







1. 读取数据
1.1 导入数据
1.1.1 csv 文件
df= pd.read_csv(
#该参数是数据在电脑里的路径,可以不填
filepath_or_buffer = r"c:\Users\win 10\Desktop\sz000002.csv",
#该参数代表数据的分隔符,csv文件默认为逗号,其他常见的"\t"
sep= ',',
#该参数代表跳过数据文件的第一行不读
skiprows = 1,
#nrows 只读前n行,若不指定,读取全部内容,
nrows= 15,
#将指定的列识别为日期格式,若不指定,时间数据将全会一字符串形式读入,
#parse_dates= ['交易日期'],
#将指定列设为index,若不指定,index 默认为0,1,2
#index_col= ['交易日期'],
#读取指定的几列数据,其他不读,若不指定,读入全部列
usecols= ['交易日期','股票代码','股票名称','收盘价','成交量','涨跌幅','MACD_金叉死叉'],
#当某行数据有问题,报错,设定false时,不报错直接跳过该行当数据比较脏乱的时候用这个
error_bad_lines= False ,
#将数据中的null识别为空值
na_values= 'NULL'
)
# 取列名集合
columns = data.columns.values.tolist()
1.1.2 json格式
import json
from glom import glom
# 字典格式的 JSON
import pandas as pd
data = [
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.DataFrame(data)
print(df)
# 字典格式的 JSON,字典格式转化为datafram,外边的key 为dataframe列, value 中的嵌套字典的key:value 为对应行的取值
s = {
"col1": {"row1": 1, "row2": 2, "row3": 3},
"col2": {"row1": "x", "row2": "y", "row3": "z"}
}
# 读取 JSON 转为 DataFrame
df = pd.DataFrame(s)
print(df)
# 从URL中读取Json数据
url_json = [
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
url = "http://static.runoob.com/download/sites.json"
df = pd.read_json(url) # 数组中的每一个{} 中 key 为dataframe 对应的col_name, value 为对应的取值,数组中{}的个数为dataframe最后的行数
# 一组内嵌的json数据文件
nested_list = {
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
with open("nested_list.json", "w") as f:
json.dump(nested_list, f)
"""
json 相关函数基本说明
json.dumps() 是将dict转化为str格式, json.loads是将str转化成dict格式
json.load() 和json.dump() 需要和文件的读写操作结合起来
"""
str = json.dumps(nested_list)
print(json.loads(str))
df = pd.read_json("nested_list.json") # read_json 只能读取[], {} 第一层的键值对,并分别付值为对应的col_name 和相应的取值
print(df)
# 先加载json数据
with open("nested_list.json", "r") as f:
data = json.loads(f.read())
print(data)
# 展平数据
df_nested_list = pd.json_normalize(data, record_path=["students"])
print(df_nested_list)
# data=json.loads(f.read()) 使用python json 模块载入数据
# json_normalize 使用了参数record_path并设置为["students"]用于展开内嵌的json数据students,
# 显示结果并没有包含school_name 和class 元素,如果需要展示可以使用meta参数来显示这些数据
df_nested_list_1 = pd.json_normalize(
data,
record_path=["students"],
meta=["school_name", 'class']
)
print(df_nested_list_1)
# 让我们尝试读取更复杂的json数据,该数据嵌套了列表和字典,数据文件nested_mix.json
# 使用到 glom 模块来处理数据套嵌,glom 模块允许我们使用 . 来访问内嵌对象的属性。
nested_mix = {
"school_name": "local primary school",
"class": "Year 1",
"info": {
"president": "John Kasich",
"address": "ABC road, London, UK",
"contacts": {
"email": "admin@e.com",
"tel": "123456789"
}
},
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
with open("nested_mix.json", 'w') as f:
json.dump(nested_mix, f)
with open("nested_mix.json", 'r') as f:
data = json.loads(f.read())
df = pd.json_normalize(
data,
record_path=['students'],
meta=[
'class',
['info', 'president'],
['info', 'contacts', 'tel']
]
)
print(df)
# 我们只读取内嵌中的 math 字段
nested_deep = {
"school_name": "local primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"grade": {
"math": 60,
"physics": 66,
"chemistry": 61
}
},
{
"id": "A002",
"name": "James",
"grade": {
"math": 89,
"physics": 76,
"chemistry": 51
}
},
{
"id": "A003",
"name": "Jenny",
"grade": {
"math": 79,
"physics": 90,
"chemistry": 78
}
}]
}
with open("nested_deep.json", 'w') as f:
json.dump(nested_mix, f)
df = pd.read_json('nested_deep.json')
print(df)
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
print(data)
def traverse_take_field(data, fields, currentKey=None):
"""遍历嵌套字典列表,取出某些字段的值
:param data: 嵌套字典列表
:param fields: 列表,某些字段
:param values: 返回的值
:param currentKey: 当前的键值
:return: 列表
"""
if isinstance(data, list):
for i in data:
traverse_take_field(i, fields, currentKey)
elif isinstance(data, dict):
for key, value in data.items():
traverse_take_field(value, fields, key)
else:
values.append(data)
# if currentKey in fields:
# values.append(data)
data = {"info": "2班成绩单",
"grades": {
"小明":
[{"chinese": 60}, {"math": 80}, {"english": 100}],
"小红":
[{"chinese": 90}, {"math": 70}, {"english": 50}],
"小蓝":
[{"chinese": 80}, {"math": 80}, {"english": 80}],
},
"newGrades": {
"info": "新增数据",
"newChinese": 77
}}
if __name__ == '__main__':
values = []
fields = ["chinese", "newChinese"]
traverse_take_field(data, fields)
print(values)
1.2 查看数据
print(df.shape) #输出dataframe 有多少行多少列
print(df.shape[0]) #取行数
print(df.shape[1]) #取列数
print(df.columns) #顺序输出每一列的名字,是一个列表
print(df.index) #顺序输出每一行的名字,
print(df.dtypes) # 数据每一列的类型不一样,比如数字、字符串、日期等。该方法输出每一列变量类型
print(df.head(3)) #看前3行的数据,默认为5
print(df.tail(3)) #看最后3行的数据,默认为5
print(df.sample(frac=0.5)) #随机抽取3行,想要的固定比例的话,可以用frac参数
print(df.describe()) #非常方便的函数,对每一列数据有一个直管感受;只会对数字类型的列有效
df.get("salary") # 取某一列
1.3 设置输出格式
pd.set_option('expand_frame_repr',False) # 当行太多时不换行
pd.set_option('max_colwidth',8) #设置每一行的最大宽度,恢复原设置方法pd.reset_option('max_colwidth')
1.4 读取数据
1.4.1 loc 操作
通过label(columns和index的名字)来读取数据
df.loc['09/12/2016'] #选取指定的某一行,读取的数据是series类型的
df.loc['13/12/2016': '06/12/2016'] # 选取在此范围内的多行,和在list中slice操作类似,读取的数据是DataFrame类型
df.loc[:, '股票代码':'收盘价'] # 选取在此范围内的多列,读取的数据是DataFrame类型
df.at['12/12/2016', '股票代码'] # 使用at读取指定的某个元素。loc也行,但是at更高效。
1.4.1 iloc 操作
通过position来读取数据
df.iloc[0] # 以index选取某一行,读取的数据是Series类型
df.iloc[1:3] # 选取在此范围内的多行,读取的数据是DataFrame类型
df.iloc[:, 1:3] # 选取在此范围内的多列,读取的数据是DataFrame类型
df.iloc[1:3, 1:3] # 读取指定的多行、多列,读取的数据是DataFrame类型
df.iloc[:, :] # 读取所有行、所有列,读取的数据是DataFrame类型
df.iat[1, 1] # 使用iat读取指定的某个元素。使用iloc也行,但是iat更高效。
2. 列操作
2.1 加减乘除
print(df['股票名称'] + '_地产') # 字符串列可以直接加上字符串,对整列进行操作
print(df['收盘价'] * 100) # 数字列直接加上或者乘以数字,对整列进行操作。
print(df['收盘价'] * df['成交量']) # 两列之间可以直接操作。收盘价*成交量计算出的是什么?
df['股票名称+行业'] = df['股票名称'] + '_地产' # 新增一列
print(df)
2.2 相关统计函数
df['收盘价'].mean() # 求一整列的均值,返回一个数。会自动排除空值。
df[['收盘价', '成交量']].mean() # 求两列的均值,返回两个数,Series
df[['收盘价', '成交量']].mean(axis=0) # 求两列的均值,返回DataFrame。axis=0或者1要搞清楚。
df['收盘价'].max() # 最大值
df['收盘价'].min() # 最小值
df['收盘价'].std() # 标准差
df['收盘价'].count() # 非空的数据的数量
df['收盘价'].median() # 中位数
df['收盘价'].quantile(0.25) # 25%分位数
2.3 shift类函数
df['昨天收盘价'] = df['收盘价'].shift(3) # 读取上一行的数据,若参数设定为3,就是读取上三行的数据;若参数设定为-1,就是读取下一行的数据;
print(df[['收盘价','昨天收盘价']])
del df['昨天收盘价'] # 删除某一列的方法
print(df)
df['涨跌'] = df['收盘价'].diff(-1) # 求本行数据和上一行数据相减得到的值
print(df[['收盘价', '涨跌']])
df.drop(['涨跌'], axis=1, inplace=True) # 删除某一列的另外一种方式,inplace参数指是否替代原来的df
print (df)
df['涨跌幅_计算'] = df['收盘价'].pct_change(-1) # 类似于diff,但是求的是两个数直接的比例,相当于求涨跌幅
print(df)
2.4 累加|乘
df['成交量_cum'] = df['成交量'].cumsum() # 该列的累加值
print(df[['成交量', '成交量_cum']])
print((df['涨跌幅'] + 1.0).cumprod()) #product 该列的累乘值,此处计算的就是资金曲线,假设初始1元钱。
2.5 rank、value_counts
df['收盘价_排名'] = df['收盘价'].rank(ascending=True, pct=False) # 输出排名。ascending参数代表是顺序还是逆序。pct参数代表输出的是排名还是排名比例
print(df[['收盘价', '收盘价_排名']])
del df['收盘价_排名']
print(df['股票代码'].value_counts()) # 计数。统计该列中每个元素出现的次数。返回的数据是Series
2.6 筛选操作
print(df['股票代码'] == 'sh000002') # 判断股票代码是否等于sz000002
print(df[df['股票代码'] == 'sz000002']) # 将判断为True的输出:选取股票代码等于sz000002的行
print(df[df['股票代码'].isin(['sz000002', 'sz000003 ', 'sz000004'])]) # 选取股票代码等于sz000002的行
print(df[df['收盘价'] >= 24.0] ) # 选取收盘价大于24的行
print(df[(df.index >= '03/12/2016') & (df.index <= '06/12/2016')]) # 两个条件,或者的话就是|
2.7 缺失值处理
2.7.1 删除缺失值
print(df.dropna(how='any')) # 将带有空值的行删除。how='any'意味着,该行中只要有一个空值,就会删除,可以改成all。
print(df.dropna(subset=['MACD_金叉死叉', '涨跌幅'], how='all')) # subset参数指定在特定的列中判断空值。
all代表全部为空,才会删除该行;any只要一个为空,就删除该行。
# 删除列
df.drop(labels=['row_label', 'marital_stat'], axis=1, inplace=True)
2.7.2 补全缺失值
print(df.fillna(value='没有金叉死叉')) # 直接将缺失值赋值为固定的值
df['MACD_金叉死叉'].fillna(value=df['收盘价'], inplace=True) # 直接将缺失值赋值其他列的数据
print(df.fillna(method='ffill')) # 向上寻找最近的一个非空值,以该值来填充缺失的位置,全称forward fill,非常有用
print(df.fillna(method='bfill')) # 向下寻找最近的一个非空值,以该值来填充确实的位置,全称backward fill
2.7.3 找出缺失值
print(df.notnull()) # 判断是否为空值,反向函数为isnull()
print(df[df['MACD_金叉死叉'].notnull()]) # 将'MACD_金叉死叉'列不为空的行输出
2.8 排序函数 sort
df.reset_index(inplace=True)
print(df.sort_values(by=['交易日期'], ascending=1)) # by参数指定按照什么进行排序,acsending参数指定是顺序还是逆序,1顺序,0逆序
print(df.sort_values(by=['股票名称', '交易日期'], ascending=[1, 1])) # 按照多列进行排序
3. df操作
3.1 DataFrame 数据拼接
3.1.1 上下合并append
df.reset_index(inplace=True)
df1 = df.iloc[0:10][['交易日期', '股票代码', '收盘价', '涨跌幅']]
print(df1)
df2 = df.iloc[5:15][['交易日期', '股票名称', '收盘价', '涨跌幅']]
print(df2)
print(df1.append(df2)) # append操作,将df1和df2上下拼接起来。注意观察拼接之后的index
df3 = df1.append(df2, ignore_index=True) # ignore_index参数,用户重新确定index
print(df3)
3.1.2 merge操作
df.merge(): 可以根据一个或多个键将不同DataFrame中的行连接起来,类似于数据库中的join方法
df = pd.merge(
left=df, # 两个表合并,放在左边的表
right=df_index, # 两个表合并,放在右边的表
on=['交易日期'], # 以哪个变量作为合并的主键,可以是多个,但是一定要在两张表中都存在。
how='outer',
# left:只保留左表的主键,right:只保留右表的主键,
# outer:两边的主键都保留,inner:两边都有的主键才保留
# 此处使用outer和right都可以
sort=True, # 结果数据是否按照主键进行排序
suffixes=['_股票', '_指数'], # 若两边除了主键之外有相同的列名,给这些列加上后缀
# indicator=True # 增加_merge列,表明这一行数据来自哪个表
)
3.1.3 join操作
join 连接主要是列索引上的合并,join默认为左连接,只能操作DataFrame
df = pd.DataFrame({'a':[1,2,34]})
df = df.join(pd.DataFrame({'b':[11,22]}))
3.1.4 concat()操作
concat是轴向链接,关键在与axis,axis=0表示列操作,axis=1 行操作,默认为0
df= pd.concat([df1, df2,df3], axis=0, ignore_index=True)
差集(df1-df2为例)
diff=pd.concat([df1,df2]).drop_duplicates(keep=False)
3.2 聚合和分组
https://sparkbyexamples.com/pandas/pandas-groupby-count-examples/
3.3 apply 方法
当想要进行的操作,在pandas当中,没有相应直接可用的函数的时候,可以使用apply方法
# apply的参数是函数名
# 以下定义几个简单的函数,演示apply
def f1(x):
return x + 100
# x究竟是什么?
# print x
# print type(x)
# exit()
# x就是['收盘价']这个series,对series可以进行的任何操作,在f1中都可以进行。可以进行很复杂的操作。
# print df[['收盘价']].apply(f1)
# lambda函数定义方法
# 通常用于定义一些比较简单的、一行代码可以表述清楚的、一次性的函数。比较复杂就不要使用。
# 以下是几个案例
print(df['收盘价'].apply(lambda x: int(x * 100)))
print(df['股票代码'].apply(lambda x: x[2:] + x[:2].upper()))
3.2 数据去重
df3中有重复的行数,我们如何将重复的行数去除?
df3.drop_duplicates(
subset=['收盘价', '交易日期'], # subset参数用来指定根据哪类类数据来判断是否重复。若不指定,则用全部列的数据来判断是否重复
keep='first', # 在去除重复值的时候,我们是保留上面一行还是下面一行?first保留上面一行,last保留下面一行,False就是一行都不保留
inplace=True
)
print(df3)
3.2 重命名、转置、空值
print(df.rename(columns={'MACD_金叉死叉': '金叉死叉', '涨跌幅': '涨幅'})) # rename函数给变量修改名字。使用dict将要修改的名字传给columns参数
print(df.empty) # 判断一个df是不是为空,此处输出不为空
print(pd.DataFrame().empty) # pd.DataFrame()创建一个空的DataFrame,此处输出为空
print(df.T) # 将数据转置,行变成列,很有用
np.random.pernutation
explode
3.3 字符串处理
print(df['股票代码'])
print('sz000002'[:2])
print(df['股票代码'].str[:2])
print(df['股票代码'].str.upper()) # 加上str之后可以使用常见的字符串函数对整列进行操作
print (df['股票代码'].str.lower())
print (df['股票代码'].str.len()) # 计算字符串的长度,length
df['股票代码'].str.strip() # strip操作,把字符串两边的空格去掉
print(df['股票代码'].str.contains('sh')) # 判断字符串中是否包含某些特定字符
print(df['股票代码'].str.replace('sz', 'sh')) # 进行替换,将sz替换成sh
split操作
print (df['新浪概念'].str.split(';')) # 对字符串进行分割
print(df['新浪概念'].str.split(';').str[:2]) # 分割后取第一个位置
print(df['新浪概念'].str.split(';', expand=True)) # 分割后并且将数据分列
3.4 时间处理
df['交易日期'] = pd.to_datetime(df['交易日期']) # 将交易日期由字符串改为时间变量
print(df['交易日期'])
print(df['交易日期'].iloc[0])
print(df.dtypes)
print(pd.to_datetime('1999年01月01日')) # pd.to_datetime函数:将字符串转变为时间变量,,!!!!python3此用法不合理
print(df.at[0, '交易日期'])
print(df['交易日期'].dt.year) # 输出这个日期的年份。相应的month是月份,day是天数,还有hour, minute, second
print(df['交易日期'].dt.week) # 这一天是一年当中的第几周
print(df['交易日期'].dt.dayofyear) # 这一天是一年当中的第几天
print(df['交易日期'].dt.dayofweek) # 这一天是这一周当中的第几天,0代表星期一
print(df['交易日期'].dt.weekday) # 和上面函数相同,更加常用
print(df['交易日期'].dt.weekday_name) # 和上面函数相同,返回的是星期几的英文,用于报表的制作。
print(df['交易日期'].dt.days_in_month) # 这一天是这一月当中的第几天
print(df['交易日期'].dt.is_month_end ) # 这一天是否是该月的开头,是否存在is_month_end?
print(df['交易日期'] + pd.Timedelta(days=1)) # 增加一天,Timedelta用于表示时间差数据
print((df['交易日期'] + pd.Timedelta(days=1)) - df['交易日期']) # 增加一天然后再减去今天的日期
3.5 rolling、expanding操作
# 计算'收盘价'这一列的均值
print(df['收盘价'].mean())
# 如何得到每天的最近3天收盘价的均值呢?即如何计算常用的移动平均线?
使用rolling函数
df['收盘价_3天均值'] = df['收盘价'].rolling(3).mean()
print(df[['收盘价', '收盘价_3天均值']])
rolling(n)即为取最近n行数据的意思,只计算这n行数据。后面可以接各类计算函数,例如max、min、std等
print(df['收盘价'].rolling(3).max())
print(df['收盘价'].rolling(3).min())
print(df['收盘价'].rolling(3).std())
rolling可以计算每天的最近3天的均值,如果想计算每天的从一开始至今的均值,应该如何计算?
使用expanding操作
df['收盘价_至今均值'] = df['收盘价'].expanding().mean()
print(df[['收盘价', '收盘价_至今均值']])
expanding即为取从头至今的数据。后面可以接各类计算函数
print df['收盘价'].expanding().max()
print df['收盘价'].expanding().min()
print df['收盘价'].expanding().std()
3.6 多列合并为一列
df['ColumnA'] = df[df.columns[1:]].apply(
lambda x: ','.join(x.dropna()),
axis=1) # ”1:“表示合并第一列之后的各列为一列
3.7 一列变多列
# pandas:一列分解成多列 series.str.split(',',expand=True)
def preprocessing(data):
df_result = pd.DataFrame()
# df_sub = data['emb'].str.split(',', expand=True)
sub = data['emb'].apply(lambda x: [float(i) for i in x.split(',')])
df_sub = pd.DataFrame(sub.values.tolist()) # 一列list变多列
df_sub.columns = ['emb_' + str(x) for x in df_sub.columns]
df_result = pd.concat([df_result, df_sub], axis=1)
return df_result
3.8 filter、map操作
# 1. filter 操作
pd.read_csv('imdb.txt')
.sort(columns='year')
.filter(lambda x: x['year']>1990)
.to_csv('filtered.csv')
# 2. map 操作
# Select the basic features.
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"]
})
movies = movies.map(lambda x: x["movie_title"])
# ①使用字典进行映射
data["gender"] = data["gender"].map({"男":1, "女":0})
#②使用函数
def gender_map(x):
gender = 1 if x == "男" else 0
return gender
#注意这里传入的是函数名,不带括号
data["gender"] = data["gender"].map(gender_map)
4. 文件输出
df.to_csv('output.csv', encoding='gbk', index=False)
5. 创建DF
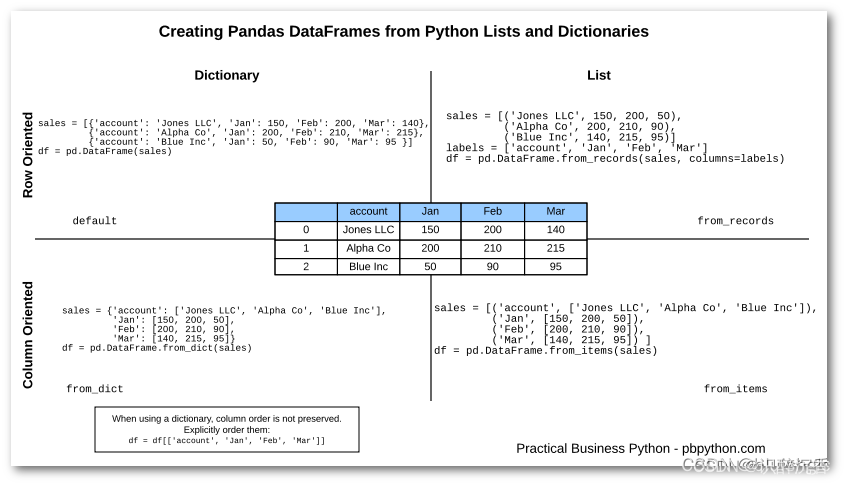
6. 划分训练集
- 使用 sample方法
train = df.sample(frac=0.7, random_state=0, axis=0)
test = df[~df.index.isin(df.index)]















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









