






简介
论文题目:Enhancing LSM-tree Key-Value Stores for Read-Modify-Writes via Key-Delta Separation
会议:2024 ICDE
总体思想:通过桶设计来实现对key-delta(键-增量)的一些增量合并操作
阅读该论文一些翻译笔记和思考(一般使用高亮标记)
Abstract
Read-modify-writes(RMWs)
读取-修改-写入
为了提高 RMWs的效率,一种方法是将增量(即对当前值的更改)写入日志结构化合并树 (LSM-tree),但这会增加检索和组合增量链所导致的读取开销。
本文提出了一种称为键-增量 (KD) 分离的新概念,以支持在 RMW 密集型工作负载下在 LSM-tree KV 存储中进行高效读取和 RMW。
KD 分离旨在将增量存储在单独的存储区域中,并将增量分组到称为存储桶的存储单元中,这样键的所有增量都保存在同一个存储桶中,并且可以在后续读取中一起访问。
为此,我们构建了 KDSep,这是一个实现 KD 分离的中间件层,并将 KDSep 集成到最先进的 LSM-tree KV 存储(例如 RocksDB 和 BlobDB)中。我们表明,KDSep 在 RMW 密集型工作负载下实现了显著的 I/O 吞吐量提升和读取延迟减少,同时保持了一般工作负载的效率。
1. Introduction
键值 (KV) 存储是实现大规模结构化存储的关键范例,它将数据组织为用于读取(即从存储中检索现有键值对)和写入(即,将键值对插入存储或用新值覆盖现有键值对)的键值对。
RMW:reads from storage,fully or partially modified based on the curretn values, and written back to storage
RMWs在诸多数据库应用场景中占比很大
RMSWs 也常见于NoSQL 存储,实时数据处理和社会图数据库中
RocksDB 在Facebook后端使用,使用LSM-Tree结构,
LSM-tree 在多个树层上以日志结构存储方式排列 KV 对,并对新的 KV 对发出顺序写入,以实现快速写入。它还在每层树内以排序方式维护 KV 对,以实现高效的读取和范围查询。
为了支持高效RMWs,RocksDB支持merge(),相对于简单的读和修改KV对,==merge() 无需读取即可写入 KV 对的增量(即值的变化),==从而实现快速 RMW。因此,LSM-tree 可以说是 RMW 密集型工作负载的良好候选者。
但是merge()操作会增加增量 key子集后续读取的负载开销
对于快速 RMW,merge() 只会将增量写入 LSM 树,而不会将增量与其关联的 KV 对合并。因此,读取 KV 对不仅会检索当前值,还会检索增量链,以便重建值的最新版本,并且此类增量可能跨越树级别。
为了解决读负载问题
-
一种解决方式是KV分离,即将值存储在 LSM 树外部的单独存储中,以减少 LSM 树的大小并减少读取延迟。
一种现实的实现是BlobDB,仍然将增量存储在 LSM 树中。这种方式虽然在RMW密集型工作负载下,KV分离在一定程度上降低了读取延迟,但是读取延迟仍然很高。
本文提出了key-delta 分离:
KD 分离的灵感来自 KV 分离,并更进一步将增量存储在 LSM 树之外的单独存储中。它基于三个设计元素:
-
bucket-based delta placement
基于存储桶的增量放置,按存储桶对增量进行分组,这样,一个键的所有增量都映射到同一个存储桶(自己的论文是离散时间桶存储),并且任何对键的后续读取都可以通过直接访问其所有对应增量的单个存储桶来高效完成;
-
delta-based garbage collection
基于增量的垃圾收集,从存储桶中回收陈旧增量的空间,并进一步允许动态拆分和合并存储桶,以保持存储桶大小和存储桶数量易于管理;(然后使用桶的编码存放到LSM-Tree中)
-
crash recovery
崩溃恢复,确保在崩溃后可以恢复写入和垃圾收集的状态
为了实现KD分离,设计并实现了KDSep:
将 KD 分离集成到现有 LSM 树 KV 存储中的中间件层,以有效处理 RMW 密集型工作负载。
我们证明了 KDSep 可以切实地集成到现有的带或不带键值分离的 LSM-tree 键值存储中,包括 RocksDB、BlobDB 和 vLogDB([8] 中的键值分离实现)。我们还对 KDSep 的性能进行了渐近分析。
我们使用可调参数合成生成的自定义工作负载、基于 Facebook RocksDB 部署 [7] 的生产工作负载和 YCSB 核心工作负载 [12] 来评估 KDSep。
实验结果表明,在 RMW 密集型工作负载下,与没有 KD 分离的基线 KV 存储相比,我们的 KDSep 原型将 I/O 吞吐量提高了 67.0-80.5%,并将读取延迟降低了 41.9-49.9%。我们的 KDSep 原型已在 https://github.com/adslabcuhk/kdsep 开源
2. 背景和动机
2.1 LSM-Tree 基础理论
LSM Tree 组织

总共有n+1层,代表L0到Ln
每个级别将键值对存储在不可变的固定大小文件中(类似于HDFS的块设定),每个文件有几个 MiB,在持久化存储中被称为SSTables。
每个 SSTable 将 KV 对分组到几个 KiB 大小的数据块中,并保留一个索引块,用于存储 SSTable 中所有数据块的键范围和偏移量(存于SSTable 内部)。
为了实现高效的范围查询,每个 SSTable 按键对所有 KV 对进行排序,并且同一级别(L0 除外)的所有 SSTable 都具有不相交的键范围。此外,Li(2 ≤ i ≤ n)的总大小通常是其较低级别 Li−1 的数倍(例如,RocksDB [16] 中的 10 倍)
Writes
put(key, value) 操作符将一个键值对写入 LSM 树。它首先将键值对附加到预写日志 (WAL) 中,用于崩溃恢复。
然后将键值对写入内存中的可变结构,称为 MemTable。当 MemTable 已满时,它将转换为不可变的 MemTable,该 MemTable 将被刷新并成为磁盘上 L0 中的 SSTable;刷新的键值对也将从 WAL 中删除。SSTables 中的键值对通过压缩迁移到更高级别,步骤如下:
- 在 Li (0 ≤ i ≤ n − 1) 中选择 SSTable,并在 Li+1 中选择具有重叠键范围的多个 SSTable
- 合并排序所有键值对并丢弃任何无效(陈旧)的键值对,以及
- 将活动(非陈旧)键值对作为新 SSTable 写入 Li+1。压缩后,每个级别(L0 除外)的所有键值对都保持排序,因此可以通过二分搜索来查询 Li(i ≥ 1)中的键。请注意,压缩会导致写入放大,因为它会将有效的键值对重写到新的 SSTable 中。
Reads
get(key) 操作符读取给定键的 KV 对并返回其值。它首先搜索当前写入的 MemTable 和内存中的不可变 MemTable,然后从 LSM 树的低级到高级搜索磁盘上的 SSTable。因此**,它会导致读取放大,**因为它经常向不同级别的 SSTable 发出多个随机读取。为了加速读取,每个 SSTable 中的索引块都维护一个布隆过滤器 [6] 来快速检查键是否存在。此外,经常访问的索引块和数据块会缓存在内存中的块缓存中。
2.2 Read-Modify-Writes (RMWs)
读取-修改-写入 (RMWs,好像其实就是更新操作 = = ) 逻辑上将 KV 对从 LSM-tree 读取到内存,修改内存中的值,并将修改后的 KV 对写回 LSM-tree。我们讨论了两种 RMW 方法,即 Get-Put 和 Merge。
Get-Put。RMW 可以通过一对 get() 和 put() 实现,通过 get() 读取原始值,修改值,然后通过 put() 写入新值。Get-Put 方法用于 YCSB 基准测试 [12] 和现代 LSM-tree KV 存储。
例如,YCSB 核心工作负载 A、B 和 F 中的更新通过 get() 读取具有多个字段的数据库记录、修改一个或多个字段并通过 put() 写回更新的数据库记录来实现 RMW。
另一个例子是统计计数器的更新(例如,在 Facebook [7] 的社交网络中用于监控用户活动的机器学习推理),它通过 get() 读取计数器值、增加或减少计数器值以及通过 put() 写回新的计数器值来实现 RMWs。
Get-Put 方法的一个缺点是其性能受到 get() 的瓶颈,这会导致读取放大(第 II-A 节)
Merge
为了缓解get方法在Get-Put方法的负载RocksDB引入了merge(key, delta)算子,
它通过写入增量(delta)来执行 RMW,==增量定义为原始值和新值之间的差异。==参考上面的例子,要修改数据库记录中的字段,增量表示记录中字段的偏移量和字段的新内容;要更新统计计数器,增量是从原始值到新值的数值差异。
+/- 操作
假设客户端调用merge()对某个键发出RMWs。merge()操作符首先将键和增量组合成一个键-增量(KD)对,然后将KD对写入WAL和MemTable。MemTable在已满时会作为SSTable刷新到磁盘,就像LSM树KV存储的原始写入工作流程一样;请注意,**每个MemTables和SSTable现在都包含KV对和KD对的混合。**因此,merge()消除了Get-Put方法中的get()并提高了RMW性能。
RocksDB 在merge()操作符下提供了两个可实现的接口:(i)fullMerge(value, deltaList[]),指定如何将deltaList[]中的delta列表与输入的原始值合并为一个新值;(ii)partialMerge(delta1, delta2),将两个delta(即delta1和delta2)合并为一个delta,以减少SSTables中的delta数量。这两个接口在RocksDB的压缩过程中都会被调用:如果KD对遇到了相同key的KV对,则可以通过fullMerge()将KD对的delta与KV对合并;如果KD对遇到了相同key的另一个KD对,则可以通过partialMerge()将两个KD对合并为一个。
Merge 下的 get() 操作符与原始读取路径不同,**因为它需要搜索并合并给定键的所有增量以重建返回值。具体来说,它会从低到高搜索所有 MemTable 和 SSTable,并将给定键的所有增量存储在内存中。当找到给定键的最新 KV 对时,**它会停止搜索。然后,它应用内存中的所有增量通过 fullMerge() 重建最新值并返回新值。因此,虽然 merge() 使 RMW 更高效,但它会给读取带来额外的开销(因为需要从头检索数据,尤其是当使用 RMW 频繁更新 KV 对并且对 KV 对的读取需要聚合大量增量链时。
2.3 Motivating Experiments
比较Get-Put方法和Merge方法。我们比较了 Get-Put 和 Merge 的读取和 RMW 性能,以了解它们的性能权衡
我们首先在测试平台中将 100 M 个 1-KiB 键值对加载到 RocksDB(第 IV-A 节),
其中每个键值对都有一个 24 字节的键和一个 1,000 字节的值。每个值包含 10 个 100 字节的字段(YCSB [12] 的默认设置)。
然后,我们发出 50 M 个操作的工作负载,这些操作混合了读取和 RMW,遵循 Zipf 分布,Zipfian 常数为 0.99,并启用直接 I/O。RMW 在 Get-Put 和 Merge 中随机选择并修改键值对中的一个 100 字节值字段。
图 2 显示了 Get-Put 和 Merge 的平均读取和 RMW 延迟,其中我们将读取与 RMW 的比例从 10:90 变为 90:10。我们观察到 Merge 和 Get-Put 之间的性能权衡。对于 Merge,它显著降低了 Get-Put 的 RMW 延迟 95.7-96.9%(从 139.8-156.1 µs 到 4.8-6.0 µs)(图 2(a)),因为当一个键存在多个 RMW 时,Get-Put 会发出许多对 get() 和 put(),而 Merge 直接将 KD 对存储在 LSMtree 中并避免多次调用 get()。然而,Merge 也使 Get-Put 的读取延迟增加了 50.8-74.1%(图 2(b)),因为 Merge 需要搜索键的值和所有增量,而 Get-Put 直接读取最新的键值对。具体来说,对于较小的读取与 RMW 比率(例如 10:90),其读取延迟更高,因为它向 LSM 树注入了更多增量并增加了读取开销。对于 Get-Put,其 RMW 和读取延迟几乎相同,因为它们都由 get() 主导,而 RMW 中的 put() 产生的开销可以忽略不计。

所以提出了一个新的思想:
2.3.1 Can KV separation mitigate the RMW overhead?
KV 分离由 WiscKey [20] 首次提出,通过分离键和值的存储来减少写入和读取放大。其理念是索引不需要值。因此,它将键和元数据存储在 LSM 树中以供索引,**同时将键和值存储在名为 vLog 的仅追加循环日志中(vLog 中的键用于高效的值查找 [20])(遥感影像的图片怎么存储呢?本地读取分布式切分直接入库!)。**它显著减少了 LSMtree 的大小,因此它减轻了压缩和查找成本,从而分别减轻了写入和读取放大。
直观地看,键值分离预计也能减轻 Get-Put 和 Merge 的开销。我们在 BlobDB [14] 上评估了 Get-Put 和 Merge,它在 RocksDB 中实现了键值分离,并将键和值存储在专用文件(称为 Blob 文件)中。请注意,对于 Merge 中的键值对,BlobDB 仍将它们(除了键和元数据)保留在 LSM 树中。我们关注 50:50 的读取与 RMW 比率,并评估 Get-Put 和 Merge 的平均读取和 RMW 延迟
图3展示了有无KV分离情况下的RMW和reads的平均延迟。(这里应该是会比较Get-Put方法和Merge方法)KV分离(即BlobDB)相比无KV分离(即RocksDB)降低了Get-Put和Merge中的RMW和读延迟。对于Get-Put,与无KV分离(即Get-Put+RocksDB)相比,KV分离(即Get-Put+BlobDB)分别将RMW和读延迟降低了46.5%和48.0%,但RMW延迟仍然很高。对于Merge,KV分离(即Merge+BlobDB)和无KV分离(即Merge+RocksDB)的RMW延迟都很低。但是Merge的读延迟仍然很高;例如,Merge+BlobDB的读延迟比Get-Put+BlobDB高116.6%。

可以看出读写分离对Merge方法来说影响最大
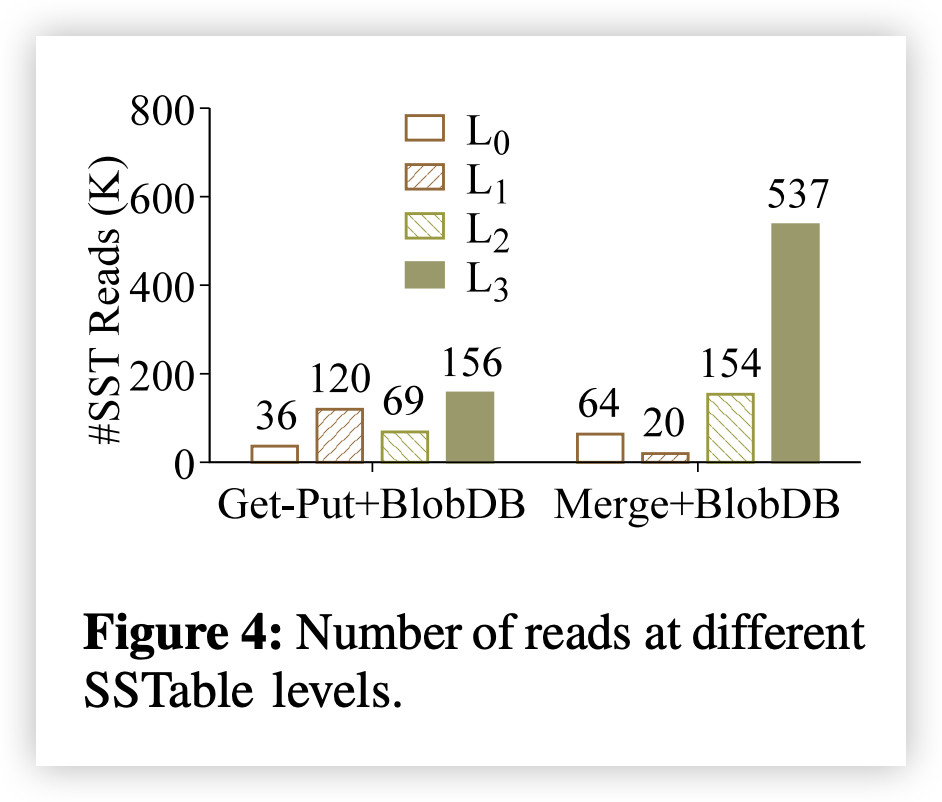
为了进一步研究 Merge 的读取惩罚 (read penalty),我们分析了在 KV 分离下 Get-Put 和 Merge 向不同 LSM-tree 级别发出的随机读取数量。图 4 显示了结果。我们做了两个观察。首先,Get-Put 中的几乎大多数 KV 对出现在低级别(例如,L0 和 L1 中总共 156.2 K 读取),
而 Merge 中的 KD 对可能出现在不同级别,尤其是高级别(例如,L2 和 L3 中分别有 153.7 K 和 536.7 K 读取)。其次,Merge 的读取次数比 Get-Put 多得多(773.7 K 对 381.1 K 读取),因为 LSM-tree 还存储了大量的 KD 对。我们还发现,在工作负载结束时,Merge+BlobDB 中的 KD 对占据了总 SSTable 大小的 23.2%(图中未显示)。(前情提要,SSTable此时不仅存放KD对,还存放KV对)
3. KDSep Design
本文提出了key-增量分离,将KD对的存储从LSM-Tree中分离出来。为了进一步降低LSM-Tree的大小和检索KD对的读放大问题。KD分离和KV分离遵循着相同的观点:keys只需要在LSM-tree用于索引,values值和增量只(delta)都可以存放在LSM-Tree外部。
KD-增量分离可以看作是与 KV 分离互补的 LSM-tree 优化技术。
最后设计了一个中间件:KDSep,为了通过KD分离增强LSM-tree KV存储,来提高RMWs和reads在RMW-密集负载的高性能,同时维持一般工作负载下的高读写性能
它以 RMWs 场景下的 Merge 解决方法为基础,因为 Merge 在 RMWs 中的表现优于 Get-Put,同时通过 KD 分离减少了 Merge 中的读取开销。
KDSep 旨在支持具有和不具有 KV 分离的一般 LSM-tree KV 存储(例如,分别为 BlobDB 和 RocksDB)。
3.1 Design Challenges
尽管和KV分离相关联,KD分离在设计层面和KV分离不同,需要面对下面不同的挑战
-
Reducing reads to LSM-tree metadata
传统KV分离将metadata存储在LSM-tree中来存储KV对在vLog中的位置
但是对于KD分离,在lSM-treee中存储元数据会引起巨大的读负载。因为一个key有许多增量,因此需要对单独的key进行单独的metadata存储(引入了桶设计
-
Reducing reads to KD pairs
KD分离
KD 分离将增量写入 LSM 树之外的某个单独存储空间,并在增量放置的设计中带来了新的挑战。现在,对某个键的每次读取都需要从单独的存储空间中检索其所有 KD 对,而不是从 KV 分离中的 vLog 中读取单个值 [20]。将增量分组在一起以减轻随机读取至关重要(这里还是引入桶设计)
-
Grabage collection of KD pairs
既然有增量更新,那么就有就旧增量问题。因为增量是从旧的 KV 对中得出的
垃圾回收旧需要回收非法KD对的空间。
然而,使用轻量级数据记录来有效地定位无效的 KD 对至关重要,因为跟踪 LSM 树中 KD 对的位置(如在 KV 分离 [20] 中)可能会产生很高的查找开销 [8]
-
Crash recovery
KV 分离中的崩溃恢复应保持 LSM 树和 vLog 的一致状态。KD 分离为增量添加了一个单独的存储组件,并且需要特别注意所有存储组件的崩溃恢复。
Architecutre
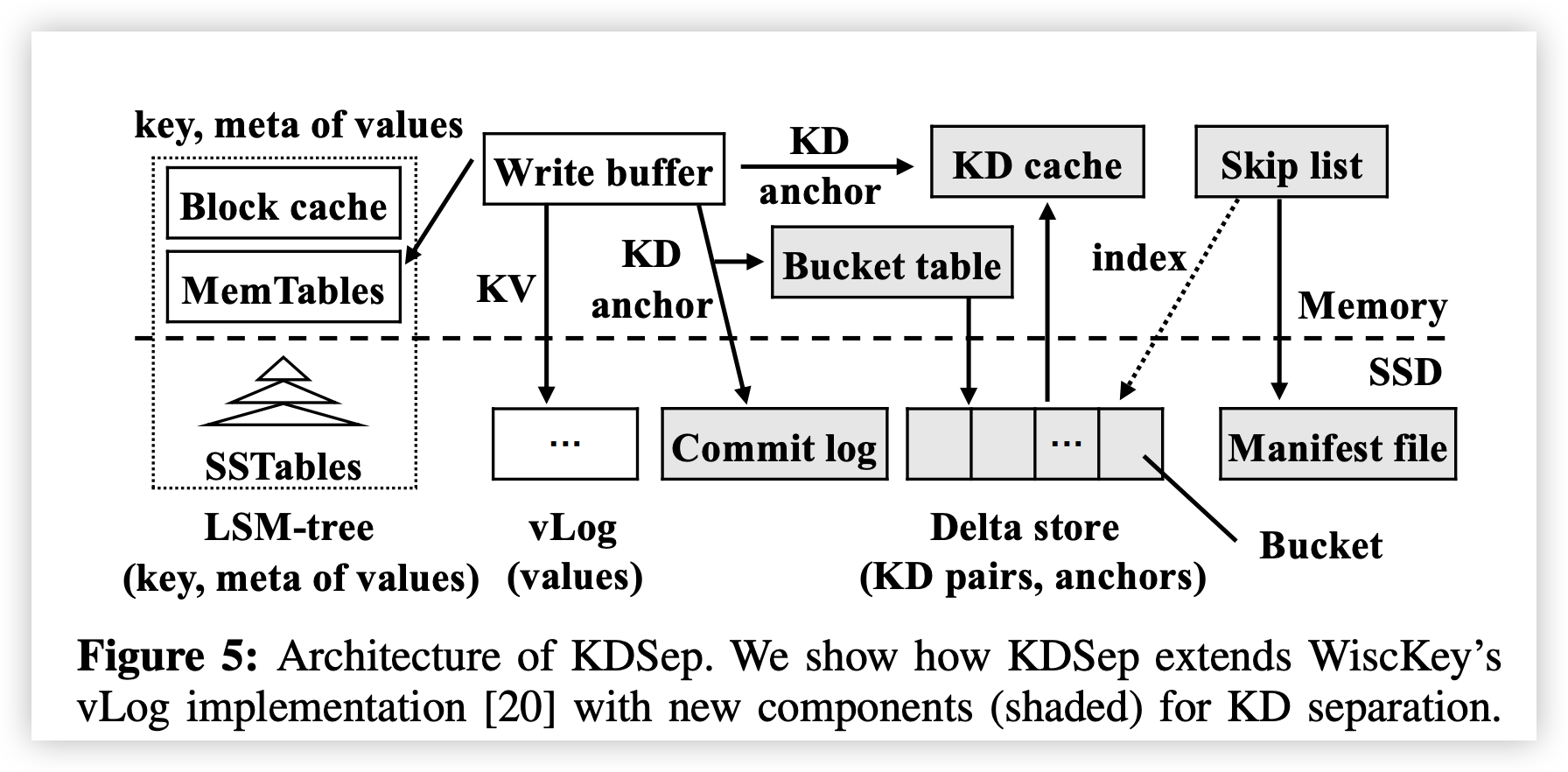
下图展示了KDSeq的架构
3.2 Design Overview
KDSep 实现了 KD 分离,将 KD 对存储在 LSM 树之外的增量存储中。它基于几种技术来解决第 III-A 节中的挑战。
-
bucket-based delta placement
增量存储将其存储空间划分为仅可追加的分区(称为存储桶)。KDSep 将密钥的 KD 对映射到同一个存储桶中,这样它就不需要在 LSM 树中保留 KD 对的元数据,同时仍可以轻松找到密钥的所有 KD 对(解决挑战 1)。它还可以轻松检索密钥的所有 KD 对,因为它们被分组在同一个存储桶中(解决挑战 2)。
-
delta-based garbage collection
-
crash recovery
Architecuture
为了使我们的讨论成立,我们将KDSeq集成到vLog的实现中,vLog不仅实现了KV分离还实现了快速恢复。
回想一下,KDSep 也适用于没有KV分离的KV存储。 KDSep在Delta存储中保留KD对。它还将提交日志和清单文件保留在持久存储中以进行崩溃恢复。我们假设Solidstate Driver(SSD)用于持续存储,以进行高度高性能[20]。
与 WiscKey 一样,KDSep 保留内存写入缓冲区以实现快速写入。写入缓冲区缓存 KV 对和 KD 对,并分别将它们批量刷新到 vLog 和增量存储。此外,KDSep 引入了三种新的内存数据结构:
(i) 用于索引增量存储中具有不相交键范围的存储桶的跳过列表,
(ii) 用于快速访问频繁访问的 KD 对的键-增量 (KD) 缓存
(iii) 用于高效基于存储桶的数据管理的存储桶表
Interfaces:
我们重点关注三个接口:(i) put() 用于写入新的 KV 对(即盲更新),(ii) merge() 用于写入新的 KD 对(即基于 Merge 的 RMW),以及 (iii) get() 用于检索最新版本的 KV 对。我们在下面描述了它们在 KDSep 下的工作流程。
-
Write workflow of
put()andmerge():KDSeq在内存写缓存中 维护根据put()方法的心写入的KV对,以及来自merge()接口的KD pairs
如果KDSeq超出了写缓存设定的缓存大小限制,KDSeq 根据如下步骤刷新缓存
- KDSeq将写缓冲区的所有键值对和KD对按键进行分组,如果某个键有新写入的值,KDSeq会对该值及其出现在该值之后的所有增量执行
fullMerge()以生成一个新的键值对进行刷新,此时已经相当于进行了一步垃圾回收,否则如果某个键没有新写入的值,KDSep依然会和增量执行方式一样,执行partialMerge(),对新的键值对进行一次刷新。 - 为了崩溃恢复,此时KDSep会按照顺序进行执行
- 刷新到VLog中
- 将元数据写入lSM-tree
- 增量存储
- 对KV对,KDSep 将其刷新到vLog中,将元数据写入到LSM-tree中,然后将锚点(anchors)写入到曾令存储的桶中。
- 对于KD对,KDSep将附加到 commit log中,更新存储桶,并将它们写入到增量存储中,请注意,他不需要药将元数据写入到LSM中(因为已经有该数据的元数据中)
- KDSeq将写缓冲区的所有键值对和KD对按键进行分组,如果某个键有新写入的值,KDSeq会对该值及其出现在该值之后的所有增量执行
-
Read workflow of
get()- KDSep 并行搜索vLog 和delta 存储中的值和delta来读取最新值。他会查询LSM tree以在vLog中定位KV对,同时,他会检查内存数据结构并检索KD对。最后他会对值和delta 执行fullMerge操作,并返回合并后的值(合并过程是发生在read操作)
3.3 Bucket-based Delta Placement
KDSep 将增量存储划分为存储桶,并确定性地将 KD 对映射到存储桶。**它为每个存储桶分配固定大小的连续存储空间(例如,默认情况下为 256 KiB)(kV分离是不是可以用一下),**从特定偏移量开始。每个存储桶存储的 KD 对的键范围与任何其他存储桶都不相交。KDSep 维护一个跳跃列表,以有序的方式组织存储桶,这样跨存储桶的所有 KD 对都是有序的,但存储桶内可能不是有序的。
Skip List(跳跃列表)。KDSep 维护一个内存跳跃列表来索引存储桶,如图 6 所示,
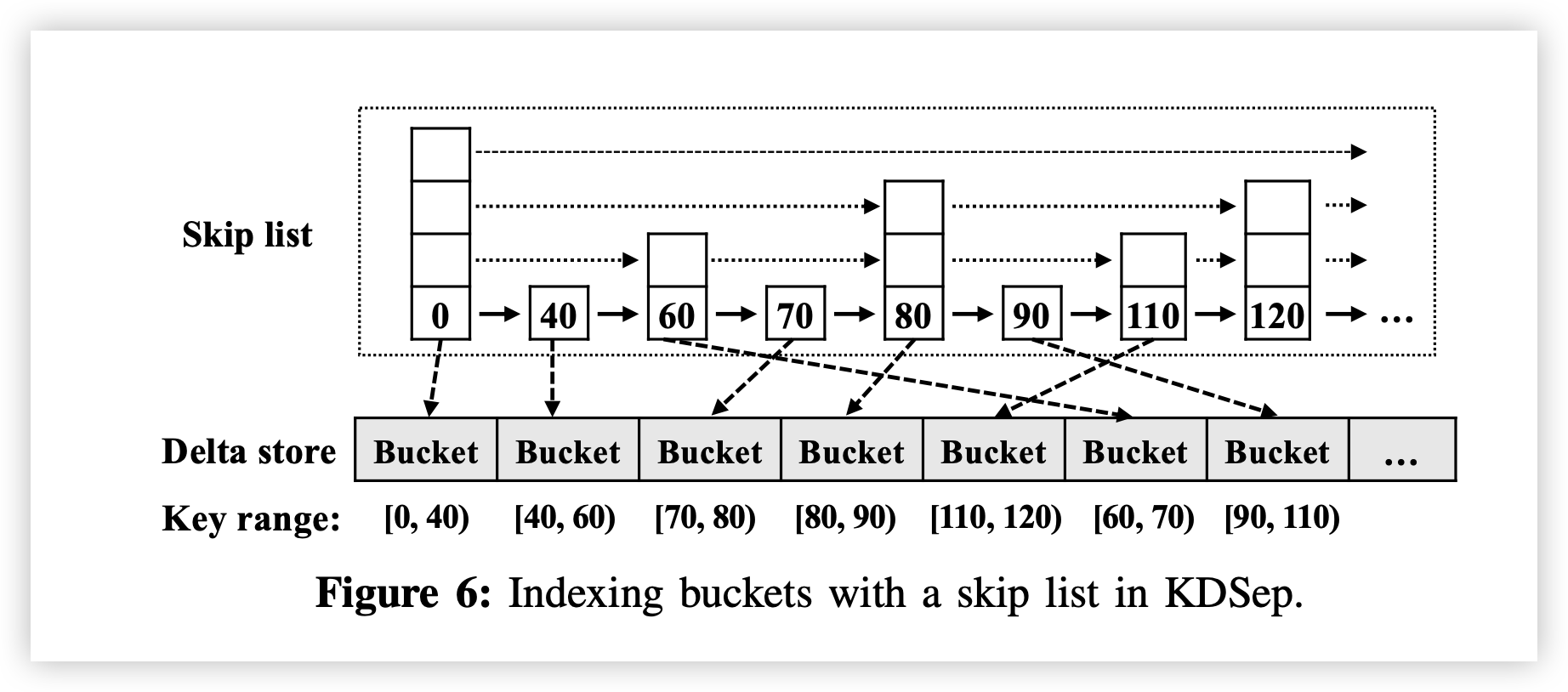
以支持对有序存储桶集进行高效查询和更新。跳跃列表维护多层节点链接列表,其中每个节点存储存储桶的最小键和对存储桶的引用。底层索引所有存储桶,而较高层维护跳跃指针,以便快速搜索底层中的节点。一层中的节点数大约是其下一较低层的一半。假设 N 为增量存储中的最大桶数,则层数为 O(logN),查询和更新成本也是 O(logN) [24]。(没有动态调整key range)
Initialization
在写入任何 KD 对之前,增量存储为空。KDSep 在首次从写入缓冲区写入 KD 对时,会初始化增量存储和跳过列表。具体而言,KDSep 对 KD 对进行排序,并将它们分成多个小存储桶(例如,存储桶容量的 5%),每个存储桶的键范围不相交,以便保留大部分存储桶容量以用于进一步添加 KD 对。然后,它根据每个存储桶的最小键构建初始跳过列表。请注意,随着 KDSep 收到更多 KD 对的写入**,存储桶的大小将会增加,并在垃圾收集期间被拆分(第 III-D 节),因此存储桶的初始大小对整体性能的影响可以忽略不计。**(对上一条疑惑的解释)
Bucket data organization
每个存储桶存储两种类型的数据:KD 对和anchors,
其中锚点标记 KD 对的删除。虽然以追加方式将新数据存储在存储桶末尾以实现快速写入很简单,但键的 KD 对和锚点分散在存储桶中,从而降低了读取性能。(是不是可以通过merge来去掉锚点)
为了保证高效的读取和写入,KDSep 将每个存储桶安排为两部分:已排序部分和未排序部分,如图 7 所示。已排序部分仅存储按键排序的 KD 对,不存储锚点,以实现高效读取;而未排序部分以追加方式存储 KD 对和锚点,以实现高效写入。
KDSep 在垃圾收集期间将 KD 对从未排序部分重新定位到已排序部分(第 III-D 节)。它还保留一个内存存储桶表来管理每个存储桶的数据。桶表包含每个桶的三个组件:(i) 每个桶的索引,(ii) 每个桶的两个布隆过滤器,以及 (iii) 每个桶的缓冲区。我们详细说明每个组件如下。

-
每个桶的索引
每个存储桶的索引维护了已排序键在存储桶的已排序部分中的位置,以便快速检索键的 KD 对。它是在存储桶处于垃圾回收状态时创建的(第 III-D 节)。为了保持索引大小较小,每个存储桶的索引仅保留键和偏移量的子集,使得两个相邻索引键之间的偏移距离略大于 SSD 页面大小 4 KiB。这允许读取最多加载两个 SSD 页面。具体来说,假设 KDSep 从排序部分读取键 K 的 KD 对。
它首先在每个存储桶索引中找到 K 所在的键范围。然后,它从排序部分加载 SSD 页面(最多两个),并搜索 K 的 KD 对。让存储桶容量为 256 KiB,键大小为 24 字节,引用大小为 4 字节。每个存储桶的索引大小最多为 256/4×(24+4) 字节 = 1.75 KiB
-
每个桶的布隆过滤器
为了快速确定存储桶中是否存在 KD 对,KDSep 在每个存储桶中保留两个小型内存布隆过滤器(每个大小为 2 KiB),一个用于已排序部分,一个用于未排序部分。当存储桶处于垃圾回收状态时,将重置并创建已排序部分的布隆过滤器,而当存储桶处于垃圾回收状态时,将重置未排序部分的布隆过滤器,并在收到新的 KD 对时进行更新。
-
每个桶的缓存
由于 KD 对通常很小(例如 100 字节 [7]、[12]),将 KD 对单独刷新到 SSD 页面(大小为 4 KiB)可能会导致大量小写入和高写入放大 [21]。因此,当 KDSep 将 KD 对从写入缓冲区刷新到增量存储时,它首先将它们添加到每个存储桶的缓冲区中。然后,当缓冲区已满时,它将每个存储桶的缓冲区刷新到 SSD。我们将每个存储桶的缓冲区大小配置为 4 KiB,以匹配 SSD 页面大小。KD 缓存。KDSep 使用内存中的 KD 缓存来缓存最近读取/写入的 KD 对,因为它们很可能很快会再次被访问。对于正在读取的每个 KD 对,如果其键是新的,KDSep 会将其添加到 KD 缓存中,或者使用 partialMerge() 将其与任何当前缓存的相同键的 KD 对相结合。对于每个正在写入的 KD 对,如果密钥已缓存,KDSep 会将其与缓存的 KD 对相结合。对于每个正在写入的锚点,KDSep 会用具有空增量的新 KD 对替换任何现有 KD 对。如果 KD 缓存已满,则使用最近最少使用的逐出方法。
Bucket writes/reads
下面我们描述如何将KD对和anchors 写入到bucket,以及如何从bucket中读KD 对
-
KD对和anchors 的写入(先写入到缓冲区,然后将缓冲区数据写入到bucket的未排序不分中,
KDSep 在将写入缓冲区刷新到增量存储时写入 KD 对和锚点(第 III-B 节)。
首先,它使用 KD 对或锚点的键来查询相关存储桶的跳过列表。
其次,它将 KD 对或锚点附加到每个存储桶的缓冲区,当缓冲区已满时,它将刷新到存储桶的未排序部分。
第三,它将键插入到每个存储桶的布隆过滤器中,以获取未排序部分。
最后,它更新 KD 缓存(缓存区重制)。
-
KD对的读取
KDSep 在 get() 期间从存储桶中读取与键关联的 KD 对。首先,它查询 KD 缓存,并在缓存命中时返回缓存的 KD 对。其次,它通过键在跳过列表中搜索存储桶。第三,它根据每个桶的布隆过滤器检查密钥是否存在于排序部分和未排序部分中。根据查询结果,它通过每个桶的索引从排序部分搜索 KD 对,或从未排序部分搜索出现在最新锚点之后的 KD 对。
它还调用 partialMerge() 来合并正在检索的 KD 对。任何正在检索的 KD 对也会更新到 KD 缓存中。(读取过程中,会将未排序的KD对进行合并)
请注意,每个桶的布隆过滤器可能会返回误报,即对排序部分或未排序部分的搜索未找到相应的 KD 对。在这种情况下,KDSep 返回一个空的增量。
3.4 Delta-based Garbage Collection
基于增量的垃圾收集的目标有三点。
- 首先,它通过删除无效的 KD 对并合并相同键的 KD 对来回收增量存储的可用空间。
- 其次,它对 KD 对进行排序并将其添加到已排序部分(第 III-C 节)。
- 最后,它通过基于工作负载模式动态拆分和合并存储桶来控制存储桶大小和存储桶数量。由于工作负载倾斜,即使增量存储仍有可用空间,某些存储桶可能会收到比其他存储桶更多的 KD 对,并很快变满(某个桶热区,其他桶冷区的情况)。因此,KDSep 根据工作负载模式重新分配存储桶。
我们详细说明垃圾收集的步骤如下。
步骤 1:触发。当 KDSep 即将将写入缓冲区刷新到增量存储但某些存储桶已满且无法存储刷新的数据时,它会触发垃圾收集(桶已满的情况)。此类存储桶称为受害者存储桶,将被选中进行垃圾收集。
步骤 2:准备有效的 KD 对。对于每个受害者存储桶,KDSep 按键将 KD 对和锚点分组。对于每个键,KDSep 仅保留最新锚点(如果有)之后的 KD 对,并对此类 KD 对执行 partialMerge(),以减少有效 KD 对的数量。
步骤 3:写入有效的 KD 对。KDSep 确定是否应拆分每个受害者存储桶(是否是因为桶太小导致了桶已满)。我们定义了一个可配置参数,称为拆分阈值(以字节为单位),这样 KDSep 就会将步骤 2 中准备的有效 KD 对的总大小与拆分阈值进行比较,以决定是否应拆分受害者存储桶。有三种情况:
- Case 1 (Rewriting a bucket(不需要)):如果有效 KD 对的总大小不大于拆分阈值,则 KDSep 不会拆分受害存储桶。相反,它会以排序的方式将有效 KD 对重写到增量存储中新存储桶的排序部分。
- Case 2 (Splitting a bucket):如果有效 KD 对的总大小超过拆分阈值,并且当前存储桶数量不大于 N - 2,则 KDSep 会拆分受害存储桶。我们选择 N -2,因为拆分会暂时添加两个新存储桶,并且我们确保拆分不会使存储桶数量超过 N。KDSep 根据有效 KD 对的键范围将其划分为两个新存储桶,并以排序的方式将 KD 对写入相应存储桶的排序部分。
- Case 3 (Merging with the vLog):如果有效 KD 对的总大小超过分割阈值,并且当前 bucket 数量超过 N − 2,则意味着增量存储无法分配更多 bucket。KDSep 通过 fullMerge() 将 victim bucket 中的所有 KD 对与 vLog 中的 KV 对合并,并释放 victim bucket
步骤 4 :Updating index structures。KDSep 根据有效 KD 对的新位置更新存储桶表和跳过列表。图 8 显示了 KDSep 在拆分或合并存储桶时如何更新跳过列表。
 如果 KDSep 拆分存储桶,它会将新节点插入跳过列表;如果 KDSep 合并两个存储桶,它会从跳过列表中删除最初引用具有较大键的存储桶的节点。在这两种情况下,KDSep 都会更新剩余节点的引用以指向新写入的存储桶。
如果 KDSep 拆分存储桶,它会将新节点插入跳过列表;如果 KDSep 合并两个存储桶,它会从跳过列表中删除最初引用具有较大键的存储桶的节点。在这两种情况下,KDSep 都会更新剩余节点的引用以指向新写入的存储桶。
步骤 5: Merging bucket。KDSep 合并只有少量 KD 对的桶,以便可以拆分其他经常追加的桶。具体来说,它会检查桶的数量是否超过 N -2(即,将来不能进行拆分)。如果是,KDSep 会检查跳过列表中所有相邻桶对,并选择有效 KD 对总大小最小的桶对。如果选定的桶对总大小不大于桶容量,并且不是由步骤 3 中情况 2 中的拆分生成的,则 KDSep 会将选定桶对的所有有效对按排序方式重写到新桶的排序部分,并像步骤 4 一样更新索引结构。
3.5 Crash Recovery
KDSep 支持在1. 写入和2. 垃圾收集期间对 LSM-tree、vLog 和增量存储进行崩溃恢复。
Crash recovert for writes 写入的崩溃恢复。
回想一下,在写入过程中,KDSep 会刷新写入缓冲区并按顺序更新 vLog、LSM-tree 和增量存储(第 III-B 节)。我们遵循 WiscKey [20] 删除 WAL 以避免冗余写入,因为 vLog 也可以用作 WAL。与 WiscKey 一样,KDSep 定期将 vLog 的头指针(即 vLog 发出新写入的偏移量,更新vLog新的偏移值,确保对实时写入的记录)记录到 LSM-tree。在崩溃恢复中,KDSep 从头指针指定的偏移量扫描到 vLog 的末尾(超过的部分自动截断),从而提供 vLog 和 LSM-tree 之间的崩溃一致性。
为了提供 vLog 和增量存储之间的崩溃一致性,KDSep 在每个 KD 对中附加一个全局单调递增的序列号,并在 put() 或 merge() 期间进行锚定以识别发生序列。它还引入了一个提交日志来附加 KD 对和锚点(带有序列号)。
具体来说,KDSep 首先通过将 KV 对附加到 vLog 并将 KD 对和锚点附加到提交日志(两个附加操作可以并行完成)来刷新写入缓冲区。接下来,它将提交消息写入提交日志。最后,它更新 LSM 树(包括元数据和记录的头指针)、存储桶表和增量存储。我们考虑两种崩溃场景来展示 KDSep 如何执行崩溃恢复。
KV 附加到vlog。 | 将commit 消息写入到提交日志|更新LSM tree
KD pairs和anchors 附加到commit logs| |
Case 1 : A crash happens before the commit message is written: 在写入提交消息之前发生崩溃。在这种情况下,写入缓冲区中的数据未完全提交。KDSep 回滚提交日志以丢弃任何未提交的数据。它还通过将最新的头指针设置为 LSM 树中记录的头指针(指最后提交的写入)来回滚 vLog。vLog 中的任何未提交数据稍后都可以被来自最新头指针的新提交的 KV 对覆盖。
Case 2 : A crash happens after the commit message is written。崩溃发生在提交消息写入之后。与 WiscKey 一样,KDSep 从 LSMtree 读取头指针,从记录的头指针到末尾扫描 vLog,并将扫描的键及其元数据重写到 LSM 树。在这两种情况下,KDSep 都会通过提交日志恢复存储桶表。它会扫描提交日志(在丢弃任何未提交的数据之后),并从提交日志中恢复每个存储桶的缓冲区(如果它们的序列号大于存储桶中的数据,即,崩溃之前此类数据仍写入存储桶)。最后,它会扫描所有存储桶以恢复每个存储桶的索引和布隆过滤器。
Crash recovery for garbage collection
垃圾收集可能会改变跳跃列表中的 bucket 引用。为了确保崩溃后能够找到 bucket,KDSep 维护一个清单文件来记录跳跃列表中的 key 和 bucket 偏移量(注意,RocksDB 也维护一个清单文件来跟踪文件的版本变化)。KDSep 中的清单文件会保留跳跃列表的快照,并附加任何描述跳跃列表变化的记录。在垃圾收集期间,KDSep 首先更新索引结构并修改 bucket,然后将要修改的 bucket 的最小 key 和 bucket 偏移量附加到清单文件中。在崩溃恢复期间,KDSep 会重放清单文件中的快照和附加的记录以重建跳跃列表。
3.6 Asymptotic Analysis 渐进分析
数学性质的对时间复杂度进行分析
我们对 KDSep 的读写性能进行了渐近分析,并展示了 KD 分离的有效性。我们表明 KDSep 提高了读取性能并保持了写入性能。先前的研究 [5]、[11]、[20] 也对 LSM 树进行了渐近分析,但它们没有考虑 KD 分离。
在这里,我们假设 LSM 树将所有索引块和布隆过滤器缓存在内存中,这在现代 KV 存储实现中是现实的 [16]。我们还假设 vLog 被禁用,但引入 vLog 只会使 LSMtree 更小,不会影响我们的分析。表一总结了我们的分析结果。
Read performance
回想一下,n+1 是 LSMtree 层数(第 II-A 节),让 m 为 L0 中 SSTable 的最大数量。每次读取都会检索某个键的所有 KD 对和 KV 对。如果不进行 KD 分离,为了检索所有 KD 对,LSM 树会读取 L0 中的每个 SSTable 并检查所有 LSM 树层,因此读取次数可以是 O(n+m);要检索 KV 对,LSM 树会发出 O(1) 读取,假设布隆过滤器的误报率足够低 [11]。进行 KD 分离后,总读取复杂度仅为 O(1),因为 KDSep 读取单个存储桶来查找其所有 KD 对,并在 LSM 树中发出 O(1) 读取来检索与 KD 对关联的 KV 对。请注意,存储桶中的读取大小可能比 LSM 树中的读取大小(例如 4 KiB 数据块)更大(受存储桶容量 256 KiB 的限制)。但是,对于小读取,读取延迟与读取大小不成比例。例如,我们测试的驱动器 [2] 上的 256 KiB 读取延迟仅为 4 KiB 读取的 4 倍左右。此外,每个存储桶索引和布隆过滤器可以进一步减轻读取大小
Write Performance
令 F 为相邻两层 LSM-tree 的大小比(例如 RocksDB 中默认为 10)。如果没有 KD 分离,则每个写入的 KV 或 KD 对在压缩期间最多可以被重复写入 O(Fn) 次,因为数据在每个 LSMtree 层中平均被写入 F 次。如果使用 KD 分离,KV 对的写入次数也是 O(Fn),而 KD 对的写入次数取决于增量存储是否有足够的预留空间来存储所有写入的 KD 对:
Case 1 (sufficient reserved space):
令 p(p < 1)为分割阈值与桶容量的比值。如果有足够的空间,垃圾回收不会导致分割,因此垃圾回收期间有效 KD 对的总大小以分割阈值为上限。因此,每个 KD 对在一次垃圾回收操作中最多被重写 p 次。从长远来看,KD 对的平均重复写入次数上限为 O(p+ p 2 + p 3 + ···) = O(
1 1−p )。例如,通过将分割阈值设置为桶容量的 80%,该分数仅为 1 1−p = 5,因此 KD 分离不会导致写入性能的显著下降
Case 2 (Insufficient reserved space):
存储桶中的每个 KD 对都会与其对应的 KV 对合并(参见第 III-D 节中的步骤 3,案例 3)。这会导致 KV 对额外读取一次 O(1)。合并后,每个新 KV 对的写入复杂度为 O(Fn),与没有 KD 分离时一样。
3.7 实现细节
我们在 Linux 上用 C++ 实现了一个 KDSep 原型,其 LoC 为 14.4 K,以支持 KD 分离。具体来说,我们将增量存储实现为用户空间中的大文件,其中存储桶从与存储桶容量倍数对齐的文件偏移量开始。我们让 KDSep 分别通过 pread 和 pwrite 系统调用发出读取和写入。
KDSep 充当中间件层,可以以最少的代码更改集成到通用 LSM 树 KV 存储(可能不支持合并)中。在这项工作中,我们将 KD 分离集成到 RocksDB(v7.7.3)[16] 和 BlobDB(包含在 RocksDB 的源代码中)[14] 中;RocksDB 不支持 KV 分离,而 BlobDB 支持。我们还将 KDSep 与 [8] 中基于 vLog 的 KV 存储实现集成,它支持 KV 分离并使用 RocksDB(v7.7.3)[16] 作为 LSM 树。
Multi-threading
KDSep 实现了多线程以实现 I/O 并行化。它使用 boost 库中的 asio::thread_pool 来管理线程。在刷新写入缓冲区时,KDSep 将属于同一存储桶的 KD 对和锚点分组,并分配一个线程将它们写入存储桶。具体而言,KDSep 利用多线程并行向多个存储组件发出读取操作,从而保持读取效率。它分配两个线程,一个用于从 LSM-tree 和 vLog 读取 KV 对,另一个用于从增量存储中读取 KD 对。两个线程使用 boost 库通过无锁消息队列交换数据,并使用轮询实现低延迟数据同步。请注意,我们的轮询实现仅会导致 CPU 使用率略高(第 IV-B 节)。KDSep 还发出两个线程进行范围查询,一个用于从 LSM 树读取键和元数据以从 vLog 中检索 KV 对,另一个用于从增量存储中检索 KD 对。它对 KV 和 KD 对执行 fullMerge(),并返回合并的 KV 对
Memory budget
内存预算。内存使用主要来自块缓存(在 RocksDB 中)、KD 缓存和 bucket 表。为了控制整体内存使用量并遵守给定的内存预算,KDSep 会随着 KD 缓存和 bucket 表大小的增长而动态调整块缓存的容量。具体来说,KDSep 设置内存预算,并最初将块缓存的容量设置为等于内存预算。在运行时,如果 KD 缓存和 bucket 表的大小增加,KDSep 会使用 RocksDB 中的 Cache::SetCapacity() 接口减少块缓存的容量,以保持相同的内存使用量
Trade-off discussion
我们的 KDSep 实现在两个方面做出了权衡。首先,它牺牲了额外的 CPU 周期来支持多线程 I/O 并行化,从而实现更快的读写速度。然而,与 I/O 相比,这种 CPU 开销很小(第 IV-B 节)。其次,它牺牲了额外的内存来维护每个存储桶的缓冲区,但额外的内存使用量可以忽略不计,因为主要的内存使用量用于缓存(例如,每个存储桶缓冲区的 2 15 ×4 KiB= 128 MiB,相当于总内存预算的 128 4∗1024 = 3.1%)。















 1429
1429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









