







Lab 9: file system
- Lab Guide: https://pdos.csail.mit.edu/6.828/2020/labs/fs.html
- Lab Code: https://github.com/peakcrosser7/xv6-labs-2020/tree/fs
Large files (moderate)
要点
- 实现二级间接块索引(doubly-indirect block)的 inode 结构:
ip->addrs[]的前 11 个元素是直接块(direct block), 第 12 个元素是一个一级间接块索引(singly-indirect block), 第 13 个元素是一个二级间接块索引(doubly-indirect block). - 修改
bmap()函数以适配 double-indirect block
步骤
- 修改
kernel/fs.h中的直接块号的宏定义NDIRECT为 11.
根据实验要求, inode 中原本 12 个直接块号被修改为 了 11 个.
#define NDIRECT 11 // lab9-1
- 修改 inode 相关结构体的块号数组. 具体包括
kernel/fs.h中的磁盘 inode 结构体struct dinode的addrs字段; 和kernel/file.h中的内存 inode 结构体struct inode的addrs字段. 将二者数组大小设置为NDIRECT+2, 因为实际 inode 的块号总数没有改变, 但NDIRECT减少了 1.
// On-disk inode structure
struct dinode {
// ...
uint addrs[NDIRECT+2]; // Data block addresses // lab9-1
};
// in-memory copy of an inode
struct inode {
// ...
uint addrs[NDIRECT+2]; // lab9-1
};
- 在
kernel/fs.h中添加宏定义NDOUBLYINDIRECT, 表示二级间接块号的总数, 类比NINDIRECT. 由于是二级, 因此能够表示的块号应该为一级间接块号NINDIRECT的平方.
#define NDOUBLYINDIRECT (NINDIRECT * NINDIRECT) // lab9-1
- 修改
kernel/fs.c中的bmap()函数.
该函数用于返回 inode 的相对块号对应的磁盘中的块号.
由于 inode 结构中前NDIRECT个块号与修改前是一致的, 因此只需要添加对第NDIRECT即 13 个块的二级间接索引的处理代码. 处理的方法与处理第NDIRECT个块号即一级间接块号的方法是类似的, 只是需要索引两次.
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
if(bn < NDIRECT){
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[bn]) == 0){
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
// doubly-indirect block - lab9-1
bn -= NINDIRECT;
if(bn < NDOUBLYINDIRECT) {
// get the address of doubly-indirect block
if((addr = ip->addrs[NDIRECT + 1]) == 0) {
ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev);
}
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
// get the address of singly-indirect block
if((addr = a[bn / NINDIRECT]) == 0) {
a[bn / NINDIRECT] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
bn %= NINDIRECT;
// get the address of direct block
if((addr = a[bn]) == 0) {
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
panic("bmap: out of range");
}
- 修改
kernel/fs.c中的itrunc()函数.
该函数用于释放 inode 的数据块.
由于添加了二级间接块的结构, 因此也需要添加对该部分的块的释放的代码. 释放的方式同一级间接块号的结构, 只需要两重循环去分别遍历二级间接块以及其中的一级间接块.
void
itrunc(struct inode *ip)
{
int i, j, k; // lab9-1
struct buf *bp, *bp2; // lab9-1
uint *a, *a2; // lab9-1
for(i = 0; i < NDIRECT; i++){
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
if(ip->addrs[NDIRECT]){
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
// free the doubly-indirect block - lab9-1
if(ip->addrs[NDIRECT + 1]) {
bp = bread(ip->dev, ip->addrs[NDIRECT + 1]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; ++j) {
if(a[j]) {
bp2 = bread(ip->dev, a[j]);
a2 = (uint*)bp2->data;
for(k = 0; k < NINDIRECT; ++k) {
if(a2[k]) {
bfree(ip->dev, a2[k]);
}
}
brelse(bp2);
bfree(ip->dev, a[j]);
a[j] = 0;
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT + 1]);
ip->addrs[NDIRECT + 1] = 0;
}
ip->size = 0;
iupdate(ip);
}
- 修改
kernel/fs.h中的文件最大大小的宏定义MAXFILE. 由于添加了二级间接块的结构, xv6 支持的文件大小的上限自然增大, 此处要修改为正确的值.
#define MAXFILE (NDIRECT + NINDIRECT + NDOUBLYINDIRECT) // lab9-1
遇到问题
- 在 xv6 中执行
bigfile通过, 但执行usertests出现virtio_disk_intr status的 panic, 如下图所示:

解决: 该 panic 的具体出现原因笔者不是很清楚, 但开始时笔者未修改NDIRECT为 11, 而是保持 12, 但在bmap()和itrunc()中修改. 但将NDIRECT修改为 11 后, 便不再有该 panic.
测试
- 在 xv6 中执行
bigfile:

- 在 xv6 中执行
usertests:

./grade-lab-fs bigfile单项测试:

Symbolic links (moderate)
要点
- 添加符号链接(软链接)的系统调用
symlink - 修改
open系统调用处理符号链接的情况, 且符号链接的目标文件仍是符号链接文件时需要递归查找目标文件. - 以
O_NOFOLLOW打开符号链接不会跟踪到链接的文件. - 其它系统调用不会跟踪符号链接, 之后处理符号链接文件本身.
步骤
-
添加有关
symlink系统调用的定义声明. 包括kernel/syscall.h,kernel/syscall.c,user/usys.pl和user/user.h.
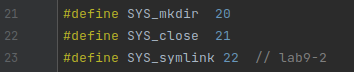




-
添加新的文件类型
T_SYMLINK到kernel/stat.h中.

-
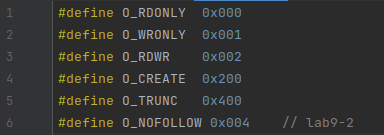
添加新的文件标志位
O_NOFOLLOW到kernel/fcntl.h中.
-
在
kernel/sysfile.c中实现sys_symlink()函数.
该函数即用来生成符号链接. 符号链接相当于一个特殊的独立的文件, 其中存储的数据即目标文件的路径.
因此在该函数中, 首先通过create()创建符号链接路径对应的 inode 结构(同时使用T_SYMLINK与普通的文件进行区分). 然后再通过writei()将链接的目标文件的路径写入 inode (的 block)中即可. 在这个过程中, 无需判断连接的目标路径是否有效.
需要注意的是关于文件系统的一些加锁释放的规则. 函数create()会返回创建的 inode, 此时也会持有其 inode 的锁. 而后续writei()是需要在持锁的情况下才能写入. 在结束操作后(不论成功与否), 都需要调用iunlockput()来释放 inode 的锁和其本身, 该函数是iunlock()和iput()的组合, 前者即释放 inode 的锁; 而后者是减少一个 inode 的引用(对应字段ref, 记录着内存中指向该 inode 的指针数, 这里的 inode 实际上是内存中的 inode, 是从内存的 inode 缓存icache分配出来的, 当ref为 0 时就会回收到icache中), 表示当前已经不需要持有该 inode 的指针对其继续操作了.
// lab9-2
uint64 sys_symlink(void) {
char target[MAXPATH], path[MAXPATH];
struct inode *ip;
int n;
if ((n = argstr(0, target, MAXPATH)) < 0
|| argstr(1, path, MAXPATH) < 0) {
return -1;
}
begin_op();
// create the symlink's inode
if((ip = create(path, T_SYMLINK, 0, 0)) == 0) {
end_op();
return -1;
}
// write the target path to the inode
if(writei(ip, 0, (uint64)target, 0, n) != n) {
iunlockput(ip);
end_op();
return -1;
}
iunlockput(ip);
end_op();
return 0;
}
- 修改
kernel/sysfile的sys_open()函数.
该函数使用来打开文件的, 对于符号链接一般情况下需要打开的是其链接的目标文件, 因此需要对符号链接文件进行额外处理.
考虑到跟踪符号链接的操作相对独立, 此处笔者编写了一个独立的函数follow_symlink()用来寻找符号链接的目标文件.
在跟踪符号链接时需要额外考虑到符号链接的目标可能还是符号链接, 此时需要递归的去跟踪目标链接直至得到真正的文件. 而这其中需要解决两个问题: 一是符号链接可能成环, 这样会一直递归地跟踪下去, 因此需要进行成环的检测; 另一方面是需要对链接的深度进行限制, 以减轻系统负担(这两点也是实验的要求).
对于链接的深度, 此处在kernel/fs.h中定义了NSYMLINK用于表示最大的符号链接深度, 超过该深度将不会继续跟踪而是返回错误.
// the max depth of symlinks - lab9-2
#define NSYMLINK 10
而对于成环的检测, 此处也是选择了最简单的算法: 创建一个大小为 NSYMLINK 的数组 inums[] 用于记录每次跟踪到的文件的 inode number, 每次跟踪到目标文件的 inode 后都会将其 inode number 与 inums 数组中记录的进行比较, 若有重复则证明成环.
因此整体上 follow_symlink() 函数的流程其实比较简单, 就是至多循环 NSYMLINK 次去递归的跟踪符号链接: 使用 readi() 函数读出符号链接文件中记录的目标文件的路径, 然后使用 namei() 获取文件路径对应的 inode, 然后与已经记录的 inode number 比较判断是否成环. 直到目标 inode 的类型不为 T_SYMLINK 即符号链接类型.
而在 sys_open() 中, 需要在创建文件对象 f=filealloc() 之前, 对于符号链接, 在非 NO_FOLLOW 的情况下需要将当前文件的 inode 替换为由 follow_symlink() 得到的目标文件的 inode 再进行后续的操作.
最后考虑这个过程中的加锁释放的规则. 对于原本不考虑符号链接的情况, 在 sys_open() 中, 由 create() 或 namei() 获取了当前文件的 inode 后实际上就持有了该 inode 的锁, 直到函数结束才会通过 iunlock() 释放(当执行成功时未使用 iput() 释放 inode 的 ref 引用, 笔者认为后续到 sys_close() 调用执行前该 inode 一直会处于活跃状态用于对该文件的操作, 因此不能减少引用). 而对于符号链接, 由于最终打开的是链接的目标文件, 因此一定会释放当前 inode 的锁转而获取目标 inode 的锁. 而在处理符号链接时需要对 ip->type 字段进行读取, 自然此时也不能释放 inode 的锁, 因此在进入 follow_symlink() 时一直保持着 inode 的锁的持有, 当使用 readi() 读取了符号链接中记录的目标文件路径后, 此时便不再需要当前符号链接的 inode, 便使用 iunlockput() 释放锁和 inode. 当在对目标文件的类型判断是否不为符号链接时, 此时再对其进行加锁. 这样该函数正确返回时也会持有目标文件 inode 的锁, 达到了函数调用前后的一致.
// recursively follow the symlinks - lab9-2
// Caller must hold ip->lock
// and when function returned, it holds ip->lock of returned ip
static struct inode* follow_symlink(struct inode* ip) {
uint inums[NSYMLINK];
int i, j;
char target[MAXPATH];
for(i = 0; i < NSYMLINK; ++i) {
inums[i] = ip->inum;
// read the target path from symlink file
if(readi(ip, 0, (uint64)target, 0, MAXPATH) <= 0) {
iunlockput(ip);
printf("open_symlink: open symlink failed\n");
return 0;
}
iunlockput(ip);
// get the inode of target path
if((ip = namei(target)) == 0) {
printf("open_symlink: path \"%s\" is not exist\n", target);
return 0;
}
for(j = 0; j <= i; ++j) {
if(ip->inum == inums[j]) {
printf("open_symlink: links form a cycle\n");
return 0;
}
}
ilock(ip);
if(ip->type != T_SYMLINK) {
return ip;
}
}
iunlockput(ip);
printf("open_symlink: the depth of links reaches the limit\n");
return 0;
}
uint64
sys_open(void)
{
// ...
if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){
iunlockput(ip);
end_op();
return -1;
}
// handle the symlink - lab9-2
if(ip->type == T_SYMLINK && (omode & O_NOFOLLOW) == 0) {
if((ip = follow_symlink(ip)) == 0) {
// 此处不用调用iunlockput()释放锁,因为在follow_symlinktest()返回失败时ip的锁在函数内已经被释放
end_op();
return -1;
}
}
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){
if(f)
fileclose(f);
iunlockput(ip);
end_op();
return -1;
}
// ...
}
- 最后在
Makefile中添加对测试文件symlinktest.c的编译.
遇到问题
- 在 xv6 中执行
symlinktest会出现Failed to open 1的错误, 如下图所示:
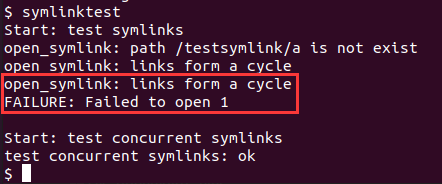
解决: 根据上图的输出并结合user/symlinktest.c的代码, 可以看到这里因为成环而未能打开文件 1, 而根据代码可以知道实际上这里并未有成环.
最后笔者对成环的代码进行检测发现了问题所在, 如下图代码, 笔者开始记录的不是 inode number 而是执行 inode 的指针, 并通过指针进行比较. 而需要注意的一点是, 这里的struct inode实际上是内存中的 inode 缓存, 当调用iput()在ref引用计数为 0 时实际上该 inode 被回收后续可以通过iget()存储磁盘中的 inode 信息(相当于有个内存 inode 的缓存池).

而如若使用struct inode的指针进行比较, 则有可能该内存中的 inode 缓存被回收后又被复用, 从而产生了重复. 因此应该按照上文描述, 记录 inode number 即ip->inums, 并用其进行比较, 该值是磁盘对 inode 的编号, 具有唯一性, 应该用此进行 inode 的成环检测. 正确代码见上文.
测试
- 在 xv6 中执行
symlinktest测试:
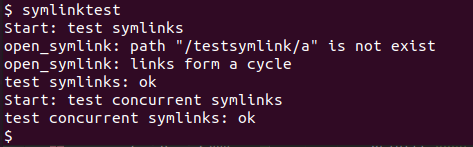
- 在 xv6 中执行
usertests测试:

./grade-lab-fs symlinktest单项测试:
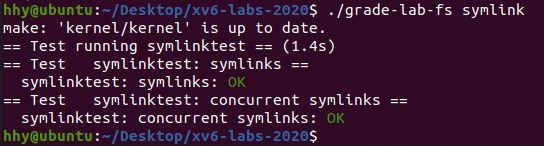















 1977
1977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









