









排序与查找
算法时间,空间复杂度
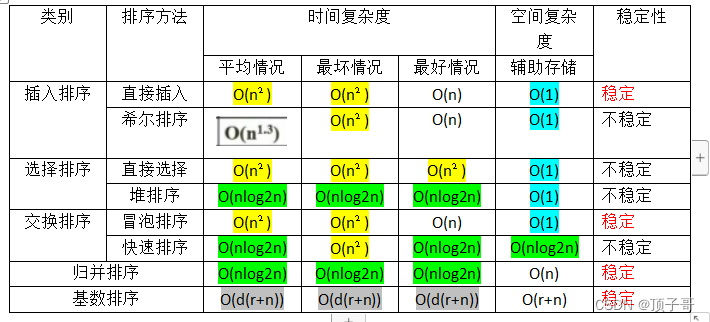
排序
排序有插入排序(直接插入排序,希尔排序),
选择排序(直接选择排序,堆排序),
交换排序(冒泡排序,快速排序),
归并排序,基数排序
直接插入排序
主要操作:
现将序列中的第一个记录看成一个有序子序列(标准),然后从第二个序列开始,逐个进行插入,直到整个序列有序,排序过程为n-1趟插入。
例:关键字序列T=(13,6,3,31,9,27,5,11)
开始直接插入排序
第1趟:【13】,6,3,31,9,27,5,11
第2趟:【6,13】,3,31,9,27,5,11
第3趟:【3,6,13】,31,9,27,5,11
第4趟:【3,6,13,31】,9,27,5,11
第5趟:【3,6,9,13,31】,27,5,11
第6趟:【3,6,9,13,27,31】,5,11
第7趟:【3,5,6,9,13,27,31】,11
第8趟:【3,5,6,9,1113,27,31】
时间复杂度:O(n的平方)
空间复杂度:O(1)
算法稳定性:稳定
希尔排序
主要操作:
本质是多次的直接插入排序
先取一个正整数d1<n(序列的字符数),把所有相隔d1的记录放一组,组内进行直接插入排序;然后取d2,重复上述分组排序和操作;直至di=1,即所有的记录放进一个组中排序为止。
一般取d1=n/2,di+1=di/2,如果结果为偶数,则加1
例:T=(49,38,65,97,76,13,27,48,55,4)
第一趟希尔排序:
n=10
d1=n/2=5
所以第一次排序应该把相隔5的数字放在一起比较
分组情况 :
(49,13);(38,27);(65,48);(97,55);(76,4);
直接插入排序后:
T=(13,27,48,55,4,49,38,65,97,76)
第二趟希尔排序:
d1=5
d2=d1/2=5/2=2 + 1 = 3
T=(13,27,48,55,4,49,38,65,97,76)
所以第二次排序应该把相隔3的数字放在一起比较
分组情况:
(13,55);(27,4);(48,49);(55,38);(4,65);(49,97);(38,76);
直接插入排序后:
T=(13,4,48,38,27,49,55,65,97,76)
第三趟希尔排序:
d2=3
d3=d2/2=3/2=1
T=(13,4,48,38,27,49,55,65,97,76)
d3=1的情况是整体是一组,所以直接进行直接插入排序
分组情况:
直接插入排序后:
T=(4,13,27,38,48,49,55,65,76,97)
时间复杂度:O(n的平方)
空间复杂度:O(1)
算法稳定性:不稳定(初始序列不同会影响选择的效率)
直接选择排序
主要操作:
首先先取出所有记录中最小的记录,把他与第一个记录互换,然后在剩下的记录内选出最小的记录与第二个交换…以此类推。
例:T=(21,25,49,27,16,08)
开始直接选择排序
第1趟:【08】,25,49,27,16,21
第2趟:【08,16】,49,27,25,21
第3趟:【08,16,21】,27,25,49
第4趟:【08,16,21,25】,27,49
第5趟:【08,16,21,25,27】,49
时间复杂度:O(n的平方)
空间复杂度:O(1)
算法稳定性:不稳定
堆排序
什么是堆
堆分为小顶堆和大顶堆
满足 ri<=r2i 和 ri<=r2i+1的叫小顶堆,最小的值是数的根结点
满足 ri>=r2i 和 ri>=r2i+1的叫大顶堆,最大的值是数的根结点

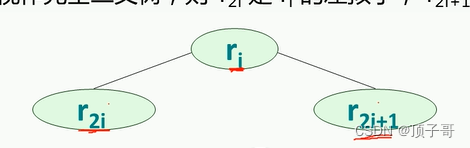
主要操作:
首先把序列化成大顶堆或者小顶堆,然后取出根结点,并且把目前堆中最后一个结点做根结点,如果此时不满足成为堆的条件,那么要调整,左右子树中最小的和父节点调换为止,直到构成堆,再取出跟结点,以此类推
时间复杂度:O(nlog2n)
空间复杂度:O(1)
算法稳定性:不稳定
冒泡排序(△△△△△经常考)
主要操作:
每趟不断将记录两两比较,按照前小后大或者前大后小规则交换
这样做能保证第一个第一趟排序后位最小或者最大的值
第一趟:第一个与第二个比较,大则交换,第二与第三个比,大则交换,一次类推
第二趟:堆前n-1个记录进行同样的操作,
以此类推,完成排序
例:T=(25,56,49,78,11,65,41,36)
前大后小型的排序
进行冒泡排序
第1趟:25,49,56,11,65,41,36,【78】
第2趟:25,49,11,56,41,36,【65,78】
第3趟:25,11,49,41,36,【56,65,78】
第4趟:11,25,41,36,【49,56,65,78】
第5趟:11,25,36【41,49,56,65,78】,
时间复杂度:O(n的平方)
空间复杂度:O(1)
算法稳定性:稳定
快速排序(前提:顺序存储结构)
主要操作:
从待排序序列中任取一个元素(例如第一个)作为它的中心,比他小(或者相等)的元素一律放前,所有比他大的数一律放后面;
然后在对格子表重新选择中心元素并按照次规则调整,直到每个字表的元素只剩一个。此时就是有序序列了
对r[0…n-1]中记录快速排序,设两个指针i和j,基准x=r[0],初始指令i=0+1,j=n-1
从j所指为止向前搜索第一个关键字小于x的记录,并和r[j]交换
从i所指为止向后搜索,找到第一个关键字大于x的记录和r[i]交换
重复上述两部,直到i==j为止
再对子序列重复以上步骤
例:T=(49,38,65,97,76,13,27,50)
进行快速排序:
第一趟:
选择第一个数作为中心 49
【27,38,13】49【76,97,65,50】
第二趟:
选择第一个数作为中心 27,76
【13,】27,【38】,49,【50,65】76,【97】
第三趟:
13,27,38,49,65,76,97
时间复杂度:O(n的平方)
空间复杂度:O(nlog2n)
算法稳定性:不稳定
归并排序
主要操作:
可以把一个长度为n的无序序列看成是n个长度为1的有序子序列,首先做两两归并,等到n/2个长度为2的有序子序列,在做两两归并,不断重复,直到最后得到一个长度n的有序序列
例:T=(21,25,49,25,93,62,72,08,37,16,54)
开始归并排序
第一趟两两归并:
【21,25】,【25*,49】,【62,93】,【08,72】,【16,37】,【54】
第二趟两两归并:
【21,25,25*,49】,【08,62,78,93】,【16,37,54】
第三趟两两归并:
【08,21,25,25*,49,62,78,93】,【16,37,54】
第三趟两两归并:
【08,16,21,25,25*,37,49,54,62,78,93】
时间复杂度:O(n的平方)
空间复杂度:O(n)
算法稳定性:稳定
基数排序
主要操作:
过程简单,但是代码不好写
基数排序比较时候大数之间的排序。首先他确定最大的数的位数(个位,十位,百位),然后确定十个桶,编号0-9(这是固定的)
先按照每个数的个位数排序,放入桶内,得到一个序列,桶清空;
依据上个序列,按照每个数的十位位数排序,放入桶内,得到一个序列,桶清空;
以此类推,直到完成最大数的位数
例 T=(123,34,456,7,89)
开始继续基数排序
第一次:
123,34,456,7,89
按照个位排序:
0,1,2,3【123】,4【34】,5,6【456】,7【7】,8,9【89】
得到:
123,34,456,7,89
第二次:
123,34,456,7,89
按照十位排序:
0【7】,1,2【123】,3【34】,4,5【456】,6,7,8【89】,9
注意:此时7的十位是0
得到:
7,123,34,456,89
第三次:
按照百位排序:
0【7,34,89】,1【123】,2,3,4【456】,5,6,7,8,9
得到:
7,34,89,123,456
时间复杂度:O(d(r+x))
空间复杂度:O(d(r+x))
算法稳定性:稳定
查找
顺序查找
用逐一比较的办法顺序查找
平均查找长度:(n+1)/2
优点:算法简单,适应面广,对查找标的结构没有要求,无论记录是否按照关键字序列排列均可使用。
缺点:在n值较大时,平均查找长度较大,查找效率较低。
折半查找(二分查找)
首先给数据排序,形成有序表,把待查数据值与查找范围中间元素值进行比较,会有四种情况出现
1.二分查找查找的元素与中间元素相等,返回中间元素值的索引。
2.待查找数值比中间元素值小,则以整个查找范围的前半部分作为新的查找范围,执行1,直到找到相等的值。
3.待查找数值比中间元素值大,则以整个查找范围的后半部分作为新的查找范围,执行1,直到找到相等的值
4.如果没有找到相等的值,返回错误信息。
平均查找长度:约等于log2(n+1)-1
优点:效率比顺序查找效率要高。
缺点:要求查找表进行顺序存储并且按关键字有序排列,因此对表进行元素的插入和删除时,需要移动大量的元素,所以折半查找适用于表不易变动,又经常查找的情况。
分块查找
分块查找又叫索引顺序查找,是对顺序查找方法的一种改进,其性能介于顺序查找和折半查找之间。
首先靶标分成若干块,块内关键字不一定有序,但是块之间是有序地,即后一块中所有记录的关键字均大于前一块中最大的关键字,还简历了一个索引表,索引表按关键字有序
组内无序,组外有序
【22,12,13,8,9,20】,【33,42,44,38,24,48】,【60,58,74,49,86,53】
索引表(第一行是各块第一个数,第二行代表各块起始地址),索引表表示了块之间的有序关系
22 48 86
1 7 13
分块查找开始
首先对索引表进行折半查找(因为索引表是有序的)
然后确定了带查找关键字所在的字表后,在表内裁员顺序查找法(因为表内是无需的)
算法
分治法(归并,分币,快排)
分治算法是一种将问题拆分为独立的子问题,并将子问题的解合并成原问题解的方法。
分治算法通常使用递归实现,将问题逐步拆解为更小的子问题,直到问题规模足够小,可以直接解决。
分治算法的关键是找到问题的拆分方式和合并方式,以及确定递归的终止条件。
动态规划法(背包,0-1,公共子序列)
- 动态规划法是一个以获取问题最优解为目标的算法
- 关键字:最优子结构,重叠子问题
- 动态规划是一种通过将问题拆分为重叠子问题,并根据子问题的解构建整体问题的解的方法。
动态规划通常使用记忆化技术,将子问题的解存储起来以便后续使用,避免重复计算。
动态规划的关键是找到正确的状态转移方程,将原问题划分为子问题,并通过子问题的解构建全局最优解。
贪心法(场合)
贪心法并不总能得到全局最优解,局部最优解
贪心算法是一种在每一步选择中都采取局部最优解的策略,以期望最终能够得到全局最优解。
使用贪心算法时,需要注意证明局部最优解能够推导出全局最优解,否则可能会得到次优解或不正确的答案。
回溯法(n皇后)
深度优先
迷宫问题,寻找正确路径,错了就返回,返回的过程就叫做回溯。
回溯算法是一种通过穷举所有可能的解并逐步构建答案的方法。
回溯算法通常使用递归来遍历所有可能的解空间,并通过剪枝技术来提高搜索效率。
回溯算法适用于求解满足某些限制条件的问题,但随着问题规模的增大,其复杂度往往会迅速增加。



















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











