







oracle
参考网站(有用)
https://www.dofactory.com/sql/subquerysql语法
命令行方式启动Oracle
从任何cmd中以sys超级用户进入Oracle数据库
**sqlplus sys/sys as sysdba; **
展示目前用户名
show user;
换成普通用户登录
conn scott/tiger; **
查看当前用户下单表
** select * from tab; **
查看表结构
** desc 表名;
Oracle中group by用法
聚合函数
聚合函数只能单独出现或者下面有group by
group by问题:
select item.itemnum,item.in1,item.in4,inventory.location from item,inventory
where item.itemnum=inventory.itemnum
and inventory.location=‘DYB’
and item.in1=‘D/MTD/MRM’
GROUP BY ITEM.ITEMNUM
提示错误是NOT A GROUP BY EXPRESSION
答案:
GROUP BY 是分组查询, 一般 GROUP BY 是和 聚合函数配合使用,你可以想想
你用了GROUP BY 按 ITEM.ITEMNUM 这个字段分组,那其他字段内容不同,变成一对多又改如何显示呢,比如下面所示
A B
1 abc
1 bcd
1 asdfg
select A,B from table group by A
你说这样查出来是什么结果,
A B
abc
1 bcd
asdfg
右边3条如何变成一条,所以需要用到聚合函数,比如
select A,count(B) 数量 from table group by A
这样的结果就是
A 数量
1 3
group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面
在select 语句中可以使用group by 子句将行划分成较小的组,一旦使用分组后select操作的对象变为各个分组后的数据,使用聚合函数返回的是每一个组的汇总信息。
使用having子句 限制返回的结果集。group by 子句可以将查询结果分组,并返回行的汇总信息Oracle 按照group by 子句中指定的表达式的值分组查询结果。
在带有group by 子句的查询语句中,在select 列表中指定的列要么是group by 子句中指定的列,要么包含聚合函数 select max(sal),job emp group by job; (注意max(sal),job的job并非一定要出现,但有意义) 查询语句的select 和group by ,having 子句是聚合函数唯一出现的地方,在where 子句中不能使用聚合函数。
select deptno,sum(sal)
from emp where sal>1200
group by deptno
having sum(sal)>8500
order by deptno;
当在gropu by 子句中使用having 子句时,查询结果中只返回满足having条件的组。在一个sql语句中可以有where子句和having子句。having 与where 子句类似,均用于设置限定条件 where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚合函数,使用where条件显示特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚合函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
使用order by排序时order by子句置于group by 之后 并且 order by 子句的排序标准不能出现在select查询之外的列。
查询每个部门的每种职位的雇员数
select deptno,job,count(*) from emp group by deptno,job
/****
记住这就行了:
在使用group by 时,有一个规则需要遵守,即出现在select列表中的字段,如果没有在聚合函数中,那么必须出现在group by 子句中。(select中的字段不可以单独出现,必须出现在group语句中或者在组函数中。)
1.group by 前面的查询字段必须是group by后面的字段或者分组函数(类似count,sum,min,max等等)。
2.如果分组函数(类似count,sum,min,max等)和单个字段一起查询的时候,必须使用group by。
union联合查询
UNION 组合了两个查询的结果集。
两个查询中的列数据类型必须匹配。
按列位置而不是列名称组合。
子查询
子查询是查询中的 SQL 查询。
子查询是向封闭查询提供数据的嵌套查询。
子查询可以返回单个值或记录列表
子查询必须用括号括起来
没有固定语法:
下面是带in的方法
SELECT 列-名称
从表- name1
WHERE 值 IN ( SELECT 列-名称
从表- name2
WHERE 条件)
NULL 是一个特殊值,表示“无值”。
使用 = 运算符将列与 NULL 进行比较是undefined
相反,使用 WHERE IS NULL 或 WHERE IS NOT NULL。
排名函数rank()/dense_rank() over(order by XXX 顺序)

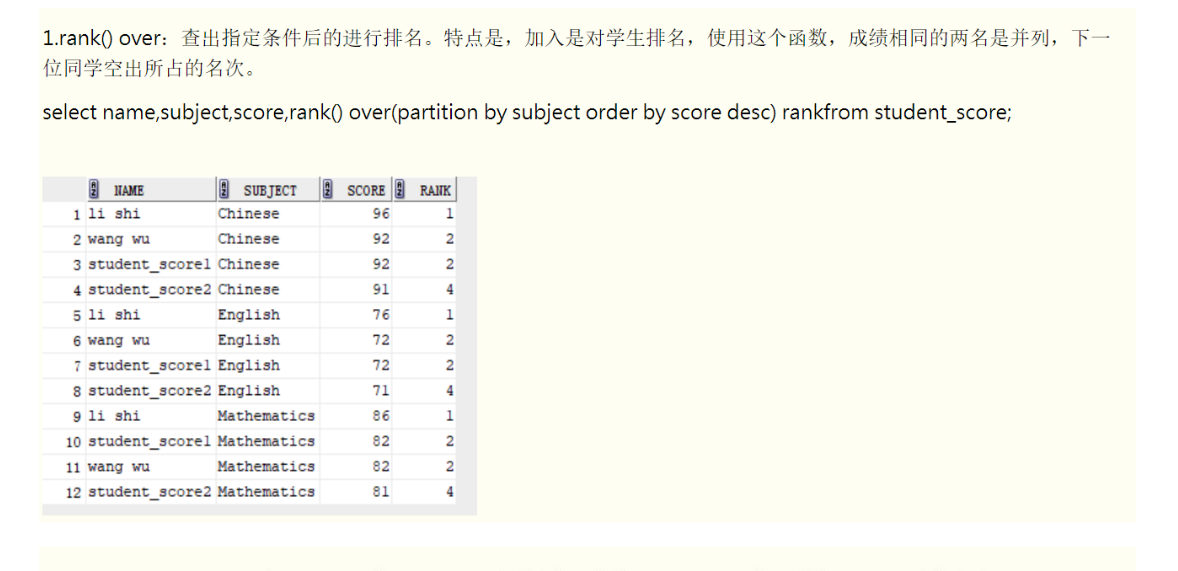

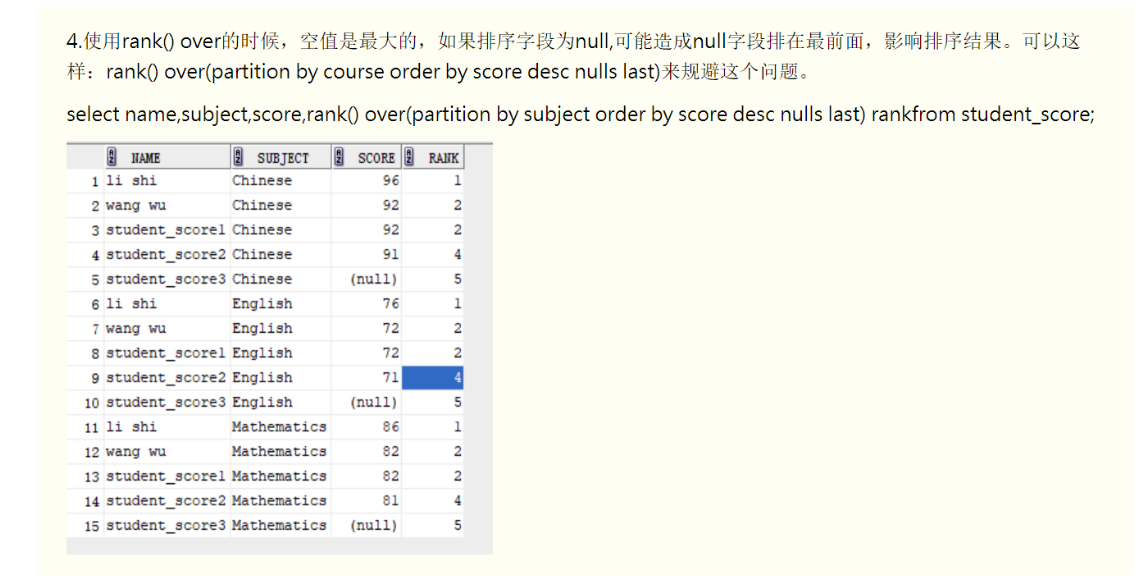
分析函数和聚合函数的不同之处:
分析函数和聚合函数很多是同名的,意思也一样,只是聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。简单的说就是聚合函数返回统计结果,分析函数返回明细加统计结果。
分析函数带有一个开窗函数over(),包含三个分析子句:
分组(partition by)
排序(order by)
窗口(rows)
前两个好理解,最后一个窗口则是表示分析函数的作用范围,默认范围是组内所有记录,即:
SUM(SAL) OVER(PARTITION BY E.DEPTNO
ORDER BY E.SAL)
相当于
SUM(SAL) OVER(PARTITION BY E.DEPTNO
ORDER BY E.SAL
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
其它表示范围的写法还有:
第一行至当前行:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
当前行至最后一行:
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
当前行的上一行(rownum-1)到当前行:
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
当前行的上一行(rownum-1)到当前行的下辆行(rownum+2):
ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING
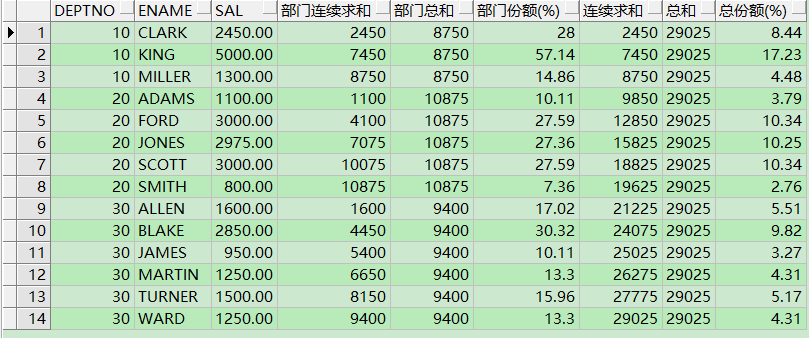
此外,over中条件不同,结果也不同,以sum函数求薪水之和为例,注意over(…)条件的不同:
sum(sal) over (partition by deptno order by ename) 按部门“连续”求总和
sum(sal) over (partition by deptno) 按部门求总和
sum(sal) over (order by deptno,ename) 不按部门“连续”求总和
sum(sal) over () 不按部门,求所有员工总和,效果等同于sum(sal)。
例句:
select deptno,
ename,
sal,
sum(sal) over(partition by deptno order by ename) 部门连续求和, --各部门的薪水"连续"求和
sum(sal) over(partition by deptno) 部门总和, -- 部门统计的总和,同一部门总和不变
100 * round(sal / sum(sal) over(partition by deptno), 4) "部门份额(%)",
sum(sal) over(order by deptno, ename) 连续求和, --所有部门的薪水"连续"求和
sum(sal) over() 总和, -- 此处sum(sal) over () 等同于sum(sal),所有员工的薪水总和
100 * round(sal / sum(sal) over(), 4) "总份额(%)"
from emp
这样的连续求和意义并不大,所以写over中的条件时应按需要决定是否需要order by语句,搞不好变成了画蛇添足了。其他函数也是如此,比如count函数,没有order by是正常的计数,有了order by变成连续计数,其结果和row_number是一样了。例如:
select deptno,
ename,
sal,
count(*) over(partition by deptno order by sal) rowcount,
row_number() over(partition by deptno order by sal) rownumb
from emp;
查询结果中rowcount和rownumb内容是相同的。
常用的分析函数如下所列:
row_number() over(partition by … order by …)
rank() over(partition by … order by …)
dense_rank() over(partition by … order by …)
count() over(partition by … order by …)
max() over(partition by … order by …)
min() over(partition by … order by …)
sum() over(partition by … order by …)
avg() over(partition by … order by …)
first_value() over(partition by … order by …)
last_value() over(partition by … order by …)
lag() over(partition by … order by …)
lead() over(partition by … order by …)
这些都是分析函数,基本上都是要带参数的,参数可以是字段名,也可以是字段名构成的表达式。
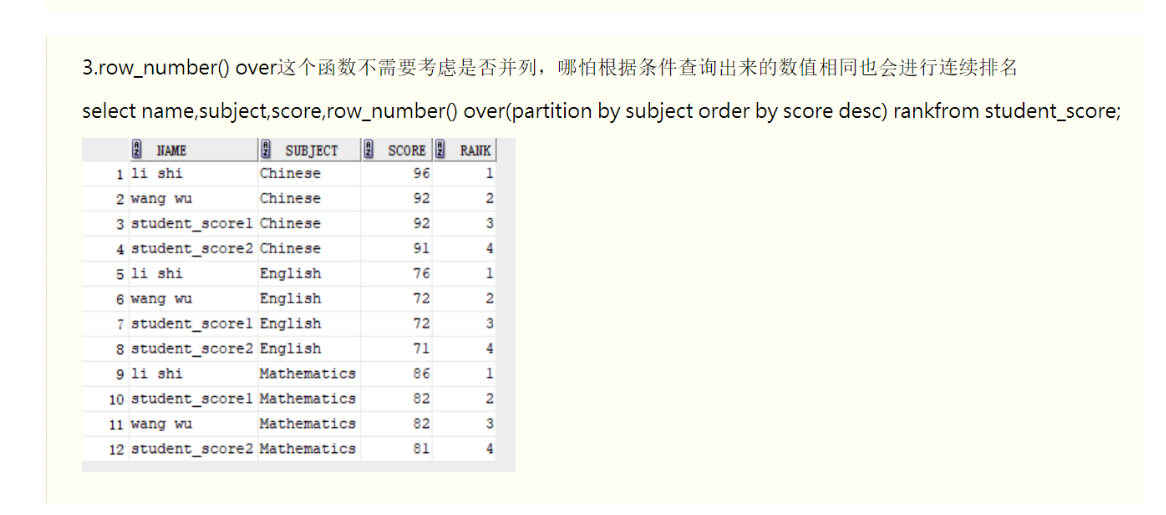
row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序)。
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)。
dense_rank()是连续排序,有两个第二名时仍然跟着第三名,相比之下row_number是没有重复值的
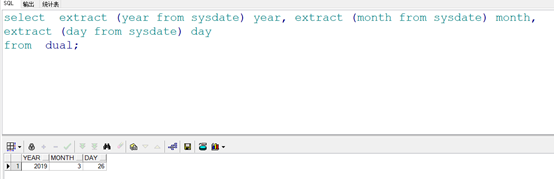
extract时间截取函数
oracle中extract()函数从oracle 9i中引入的,主要作用于一个date或者interval类型中截取特定的部分
extract()语法如下:
extract (
{ year | month | day | hour | minute | second | 某一时区 }
from { date类型值 | interval类型值} )
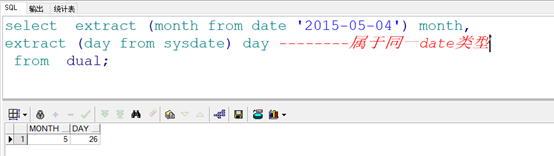
要点一:extract()只能从一个date类型中截取年月日
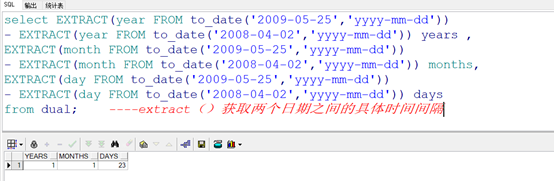
要点二:extract()获取两个日期之间的具体时间间隔
取别名
给列取别名
- 可以使用as 也可以不使用
- 不能使用单引号
- 可以使用双引号或者不使用
- 但是当别名中有特殊字符的时候,必须使用双引号
- 当别名是关键字的时候,也需要用双引号
在我们使用sql语句使用别名的时候,如果别名中包括如括号,运算符和引号之类的值的时候,操作数据的时候会出现错误,
如
select 1 as ABC(AB) from dual;–这样会报错。
select 1 as ABC-RH from dual;–这样会报错。
修改为如下的话,就可以解决:
select 1 as “ABC(AB)” from dual;–这样的不会报错。
此类的情况针对程序自动生成别名的情况下特别注意
给表取别名
如果是给表起别名需要去掉as关键字,而对列取别名关键字as可有可无,不能使用单引号和双引号
select * from (
select b.*,rownum as rn from(
select * from emp where empno in(
select mgr from emp group by mgr
) order by sal
)b
)c
where c.rn > 0 and c.rn < 5
下面根据代码说一些我出现的错误。
第一点:在命别名的时候需要清楚的明白,你查询出来的数据是作为子查询的条件还是作为一个表来使用,如果不清楚这一点,很可能就会在order by sal 的前面添加一个自命名的表名,而这时sql语句就会报错。在这里,第一步查询出来的数据是被用来做查询条件的,所以这里不能命别名,如果强制命别名的话还需要在其外部再嵌套一个查询,查询出来列当数据。写法如下,但是显得很多此一举。
select * from (
select b.*,rownum as rn from(
select * from emp where empno in(
select a.* from(
select mgr from emp group by mgr
)a
)order by sal
)b
)c
where c.rn > 0 and c.rn < 5
第二点:由于rownum只能取小于号,不能取大于号,所以还需要嵌套一层子循环,让rownum作为一个普通列后,再进行分页。结合题目根据查询结果来看,b,c别名前括号的内容都是作为一个表来使用,所以直接为其名别名即可。
总结
在命别名的时候需要清楚的明白,你查询出来的数据是作为子查询的条件还是作为一个表来使,作为表使用可以直接取别名,作为查询条件则不能取别名
exists
exists与子查询连用时,如果子查询有值的话,exists()括号中的查询结果将返回给主查询
exists 用于外表小的情况下。
外表大 而内表小 可以用in ,因为 exists 是先> > 循环外表。
外表小 的情况下可以用 exists.
用exists需要在where将内外表联系,in则不需要
(一)用Oracle Exists替换DISTINCT:
当提交一个包含一对多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT。一般能够考虑用Oracle EXIST替换,Oracle Exists使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立即返回结果。
例子:
SELECT DISTINCT DEPT_NO,DEPT_NAME FROM DEPT D,EMP E WHERE D.DEPT_NO = E.DEPT_NO;
SELECT DEPT_NO,DEPT_NAME FROM DEPT D WHERE Exists (SELECT ‘X' FROM EMP E WHERE E.DEPT_NO = D.DEPT_NO);
二)exists和in的效率问题:
使用EXISTS,Oracle会首先检查主查询,然后运行子查询直到它找到第一个匹配项,这就节省了时间。Oracle在执行IN子查询时,首先执行 子查询,并将获得的结果列表存放在一个加了索引的临时表中。在执行子查询之前,系统先将主查询挂起,待子查询执行完毕,存放在临时表中以后再执行主查询。 这也就是使用EXISTS比使用IN通常查询速度快的原因。
- select * from T1 where exists(select 1 from T2 where T1.a=T2.a) ;
- select * from T1 where T1.a in (select T2.a from T2) ;
T1数据量小而T2数据量非常大时,T1<
T1数据量非常大而T2数据量小时,T1>>T2 时,2) 的查询效率高。
1)Select name from employee where name not in (select name from student);
2)Select name from employee where not exists (select name from student);
第一句SQL语句的执行效率不如第二句。
二
例: select * from emp_tax;
1: 内表必须要和外表连接。
select *
from emp_tax o
where exists (select *
from emp_tax i
where i.empno = o.empno
and i.empno < 0005);
- exists 适合外表的结果集小的情况。因为exists是对外表作loop,每次loop再对那表进行查询。
当 exists 中的 where 后面条件为真的时候则把前面select 的内容显示出来(外表的select ).
Oracle exists 和 in 的真正区别
in 是把外表和那表作hash join,而exists是对外表作loop,每次loop再对那表进行查询。
这样的话,in适合内外表都很大的情况,exists适合外表结果集很小的情况。
START WITH
START WITH… CONNECT BY PRIOR…常见的用法,是用来遍历含有父子关系的表结构中。比如省市关系,一个省或者我,上级,上级的上级
rollup介绍:
group by后带rollup子句的功能可以理解为:先按一定的规则产生多种分组,然后按各种分组统计数据。(至于统计出的数据是求和还是最大值还是平均值等这就取决于SELECT后的聚合函数)。 oracle中rollup和mysql的差不多,但比mysql的强大(mysql只有下面的第1和第2使用方式),且oracle中rollup可以和order by一起使用。具体使用如下:
1)对比没有带rollup的goup by :
Group by A,B产生的分组种数:1种;
group by A,B
返回结果集:也就是这一种分组的结果集。
2)带rollup但group by与rollup之间没有任何内容 :
A、Group by rollup(A ,B) 产生的分组种数:3种;
第一种:group by A,B
第二种:group by A
第三种:group by NULL
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
B、Group by rollup(A ,B,C) 产生的分组种数:4种;
第一种:group by A,B,C
第二种:group by A,B
第三种:group by A
第四种:group by NULL
返回结果集:为以上四种分组统计结果集的并集且未去掉重复数据。
3)带rollup但groupby与rollup之间还包含有列信息
A、Group by A , rollup(A ,B) 产生的分组种数:3种;
第一种:group by A,A,B 等价于group by A,B
第二种:group by A,A 等价于group by A
第三种:group by A,NULL 等价于group by A
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
B、Group by C , rollup(A ,B) 产生的分组种数:3种;
第一种:group by C,A,B
第二种:group by C,A
第三种:group by C,NULL 等价于group by C
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
4)带rollup且rollup子句括号内又使用括号对列进行组合
A、Group by rollup((A ,B)) 产生的分组种数:2种;
第一种:group by A,B
第二种:group by NULL
返回结果集:为以上两种分组统计结果集的并集且未去掉重复数据。
B、Group by rollup(A ,(B,C)) 产生的分组种数:3种;
第一种:group by A,B,C
第二种:group by A
第三种:group by NULL
返回结果集:为以上三种分组统计结果集的并集且未去掉重复数据。
注:对这种情况,可以理解为几个列被括号括在一起时,就只能被看成一个整体,分组时不需要再细化。因此也可推断rollup括号内也顶多加到一重括号,加多重了应该没有任何意义(这个推断我没有做验证的哦)。
2、与rollup组合使用的其它几个辅助函数:
1)grouping()函数:
必须接受一列且只能接受一列做为其参数。参数列值为空返回1,参数列值非空返回0。(如果参数的列在rollup中,则返回1;否则返回0)
2)grouping_id()函数:
必须接受一列或多列做为其参数。返回值为按参数排列顺序,依次对各个参数使用grouping()函数,并将结果值依次串成一串二进制数然后再转化为十进制所得到的值。
例如:grouping(A) = 0 ;grouping(B) = 1;
则:grouping_id(A,B) = (01)2 = 1;
grouping_id(B,A)= (10)2 =2;
3)group_id()函数
调用时不需要且不能传入任何参数。返回值为某个特定的分组出现的重复次数(第一大点中的第3种情况中往往会产生重复的分组)。重复次数从0开始,例如某个分组第一次出现则返回值为0,第二次出现时返回值为1,……,第n次出现返回值为n-1。
注:使用以上三个函数往往是为了过滤掉一部分统计数据,而达到美化统计结果的作用。
3、cube和rollup区别:
带cube子句的groupby会产生更多的分组统计数据。cube后的列有多少种组合(注意组合是与顺序无关的)就会有多少种分组。
1)假设有n个维度,rollup会有n个聚合:
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c)统计列包含:(a,b,c)、(a,b)、(a)、()
……以此类推ing……
2)假设有n个纬度,cube会有2的n次方个聚合:
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、©、()
……以此类推ing……
引号问题
字符串需要加单引号,数字可以加单引号也可以不加单引号
列的别名最好不使用as且加上双引号,
表的别名就直接空格加别名,单/双引号都不加














 4971
4971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









