







Location
参数匹配模式
| 参数 | 匹配方式 | 匹配模式 | 说明 | 注意事项 |
|---|---|---|---|---|
= | 精准匹配 | 普通字符串匹配 | 用于标准uri前,要求请求字符串与uri精准匹配,成功则立即处理,nginx停止搜索其他匹配。 | |
~ | 正则匹配 | 正则表达式匹配 | 用于正则uri,表示uri包含正则表达式,并且区分大小写。 | 如果uri包含正则表达式,就必须要使用“~”或者“~*”标识。 |
~* | 正则表达式匹配 | 用于正则uri,表示uri包含正则表达式,并且不区分大小写。 | ||
^~ | 带参前缀匹配 (短路匹配) | 普通字符串匹配 | 用于标准uri前,并要求一旦匹配到就会立即处理,不再去匹配其他的正则URI,一般用来匹配目录。 | |
空 | 普通前缀匹配 | 普通字符串匹配 | location后没有参数直接跟着标准uri,表示前缀匹配,代表跟请求中的uri从头开始匹配。 |
参数匹配模式优先级
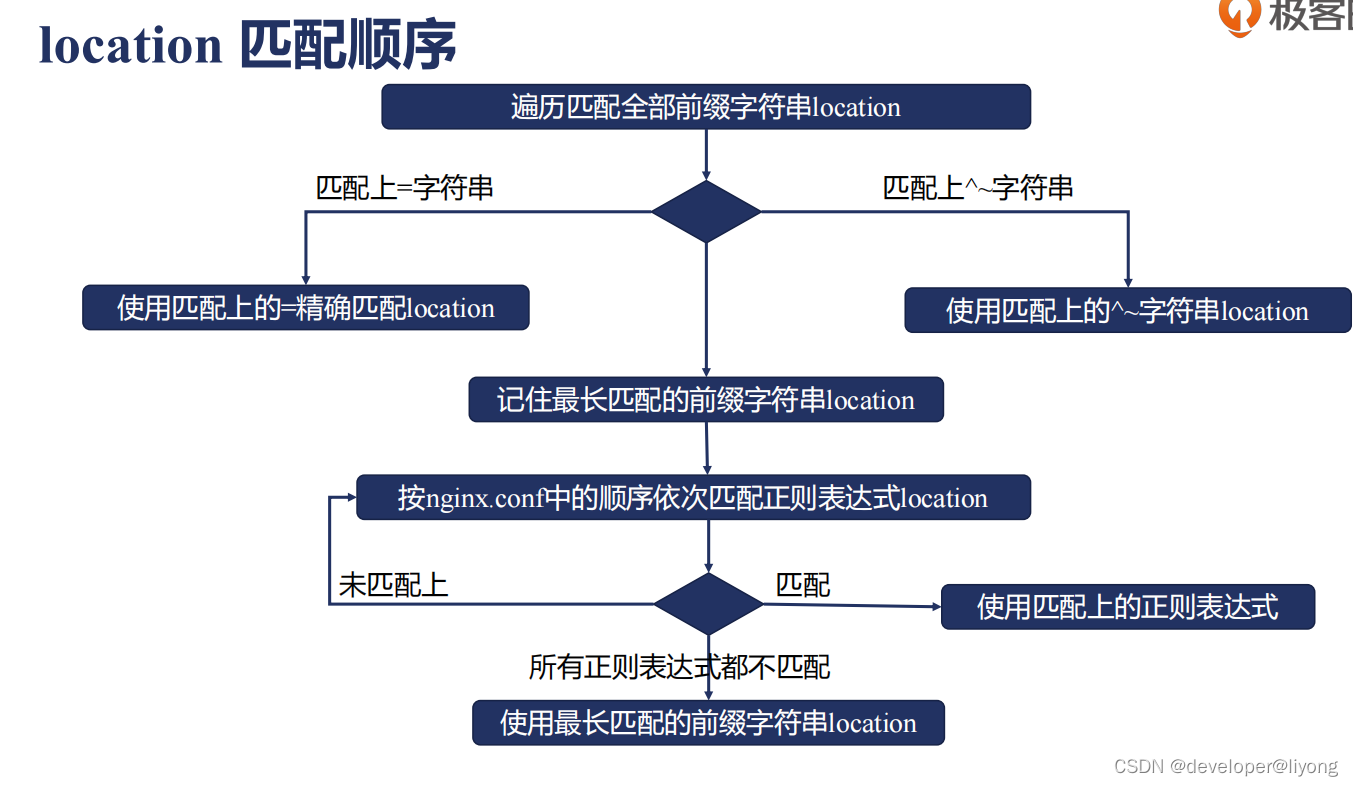
location 的匹配并不完全按照其在配置文件中出现的顺序来匹配,请求URI 会按如下规则进行匹配,优先级从高到低依次为(序号越小优先级越高):
1. location = # 精准匹配,精准匹配成功则会立即停止其他类型匹配;
2. location ^~ # 带参前缀匹配。如果是带有 ^~ 的前缀匹配,匹配成功则立即停止其他类型匹配;如果是普通前缀匹配(不带参数 ^~ )成功则会暂存,继续查找正则匹配;
3. location ~ # 正则匹配(区分大小写)。当同时有多个正则匹配时,按其在配置文件中出现的先后顺序优先匹配,命中则立即停止其他类型匹配;
4. location ~* # 正则匹配(不区分大小写)
5. location /a # 普通前缀匹配,优先级低于带参数前缀匹配。所有正则匹配均未成功时,返回步骤 2 中暂存的普通前缀匹配(不带参数 ^~ )结果。普通字符串匹配则无视顺序,只会选择最精确的匹配。
6. location / # 任何没有匹配成功的,都会匹配这里处理
| 表达式 | 说明 | |
|---|---|---|
| ^ | 匹配输入字符串的起始位置(以什么开头)。 | |
| $ | 匹配输入字符串的结束位置(以什么结尾)。 | |
| * | 匹配前面的字符零次或多次。 如"01*“能够匹配到"0”、“01”、“011”、“0111…”。 | |
| + | 匹配前面的字符一次或多次。 如"01*“能够匹配到"01”、“011”、“0111…”。 | |
| ? | 匹配前面字符零次或一次。 如01?只能能够匹配到"0"、“01”。 | |
| . | 匹配除”\n“之外的任意一个字符,若要匹配包括”\n“在内的任意字符则使用”[.\n]“之类的表达式 | .* |
| |转义符 | ||
| \d | 匹配出数字效果于[0-9]一致 | |
| \s | 空白符 | |
| \w | 任意单词字符包括下划线 | |
| {n} | 匹配前面表字符n次 | |
| {n,} | 匹配前面字符不少于n次 | |
| {n,m} | 匹配前面字符n到m次 | |
| [] | 定义匹配的字符范围 | |
| [c] | 匹配单个字符c | |
| [a-z] | 匹配a-z小写字母任意一个 | |
| [a-zA-Z0-9] | 匹配范围大小写字母及数字 | |
| () | 看成整体匹配 | |
| 或运算符 |
直接上案例
开始之前先介绍一个配置:
merge_slashes on | off; 默认是开启的也就是会合并// 为/ 提高匹配成功的概率,也就是容错
通用匹配
一般是兜底策略(待完善)
#如果兜底策略是 静态文件 这样是不行了 比如请求一个路径 /jj 会404 (why?)
location / {
root html;
index index.html index.htm;
}
# 如果是这样配置 则所有没有匹配上的路径最终都会返回402
location / {
return 402;
}
普通前缀匹配和通用匹配
1 在普通匹配里一定要注意这两个路径是不同的,如果是下面这样的配置:
http://127.0.0.1:8887/doc/aaa/ 可以匹配成功
http://127.0.0.1:8887/doc/aaa 会404
http://127.0.0.1:8887/Doc/aaa 也会匹配成功
location /doc/aaa/ {
return 401;
}
2 普通匹配遵循最长策略
location /document {
return 401;
}
location /doc {
return 402;
}
访问document docm docume 都会返回401
带参匹配
server {
listen 80;
server_name localhost;
location ^~ /doc {
return 401;
}
location ~* ^/document$ {
return 402;
}
}
如果没有其它的带参匹配,则带参匹配匹配成功后立即返回。如果还有其他带参匹配,则也是遵循最长匹配原则。
精准匹配
server {
listen 80;
server_name localhost;
location = / {
return 400;
}
location = /document {
return 401;
}
}
同理也是如果只有一个精准匹配则会立即返回,否则也是遵循最长原则。
优先级
location ~ /Test1/$ {
add_header Content-Type "text/plain";
return 200 'first regular expressions match!';
}
location ~* /Test1/(\w+)$ {
add_header Content-Type "text/plain";
return 200 'longest regular expressions match!';
}
location ^~ /Test1/ {
add_header Content-Type "text/plain";
return 200 'stop regular expressions match!';
}
location /Test1/Test2 {
add_header Content-Type "text/plain";
return 200 'longest prefix string match!';
}
location /Test1 {
add_header Content-Type "text/plain";
return 200 'prefix string match!';
}
location = /Test1 {
add_header Content-Type "text/plain";
return 200 'exact match!';
}
测试1:
访问: /Test1 返回值 ‘exact match!’ 因为精确匹配的优先级最高,匹配到了以后不会再向后匹配。
测试2:
访问: /Test1/ 这个时候精准匹配不上了所以按照优先级应该是去找正则匹配,由于我们配置了带参匹配^~ 这个匹配成功也会立即返回。结果为:‘stop regular expressions match!’
测试3:
访问:/Test1/Test2 ~* /Test1/(\w+)$ 由于我们配置正则表达式优先级更高,所以返回结果:‘longest regular expressions match!’
测试4:
访问:/Test1/Test2/ ~* /Test1/(\w+)$是严格以字母或数字结尾 所以正则匹配不上,走最长前缀匹配 ‘longest prefix string match!’ (\w:用于匹配字母,数字或下划线字符)
测试5:
访问:/test1/Test2 这个时候不区分大小写的正则表达式都匹配不上,因为要以字母或数字结尾,所以走普通匹配 返回 ‘longest prefix string match!’















 2396
2396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









