







 本文详细介绍了Android APK文件实际上是一个ZIP格式的压缩包,探讨了ZIP格式的结构,包括数据区、中央目录记录区和中央目录记录尾部区的组成及各部分的作用。讲解了如何通过解压过程中寻找中央目录尾部标志来定位解压信息,并解释了大小端模式的概念。最后,通过实例分析了一个APK文件,验证了理论知识。
本文详细介绍了Android APK文件实际上是一个ZIP格式的压缩包,探讨了ZIP格式的结构,包括数据区、中央目录记录区和中央目录记录尾部区的组成及各部分的作用。讲解了如何通过解压过程中寻找中央目录尾部标志来定位解压信息,并解释了大小端模式的概念。最后,通过实例分析了一个APK文件,验证了理论知识。
【前言】
Android的安装包.apk实际上就是个zip格式的压缩包,所以在了解apk签名之前,有必要先来探索一下zip格式压缩包的结构
一、Zip格式结构图总览

二、Zip文件结构详解
zip格式压缩包主要由三大部分组成:数据区、中央目录记录区(也有叫核心目录记录)、中央目录记录尾部区
1、数据区
数据区是由一系列本地文件记录组成,本地文件记录主要是记录了压缩前后文件的元数据以及存放压缩后的文件,组成部分也分为三大部分:本地文件头、文件数据、文件描述
1.1、本地文件头

本地文件头主要是记录了压缩文件的元数据:
1)0~3:4个字节,用来存放本地文件头标识:0x04034b50,用于解压时候,读取判断文件头的开始
2)4~5:2个字节,记录解压缩文件所需的最低支持的ZIP规范版本,apk压缩版本默认是20, 即Deflate压缩方式
当前最低功能版本定义如下:(
压缩包记录的解压版本都是需要版本*10,比如:2.0 * 10 = 20)
1.0 - 默认值
1.1 - 文件是卷标
2.0 - 文件是一个文件夹(目录)
2.0 - 使用 Deflate 压缩来压缩文件
2.0 - 使用传统的 PKWARE 加密对文件进行加密
2.1 - 使用 Deflate64™ 压缩文件
2.5 - 使用 PKWARE DCL Implode 压缩文件
2.7 - 文件是补丁数据集
4.5 - 文件使用 ZIP64 格式扩展
4.6 - 使用 BZIP2 压缩文件压缩
5.0 - 文件使用 DES 加密
5.0 - 文件使用 3DES 加密
5.0 - 使用原始 RC2 加密对文件进行加密
5.0 - 使用 RC4 加密对文件进行加密
5.1 - 文件使用 AES 加密进行加密
5.1 - 使用更正的 RC2 加密对文件进行加密
5.2 - 使用更正的 RC2-64 加密对文件进行加密
6.1 - 使用非 OAEP 密钥包装对文件进行加密
6.2 - 中央目录加密
3)6~7:2个字节,记录通用标志位,第0位为1时(即二进制:00000000 00000001),表示文件被加密,解压时候需要解密;第3位为1时候(即二进制:00000000 00000100),表示有数据描述部分,那么本地文件头中的 (虽然zip规范是这么定义,但是发现有些压缩包即使声明有数据描述部分,但是本地文件头的CRC-32、压缩大小和未压缩大小字段都被设置为0CRC-32、压缩大小和未压缩大小依然还是设置为真实值) , 正确的值被放在紧跟在压缩数据之后的数据描述部分,apk的通用标志位默认传0即可,也有传2048、2056,目前第15位是PKWARE保留位,没啥意义,更多通用标志位含义可见这里
4)8~9:2个字节,记录压缩包所用到的压缩方式,apk默认Deflate压缩,传8即可, 要是传0 ,则是不压缩,各种压缩方式对应数值如下:
0 - The file is stored (no compression)
1 - The file is Shrunk
2 - The file is Reduced with compression factor 1
3 - The file is Reduced with compression factor 2
4 - The file is Reduced with compression factor 3
5 - The file is Reduced with compression factor 4
6 - The file is Imploded
7 - Reserved for Tokenizing compression algorithm
8 - The file is Deflated
9 - Enhanced Deflating using Deflate64™
10 - PKWARE Data Compression Library Imploding
11 - Reserved by PKWARE
12 - File is compressed using BZIP2 algorithm
5)10~11:2个字节,记录文件最后修改时间,是MS-DOS格式编码的时间
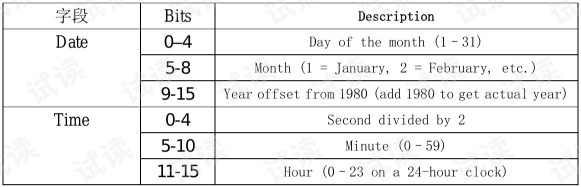
6)12~13:2个字节,记录文件最后修改日期,是MS-DOS格式编码的日期
7)14~17:4个字节,记录文件未压缩时的CRC-32校验码
8)18~21:4个字节,记录文件压缩后的大小
9)22~25:4个字节,记录文件未压缩的大小
10)26~27:2个字节,记录文件名的长度(假设文件名长度为n)
11)28~29:2个字节,记录扩展区的长度(假设扩展区长度为m)
12)30~30+n: n个字节,记录文件名
13)30+n~30+n+m: m个字节,记录扩展数据
1.2、文件数据
文件数据紧跟在本地文件头之后,一般是压缩后的文件数据或压缩方式选择不压缩时候,用来存储未压缩文件数据。
1.3、文件描述
文件描述符仅在通用位标志的第 3 位被设置为1时才存在。 它是字节对齐的,紧跟在文件数据的最后一个字节之后。当且仅当无法在 .ZIP 文件中查找时才使用此描述符,例如:当输出 的.ZIP 文件是标准输出或不可查找设备时使用文件描述,换句话说,正常情况下都不需要使用

数据描述符标识不一定有,因为一开始规范是没有的,后面才加上去的
2、中央目录记录区(也称核心目录记录区 )
中央目录记录区是有一系列中央目录记录所组成,一条中央目录记录对应数据区中的一个压缩文件记录,中央目录记录由以下部分构成: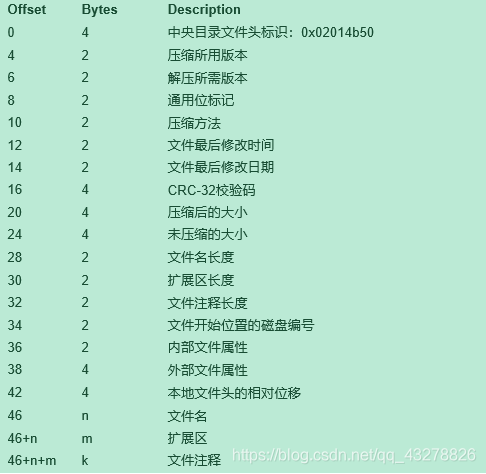
1)0~3:4个字节,记录核心目录文件头标识:0x02014b50,用于解压时候,查找判断是否是中央目录的开始位置
2)4~5:2个字节,记录压缩
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









