







数据集介绍
用的是RGDD2020数据集和武汉市11月份坑洞的数据
数据集介绍参考:
GRDDC2020数据集下载及介绍
paddledection部分
# 缓存设置,克隆paddledection可能中断
!git config --global http.postBuffer 319430400
# 克隆PaddleDetection仓库
# 只有第一次运行空项目时需要执行
!git clone https://gitee.com/paddlepaddle/PaddleDetection.git
# 下载依赖包
# 每次启动项目后都需要执行
%cd PaddleDetection
!pip --default-timeout=100 install --user -r requirements.txt
建议上午安装paddlex,防止占用过高下载中断
# 安装paddlex:为了方便切分数据集
!pip install paddlex
#测试是否安装成功
!python ppdet/modeling/tests/test_architectures.py
预处理数据
#解压数据集
%cd
!rar x data/data220428/train.rar -C data/data220428/
#建立label_list 包含所检测的类别 跟classes一样
#合并数据集
%cd
!mkdir work/train
!mkdir work/train/Annotations
!mkdir work/train/JPEGImages
!cp -r data/data220428/train/Czech/annotations/xmls/* work/train/Annotations/
!cp -r data/data220428/train/Japan/annotations/xmls/* work/train/Annotations/
!cp -r data/data220428/train/India/annotations/xmls/* work/train/Annotations/
!cp -r data/data220428/train/wuhan/annotations/xmls/* work/train/Annotations/
!cp -r data/data220428/train/Czech/images/* work/train/JPEGImages/
!cp -r data/data220428/train/Japan/images/* work/train/JPEGImages/
!cp -r data/data220428/train/India/images/* work/train/JPEGImages/
!cp -r data/data220428/train/wuhan/images/* work/train/JPEGImages/
#拆分数据集
!paddlex --split_dataset --format VOC --dataset_dir work/train/ --val_value 0.1 --test_value 0.2
转换成coco格式
#转换train
%cd /home/aistudio/PaddleDetection/PaddleDetection/
!python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir /home/aistudio/work/train/ \
--voc_anno_list /home/aistudio/work/train/train_list.txt \
--voc_label_list /home/aistudio/work/train/labels.txt \
--voc_out_name /home/aistudio/work/train/voc_train.json
#转换val
!python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir /home/aistudio/work/train/ \
--voc_anno_list /home/aistudio/work/train/val_list.txt \
--voc_label_list /home/aistudio/work/train/labels.txt \
--voc_out_name /home/aistudio/work/train/voc_val.json
#转换test
!python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir /home/aistudio/work/train/ \
--voc_anno_list /home/aistudio/work/train/test_list.txt \
--voc_label_list /home/aistudio/work/train/labels.txt \
--voc_out_name /home/aistudio/work/train/voc_test.json
修改配置文件
#PicoDet 的配置文件 由1个入口配置文件,和5个相关联的子配置文件组成。
_BASE_: [
'../datasets/coco_detection.yml',
'../runtime.yml',
'_base_/picodet_v2.yml',
'_base_/optimizer_300e.yml',
'_base_/picodet_416_reader.yml',
]
接下来我们从子配置文件开始,依次说明每个配置文件的用途和需要修改的部分。
数据集配置文件 coco_detection.yml
设置数据集的配置信息。根据本案例的情况,请按照如下内容进行修改 num_classes、image_dir、anno_path、dataset_dir:
metric: COCO
num_classes: 9
TrainDataset:
!COCODataSet
image_dir: JPEGImages #image_dir=dataset_dir/image_dir
anno_path: voc_train.json
dataset_dir: /home/aistudio/work/train
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
EvalDataset:
!COCODataSet
image_dir: JPEGImages
anno_path: voc_val.json
dataset_dir: /home/aistudio/work/train
allow_empty: true
TestDataset:
!ImageFolder
anno_path: voc_test.json # also support txt (like VOC's label_list.txt)
dataset_dir: /home/aistudio/work/train # if set, anno_path will be 'dataset_dir/anno_path'
运行时配置文件 runtime.yml
用于设置运行时的参数,主要包括:
use_gpu: 是否使用GPU训练
use_xpu: 是否使用XPU训练
log_iter: 显示训练信息的间隔
save_dir: 模型保存路径
snapshot_epoch: 保存模型的间隔
# Exporting the model: 与导出模型相关的设置
模型网络参数 picodet_v2.yml
用于设置模型的网络参数,也包括预训练集的加载,这里为了可以快速开始实际训练,我们也暂时保留默认的参数,不做修改。
训练优化参数 optimizer_300e.yml
主要说明了学习率和优化器的配置。其中比较重要的参数是训练轮数 epoch 和 学习率 base_lr。同样,我们暂时不在这里修改,稍后再设置。
数据读取器配置参数 picodet_416_reader.yml
主要说明了在训练时读取数据集的配置参数,其中比较重要的有:
sample_transforms / batch_transforms: 数据增强算子
batch_size: 批量大小
worker_num: 并发加载子进程数
resize: 读取后的预处理大小
修改入口配置文件 picodet_s_416_coco_lcnet.yml
这是控制模型训练的主配置文件,其中设置的参数会覆盖掉子配置文件中的相关参数。这也是为什么我们之前在子配置文件中基本保留了默认配置而不做修改,原因就在于,在主配置文件内集中修改参数,可以更方便的修改训练参数,避免要修改的参数过于分散。
按如下内容修改主配置文件的内容:
_BASE_: [
'../datasets/coco_detection.yml',
'../runtime.yml',
'_base_/picodet_v2.yml',
'_base_/optimizer_300e.yml',
'_base_/picodet_416_reader.yml',
]
weights: output/picodet_m_416_coco/best_model
find_unused_parameters: True
use_ema: true
epoch: 80
snapshot_epoch: 10
TrainReader:
batch_size: 48
LearningRate:
base_lr: 0.03
schedulers:
- name: CosineDecay
max_epochs: 300
- name: LinearWarmup
start_factor: 0.1
steps: 300
其中:
- Batch Size指模型在训练过程中,前向计算一次(即为一个step)所用到的样本数量 如若使用多卡训练,
- batch_size会均分到各张卡上(因此需要让batch size整除卡数)
- Batch Size跟机器的显存/内存高度相关,batch_size越高,所消耗的显存/内存就越高
- step与epoch的关系:1个epoch由多个step组成,例如训练样本有800张图像,train_batch_size为8,
那么每个epoch都要完整用这800张图片训一次模型,而每个epoch总共包含800//8即100个step
训练模型
# 单卡GPU上训练
%cd /home/aistudio/PaddleDetection/PaddleDetection/
!export CUDA_VISIBLE_DEVICES=0 # windows和Mac下不需要执行该命令
!python tools/train.py -c configs/picodet/picodet_m_416_coco_lcnet.yml \
--use_vdl True --eval
#中断后可使用 -r 继续训练
# !export CUDA_VISIBLE_DEVICES=0
# !python tools/train.py -c configs/picodet/picodet_m_416_coco_lcnet.yml \
# -r output/picodet_m_416_coco_lcnet/model_final.pdparams \
# --use_vdl True --eval
模型评估
#评估picodet_m_416模型
%cd /home/aistudio/PaddleDetection/PaddleDetection/
!export CUDA_VISIBLE_DEVICES=0
!python tools/eval.py -c configs/picodet/picodet_m_416_coco_lcnet.yml -o weights=output/picodet_m_416_coco_lcnet/model_final.pdparams
单张图片预测
# 图片预测
%cd /home/aistudio/PaddleDetection/PaddleDetection/
!python tools/infer.py -c configs/picodet/picodet_m_416_coco_lcnet.yml \
--infer_img=/home/aistudio/work/train/wuhan0-11-1.jpg \
--output_dir=/home/aistudio/infer_output_m_416/ \
--draw_threshold=0.5 \
-o weights=output/picodet_m_416_coco_lcnet/best_model \
--use_vdl=True
在pycharm上用picodet预测图片
python infer.py -c C:\Users\Administrator\PaddleDetection\configs\picodet\picodet_s_320_coco.yml -o use_gpu=false weights=https://paddledet.bj.bcebos.com/models/picodet_s_320_c
oco.pdparams --infer_img=C:\Users\Administrator\PaddleDetection\demo\Japan_000171.jpg

模型导出
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 导出后的模型会保存在:
output_inference/picodet_m_416_coco_lcnet/
包含如下文件:
infer_cfg.yml
model.pdiparams
model.pdiparams.info
model.pdmodel
导出后的文件,将用于后续的模型部署。
# 导出模型
!python tools/export_model.py -c configs/picodet/picodet_m_416_coco_lcnet.yml -o weight=SavedModel/picodet_m_416_coco_lcnet/model_final.pdparms
量化训练
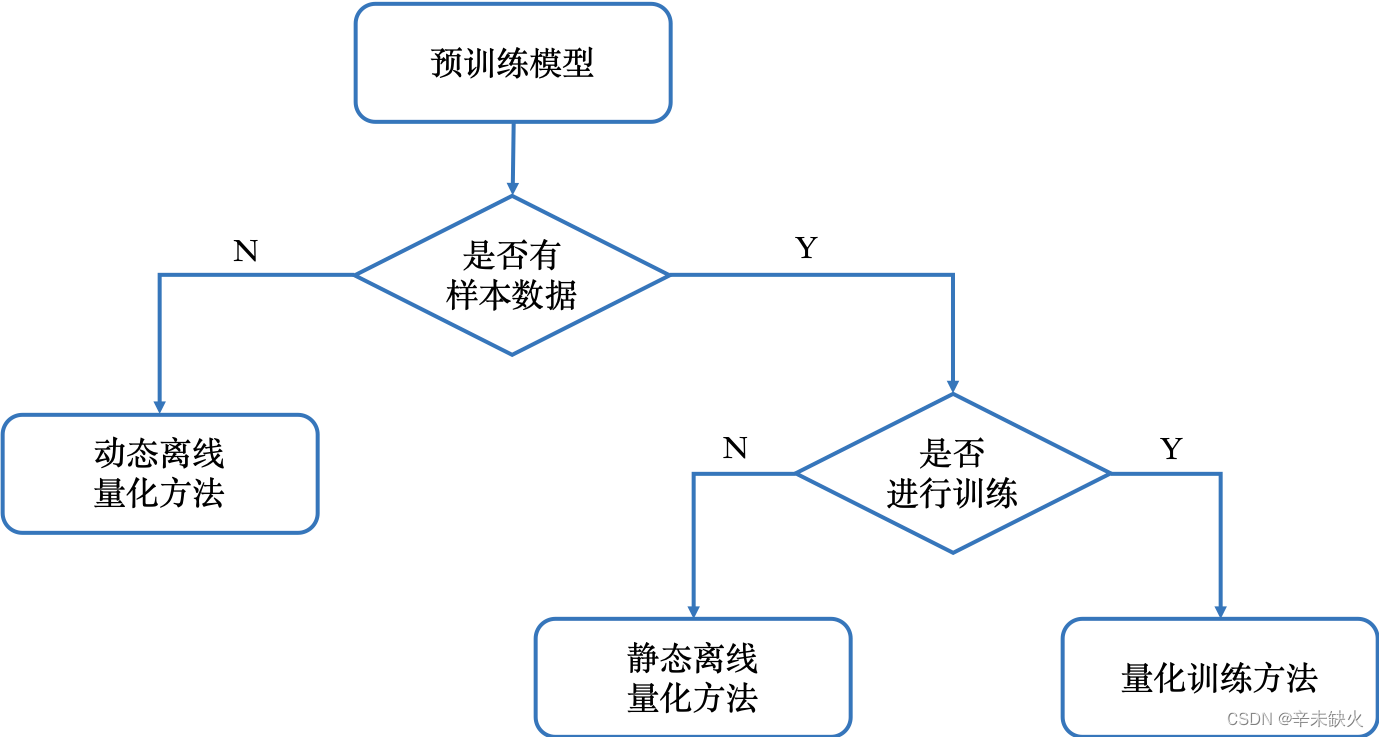
模型的压缩,从本质上讲,是为了在模型的体积、推理速度和精度三者之间寻求一个平衡。
PaddleSlim 提供的模型压缩工具,大致分为以下几类:
- 剪裁: 评估模型中参数的重要性,将不重要的参数去掉,或者设置为0。
- 动态离线量化: 动态离线量化仅将模型中特定算子的权重从FP32类型映射成INT8/16类型。
- 静态离线量化: 静态离线量化使用少量无标签校准数据,采用KL散度等方法计算量化比例因子。
- 量化训练: 量化训练让模型感知量化运算对模型精度带来的影响,通过finetune训练降低量化误差。
- 蒸馏: 选择规模大的模型作为Teacher,对相对轻量的Student模型进行训练。
- 模型结构搜索(NAS): 给定一个称为搜索空间的候选神经网络结构集合,用某种策略从中搜索出最优网络结构。
考虑到最终部署的硬件设备是算力和内存都比较受限的ARM设备,就需要进一步减小模型体积、加快预测速度。因此,我们着重从量化的角度进行模型压缩:动态离线量化、静态离线量化、量化训练。

# 安装 PaddleSlim
# 每次进入项目后,需要执行一次
!pip install paddleslim -i https://pypi.tuna.tsinghua.edu.cn/simple


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









