






**
HashSet/TreeSet
**
HashSet内部有一个HashMap,只使用了map的key,value都是同一个object
private static final Object PRESENT = new Object();
TreeSet内部是一个TreeMap,只使用了key,value也是上面这个object
LinkedHashMap
LinkedHashMap是HashMap的子类,与HashMap有着同样的存储结构,但它加入了一个双向链表的头结点(有head和tail指针),将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同。LinkedHashMap同样是非线程安全的,只在单线程环境下使用。
LinkedHashMap的实现:
对于LinkedHashMap而言,它继承与HashMap、底层使用哈希表与双向链表来保存所有元素。其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。
- Entry元素:
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了数组中保存的元素Entry,该Entry除了保存当前对象的引用外,还保存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表。 - 初始化:
通过源代码可以看出,在LinkedHashMap的构造方法中,实际调用了父类HashMap的相关构造方法来构造一个底层存放的table数组。 - 存储:
LinkedHashMap并未重写父类HashMap的put方法,而是重写了父类HashMap的put方法调用的子方法void addEntry() 和void createEntry(i),提供了自己特有的双向链接列表的实现。 - 读取:
LinkedHashMap重写了父类HashMap的get方法,实际在调用父类getEntry()方法取得查找的元素后,再判断当排序模式accessOrder为true时,记录访问顺序,将最新访问的元素添加到双向链表的表头,并从原来的位置删除。由于的链表的增加、删除操作是常量级的,故并不会带来性能的损失。 - 排序模式:
LinkedHashMap定义了排序模式accessOrder,该属性为boolean型变量,对于访问顺序,为true;对于插入顺序,则为false。
一般情况下,不必指定排序模式,其迭代顺序即为默认为插入顺序。这些构造方法都会默认指定排序模式为插入顺序。如果你想构造一个LinkedHashMap,并打算按从近期访问最少到近期访问最多的顺序(即访问顺序)来保存元素,可以实现LRU(最近最少使用页面置换算法)

Hashtable底层实现原理
与HashMap十分类似,在put、get、remove等方法上加了同步
public synchronized V put(K key, V value) {}
方法的synchronized使用this锁,把整个对象都锁了,粒度大

计算哈希值,0x7FFFFFFF转换为二进制是1个0,31个1,返回一个符号位为0的数,即丢弃最高位,以免函数外产生影响。

使用volatile关键字
Hashtable 的 key 和 value 都不允许为 null,Hashtable遇到 null,直接返回 NullPointerException。
Collections.SynchronizedMap底层实现原理
Collections.synchronizedMap()实现原理是Collections定义了一个SynchronizedMap的内部类,并返回这个类的实例。
SynchronizedMap这个类实现了Map接口,在调用方法时使用synchronized来保证线程同步,当然了实际上操作的还是我们传入的HashMap实例,简单的说就是Collections.synchronizedMap()方法帮我们在操作HashMap时自动添加了synchronized来实现线程同步,类似的其它Collections.synchronizedXX方法也是类似原理)
Mutex在构造时默认赋值为this,即所有方法都用的同一个锁。
ConcurrentHashMap底层实现原理
http://ifeve.com/concurrenthashmap/
http://blog.csdn.net/dingji_ping/article/details/51005799
ConcurrentHashMap主要有三大结构:整个Hash表,segment(段),HashEntry(节点)。每个segment就相当于一个HashTable。ConcurrentHashMap将锁加在segment上(每个段上),这样我们在对segment1操作的时候,同时也可以对segment2中的数据操作,这样效率就会高很多。
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。Put和remove方法中有lock()和unlock()(都是使用的this对象,lock()在代码开始,unlock在finally中)。
Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素.

segments数组的长度ssize通过concurrencyLevel(并发等级默认是16)计算得出。为了能通过按位与的哈希算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方(power-of-two size),所以必须计算出一个是大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。
初始化每个Segment。输入参数initialCapacity是ConcurrentHashMap的初始化容量,loadfactor是每个segment的负载因子,在构造方法里需要通过这两个参数来初始化数组中的每个segment。segment里HashEntry数组的长度,它等于initialCapacity除以ssize的倍数(总大小除以segments数组长度),HashEntry的长度也是2的N次方
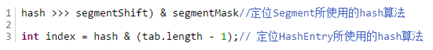
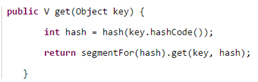

我们知道HashTable容器的get方法是需要加锁的,那么ConcurrentHashMap的get操作是如何做到不加锁的呢?原因是它的get方法里将要使用的共享变量都定义成volatile,之所以不会读到过期的值,是根据java内存模型的happen before原则,对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取volatile变量,get操作也能拿到最新的值。
如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
其中有一个Segment数组,每个Segment中都有一个锁,因此Segment相当于一个多线程安全的HashMap,采用分段加锁。每个Segment中有一个Entry数组,Entry中成员value是volatile修饰,其他成员通过final修饰。get操作不用加锁,put和remove操作需要加锁,因为value通过volatile保证可见性。
两个hash过程,第一次找到所在的桶,并将桶锁定,第二次执行写操作。而读操作不加锁
Collections.SynchronizedMap和Hashtable都是整个表的锁,与ConcurrentHashMap锁粒度不同
ConcurrentHashMap不允许key或value为null值。
ConcurrentHashMap允许一边更新、一边遍历,也就是说在Iterator对象遍历的时候,ConcurrentHashMap也可以进行remove,put操作,且遍历的数据会随着remove,put操作产出变化,相当于有多个线程在操作同一个map(可以在foreach keyset时remove对象,HashMap不可以)















 150
150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









