









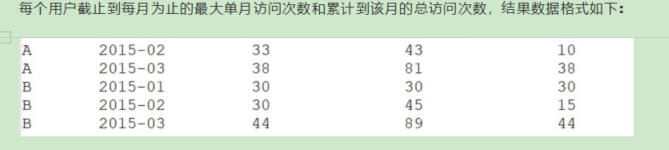
1.1.2 开窗 开窗的意义
数 据 : userid,month,visits A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
val spark = SparkSession
.builder
.master(“local”)
.appName(“test”)
//.enableHiveSupport()
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel(“WARN”)
import spark.implicits._
val df = spark.read.option(“header”, true).option(“inferschema”, “true”).csv(“in/sql/work1.1.2”)
df.show()
val w1 = Window.partitionBy(“userid”).orderBy(“month”)
val df1 = df.groupBy(“userid”,“month”).agg(sum(“visits”).alias(“visits”))
df1.select(
"
u
s
e
r
i
d
"
,
"userid",
"userid",“month”,$“visits”,max(“visits”).over(w1).alias(“maxvisit”),
sum(“visits”).over(w1).alias(“totalvisit”)).show()
1.1.4 selectexpr 处理
1 2019-07-11 1
1 2019-07-12 1
1 2019-07-13 1
1 2019-07-14 1
1 2019-07-15 1
1 2019-07-16 1
1 2019-07-17 1
1 2019-07-18 1
2 2019-07-11 1
2 2019-07-12 1
2 2019-07-13 0
2 2019-07-14 1
2 2019-07-15 1
2 2019-07-16 0
2 2019-07-17 1
2 2019-07-18 0
3 2019-07-11 1
3 2019-07-12 1
3 2019-07-13 1
3 2019-07-14 1
3 2019-07-15 1
3 2019-07-16 1
3 2019-07-17 1
3 2019-07-18 1

val df4: DataFrame = spark.read
.option(“header”, “true”)
.option(“inferschema”, “true”)
.csv(“in/sql/work1.1.4”)
df4.show()
df4.printSchema()
val w1: WindowSpec = Window.partitionBy(“uid”).orderBy(“dt”)
df4.where(“login_status==1”)
.selectExpr(
“uid”,
“dt”,
“row_number()over(distribute by uid order by dt) as rank”
)
// .select(
"
u
i
d
"
,
"uid",
"uid",“dt”,row_number().over(w1).alias(“rank”))
.selectExpr(
“uid”,
“date_sub(dt,rank) as dt”
).groupBy(“uid”,“dt”).agg(count(“dt”).alias(“count”))
.selectExpr(“uid”,“count”)
.where($“count”>6)
.show()
1.1.6 用dsl写 不用写临时表名
1 1901 90
2 1901 90
3 1901 83
4 1901 60
5 1902 66
6 1902 23
7 1902 99
8 1902 67
9 1902 87


编写sql语句实现每班前三名,分数一样并列,同时求出前三名按名次排序的一次的分差
val df6: DataFrame = spark.read
.option(“header”, “true”)
.option(“inferschema”, “true”)
.csv(“in/sql/work1.1.6”)
df6.show()
df6.printSchema()
df6.selectExpr(
“class”,
“score”,
“dense_rank()over(distribute by class order by score desc) as dense”,
“row_number()over(distribute by class order by score desc) as dense1”
).where(“dense1<=3”)
.selectExpr(
“class”,
“score”,
“dense”,
//todo 形式写错了就会找不到函数
“score-nvl(lag(score)over(distribute by class order by dense1),0) as difference”
)
.show()
行转列
val lst = List(
(“a”, “b”, 2),
(“a”, “b”, 1),
(“a”, “b”, 3),
(“c”, “d”, 6),
(“c”, “d”, 8),
(“c”, “d”, 8))
val df1 = spark.createDataFrame(lst).toDF(“id”, “tag”, “flag”)
//df1.printSchema()
df1.groupBy(“id”, “tag”)
.agg(concat_ws("|", collect_set(“flag”)) as “flag”)
.show
spark.stop()
1.2.10 行转列 增列
t1表:
用户 商品
A P1
B P1
A P2
B P3
请你使用hql变成如下结果:
用户 P1 P2 P3
A 1 1 0
B 1 0 1
withColumn
when otherwise
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
object work1 {
def main(args: Array[String]): Unit = {
val spark=SparkSession
.builder()
.appName(“dsl1”)
.master(“local[*]”)
.getOrCreate()
spark.sparkContext.setLogLevel(“warn”)
import spark.implicits._
val df: DataFrame = spark.read
.option("inferschema","true")
.option("delimiter"," ")
.csv("in/sql/work1")
.withColumnRenamed("_c0","user")
.withColumnRenamed("_c1","goods")
df.printSchema()
df.createOrReplaceTempView("t1")
// spark.sql(" select user,sum(case when goods=‘P1’ then 1 else 0 end) as P1,sum(case when goods=‘P2’ then 1 else 0 end) as P2,sum(case when goods=‘P3’ then 1 else 0 end) as P3 from t1 group by user").show()
df.withColumn("P1",when($"goods"==="P1",1)otherwise(0))
.withColumn("P2",when($"goods"==="P2",1)otherwise(0))
.withColumn("P3",when($"goods"==="P3",1)otherwise(0))
.groupBy("user")
.agg(
sum("P1"),sum("P2"),sum("P3")
)
.show()
}
}
1.2.11 行转列 增列
t1表:
name course score
aa English 75
bb math 85
aa math 90
使用hql输出以下结果
name English math
aa 75 90
bb 0 85
pivot agg
nvl selectexpr
import org.apache.spark.sql.catalyst.expressions.CaseWhen
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
object work2 {
def main(args: Array[String]): Unit = {
val spark=SparkSession
.builder()
.appName(“dsl1”)
.master(“local[*]”)
.getOrCreate()
spark.sparkContext.setLogLevel(“warn”)
import spark.implicits._
val df: DataFrame = spark.read
.option("header","true")
.option("inferschema","true")
.option("delimiter"," ")
.csv("in/sql/work2")
df.printSchema()
df.show()
df.groupBy("name").pivot("course")
.agg(sum("score"))
.selectExpr("name","nvl(English,'0') as English","math")
.show()
/* df.withColumn(“English”,when(
"
c
o
u
r
s
e
"
=
=
=
"
E
n
g
l
i
s
h
"
,
"course"==="English",
"course"==="English",“score”)otherwise(0))
.withColumn(“math”,when(
"
c
o
u
r
s
e
"
=
=
=
"
m
a
t
h
"
,
"course"==="math",
"course"==="math",“score”)otherwise(0))
.groupBy(“name”)
.agg(
sum(“English”) as “English”,sum(“math”)as “Math”
)
.show()*/
}
}















 1655
1655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









