







1 多线程的介绍
1.1 操作系统的演进过程
批处理操作系统(单道和多道):
计算机能够自动地、成批地处理一个或多个用户的作业。不过单道批处理系统在进行I/O操作的时候,CPU资源是没有被利用的,为了能够更高效的利用cpu资源,多道批处理系统诞生了。
单道批处理操作系统工作图示:

多道(两道)批处理操作系统工作图示:

分时操作系统
批处理系统对于用户需要的计算机系统来说缺少交互性,工作之间的独立性。以及能在预期时间内完成用户需要的任务。分时操作系统产生了,它支持多用户交互式操作系统,每个用户可以通过自己的终端向系统发出各种操作控制命令,完成作业的运行。分时是指把cpu的运行时间分成很短的时间片,按时间片轮流把cpu资源分配给各任务使用。
分时操作系统工作图示:

实时系统:常用于飞机飞行、导弹发射,等场景,这里不做详细介绍。
1.2 线程和进程的关系
介绍完操作系统之后再来看进程和线程。随着计算机硬件的发展,计算机的内存越来越大,cpu数也越来越多。进程和线程为了更好的利用计算机资源自然而然的诞生了。
进程是资源(CPU、内存等)分配的基本单位,它是程序执行时的一个实例。程序运行时系统就会创建一个进程,系统会给每个进程分配独立的内存地址空间,并且每个进程的地址不会相互干扰。对于单核CPU来说,在任意一个时刻,只会有一个任务去执行,只是通过切换时间片的方式完成了并行执行。多个进程之间通过CPU时间片的不断切换交替执行(给人的感觉就是应用程序同时进行的,所以你可以无感知的一边写代码,一边听歌)。
线程
线程是程序执行时的最小单位,它是进程的一个执行流,是CPU调度和分派的基本单位,一个进程可以由很多个线程组成,每个线程会负责一个独立的子任务,进程在一个时间内只能干一件事情,如果想同时干多件事情的话, 就要把进程中的多个子任务划分到多个线程,利用线程更高效的完成任务。
2 多线程的适合场景
什么情况下需要使用多线程呢?对于我们编写程序来说一般一个主线程就可以处理所有的事情,但是当我们需要对于一些耗时操作做一些优化的时候,可以考虑多线程。
- 需要多次从其他rpc服务取数据,可以考虑利用多线程获取数据,都返回之后再统一处理。
- 需要从数据库中的多个表中取数据,可以考虑利用多线程从表取数据,然后再处理。
- 需要我们需要导入一个较大的表格数据的时候,可以考虑利用多线程分批导入数据等等。
使用多线程时需要我们注意⚠️ 因为多线程之间执行是无序的,我们需要确定并行的任务之间是独立的才可以。如果两个线程之间的任务不是独立的,需要利用线程安全的变量做线程之前的通信。
3 多线程的实践(java)
3.1 我们先来看一下如何创建一个线程
通过继承Thread类
public class TestThread extends Thread {
public TestThread() {
}
@Override
public void run() {
System.out.print("当前执行线程是:" + this.getName() + " ");
}
public static void main(String[] args) {
System.out.println("当前的线程是" + Thread.currentThread().getName());
TestThread testThread1 = new TestThread();
TestThread testThread2 = new TestThread();
testThread1.start();
testThread2.start();
}
}
实现Runnable接口
public class TestRunnable implements Runnable {
private int count = 10;
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(Thread.currentThread().getName() + "运行 count= " + count--);
}
}
public static void main(String[] args) {
TestRunnable testRunnable = new TestRunnable();
new Thread(testRunnable, "C").start();
new Thread(testRunnable, "D").start();
}
}
实现Callable接口
import java.util.concurrent.*;
public class TestCallable implements Callable<Integer> {
private final static ExecutorService executor = Executors.newCachedThreadPool();
private Integer number;
public TestCallable(Integer number) {
this.number = number;
}
@Override
public Integer call() throws Exception {
System.out.println("线程number=" + number);
return number;
}
public static void main(String[] args) {
executor.submit(new TestCallable(1));
}
}
从JDK 1.5之后,提供了Callable和Future,通过它们可以在任务执行完毕之后得到任务执行结果。Callable和Future的配合使用样例:
package com.bytedance.cg.robot.web.practise.multithreading;
import java.util.concurrent.*;
public class TestCallable implements Callable<Integer> {
private final static ExecutorService executor = Executors.newCachedThreadPool();
private Integer number;
public TestCallable(Integer number) {
this.number = number;
}
@Override
public Integer call() throws Exception {
System.out.println("线程number=" + number);
return number;
}
public static void main(String[] args) {
Callable<Integer> callable = () -> getDoubleNumber(100);
Future future = executor.submit(callable);
try {
System.out.println(future.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
private static Integer getDoubleNumber(Integer i) {
return i * 2;
}
}
FutureTask的使用
FutureTask是Future接口的实现类,构造参数需要传入一个Callable接口或实现Callable的实现类。
FutureTask类主要实现了Future接口(可以作为Future得到Callable的返回值),实现了Runnable接口(可以作为Runnable被线程执行)。
package com.bytedance.cg.robot.web.practise.multithreading;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
public class TestCallable implements Callable<Integer> {
private final static ExecutorService executor = Executors.newCachedThreadPool();
private Integer number;
public TestCallable(Integer number) {
this.number = number;
}
@Override
public Integer call() {
System.out.println("线程number=" + number);
return number;
}
public static void main(String[] args) {
List<FutureTask<Integer>> futureTasks = new ArrayList<>();
for (int i = 1; i <= 3; i++) {
FutureTask<Integer> integerFutureTask = new FutureTask<>(new TestCallable(i));
futureTasks.add(integerFutureTask);
// 利用线程池执行FutureTask的任务
executor.submit(integerFutureTask);
// 自建线程池执行FutureTask的任务
new Thread(new FutureTask<>(new TestCallable(i * 5)), "有返回值的线程").start();
}
// 获取返回值的接口(会阻塞主线程)
try {
futureTasks.stream().forEach(task -> {
try {
System.out.println("子线程的返回值:" + task.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.2 线程池
定义:线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
好处:
- 重复利用已经创建的线程池,避免线程创建和销毁带来的性能损耗。线程池可以管理线程,方式无限制创建线程导致资源调度失衡,统一的分配、调优和监控线程。
- 任务达到时,直接分配给线程池中已有的线程执行。
- 线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,允许任务延期执行或定期执行。
线程池介绍:
Java中的线程池核心实现类是ThreadPoolExecutor。
ThreadPoolExecutor的继承类图示:
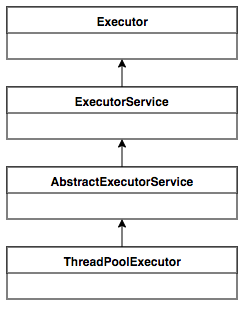
Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。
ExecutorService接口增加了一些能力:扩充执行任务的能力,补充可以为一个或一批异步任务生成Future的方法;提供了管控线程池的方法,比如停止线程池的运行。
AbstractExecutorService则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。
最下层的实现类ThreadPoolExecutor实现最复杂的运行部分,ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
ThreadPoolExecutor的运行机制:
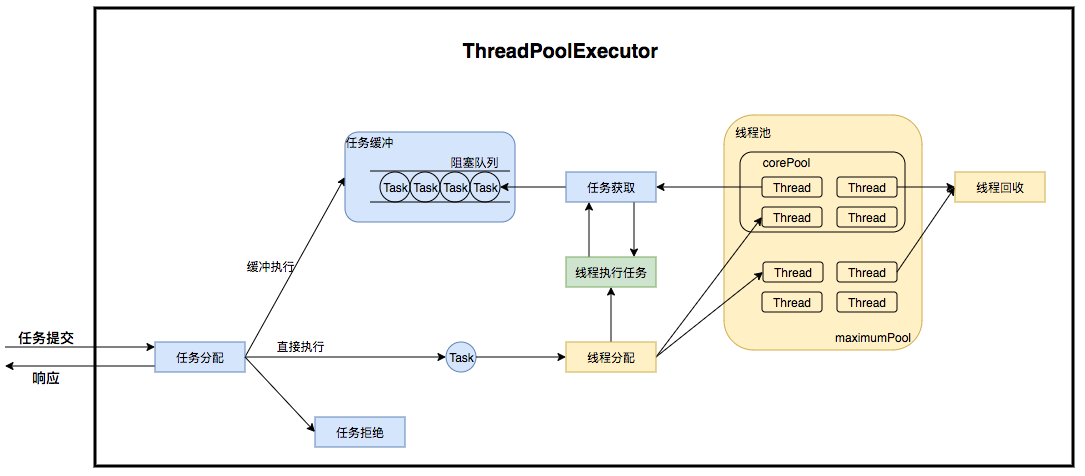
线程池主要有三个重要的元素:核心线程数,最大线程数,阻塞队列。
任务调度的执行流程:
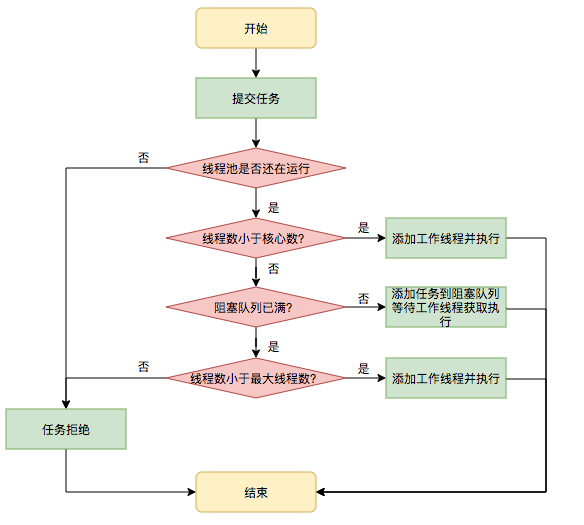
阻塞队列有很多种类型:常见的阻塞队列
ArrayBlockingQueue:一个由数组实现的有界阻塞队列。该队列采用先进先出(FIFO)的原则对元素进行排序添加的。
LinkedBlockingQueue:一个用单向链表实现的有界阻塞队列。此队列的默认和最大长度为 Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。要注意阻塞队列的长度,如果不是特殊业务,LinkedBlockingQueue 使用时,切记要定义队列容量。
PriorityBlockingQueue :一个支持优先级的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的延迟无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现 Delayed 接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。
SynchronousQueue:一个不存储元素的阻塞队列,也即是单个元素的队列。每一个 put 操作必须等待一个 take 操作,否则不能继续添加元素。线程空闲60s会被回收。
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列(实现了继承于 BlockingQueue 的 TransferQueue)采用了一种预占模式。意思就是消费者线程取元素时,如果队列不为空,则直接取走数据,若队列为空,那就生成一个节点(节点元素为null)入队,然后消费者线程被等待在这个节点上,后面生产者线程入队时发现有一个元素为null的节点,生产者线程就不入队了,直接就将元素填充到该节点,并唤醒该节点等待的线程,被唤醒的消费者线程取走元素,从调用的方法返回。我们称这种节点操作为“匹配”方式。重写了tryTransfer和transfer方法具有匹配的功能
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列,多线程并发时候,降低竞争锁。
任务拒绝策略:(当达到阻塞队列的最大容量和线程池最大线程数时会生效)

摘自:Java线程池实现原理及其在美团业务中的实践 - 美团技术团队
ExecutorService类的常见ThreadPoolExecutor实现
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
} public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}// 这个线程池jdk8出现的,paramStream用的就是这种线程池。
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}3.3 springboot线程池之ThreadPoolTaskExecutor
当我们创建线程池时不想要jdk ExecutorService类默认的几种线程池,我们可以选择springboot的ThreadPoolTaskExecutor来定义我们需要的线程池。ThreadPoolTaskExecutor相比ThreadPoolExecutor,增加了 submitListenable 方法,该方法返回 ListenableFuture 接口对象,ListenableFuture 接口对象,增加了线程执行完毕后成功和失败的回调方法。从而避免了 Future 需要以阻塞的方式调用 get,然后再执行成功和失败的方法。
ListenableFuture的类图结构

ListenableFuture相对于Future提供一个线程执行结束后的回调方法(addCallback),获取结果不会阻塞主线程。
我们可以自定义核心线程数,最大线程数,和阻塞队列长度来初始化bean交给spring容器管理。后面通过注解来获取线程池。使用姿势
import org.springframework.beans.factory.annotation.Configurable;
import org.springframework.context.annotation.Bean;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.Executor;
import java.util.concurrent.ThreadPoolExecutor;
@Configurable
@EnableAsync
public class ThreadPoolConfig {
@Bean("goodsWriteExecutor")
public Executor goodsWriteExecutor() {
return buildExecutor(40, 60, 100, 60, "goodsWriteExecutor");
}
@Bean("brandWriteExecutor")
public Executor brandWriteExecutor() {
return buildExecutor(40, 60, 100, 60, "brandWriteExecutor");
}
@Bean("supplierWriteExecutor")
public Executor supplierWriteExecutor() {
return buildExecutor(40, 60, 100, 60, "supplierWriteExecutor");
}
private Executor buildExecutor(int corePoolSize, int maxPoolSize, int queueCapacity, int keepAliveSeconds, String name) {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
//设置线程池参数信息
taskExecutor.setCorePoolSize(corePoolSize);
taskExecutor.setMaxPoolSize(maxPoolSize);
taskExecutor.setQueueCapacity(queueCapacity);
taskExecutor.setKeepAliveSeconds(keepAliveSeconds);
taskExecutor.setThreadNamePrefix(name);
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
//修改拒绝策略为使用当前线程执行
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//初始化线程池
taskExecutor.initialize();
return taskExecutor;
}
}
@Autowired
private Executor brandWriteExecutor; // 根据名称从spring容器中获取线程池。3.4 CompletableFuture和parallelStream用法。
CompletableFuture介绍:
Future具有一定的局限性,获取得线程执行结果前,我们的主线程get()得到结果需要一直阻塞等待,浪费cpu资源。而且不太便于我们做异步计算的编排组合。
CompletableFuture常用方法:
runAsync 异步操作,不支持返回值
supplyAsync 异步操作,支持返回值
exceptionally:当前任务出现异常时,执行exceptionally中的回调方法。
whenComplete 消费上一个任务的处理结果(包括异常)不会影响上一个任务的结果,虽然后返回值,其实返回的是上一个任务的结果,(whenComplete用的是主线程)。
thenAccept 消费处理结果,接收任务的处理结果,并消费处理,无返回结果。
thenApply 方法,消费上一个任务的处理结果,有返回值。任务出现异常则不会执行该方法。(用的是自建线程池或forkjoinpool,取决于CompletableFuture任务的线程池参数。)
handle和thenApply 方法处理方式基本一样。不同的是 handle 是在任务完成后再执行,还可以处理异常的任务。
thenCombine 合并任务,thenCombine 会把 两个 CompletionStage 的任务都执行完成后,把两个任务的结果一块交给 thenCombine 来处理。
thenCompose 方法,thenCompose 方法允许你对两个 CompletionStage 进行流水线操作,第一个操作完成时,将其结果作为参数传递给第二个操作。
allof 可以把多个CompletableFuture任务组合在一起,用stream获取结果后再利用thenApply执行业务逻辑。
anyof 可以把多个CompletableFuture任务组合在一起,用组合后的CompletableFuture.get可以获取到第一个执行完任务的CompletableFuture的结果。
CompletableFuture支持通过回调的方式获取结果,主线程不会被阻塞。简单的异步处理demo
@SneakyThrows
@Override
public BaseUploadResponse upload(StoreUploadReq uploadReq) {
// 1 获取api层的解析的属性信息
List<AttributeUploadTDTO> attributeUploadTDTOs = uploadReq.getAttributeUploadTDTOList();
List<UploadFailedResponse> failedResponses = attributeUploadTDTOs.parallelStream().map((attributeUploadTDTO) -> {
// 2 对实体类做参数校验(包括关联关系的校验) -> 把实体类转化成创建需要的参数类型 -> 记录创建失败的记录
UploadFailedResponse verifyResult = verifyUploadAttribute(attributeUploadTDTO, Integer.parseInt(attributeUploadTDTO.getRowNumber()),
uploadReq.getGoodsType());
// 这里如果检验成功,直接用CompletableFuture.runAsync()进行写入操作!!!
if (Objects.isNull(verifyResult)) {
CompletableFuture<Void> voidCompletableFuture =
CompletableFuture.runAsync(() -> attributeModifyServiceImpl.create(Convert2basicGoodsData(attributeUploadTDTO,
uploadReq.getGoodsType()), uploadReq.getCparam()), attrWriteExecutor);
// 这里因为是异步处理的,可能线程监听不到异步写线程的返回结果,可能会没有打印日志
if (voidCompletableFuture.isCompletedExceptionally()) {
log.error("create attribute error, AttributeUploadTDTO={}", JacksonUtils.marshalToString(attributeUploadTDTO));
return baseUploadServiceImpl.packFailedResponse(attributeUploadTDTO.getName(),
Integer.parseInt(attributeUploadTDTO.getRowNumber()), "属性名称", Constant.SYSTEM_ERROR);
}
}
return verifyResult;
}).filter(Objects::nonNull).collect(Collectors.toList());这里会对传入的参数进行校验操作,校验通过之后,直接用CompletableFuture进行写入操作,写操作通过线程池在其他线程处理,不会阻塞主进程的进度
@SneakyThrows
private ResponseDTO<Object> parallelBatchHandle(StoreModuleTEnum moduleTEnum, StoreOperationTEnum operation,
GoodsTypeTEnum goodsTypeTEnum, List<String> ids) {
//这里使用并行方式提高效率
List<CompletableFuture<Pair<Long, StoreStandardRes>>> futures = ids.stream()
.map(Long::parseLong)
.map(id -> CompletableFuture.supplyAsync(() -> invoke(moduleTEnum, operation, goodsTypeTEnum, id), Executors.newCachedThreadPool())) //注意这里使用cachedThreadPool,可能有内存泄漏风险
.collect(Collectors.toList());
//等待所有结果返回进行计算
return sequence(futures)
.thenApply(pairList -> buildResponse(pairList, operation, moduleTEnum, goodsTypeTEnum))
.get(2000, TimeUnit.MILLISECONDS);
}
private <T> CompletableFuture<List<T>> sequence(List<CompletableFuture<T>> futures) {
CompletableFuture<Void> allDoneFuture = CompletableFuture.allOf(futures.toArray(new CompletableFuture[futures.size()]));
return allDoneFuture.thenApply(v -> futures.stream().map(CompletableFuture::join).collect(Collectors.<T>toList()));
}利用CompletableFuture异步处理,再用stream收集处理结果,allof组合所有CompletableFuture,等待所有结果返回,再做处理是比较巧妙的处理方式。
parallelStream介绍:
parallelStream其实就是一个并行执行的流,它通过默认的ForkJoinPool,提高多线程任务的速度。
并行流内部使用了默认的
ForkJoinPool,它默认的线程数量就是你的处理器(cpu核数)数量。可以通过设置【java.util.concurrent.ForkJoinPool.common.parallelism】这个变量改变ForkJoinPool的线程数量。
注意事项:1:java.util.concurrent.ForkJoinPool.common.parallelism
变量是final类型的,整个JVM中只允许设置一次2:多个并行流用的都是全局的
ForkJoinPool的线程池,IO操作尽量不要放进中,会阻塞其他parallelStream。
ForkJoinPool的核心:Fork/Join 框架
Fork/Join框架的核心是采用分治法的思想,将一个大任务拆分为若干互不依赖的子任务,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务。(可以做到执行完子任务之后再执行父任务)
Fork/Join框架采用了工作窃取算法来运行任务,也就是说当某个线程处理完自己工作队列中的任务后,尝试当其他线程的工作队列中窃取一个任务来执行,直到所有任务处理完毕。为了减少线程之间的竞争,任务会使用双端队列,窃取任务的队列从尾部窃取任务执行。
parallelStream简单用法:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.parallelStream().forEach(System.out::println);














 8331
8331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









