









问题背景:
19cRAC使用swingbench进行压测
并发数200
压测截图:
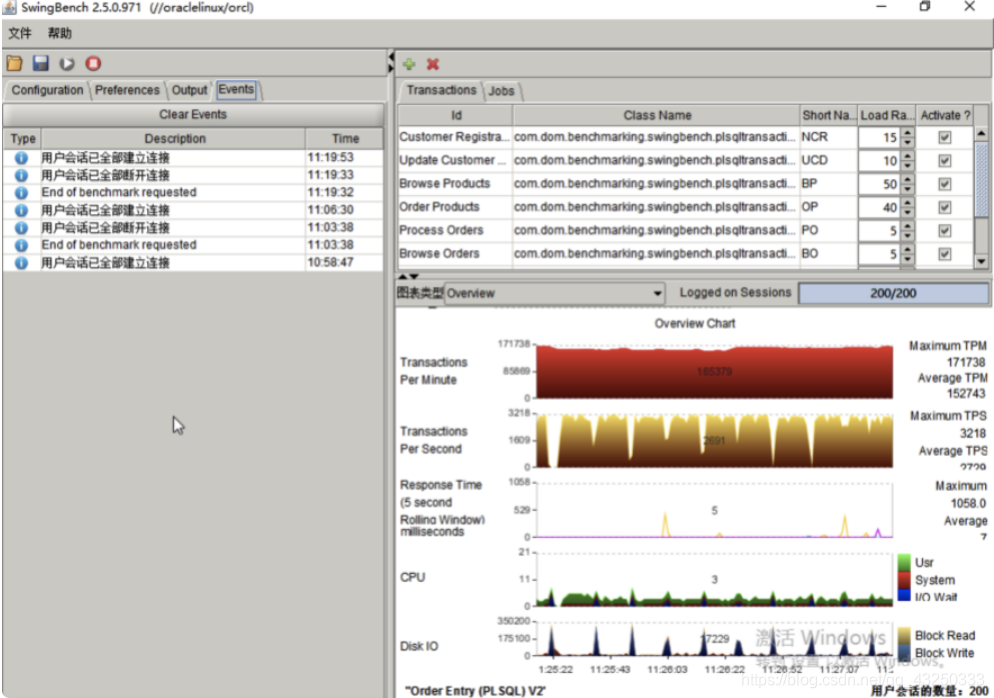
tps存在较多起伏,同时磁盘IO存在较多抖动,说明对磁盘的写较为频繁且tps与磁盘IO变化趋势接近
ash查看当前等待事件:
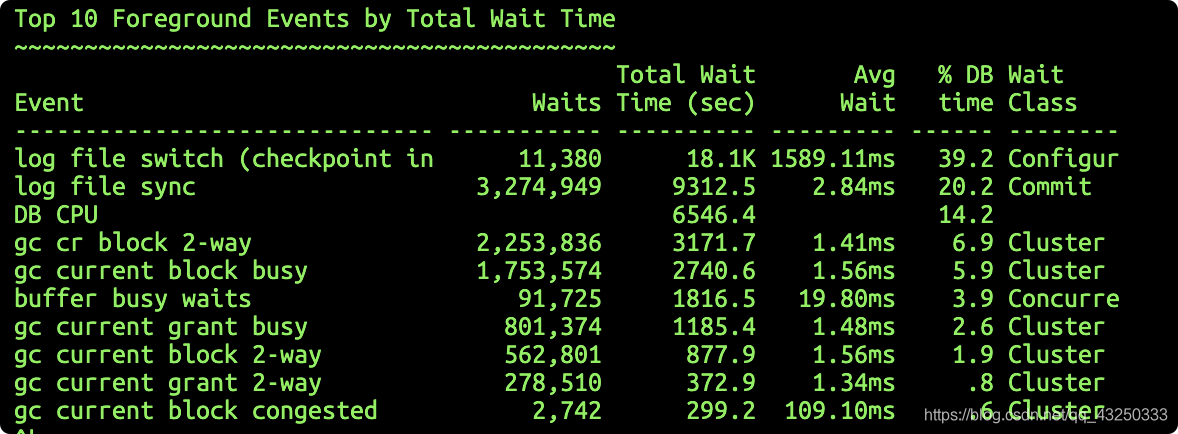
发现较多log files witch,log file switch等待,该等待事件在日志发生切换的时候出现。后台进程 LGWR需要关闭当前日志组,切换并打开下一个日志组,在这个切换过程中, 数据库的所有 DML 操作都处于停顿状态,直至这个切换完成。
log file switch主要包含log file switch(archiving needed)以及log file switch(checkpoint incomplete)。前者主要是因为日志组循环写满以后, 在需要覆盖先前日志时,需要对日志文件进行归档却发现日志归档尚未完成,出现该等待。由于 Redo 不能写出,该等待出现时,数据库将陷于停顿状态。出现该等待,可能表示 I/O 存在问题、归档进程写出缓慢,也有可能是日志组设置不合理等原因导致。针对不同原因有以下途径进行解决:
-
可以考虑增大日志文件和增加日志组;
-
移动归档文件到快速磁盘;
-
调整 log_archive_max_processes 参数等( alter system set log_archive_max_processes=n scope=both;)。
后者即日志切换(检查点未完成)。 当所有的日志组都写满之后, LGWR 试图覆盖某个日志文件,如果这时数据库没有完成写出由这个日志文件所保护的脏数据时(检查点未完成),该等待事件出现。 该等待出现时,数据库同样将陷于停顿状态。可以考虑增加额外的 DBWR 或者增加日志组或日志文件大小
主要就是redo的switch等待很严重,log files switch触发的原因,硬件算一方面,还有就是业务的频繁度,频繁的业务,redo越多,切换越频繁,但是为了落盘就要等,在硬件解决不了的情况,只能先调一下大小缓解一下它的切换。
使用如下语句查看当前日志组大小与组数:
select a.thread#,
a.status,
a.bytes / 1024 / 1024,
b.type,
b.group#
from v$log a, v$logfile b
where a.group# = b.group#;
原日志组为4组每组只有200M,做出如下调整
--添加日志组
alter database add logfile thread 1 group 9 ('+DATA01/ORCL/ONLINELOG/redo09.log') size 1024M;
alter database add logfile thread 1 group 10 ('+DATA01/ORCL/ONLINELOG/redo10.log') size 1024M;
alter database add logfile thread 2 group 11 ('+DATA01/ORCL/ONLINELOG/redo11.log') size 1024M;
alter database add logfile thread 2 group 12 ('+DATA01/ORCL/ONLINELOG/redo12.log') size 1024M;
....
alter database add logfile thread 1 group 21 ('+DATA01/ORCL/ONLINELOG/redo21.log') size 1024M;
alter database add logfile thread 1 group 22 ('+DATA01/ORCL/ONLINELOG/redo22.log') size 1024M;
alter database add logfile thread 2 group 23 ('+DATA01/ORCL/ONLINELOG/redo23.log') size 1024M;
alter database add logfile thread 2 group 24 ('+DATA01/ORCL/ONLINELOG/redo24.log')
--添加完成后,手动执行切换日志将原日志状态切换至非current状态
alter system switch logfile
--手动执行完全检查点使所有非current日志调整为inactive
alter system checkpoint
--删除原来的日志组,保证每次切换日志间隔均匀
alter database drop logfile group 1;
alter database drop logfile group 2;
alter database drop logfile group 3;
alter database drop logfile group 4;
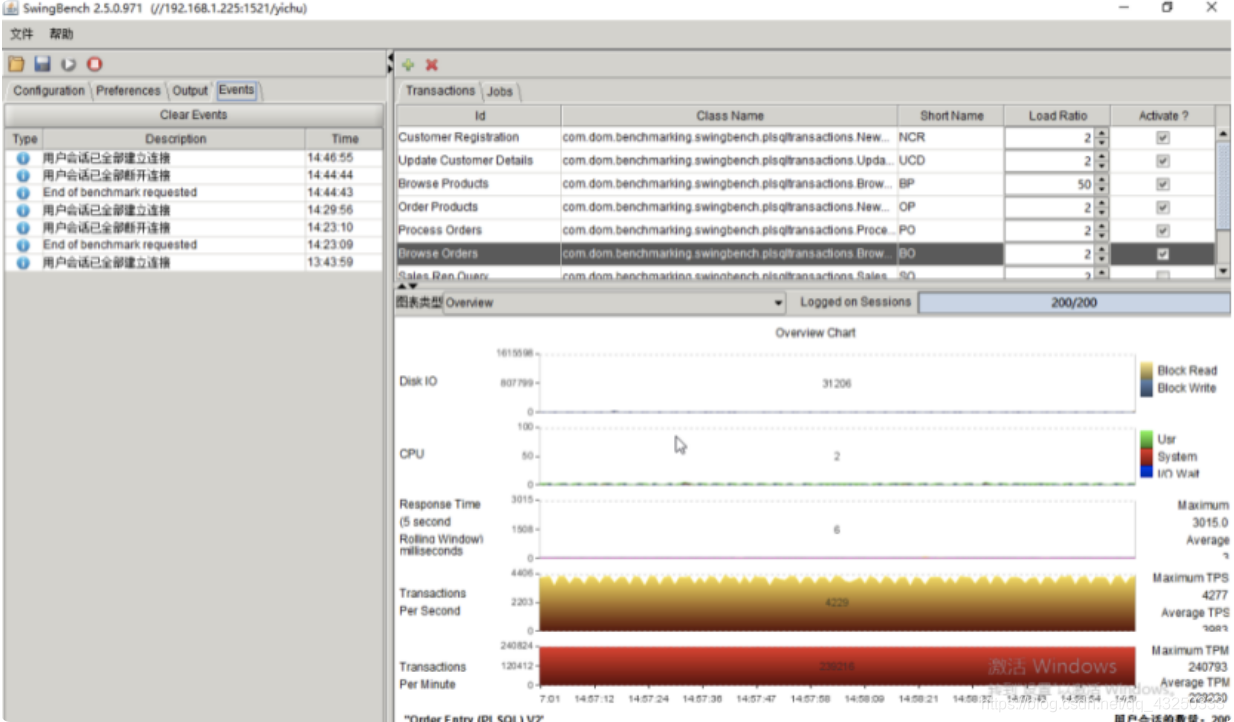
重新压测各项指标恢复正常,曲线也变得平滑














 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









