









准备
我使用hive建的表 之后也是在hive上的查询
create table student(
sid string,
sname string,
birth string,
sex string
)
row format delimited fields terminated by ‘ ’;
load data local inpath ‘/opt/datalx/hivedata/fiftystu.txt’ into table student;
01 赵雷 1990-01-01 男
02 钱电 1990-12-21 男
03 孙风 1990-05-20 男
04 李云 1990-08-06 男
05 周梅 1991-12-01 女
06 吴兰 1992-03-01 女
07 郑竹 1989-07-01 女
08 王菊 1990-01-20 女
create table course(
cid string,
cname string,
tid string
)
row format delimited fields terminated by ‘ ’;
01 语文 02
02 数学 01
03 英语 03
create table teacher(
tid string,
tname string
)
row format delimited fields terminated by ‘ ’;
01 张三
02 李四
03 王五
create table sc(
sid string,
cid string,
score int
)
row format delimited fields terminated by ‘ ’;
load data local inpath ‘/opt/datalx/hivedata/fiftystu.txt’ into table student
01 01 80
01 02 90
01 03 99
02 01 70
02 02 60
02 03 80
03 01 80
03 02 80
03 03 80
04 01 50
04 02 30
04 03 20
05 01 76
05 02 87
06 01 31
06 03 34
07 02 89
07 03 98
表结构

问题
– 1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数
– 2、查询"01"课程比"02"课程成绩低的学生的信息及课程分数
– 3、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
– 4、查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩
– (包括有成绩的和无成绩的)
– 5、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
– 6、查询"李"姓老师的数量
– 7、查询学过"张三"老师授课的同学的信息
– 8、查询没学过"张三"老师授课的同学的信息
– 9、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
– 10、查询学过编号为"01"但是没有学过编号为"02"的课程的同学的信息
– 11、查询没有学全所有课程的同学的信息
– 12、查询至少有一门课与学号为"01"的同学所学相同的同学的信息
– 13、查询和"01"号的同学学习的课程完全相同的其他同学的信息
– 14、查询没学过"张三"老师讲授的任一门课程的学生姓名
– 15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
– 16、检索"01"课程分数小于60,按分数降序排列的学生信息
– 17、按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
– 18.查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
–及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
– 19、按各科成绩进行排序,并显示排名(实现不完全)
– 20、查询学生的总成绩并进行排名
SELECT s_id , SUM(s_score) sum1 FROM score GROUP BY s_id ORDER BY sum1 DESC
– 21、查询不同老师所教不同课程平均分从高到低显示
– 22、查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
– 23、统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[0-60]及所占百分比
– 24、查询学生平均成绩及其名次
– 25、查询各科成绩前三名的记录
– 26、查询每门课程被选修的学生数
– 27、查询出只有两门课程的全部学生的学号和姓名
– 28、查询男生、女生人数
SELECT COUNT(*) FROM student WHERE s_sex = ‘男’
SELECT COUNT(s_sex) a FROM student WHERE s_sex = ‘女’
– 29、查询名字中含有"风"字的学生信息
– 30、查询同名同性学生名单,并统计同名人数
– 31、查询1990年出生的学生名单
– 32、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
– 33、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩
– 34、查询课程名称为"数学",且分数低于60的学生姓名和分数
– 35、查询所有学生的课程及分数情况;
– 36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数;
– 37、查询不及格的课程
–38、查询课程编号为01且课程成绩在80分以上的学生的学号和姓名;
– 39、求每门课程的学生人数
– 40、查询选修"张三"老师所授课程的学生中,成绩最高的学生信息及其成绩
– 41、查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
– 42、查询每门功成绩最好的前两名
– 43、统计每门课程的学生选修人数(超过5人的课程才统计)。要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
– 44、检索至少选修两门课程的学生学号
– 45、查询选修了全部课程的学生信息
–46、查询各学生的年龄
– 47、查询本周过生日的学生
– 48、查询下周过生日的学生
– 49、查询本月过生日的学生
– 50、查询下月过生日的学生
答案
– 1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数
#输出两个表后连接比较
select s.* from student s join
(
select a.* from
(select * from sc where cid=‘01’) a join
(select * from sc where cid=‘02’) b on a.sid=b.sid
where a.score>b.score)c
on s.sid=c.sid;

– 2、查询"01"课程比"02"课程成绩低的学生的信息及课程分数
select s.,c.score from student s join
(
select b. from
(select * from sc where cid=‘01’) a join
(select * from sc where cid=‘02’) b on a.sid=b.sid
where a.score<b.score)c
on s.sid=c.sid;
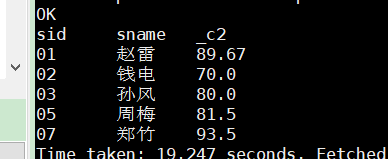
– 3、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩
1
select b1.sid,sname,avg from student s join
(select sid,round(avg(score),2) avg
from sc group by sid having avg(score)>=60) b1 on s.sid=b1.sid;
2
select sid,sname,round(avg,2) from
(select sid,sname,avg(score)over(partition by sid) avg
from (select sc.,sname from student s join sc on s.sid=sc.sid) b1) b2
group by sid,sname,avg having avg>60;
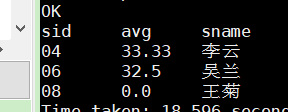
– 4、查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩
– (包括有成绩的和无成绩的)
select b2.,sname from
student s join
(select sid,round(avg(score),2) avg from
(select s.*,nvl(sc.score,0) score from student s left outer join sc on s.sid=sc.sid) b1
group by sid having avg(score)<60) b2
on s.sid =b2.sid;
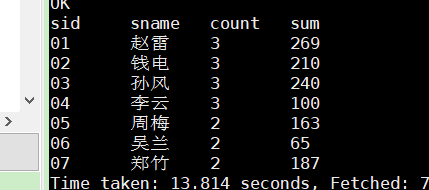
5.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
select b1.sid,sname,count,sum from
(select sid,count(cid) count,sum(score) sum from sc group by sid) b1
join
(select sid,sname from student) s
on b1.sid=s.sid
每天5题 请看后续博客















 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









