







【阅读笔记】Zero-Shot Human-Object Interaction Recognition via Affordance Graphs
目录
论文链接:https://arxiv.org/abs/2009.01039
Abstract
本文提出零样本人物交互(Zero-Shot Human- Object Interaction Recognition)新方法,涉及与未知动作的交互(而不是已知的动作和物体组成的新组合)。本文方法以图的形式利用图像中外部知识模拟动作和物体之间的可供性关系,即物体是否能够执行动作。本文提出一个损失函数,旨在将图中包含的知识提取到模型中,同时,还通过在潜在空间上施加局部结构来正则化学习表征。最后在一些数据集(包括流行的HICO和HICO-DET)上评估模型,结果表示,本文模型优于当前最先进的技术。
Introduction
人物交互(HOI)识别是从场景的视觉外观来识别人们如何与周围物体交互的任务,对理解图像内容至关重要。它为输入图像生成一系列三元组<人,动作,目标>,并且提供一个简单的图像语义表示用于图像字幕或者人机交互等更高级的任务。
处理视觉关系时最困难的问题之一就是三元组数量在人、动作和目标空间的基数上倍数增加,即使我们不在大量“人”这个类别上进行区分,比如“大人”、“小孩”等,可能的交互,即<动作,目标>对,该数量依然以平方的形式增加。由于在构数据集的实际挑战中,通常只对可能交互的一个子集进行注释,而大量的数据仍未被标记,例如,HICO中9360对中只有600个交互(8760个未标记的交互,一些是无效的,如<eating,bottle>,一些是有效但缺失的,如<carrying,knife>)。这也就是为什么越来越多研究中聚焦于人物交互识别中零样本(ZSL)的原因。ZSL旨在缓解通过模型预测先前未知交互时可能交互对的数量组合增长所造成的问题。
Method
Model
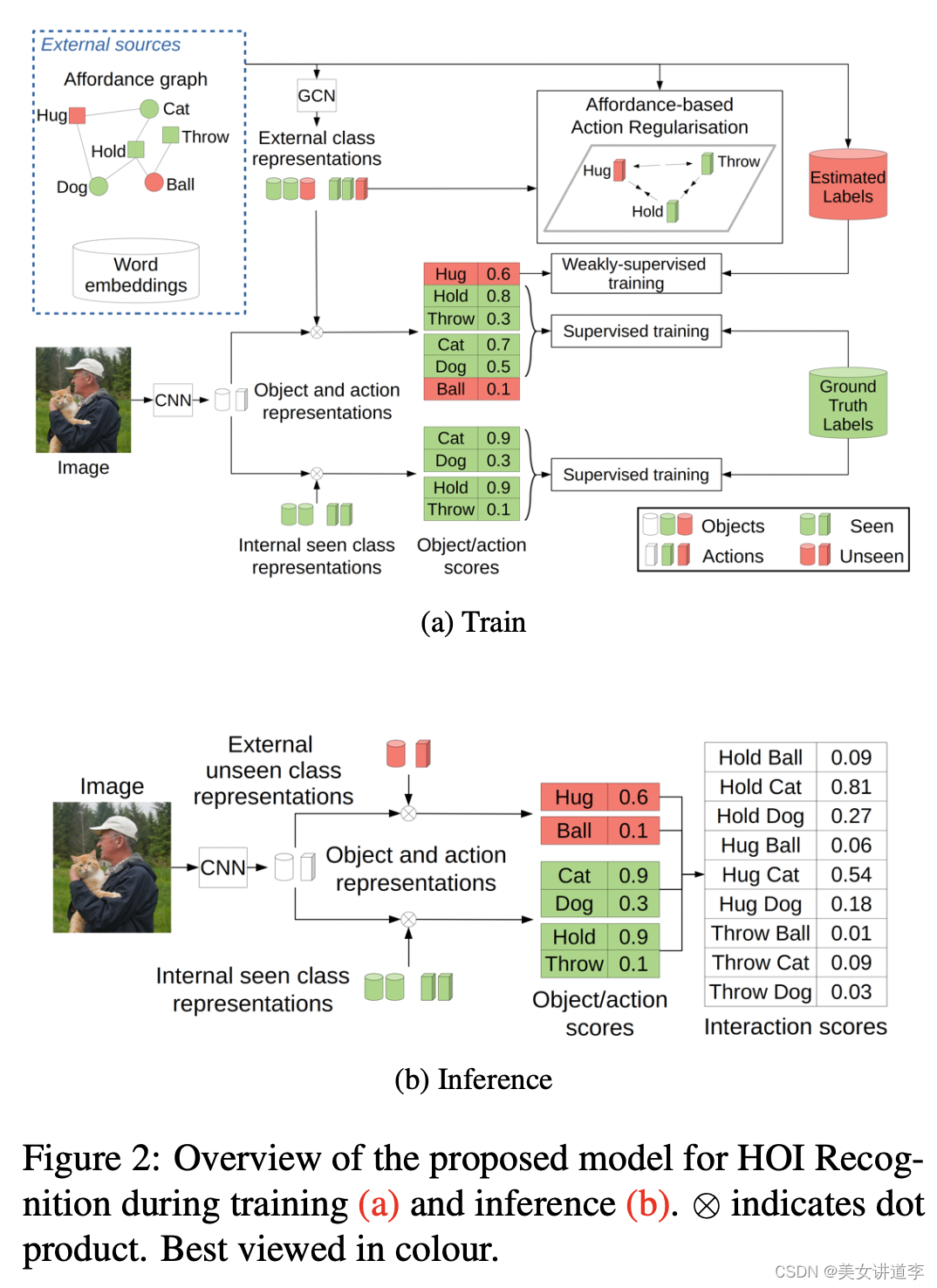
(1)输入图像I;
(2)CNN(如ResNet)提取特征,生成图像灰度级视觉特征, v = f C N N ( I ) v=f_{CNN}(I) v=fCNN(I);
(3)两个相同的结构化模块计算相似度分数,由变量q索引,一个用于物体(q=0),一个用于动作(q=A),每个模块通过非线性映射 f 1 q f_1^q f1q(如MLP)计算一个d维表征 x q = f 1 q ( v ) x^q=f_1^q(v) xq=f1q(v),使用相似函数 g ( x q , z i q ) g(x^q,z_i^q) g(xq,ziq)比较向量 x q x^q xq与d维类表征 Z q = [ z 1 q ∣ . . . ∣ z ∣ S q ⋃ U q ∣ q ] Z^q=[z_1^q|...|z_{|S^q\bigcup U^q|}^q] Zq=[z1q∣...∣z∣Sq⋃Uq∣q], g ( x , z ) = x T z g(x,z)=x^Tz g(x,z)=xTz;
(4)通过sigmoid函数 σ ( x ) = 1 / ( 1 + e − x ) \sigma(x)=1/(1+e^{-x}) σ(x)=1/(1+e−x)计算概率 y q = σ ( Z q x ) y^q=\sigma(Z^qx) yq=σ(Zqx)
inference时使用的是:
通过GCN使用已知类的表示以半监督方式学习未知类的表示external representation;
采用全监督的方式为已知类训练另一组表示internal representation;
计算:将物体和动作分数相乘,给每个交互赋值,生成一个矩阵 Y ∈ [ 0 , 1 ] ∣ O ∣ × ∣ A ∣ Y\in[0,1]^{|O|\times |A|} Y∈[0,1]∣O∣×∣A∣, y j k y_{jk} yjk表示< a k a_k ak
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3700
3700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









