惯,还会记录所有人的购物习惯,并且他们还会根据购物清单(程序)的执行顺序来预测下一个需要的商品(页面)。例如,如果他们知道大多数人在买牛奶之后都会买麦片,那么他们就会在你买牛奶的时候,就已经把麦片准备好了。
预取机制和链式操作
在这个例子中,“预取机制和链式操作”就像是一个接力赛。超市的工作人员(预取线程)根据购物清单(程序)的执行顺序,一个接一个地预取商品(页面)。当一个工作人员完成他的任务(预取一个商品)后,他就会把接力棒传给下一个工作人员(开始预取下一个商品)。这就是所谓的链式操作。
这样,当你需要一个商品的时候,很可能这个商品已经被提前准备好了,你就不需要在超市里面找这个商品,从而节省了时间。
GPU 页面错误处理
页面驱逐(Page eviction)发生在驱动程序无法为迁移出错页面分配 GPU 内存空间时。图 8 显示了页面驱逐发生的情况。当没有可用的 GPU 内存空间来处理出错的页面时,就会发生页面驱逐。页面驱逐需要大量的时间,这意味着页面驱逐逻辑是处理页面错误的关键路径上的一部分。因此,当 GPU 上没有更多的空间时,错误处理时间会增加。
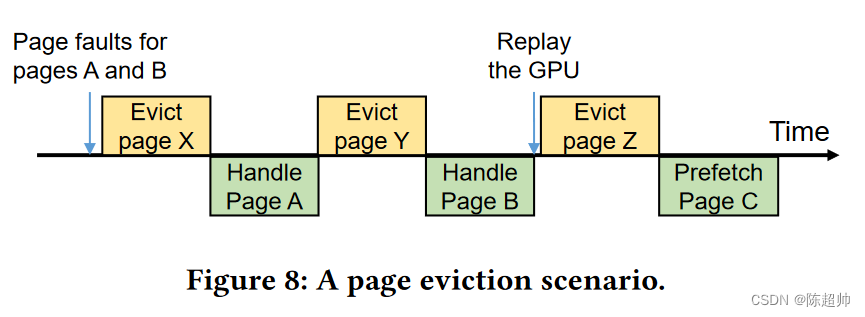
页面预驱逐(Page Pre-eviction)
为了最小化错误处理时间,当没有剩余的 GPU 内存空间时,DeepUM 驱动程序会预先驱逐页面。
Kim 等人[32]使用的策略与 NVIDIA 驱动程序中实现的策略相同。它会驱逐最近最少迁移到 GPU 的页面。这是前人的工作,我放一下论文题目,以后有可能会刷到。
Batch-Aware Unified Memory Management in GPUs for Irregular Workloads. 2020.
DeepUM 驱动程序会驱逐满足以下两个条件的页面:
- 最近最少迁移。
- 不预期被当前正在执行的内核和预测执行的下一个 𝑁 个内核访问。
由于 NVIDIA 驱动程序会跟踪 GPU 侧的空闲空间,因此 DeepUM 从 NVIDIA 驱动程序那里获取可用空间信息。它从执行 ID 关联表中获取下一个执行内核的信息。
使非活动的 PyTorch 块的 UM 块无效
先看看Pytorch的实现
PyTorch 对 CPU 和 GPU 有不同的内存分配器。PyTorch 的 GPU 内存分配器管理设备内存池,以最小化内存分配/释放时间并减少内存碎片。GPU 内存分配器管理二种类型的内存池:大型和小型。
在 PyTorch 中,一个内存对象被称为块(block)。在这篇论文中,我们称它为 PT 块,以便与 UM 块区分。大型池由大于 1MB 的 PT 块组成,小型池由小于或等于 1MB 的 PT 块组成。
当一个内存分配请求进来,且请求的大小大于 1MB,内存分配器从大型池中找到一个 PT 块。否则,它从小型池中找到一个 PT 块。
当池中的多个 PT 块与请求的大小匹配时,分配器返回最小的可用 PT 块。此外,当 PT 块的大小远大于请求的大小时,PT 块会被分割。
选择上GPU运行的 PT 块从内存池中移除,并标记为活动。然而,当内存池中没有可用的 PT 块时,GPU 内存分配器通过向 CUDA 运行时请求设备内存空间来分配新的 PT 块。
在 DNN 模型使用 PT 块并将其返回给 GPU 内存分配器后,分配器将 PT 块插入到适当的内存池并标记为非活动。只有当池中没有剩余的可用内存空间时,非活动的 PT 块(即内存池中的 PT 块)才会被释放以产生新的内存空间。
Pytorch实现的问题
问题是当我们使用 PyTorch 内存分配器和 UM 时。当 GPU 内存中的非活动 PT 块被驱逐到 CPU 内存时,会有不必要的大量数据流量。此外,它们占用了 CPU 内存空间。当非活动的 PT 块被标记为活动并再次被 DNN 模型使用时,问题会变得更糟。因为 PT 块中的页面已经被驱逐到 CPU 内存,所以
本文的解决方法
为了解决这个问题,我们在 PyTorch 内存分配器中添加了几行代码,当 PT 块被标记为非活动时通知 DeepUM 驱动程序。如果一个受害页面属于非活动的 PT 块,DeepUM 驱动程序简单地使 GPU 内存中对应的 UM 块无效。
这篇文章的技术部分就写到这里,感谢观看!















 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









