







前言
一个本硕双非的小菜鸡,备战24年秋招。打算尝试6.S081,将它的Lab逐一实现,并记录期间心酸历程。
代码下载
官方网站:6.S081官方网站
安装方式:
通过 APT 安装 (Debian/Ubuntu)
确保你的 debian 版本运行的是 “bullseye” 或 “sid”(在 ubuntu 上,这可以通过运行 cat /etc/debian_version 来检查),然后运行:
sudo apt-get install git build-essential gdb-multiarch qemu-system-misc gcc-riscv64-linux-gnu binutils-riscv64-linux-gnu
(“buster”上的 QEMU 版本太旧了,所以你必须单独获取。
qemu-system-misc 修复
此时此刻,似乎软件包 qemu-system-misc 收到了一个更新,该更新破坏了它与我们内核的兼容性。如果运行 make qemu 并且脚本在 qemu-system-riscv64 -machine virt -bios none -kernel/kernel -m 128M -smp 3 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0 之后出现挂起
,
则需要卸载该软件包并安装旧版本:
$ sudo apt-get remove qemu-system-misc
$ sudo apt-get install qemu-system-misc=1:4.2-3ubuntu6
在 Arch 上安装
sudo pacman -S riscv64-linux-gnu-binutils riscv64-linux-gnu-gcc riscv64-linux-gnu-gdb qemu-arch-extra
测试您的安装
若要测试安装,应能够检查以下内容:
$ riscv64-unknown-elf-gcc --version
riscv64-unknown-elf-gcc (GCC) 10.1.0
...
$ qemu-system-riscv64 --version
QEMU emulator version 5.1.0
您还应该能够编译并运行 xv6: 要退出 qemu,请键入:Ctrl-a x。
# in the xv6 directory
$ make qemu
# ... lots of output ...
init: starting sh
$
在本实验中,您将获得重新设计代码以提高并行性的经验。多核机器上并行性差的一个常见症状是频繁的锁争用。提高并行性通常涉及更改数据结构和锁定策略以减少争用。您将对xv6内存分配器和块缓存执行此操作。
切换分支执行操作
git stash
git fetch
git checkout fs
make clean
一、Large files(moderate)
在本作业中,您将增加xv6文件的最大大小。目前,xv6文件限制为268个块或268*BSIZE字节(在xv6中BSIZE为1024)。此限制来自以下事实:一个xv6 inode包含12个“直接”块号和一个“间接”块号,“一级间接”块指一个最多可容纳256个块号的块,总共12+256=268个块。
bigfile命令可以创建最长的文件,并报告其大小:
$ bigfile
..
wrote 268 blocks
bigfile: file is too small
$
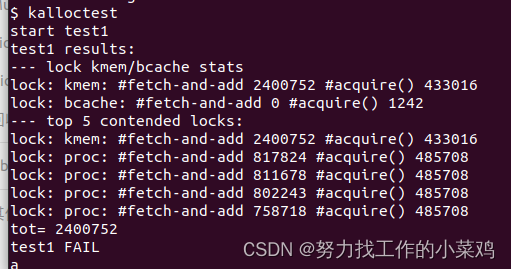
测试失败,因为bigfile希望能够创建一个包含65803个块的文件,但未修改的xv6将文件限制为268个块。
您将更改xv6文件系统代码,以支持每个inode中可包含256个一级间接块地址的“二级间接”块,每个一级间接块最多可以包含256个数据块地址。结果将是一个文件将能够包含多达65803个块,或256*256+256+11个块(11而不是12,因为我们将为二级间接块牺牲一个直接块号)。
mkfs程序创建xv6文件系统磁盘映像,并确定文件系统的总块数;此大小由kernel/param.h中的FSSIZE控制。您将看到,该实验室存储库中的FSSIZE设置为200000个块。您应该在make输出中看到来自mkfs/mkfs的以下输出:
nmeta 70 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 25) blocks 199930 total 200000
这一行描述了mkfs/mkfs构建的文件系统:它有70个元数据块(用于描述文件系统的块)和199930个数据块,总计200000个块。
如果在实验期间的任何时候,您发现自己必须从头开始重建文件系统,您可以运行make clean,强制make重建fs.img。
磁盘索引节点的格式由fs.h中的struct dinode定义。您应当尤其对NDIRECT、NINDIRECT、MAXFILE和struct dinode的addrs[]元素感兴趣。查看《XV6手册》中的图8.3,了解标准xv6索引结点的示意图。
在磁盘上查找文件数据的代码位于fs.c的bmap()中。看看它,确保你明白它在做什么。在读取和写入文件时都会调用bmap()。写入时,bmap()会根据需要分配新块以保存文件内容,如果需要,还会分配间接块以保存块地址。
bmap()处理两种类型的块编号。bn参数是一个“逻辑块号”——文件中相对于文件开头的块号。ip->addrs[]中的块号和bread()的参数都是磁盘块号。您可以将bmap()视为将文件的逻辑块号映射到磁盘块号。
修改bmap(),以便除了直接块和一级间接块之外,它还实现二级间接块。你只需要有11个直接块,而不是12个,为你的新的二级间接块腾出空间;不允许更改磁盘inode的大小。ip->addrs[]的前11个元素应该是直接块;第12个应该是一个一级间接块(与当前的一样);13号应该是你的新二级间接块。当bigfile写入65803个块并成功运行usertests时,此练习完成:
$ bigfile
...............................................................................................
wrote 65803 blocks
done; ok
$ usertests
...
ALL TESTS PASSED
$
运行bigfile至少需要一分钟半的时间。
提示:
- 确保您理解bmap()。写出ip->addrs[]、间接块、二级间接块和它所指向的一级间接块以及数据块之间的关系图。确保您理解为什么添加二级间接块会将最大文件大小增加256*256个块(实际上要-1,因为您必须将直接块的数量减少一个)。
- 考虑如何使用逻辑块号索引二级间接块及其指向的间接块。
- 如果更改NDIRECT的定义,则可能必须更改file.h文件中struct inode中addrs[]的声明。确保struct inode和struct dinode在其addrs[]数组中具有相同数量的元素。
- 如果更改NDIRECT的定义,请确保创建一个新的fs.img,因为mkfs使用NDIRECT构建文件系统。
- 如果您的文件系统进入坏状态,可能是由于崩溃,请删除fs.img(从Unix而不是xv6执行此操作)。make将为您构建一个新的干净文件系统映像。
- 别忘了把你bread()的每一个块都brelse()。
- 您应该仅根据需要分配间接块和二级间接块,就像原始的bmap()。
- 确保itrunc释放文件的所有块,包括二级间接块。
解析
按人家的要求来,首先对索引节点进行操作
正常来说是这样的

现在应该是这样的

首先需要调整inode原有的一些参数,比如NDIRECT, NINDIRECT, MAXFILE,添加宏定义,改成需要的大小。直接块修改为11,最大值改为11+256+256×256,然后把inode的地址块改为直接块+单间接块+双间接块。
//kernel/fs.h
#define NDIRECT 11
#define NINDIRECT (BSIZE / sizeof(uint))
#define NDINDIRECT ((BSIZE / sizeof(uint)) * (BSIZE / sizeof(uint)))
#define MAXFILE (NDIRECT + NINDIRECT + NDINDIRECT)
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+2]; // Data block addresses
};
file.h也需要修改
//kernel/file.h
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+2];
};
然后修改bmap,以期支持二级索引()
//kernel/fs.c
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
if(bn < NDIRECT){
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn]) == 0){
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
bn -= NINDIRECT;
if(bn < NDINDIRECT) {
if((addr = ip->addrs[NDIRECT + 1]) == 0)
ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn / NINDIRECT]) == 0){
a[bn / NINDIRECT] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn % NINDIRECT]) == 0){
a[bn % NINDIRECT] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
panic("bmap: out of range");
}
最后修改itrunc释放所有块
//kernel/fs.c
// Truncate inode (discard contents).
// Caller must hold ip->lock.
void
itrunc(struct inode *ip)
{
int i, j;
struct buf *bp, *bp2;
uint *a, *a2;
for(i = 0; i < NDIRECT; i++){
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
if(ip->addrs[NDIRECT]){ //如果有一级间接块
bp = bread(ip->dev, ip->addrs[NDIRECT]); //读取ip对应设备拥有的间接块信息,返回到缓冲区
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
if(ip->addrs[NDIRECT + 1]){ //如果有二级间接块
bp = bread(ip->dev, ip->addrs[NDIRECT + 1]);
a = (uint*)bp->data;
for(i = 0; i < NINDIRECT; i++) {
if(a[i]) {
bp2 = bread(ip->dev, a[i]);
a2 = (uint*)bp2->data;
for(j = 0; j < NINDIRECT; j++) {
if(a2[j]) {
bfree(ip->dev, a2[j]);
}
}
brelse(bp2);
bfree(ip->dev, a[i]);
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT + 1]);
ip->addrs[NDIRECT + 1] = 0;
}
ip->size = 0;
iupdate(ip);// 把内存的inode信息更新到disk中
}
没啥问题

二、Symbolic links(moderate)
在本练习中,您将向xv6添加符号链接。符号链接(或软链接)是指按路径名链接的文件;当一个符号链接打开时,内核跟随该链接指向引用的文件。符号链接类似于硬链接,但硬链接仅限于指向同一磁盘上的文件,而符号链接可以跨磁盘设备。尽管xv6不支持多个设备,但实现此系统调用是了解路径名查找工作原理的一个很好的练习。
您将实现symlink(char *target, char *path)系统调用,该调用在引用由target命名的文件的路径处创建一个新的符号链接。有关更多信息,请参阅symlink手册页(注:执行man symlink)。要进行测试,请将symlinktest添加到Makefile并运行它。当测试产生以下输出(包括usertests运行成功)时,您就完成本作业了。
$ symlinktest
Start: test symlinks
test symlinks: ok
Start: test concurrent symlinks
test concurrent symlinks: ok
$ usertests
...
ALL TESTS PASSED
$
提示:
- 首先,为symlink创建一个新的系统调用号,在user/usys.pl、user/user.h中添加一个条目,并在kernel/sysfile.c中实现一个空的sys_symlink。
- 向kernel/stat.h添加新的文件类型(T_SYMLINK)以表示符号链接。
- 在kernel/fcntl.h中添加一个新标志(O_NOFOLLOW),该标志可用于open系统调用。请注意,传递给open的标志使用按位或运算符组合,因此新标志不应与任何现有标志重叠。一旦将user/symlinktest.c添加到Makefile中,您就可以编译它。
- 实现symlink(target, path)系统调用,以在path处创建一个新的指向target的符号链接。请注意,系统调用的成功不需要target已经存在。您需要选择存储符号链接目标路径的位置,例如在inode的数据块中。symlink应返回一个表示成功(0)或失败(-1)的整数,类似于link和unlink。
- 修改open系统调用以处理路径指向符号链接的情况。如果文件不存在,则打开必须失败。当进程向open传递O_NOFOLLOW标志时,open应打开符号链接(而不是跟随符号链接)。
- 如果链接文件也是符号链接,则必须递归地跟随它,直到到达非链接文件为止。如果链接形成循环,则必须返回错误代码。你可以通过以下方式估算存在循环:通过在链接深度达到某个阈值(例如10)时返回错误代码。
- 其他系统调用(如link和unlink)不得跟随符号链接;这些系统调用对符号链接本身进行操作。
- 您不必处理指向此实验的目录的符号链接
解析:
首先先在三小只里把symlink添加进去,老套路了
//user/user.h
int symlink(char *target, char *path);
//user/usys.pl
entry("symlink");
//makefile里面添加 symlinktest
。。。
$U/_wc\
$U/_zombie\
$U/_symlinktest\
。。。
然后按着提示接着添加新类型和新字段
//kernel/stat.h
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEVICE 3 // Device
#define T_SYMLINK 4 // Symlink
//kernel/fcntl.h
#define O_RDONLY 0x000
#define O_WRONLY 0x001
#define O_RDWR 0x002
#define O_CREATE 0x200
#define O_TRUNC 0x400
#define O_NOFOLLOW 0x010
在kernel/sysfile.c实现sys_symlink,通过使用create,writei,readi实现
iunlockput既对inode解锁,还将其引用计数减1,计数为0时回收此inode
//kernel/syscall.h
#define SYS_symlink 22
//kernel/sysfile.c
uint64
sys_symlink(void) {
char target[MAXPATH], path[MAXPATH];
struct inode* ip_path;
//将target和path这两个参数从寄存器中读出来
if(argstr(0, target, MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0)
return -1;
// 开始一个新的操作
begin_op();
// 分配一个inode结点,使用create函数创建inode
// path 是符号链接的路径,T_SYMLINK 表示创建的是一个符号链接类型,后两个参数(0, 0)可能是创建文件时的权限和属性
ip_path = create(path, T_SYMLINK, 0, 0);
if (ip_path == 0) {
end_op();
return -1;
}
// 向inode数据块中写入target路径,使用writei函数
// 注意,这里如果操作失败了,需要将这个inode的锁给解开了
if (writei(ip_path, 0, (uint64)target, 0, MAXPATH) < MAXPATH) {
iunlockput(ip_path);
end_op();
return -1;
}
iunlockput(ip_path);
end_op();
return 0;
}
修改sys_open函数,支持打开符号链接
//kernel/sysfile.c
void
binit(void)
{
struct buf *b;
char lockname[16];
for (int i = 0; i < NBUCKET; i++) {
// 初始化散列桶的自旋锁
snprintf(lockname, sizeof(lockname), "bcache_%d", i);
initlock(&bcache.buckets[i].lock, lockname);
// 初始化散列桶的头节点
bcache.buckets[i].head.prev = &bcache.buckets[i].head;
bcache.buckets[i].head.next = &bcache.buckets[i].head;
}
// Create linked list of buffers
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.buckets[0].head.next;
b->prev = &bcache.buckets[0].head;
initsleeplock(&b->lock, "buffer");
bcache.buckets[0].head.next->prev = b;
bcache.buckets[0].head.next = b;
}
}
符号链接的创建也是很有难度的。

总结
这个实验重在理解文件系统的结构,然后改写了inode的数据块索引,编写了软链接的系统调用,总的来说难度还是有的,需要对整体内容做深刻把握。
















 1977
1977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











