







本文介绍了GRDDC数据集的基本信息,并进行了一些统计;同时给出了数据集的百度云下载。
目录
Update:
2022数据集也出来了,见:Data | 2022 IEEE International Conference on Big Data
1. 基本介绍
GRDDC是全球道路损伤检测挑战赛提供的数据集,从2018~2020每年举行一次。
2020年的数据集共21041个样本,包含三个国家:"Czech", "India", "Japan";样本量分别为:2829、7706、10506。
数据集中一共10类: ['d00', 'd01', 'd0w0', 'd10', 'd11', 'd20', 'd40', 'd43', 'd44', 'd50'],各类别含义分别为:
- d00:纵向裂缝;
- d01(d0w0为错误标签): 纵向拼接缝;
- d10: 横向裂缝;
- d11: 横向拼接缝;
- d20:龟裂;
- d40: 坑洞;
- d43: 十字路口模糊;
- d44: 白线模糊;
- d50: 井盖;

2. 类别分布
各个类别的分布如下:
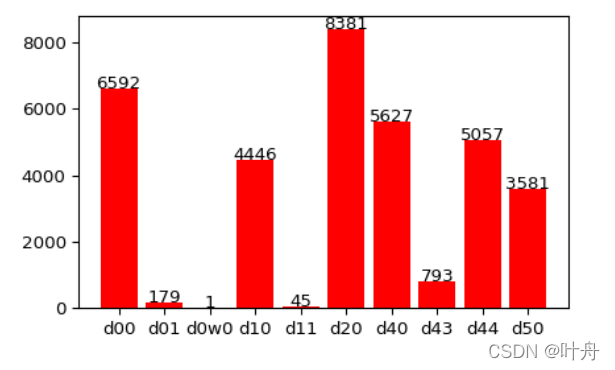
统计代码如下:
import os
import xml.etree.ElementTree as ET
import tqdm
def xml_parse(target):
"""
Arguments:
target (annotation) : the target annotation to be made usable
will be an ET.Element
Returns:
a list containing lists of bounding boxes [bbox coords, class name]
"""
res = []
for obj in target.iter("object"):
name = obj.find("name").text.strip()
bbox = obj.find("bndbox")
pts = ["xmin", "ymin", "xmax", "ymax"]
bndbox = [name]
for i, pt in enumerate(pts):
cur_pt = int(float(bbox.find(pt).text))
# scale height or width
# cur_pt = cur_pt / width if i % 2 == 0 else cur_pt / height
bndbox.append(cur_pt)
res.append(bndbox) # [xmin, ymin, xmax, ymax, label_name]
# img_id = target.find('filename').text[:-4]
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
if __name__ == '__main__':
raw_path = "path_to_grddc2020/train"
sub_dirs = ["Czech", "India", "Japan"]
statistic = {}
for sub_dir in sub_dirs:
img_path_root = os.path.join(raw_path, sub_dir, 'images')
xml_path_root = os.path.join(raw_path, sub_dir, 'annotations', 'xmls')
for f in tqdm.tqdm(os.listdir(img_path_root), ncols=100):
# parse xml
xml_path = os.path.join(xml_path_root, os.path.splitext(f)[0]+'.xml')
target = ET.parse(xml_path)
res = xml_parse(target)
for r in res:
cls = r[0]
# statistic
if cls not in statistic.keys():
statistic[cls] = 1
else:
statistic[cls] += 1
print(statistic)
for key in sorted(statistic):
print("{}: {}".format(key, statistic[key]))3. 百度云下载
链接: https://pan.baidu.com/s/1rwiflV7PVn_EZNyL7MQigg 提取码: ij09



















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











